






1、什么是支持向量机?
SVM(support vector machine)简单的说是一个分类器,并且是二类分类器。
Vector:通俗说就是点,或是数据。
Machine:也就是classifier,也就是分类器。SVM作为传统机器学习的一个非常重要的分类算法,它是一种通用的前馈网络类型,最早是由Vladimir N.Vapnik 和 Alexey Ya.Chervonenkis在1963年提出,目前的版本(soft margin)是Corinna Cortes 和 Vapnik在1993年提出,1995年发表。深度学习(2012)出现之前,SVM被认为是机器学习中近十几年最成功表现最好的算法。 2、关于wiki
Support Vector Machines are learning models used for classification: which individuals in a population belong where? So… how do SVM and the mysterious “kernel” work?
好吧,故事是这样子的:
在很久以前的一个情人节,大侠要去救他的爱人,但魔鬼和他玩了一个游戏。
魔鬼在桌子上似乎有规律放了两种颜色的球,说:“你用一根棍分开它们?要求:尽量在放更多球之后,仍然适用。”

于是大侠这样放,干的不错?

然后魔鬼,又在桌上放了更多的球,似乎有一个球站错了阵营。

SVM就是试图把棍放在最佳位置,好让在棍的两边有尽可能大的间隙。

现在即使魔鬼放了更多的球,棍仍然是一个好的分界线。

然后,在SVM 工具箱中有另一个更加重要的 trick。 魔鬼看到大侠已经学会了一个trick,于是魔鬼给了大侠一个新的挑战。

现在,大侠没有棍可以很好帮他分开两种球了,现在怎么办呢?当然像所有武侠片中一样大侠桌子一拍,球飞到空中。然后,凭借大侠的轻功,大侠抓起一张纸,插到了两种球的中间。

