







前言
CPU高速缓存是为了解决CPU速率和主存访问速率差距过大问题。本文主要从存储器层次结构和主流cache缓存原理角度,分享解析高速缓存,方便软件编程时写出更加高效的代码!
本文主要资料来源是《深入理解计算机系统》高速缓存章节,补充了一些里面没有提及到的几个重要概念。以读书笔记方式浅析CPU高速缓存原理。
程序员为何需要学习CPU cache?
作为一个程序员,我们需要理解存储器层次结构和CPU cache缓存原理,因为它们对程序性能有着巨大的影响。比如访问CPU寄存器中的数据,只需要一个时钟周期;访问高速缓存中的数据,大概需要几十个时钟周期;如果访问的数据在主存中,需要大概上百个周期;而访问磁盘中的数据则需要大约几千万个周期!因此我们应该了解存储器层次结构,让我们的程序尽可能得高效执行。
存储器层次结构
一种典型的存储器层级结构如下:
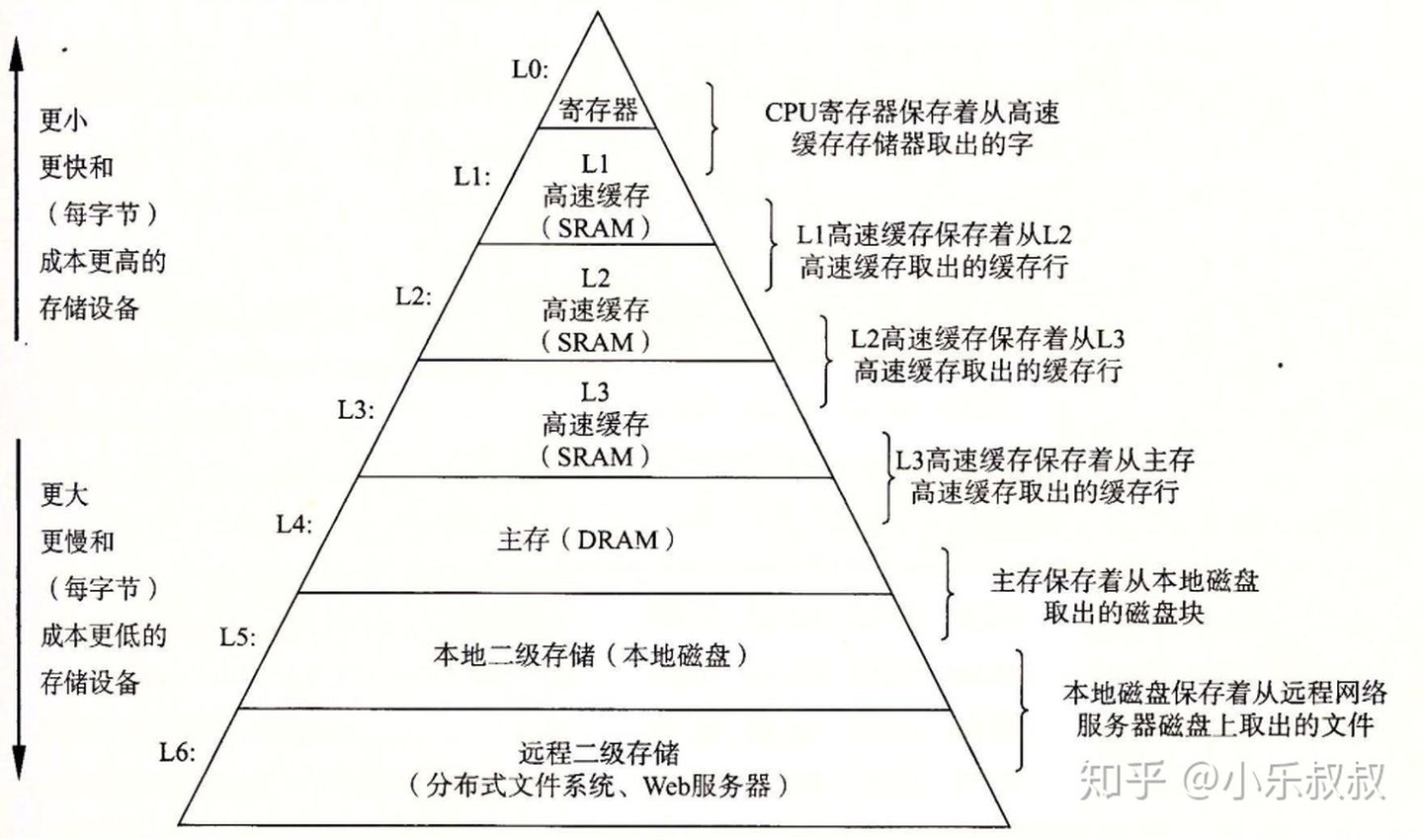
图1 存储器层级结构
几个关键的层次访问速度:
| 存储器 | 访问速度(clock) | |
|---|---|---|
| CPU寄存器 | 1 | |
| SRAM高速缓存 | n | |
| DRAM主存 | 10n ~ 100n |
除了本文主角CPU高速缓存外,计算机系统还有很多利用“缓存”的地方:

图2 不同缓存的用处
程序运行的局部性
在了解了存储器层次结构后,我们考虑一个问题:如何用缓存提高程序运行效率?
