







 本文介绍了决策树算法的基本概念,包括基尼不纯度、熵、信息增益等,并详细解析了ID3、C4.5及CART三种决策树算法的工作原理及优缺点。
本文介绍了决策树算法的基本概念,包括基尼不纯度、熵、信息增益等,并详细解析了ID3、C4.5及CART三种决策树算法的工作原理及优缺点。
决策树:决策树是一种简单的机器学习方法,它是对被观测数据进行分类的一种相当直观的方法,决策树在经过训练之后,看起来就像是以树状形式排列的一系列if-then语句,一旦我们有了决策树,根据决策树进行决策的过程就非常的简单,只有沿着树的路径一直向下,正确的回答每一个问题,就会得到最终的答案。随机森林是在建立多棵决策树,然后按照不同决策树的结果选择输出属性最多的那个作为最后的结果。
一、几个重要概念
1、基尼不纯度(Gini Impurity):
基尼不纯度是一种度量集合有多纯的方法,如果集合里面的值都是一个数的话,则基尼不纯度的值为0,随着混合的东西越多,则基尼不纯度值越高。公式为
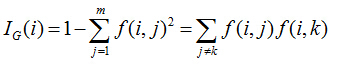
def giniimpurity(l):
total = len(l)
counts = {}
for item in l:
counts.setdefault(item,0)
counts[item]+= 1
imp = 0
for j in l:
f1 = float(counts[j])/total
for k in l:
if j==k:continue
f2 = float(counts[k])/total
imp += f1 * f2
return imp
#x = [1,1,1]
#print giniimpurity(x)
2、熵(Entropy):
在信息论中,熵代表的是集合的无序程度,即我们所处的当前集合的混杂程度。可以看成我们从集合中随机抽取一个元素的意外程度,如果说集合中的所有元素都是A,那么当我们从中抽取A元素的时候是绝对不出现意外的,此时的熵为0。熵的计算公式为:
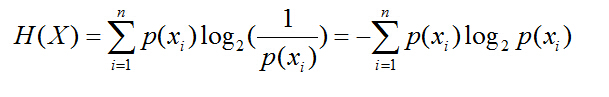
def entropy(l):
from math import log
log2 = lambda x: log(x)/log(2)
total = len(l)
counts = {}
for item in l:
counts.setdefault(item,0)
counts[item] += 1
ent = 0
for i in counts:
p = float(counts[i])/total
ent -= p * log2(p)
return ent
#x = [1,1,1,2,3]
#print entropy(x)熵和基尼不纯度之间的主要区别在于,熵达到峰值的过程相对要慢一些,因此,熵对于混乱集合的“判罚”往往要更重一些。由于人们对于熵的使用更为普遍,以下都用熵作为度量标准。
3、信息增益:
已经有了熵或者基尼不纯度作为衡量训练样本集合的纯度标准,由此,我们可以定义属性分类训练数据的效率度量标准。这个标准被称为“信息增益(information gain)”。假设我们选用熵来作为度量标准,一个属性的信息增益就是由于使用了这个属性对样本进行分割,从而导致的期望的熵值降低(分类更为纯净)。其定义公式如下:
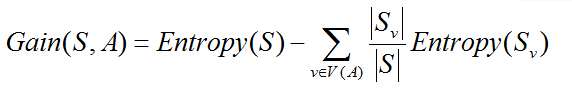
V(A)是属性A的值域
S是样本集合
S(v)是S中属性A值等于v的样本的集合
二、ID3算法
ID3算法用于决策树建立的过程:
(1)对于当前的所有样本集合,计算每个属性的信息增益
(2)选择信息增益最大的属性(假设为Ai)
(3)把在Ai出取值相同的样本对于同一个子集,Ai有几个属性,就合成几个子集
(4)重复以上的三个过程,直到结束(熵值为0或者一个阈值)
ID3算法使用的是自顶向下的贪婪搜索便利可能的决策树空间构造,属于局部最优,不一定全局最优。
三、C4.5算法
C4.5是另一种决策树构造算法,它是上文ID3的一个改进。主要的差别如下:
(1)用信息增益率代替信息增益来选择属性,ID3选择属性用的是子树的信息增益,而C4.5用的是信息增益率。
(2)在树的构造过程中进行剪枝,比较不容易overfiting
(3)对非离散值也可以进行处理
(4)能够对不完整的数据进行处理
在对于信息增益和信息增益率的比较上,july用了一个很好的例子来说明:一般来说率就是用来取平衡用的,就像方差起的作用差不多,比如有两个跑步的人,一个起点是10m/s的人、其10s后为20m/s;另一个人起速是1m/s、其1s后为2m/s。如果紧紧算差值那么两个差距就很大了,如果使用速度增加率(加速度,即都是为1m/s^2)来衡量,2个人就是一样的加速度。因此,C4.5克服了ID3用信息增益选择属性时偏向选择取值多的属性的不足。
信息增益率的定义:
分裂信息度量被定义为(分裂信息用来衡量属性分裂数据的广度和均匀):
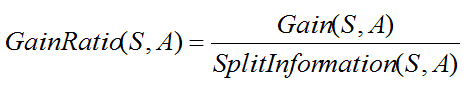
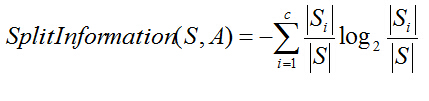
四、CART算法(Classification And Regression Tree)
CART也是决策树的一种生成算法,主要的差别在于CART的决策是二叉树的,它同样可以处理离散值,但是,只能选择其中一种来把数据分成两个部分。
对于其中有多重输出结果的属性,是如何选择它的拆分方法的?根据集体智慧编程的方法,对于属性A的所有取值保存下来,分别计算他们的信息增益,然后选择信息增益最高的value进行拆分。
Reference:
《集体智慧编程》
《数据挖掘——实用机器学习》
http://blog.csdn.net/v_july_v/article/details/7577684

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









