









1、计算机设备、组件数据传输速度类比
| 计算机设备、组件 | 读 | 类比 |
|---|---|---|
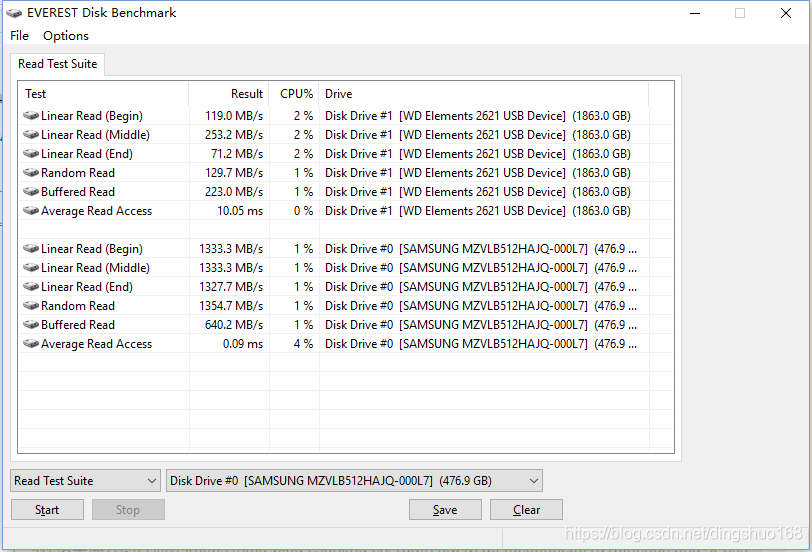
| 机械硬盘 | 0.1G/S | 蜗牛量级(60m/h) , 以机械盘为基准 |
| 固态盘 | 1.3G/S | 龟速量级(780m/h),13倍机械硬盘 |
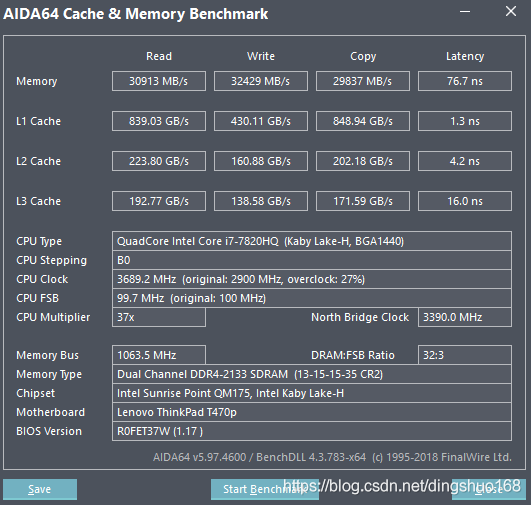
| 内存 | 30G/S | 跑步量级(23.4km/h), 300倍机械硬盘 |
| L3 Cache | 190G/S | 汽车量级(114km/h) ,1900倍机械硬盘 |
| L2 Cache | 200G/S | 跑车量级(120km/h ),2000倍 机械硬盘 |
| L1 Cache | 800G/S | 飞机量级(600km/h),8000倍机械硬盘 |
类比的速度按量级进行匹配,大家脑海中有个概念就好了。
参考:世界上速度最慢的10种动物,做什么都慢半拍
蜗牛速度理论上能达到每小时40多米
乌龟跑得慢的主要原因是因为腿短,还背着一个重重的龟壳,平均速度在每小时2公里左右。
马拉松,全程42.195km,世界纪录2019年10月12日肯尼亚选手埃鲁德·基普乔格跑出了1小时59分40秒的成绩
2、计算机设备、组件数据访问延迟时间对比
| 计算机设备、组件 | 读 | 类比 |
|---|---|---|
| 机械硬盘 | 10ms =1千万ns | 以机械盘为基准 |
| 固态盘 | 0.09ms =9万ns | 100倍 |
| 内存 | 80ns | 12万倍 |
| L3 Cache | 16ns | 63万倍 |
| L2 Cache | 4 ns | 250万倍 |
| L1 Cache | 1ns | 1000万倍 |
⚠️注意:上面的时间应该是读一个字长数据耗费的时间,由于硬盘一次传输的数据块比较大,内存和cache一次传输数据比较小,所以,各个存储的数据传输速度相对基准的倍数和数据访问延迟相对基准的倍数差别较大。
3、机械&固态硬盘测试
4、高速缓存&内存速度测试


















 1671
1671

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