计算机程序运行遵循局部性原则。局部性原理是指程序在执行时呈现出局部性规律,即在一段时间内,整个程序的执行仅限于程序中的某一部分。相应地,执行所访问的存储空间也局限于某个内存区域。局部性原理又表现为:时间局部性和空间局部性。
- 时间局部性 是指如果程序中的某条指令一旦执行,则不久之后该指令可能再次被执行;如果某数据被访问,则不久之后该数据可能再次被访问。
- 空间局部性 是指一旦程序访问了某个存储单元,则不久之后,其附近的存储单元也将被访问。
具有良好局部性的程序比差的程序更多的倾向于从存储器层次结构较高层次处访问数据,因此运行的更快,尤其是执行大数据量的算术运算。了解局部性原理,有利于提高我们程序的运行效率。
下面引用《深入理解计算机系统》中的一个经典例子,来理解程序局部性对效率的影响。
程序A:
int sum_arry(int a[m][n])
{
int i, j, sum = 0;
for (i = 0; i < m; i++) {
for (j = 0; j< n; j++)
sum += a[i][j];
}
return sum;
}程序B
int sum_arry(int a[m][n])
{
int i, j, sum = 0;
for (j = 0; j < n; j++) {
for (i = 0; i< m; i++)
sum += a[i][j];
}
return sum;
}两个程序都是对一个二维数组矩阵求和,不同的是第一种是先求第一行的和,然后第二行,依次类推,这也是最常见的写法。第二种i j换了位置,从矩阵上看是按列求和。
第一种顺序访问矩阵中的每个元素(存储顺序),具有步长为1的引用模式,这种模式被称为顺序引用模式。显然这种模式具有很好的空间局部性。顺序引用模式是程序空间局部性的重要来源。第二个程序局部性很差,并未按照二维数组在内存中的顺序来访问。
多级缓存
在前面介绍的存储器层级结构中,我们知道高速缓存是插在CPU寄存器和主存之间的缓存存储器,称为L1高速缓存,基本是由SRAM(static RAM)构成,访问时大约需要4个始终周期。刚开始只有L1高速缓存,后来CPU和主存访问速度差距不断增大,在L1和主存之间增加了L2高速缓存,可以在10个时钟周期内访问到。现代CPU又增加了一个更大的L3高速缓存,可以在大约50个时钟周期内访问到它。三个level的高速缓存用处依据具体SOC架构而定,下面给出一个典型的英特尔core:Intel Core i7
