







 本文介绍了Q-Learning作为强化学习的一种经典算法,主要用于解决马尔可夫决策问题。通过阐述马尔可夫决策过程(MDP)和k-armed bandit问题,深入理解Q-Learning的工作原理。此外,还展示了使用Q-Learning解决robocode实战案例。
本文介绍了Q-Learning作为强化学习的一种经典算法,主要用于解决马尔可夫决策问题。通过阐述马尔可夫决策过程(MDP)和k-armed bandit问题,深入理解Q-Learning的工作原理。此外,还展示了使用Q-Learning解决robocode实战案例。
强化学习(Reinforcement Learning)是一种机器学习算法,强调如何基于环境而行动,以取得最大化的预期利益,在机器人领域应用较为广泛。Q-Learning属于强化学习的经典算法,用于解决马尔可夫决策问题。
马尔可夫决策过程(Markov Decision Processes,MDP)
强化学习研究的问题都是基于马尔可夫决策过程的,分为有限马尔可夫决策过程和无限马尔可夫决策过程。这里主要介绍有限马尔可夫决策过程。
马尔可夫性质:根据每个时刻观察到的状态,从可用的行动集合中选用一个行动作出决策,系统下一步(未来)的状态是随机的,并且其下一步状态与历史状态无关。
马尔可夫决策过程可以描述为:一个机器人(agent)通过采取行动(action)改变自身状态(state),与环境(E)互动得到回报(Reward)。目的是通过一定的行动策略(π)获得最大回报。它有5个元素构成:
S:所有可能的状态的集合(元素可能会很多,设计的时候需要合并或舍弃)
A:在状态S下可以做出的行为
p:Pa(S, S'),表示在a行为下t时刻状态S转化为t+1时刻状态S'的概率
Gamma:衰减变量,距离当前时刻t越远的回报R对当前决策的影响越小,避免在无限时间序列中导致的无偏向问题
V:衡量策略(π)的价值,与当前立即回报以及未来预期回报有关,v(S) = E [U|St],U = R(t+1)+Gamma*R(t+2)+Gamma^2*R(t+3)...,其中R(t+n)表示在t+n时刻的回报
一个例子:k-armed bandit
假设有一台赌博机,一共有k个扳手,按下每个扳手的得奖概率不相同。如何用最少的次数,确定回报最大的扳手并得到最多奖励?
一个最简单的思路是每个扳手试验1000次,估算出获奖概率。大量的重复实验可以较为准确地获得接近真实的概率,但效率显然不是最高。
还有一种思路是先每个试验10次,并在之后一直坚持估算概率最高的扳手(Greedy算法),效率提高但所选的扳手可能不是得奖概率最高的。
改进:选择一个比较小的数
ε(如0.1),然后生成一个0~1之间的随机小数,如果该数小于
ε,则随机挑一个目前看来得奖概率不高的扳手,反之,继续坚持目前概率最高的扳手。该算法称为
ε-greedy算法(关于这些算法性能的比较见下图)
另外的思路:UCB算法(Upper Confidence Bound)。对一个扳手的评估:value+sqrt((2 *total_counts) / counts),value是当前得奖概率,sqr((2 *total_counts) / counts)是对这个扳手的了解程度,total_counts总实验次数,counts是对这个扳手的试验次数。在所有的评估中选最大值进行下一次试验。可以看出,如果一个扳手试验次数比较少,则有很高的概率在下一次被选中。该算法避免随机数,每个值都是可以直接计算出来的,可以让没有机会尝试的扳手得到更多的机会。
各算法的效率如图:
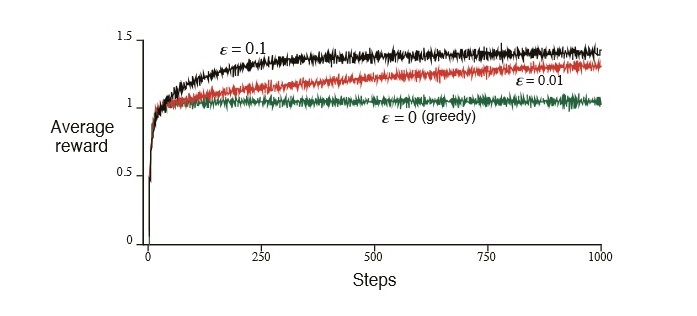
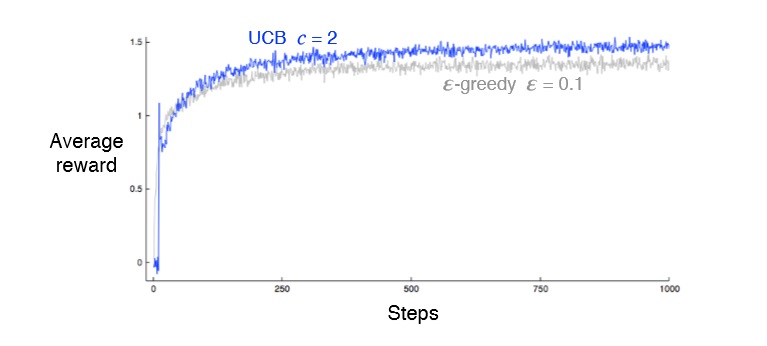
(来源:Reinforcement Learning - An Introduction,CHAPTER 2. MULTI-ARM BANDITS)
以上算法的思想是在exploration和exploitation之间的折衷,在马尔可夫问题中,不可能立刻找到最优的策略,但如何快速收敛是考察问题的重点。
马尔可夫问题求解
主要思想有3类:动态规划(不适用于大型问题),蒙特卡洛方法, Temporal-Difference Learning。其中蒙特卡洛方法与蒙特卡洛搜索树在原理上有相似性,容易被混淆。
Q-Learning属于Temporal-Difference Learning的一种
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1261
1261

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