现在,从魔鬼的角度看这些球,这些球看起来像是被一条曲线分开了。注意此时离这个曲面最近的红色球和蓝色球就是Support Vector

把这些球叫做 data
棍子叫做 classifier
最大间隙trick 叫做optimization
拍桌子叫做kernelling
那张纸叫做hyperplane
以上来自https://www.zhihu.com/question/21094489
支持向量机涉及的相关数学问题
1、关于线性可分和线性不可分
线性可分-linearly separable, 在二维空间可以理解为可以用一条直线(一个函数)把两类型的样本隔开,被隔离开来的两类样本即为线性可分样本。同理在高维空间,可以理解为可以被一个曲面(高维函数)隔开的两类样本。
线性不可分,则可以理解为自变量和因变量之间的关系不是线性的。
实际上,线性可不分的情况更多,但是即使是非线性的样本通常也是通过高斯核函数将其映射到高维空间,在高维空间非线性的问题转化为线性可分的问题。
2、关于函数间隔和几何间隔
-
函数间隔functional margin: 给定一个训练样本
有:
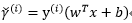
函数间隔代表了特征是正例或是反例的确信度。
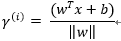
向量点到超平面的距离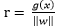
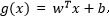
3、关于超平面分析与几何间隔详解
前面已经对SVM的原理有了一个大概的了解,并且简单介绍了函数间隔和几何间隔的概念,为了更好的理解线性可分模式下超平面,以下将进行深入的剖析推导过程,我们假设有训练样本集,期望的响应为,这里我们用类+1和类-1来代表,以表明样本是线性可分的。
决策曲面方程如下:
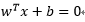
其中
x:输入向量,也就是样本集合中的向量;
w:是可调权值向量,每个向量可调权值;
T:转置,向量的转置;
b:偏置,超平面相对原点的偏移。
根据逻辑回归定义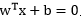
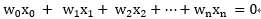
其中假设约定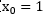
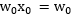
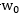
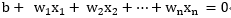
而
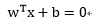
这里假设模式线性可分:
线性可分模式下最优超平面的示意图如下:
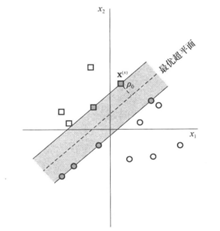
如上图所示:
为分离边缘,即超平面和最近数据点的间隔。如果一个平面能使
最大,则为最优超平面。
- 灰色的方形点和原形点就是我们所说的支持向量。
假设和向量和偏置的最优解,则最优超平面的函数为:
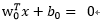
相应的判别函数是:
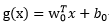
以下是点x到最优超平面的二维示意图:
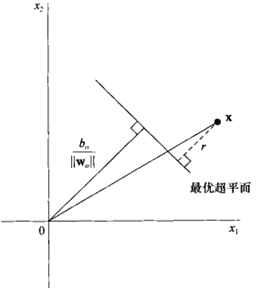
由上图可知r 为点x到最优超平面的距离:
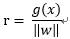
那么代数距离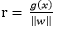
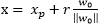
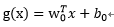
可以得到r,其中:
为x在最优超平面的正轴投影,
因为
在平面上
下面给出一种更为简单且直观的理解:
首先我们必须要知道Euclidean norm范数,即欧几里德范数(以下用w表示多维的向量):
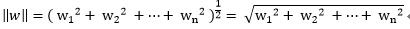
再参考点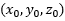
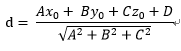
也就是
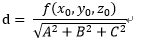
类似的,扩展到多维的w向量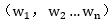
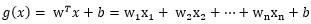
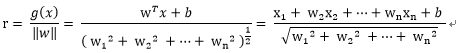
对比点平面的公式,以上的r也就多维度空间向量的到最优超平面的距离。
再看上图,如果x = 0 即原点则有
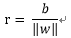
那么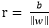
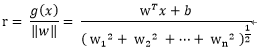
因为x = 0,它在原点,它与任意可调权值向量w相乘都等于0,于是有:
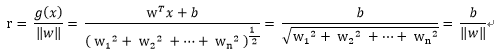
注意b为偏置,只是决定了决策曲面相对原点的偏离,结合上图我们可知道:
- b > 0 则原点在最优超平面的正面;
- b < 0 则原点在最优超平面的负面;
- b = 0 则原点就在最优超平面上。
找到的这个最优超平面的参数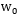
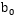
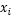
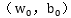
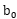
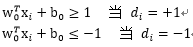
满足上式的点就是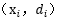
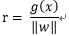
在超平面的正面和负面我们有任一支持向量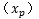
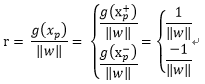
如果让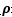
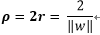
所以我们可以看出,如果要使得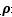
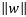
最大化两个类之间的分离边缘等价于最小化权值向量w的欧几里得范数。
4、关于二次最优化
回头看我们前面提到的,给定一个训练集,我们的需求就是尝试找到一个决策边界使得几何间隔最大,回归到问题的本质那就是我们如何找到这个最大的几何间隔? 要想要最大化间隔(margin),正如上面提到的:
最大化两个类之间的分离边缘等价于最小化权值向量w的欧几里得范数。
即:
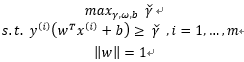
其中: 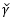
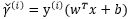
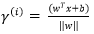
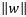
或是将优化的问题转化为以下式子:
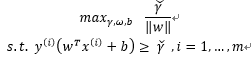
其中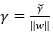
我们发现以上两个式子都可以表示最大化间隔的优化问题,但是我们同时也发现无论上面哪个式子都是非凸的,并没有现成的可用的软件来解决这两种形式的优化问题。
于是一个行之有效的优化问题的形式被提出来,注意它是一个凸函数形式,如下:
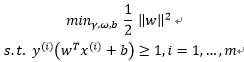
以上的优化问题包含了一个凸二次优化对象并且线性可分,概括来说就是需找最优超平面的二次最优化,这个优化的问题可以用商业的凸二次规划代码来解。
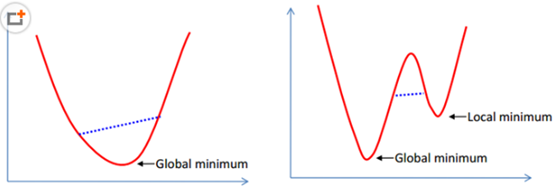
凸函数:
在凸集中任取两个点连成一条直线,这条直线上的点仍然在这个集合内部,左边
凸函数局部最优就是全局最优,而右边的非凸函数的局部最优就不是全局最优了。















 1805
1805











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