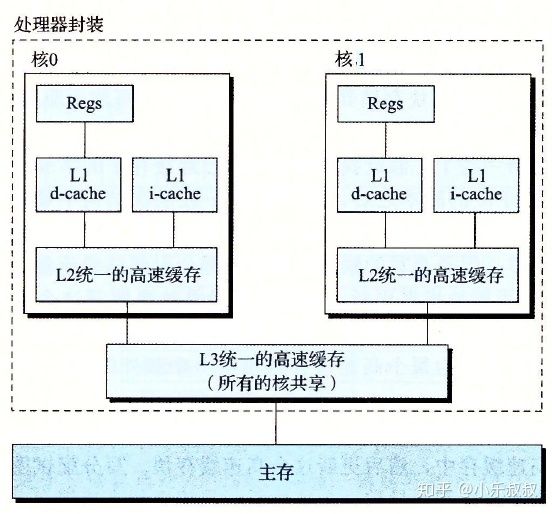
图3 Intel Core i7 缓存层级结构
L1、L2缓存在CPU核内部独有,L1分D-cache(数据) 和 I-cache(指令)。多核共享L3 cache。
高速缓存控制器
一般高速缓存只有几十KB,而主存有几GB甚至更多,系统就是通过高速缓存控制器来管理缓存映射内存。

图4 高速缓存控制器
高速缓存是由硬件来管理的,一般OS不需要参与(具体情况后面会分析)。高速缓存控制器存放一个表项数组,每一个表项对应高速缓存中的line行。表项由标签tag(n位)和表示状态的几个flag组成(图5 b)。标签能让高速缓存控制器辨别 line行映射的内存单元。在访问存储单元时,把物理地址高几位和物理地址子集提取的行的标签对比,相同则表示命中高速缓存。读操作简单,写操作会涉及写高速缓存+DRAM 和 只写 高速缓存两种情况,较为复杂,一致性问题以后再分析。现代处理器都有多级缓存cache,多级间一致性由硬件处理,Linux只当一级处理。
高速缓存原理
在x86体系中,由一个新单位:line,行。高速缓存换入换出的单元就是line。由几十个连续字节组成,用来在DRAM和SRAM间传送,实现高速缓存。主存中任意一行和高速缓存中N个行的任意一行相关联。
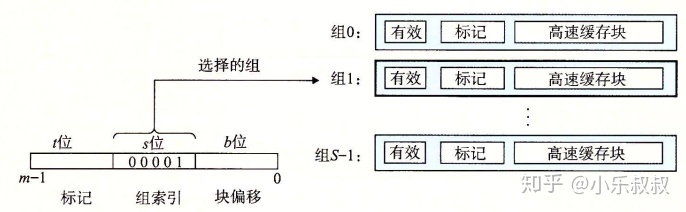
假设这样一个系统,主存地址有m位,共有M=2^m个不同地址;高速缓存分成S个组,每个组E行,每行B个字节:
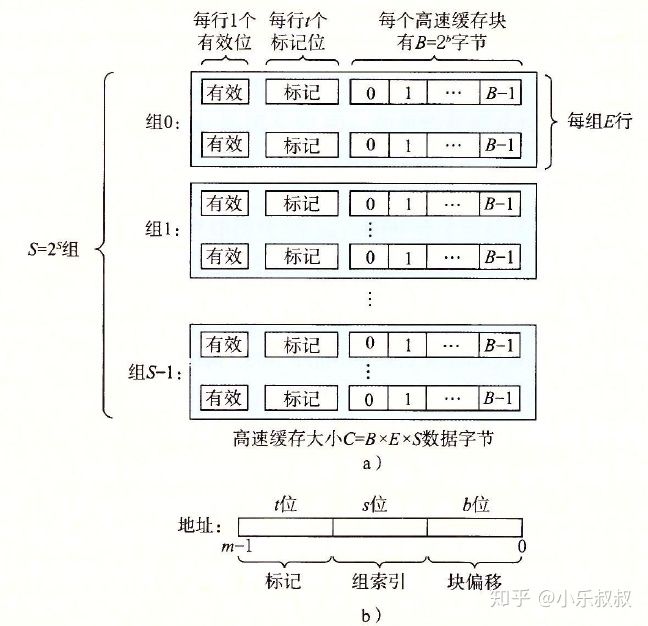
图5 高速缓存组织结构
每行由一个 B=2^b字节的数据块组成,一个有效位指明这个行是否包含有意义信息,还有t=m-(b+s)个标记位(tag bit)用于唯一标识存储在这个高速缓存行中的块。缓存总大小为C=BxExS。
这种缓存结构被称为:组相联高级缓存,
- E等于1的时候称之为“直接映射高速缓存”,
- E等于C/B即一个组包含所有行的时候称之为“全相联高速缓存”
每个组中行数E越多,硬件设计越复杂,成本就越高。但好处是标记内存地址的t位会越多,可以映射更多内存,即越不容易出现cache thrashing。
下面以一个“直接映射高速缓存”例子,来分析高速缓存原理。假设我们的缓存line为64字节(2^6),共512个line(2^9),一共32KB。

那么32K的大小怎么进行对4G的内存进行映射呢?高速缓存读物理内存的位置不是任意的,而是固定的。从RAM0地址开始,每32KB需要512行映射一次,这样固定的地址会被固定的行映射。假如CPU要访问一个地址:“0x0003 057E”,缓存映射关系和判断该地址是否命中缓存过程如下:
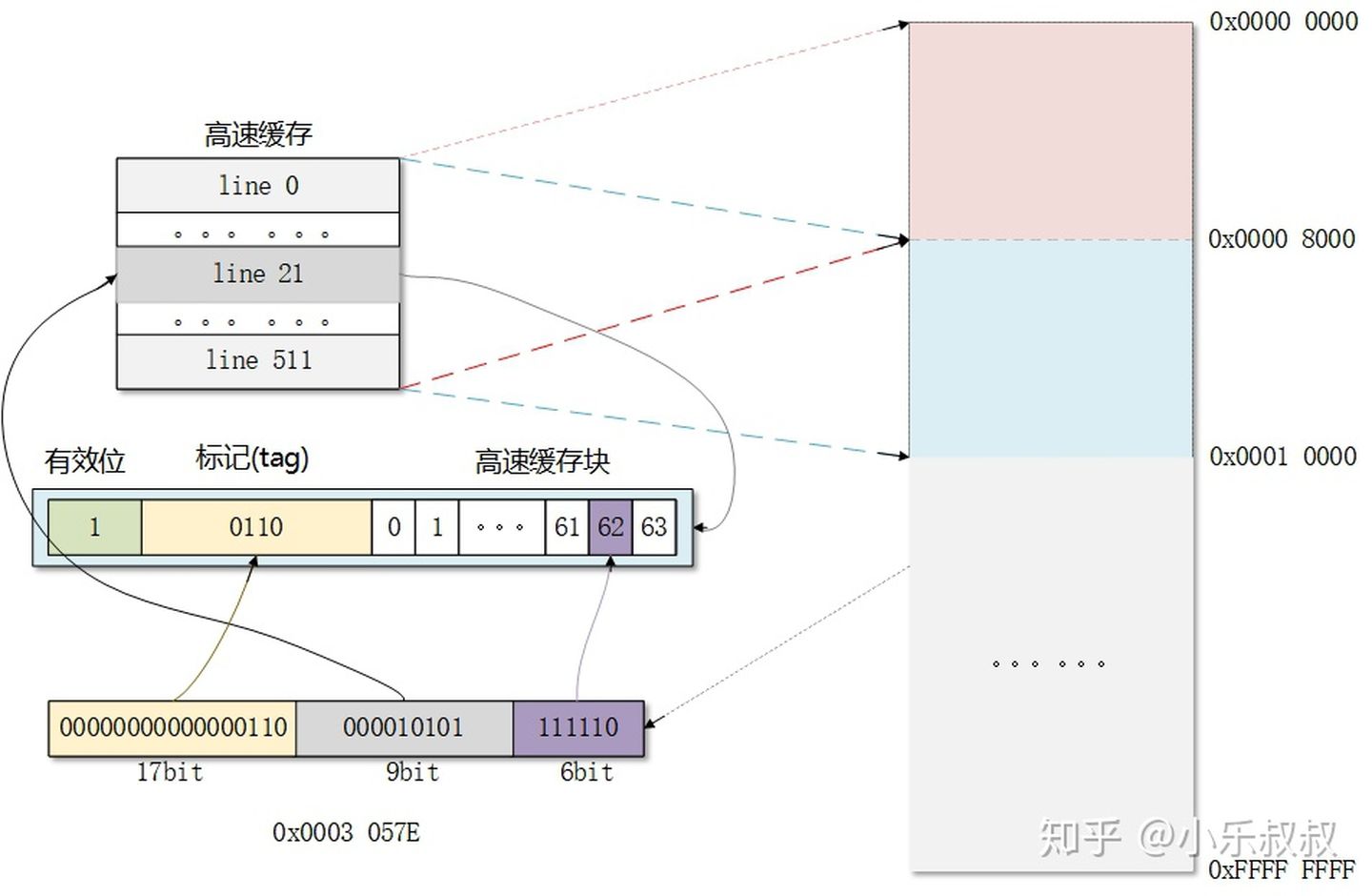
图6
缓存确定一个请求是否命中,抽取被请求字的过程分三步:
- 1)组选择
- 2)行匹配
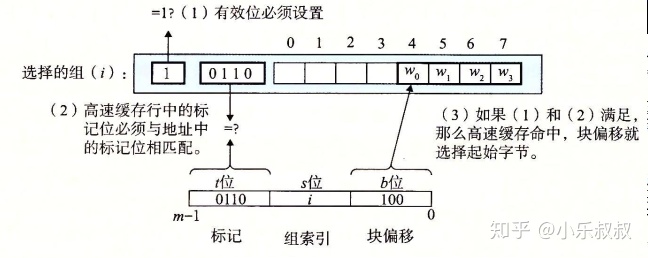
- 3)字选择
b位表示的块偏移,用于选择具体哪个字节。
这样设计的好处是,检查一个内存地址是否命中时,不需要遍历整个cache,因为可以缓存该地址的line是固定的!这里对应空间划分就是s=512,e=1,b=64B;这样的划分叫做直接映射高速缓存,缺点是地址中s位占用的过多,b位不变,标记内存地址的t位就少;常见的划分是e=16,对于32KB缓存,s=32,只不过需要在查命中时,遍历一组中的16个line。
关于缓存写
前面介绍的,关于高速缓存读的操作很简单。首先在高速缓存中查找所需字判断是否命中,如果命中,立即返回缓存中的副本给CPU;如果不命中(以一个level为例),从存储器层次结构中较低层次中取字的块,并将这个块存储到相应高速缓存行中。
写的情况则更加复杂。当缓存命中时,写又分为直写(write-through)和回写(write-back),区别是后者尽可能得推迟缓存更新到主存。当缓存不命中时,一种方法是写分配(write-allocate),加载相应的低一层中的块到高速缓存中,然后更新高速缓存。写操作优化非常复杂,本文略提不再详细讨论,后面有机会再详细分析CPU高速缓存的一致性问题。
补充:cache使用的地址和易出现的问题
【1】高速缓存抽取的地址是物理地址还是虚拟地址?
处理器在进行存储器访问时,处理器访问的是虚拟地址,经过TLB和MMU的映射,最终变成了物理地址。高速缓存在判断是否命中时使用的内存地址是虚拟内存还是物理内存?根据标记域(tag)和索引域(s位和b位)使用地址不同分为下面三种:
1) VIVT(Virtual Index Virtual Tag):使用虚拟地址索引域和虚拟地址的标记域:
简单理解是:高速缓存在判断是否命中时使用的内存地址是虚拟地址。虚拟地址直接送到高速缓存控制器,如果cache hit。直接从cache中返回数据给CPU。如果cache miss,则把虚拟地址发往MMU,经过MMU转换成物理地址,根据物理地址从主存(main memory)读取数据。
这种缓存优点是硬件设计简单,刚开始时很多CPU都是采用这种方式。但这种方式会引入很多软件使用上的问题。 操作系统在管理高速缓存正确工作的过程中,主要会面临两个问题。歧义(ambiguity)和别名(alias)。为了保证系统的正确工作,操作系统负责避免出现歧义和别名。
2) VIPT(Virtual Index Physical Tag):使用虚拟地址的索引域和物理地址的标记域:
VIPT使用虚拟地址的索引域和物理地址的标记域来查找cache line,它可以避免VIVT出现的别名(alias)问题。
以Linux kernel为例,它是以4kb为页面进行管理的,那么对于一个页来说,虚拟地址和物理地址的低12bit是相同的,所以不同的虚拟地址映射到同一个物理地址的时候,这些虚拟地址的低12bit也是相同的,在这种情况下,如果索引域在0~12bit之内,那么这些虚拟地址的cache组是相同的,同样的它们的Physical Tag也是相同的,那么这些不同的虚拟地址的cache line在cache里面是同一个,因此不会产生一致性问题。
3) PIPT(Physical Index Physical Tag):使用物理地址的索引域和物理地址的标记域
这种方式下索引域和标记域都采用物理地址,这种方式也可以避免缓存别名问题,不过性能方面要差一些,因为要先经过地址翻译的过程。
不同level的缓存,根据缓存大小、效率要求可能采用不同的虚拟/物理地址策略。VIVT Cache问题太多,软件维护成本过高,是最难管理的高速缓存,现在基本不再采用这种方式。
【2】歧义(ambiguity)问题(又称重名)
相同的虚拟地址可能对应着不同的物理地址。比如两个独立的进程就会出现这种情况,因为进程地址空间独立。采用VIVT的虚拟高速缓存中,同的数据在cache中具有相同的tag和index,就出现了歧义(ambiguity)问题。解决方法是OS在进程切换时flush缓存,这样即给OS代理负担,频繁刷新缓存也会降低效率。
采用VIPT、PIPT的平台就没有这个问题,对应的OS里flush缓存的API也是空的。
【3】别名(alias)问题
不同的虚拟地址可能映射相同的物理地址,比如共享内存。在采用VIVT的虚拟高速缓存中,同一个物理地址的数据被加载到不同的cacheline中,此时就发生了别名问题。别名问题会导致缓存不一致问题。
参考
《深入理解计算机系统第三版》















 4384
4384











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









