







参考博客:
https://blog.csdn.net/weixin_42306148/category_11116486.html
P6-P7 数据加载
关于 Dataset 数据加载
dataset 和 dataloader
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-relCLzsG-1679482636672)(C:\Users\23972\AppData\Roaming\Typora\typora-user-images\image-20230319210205720.png)]](https://i-blog.csdnimg.cn/blog_migrate/c305ce88042fbc0298bf31947b2a79c4.png)
-
如何理解数据的加载呢?
- 就是说,要想获取自己电脑里的数据,读取它,那么就要遵守 pytorch 加载数据的规则。
- 他的规则就是 定义一个class类,继承 Dataset (from torch.utils.data import Dataset),并且,在类中,定义三个函数,分别是:初始化 init、获得每一个数据 getitem、数据长度 len。
- 这里面的过程,要很清楚:
- 1、路径、合并路径、把文件夹中的每一个文件名称,做成一个列表(这是init要做的事情);
- 2、访问init中的列表,把列表的名称逐一传递给一个变量,命名为name,再次合并路径,并且把文件名连接在路径之后,接下来,用PIL中的Image.open函数,读取(加载)上述路径的文件(命名为img)(这里肯定是图像了),返回 图像img和标签 label(这是getitem的工作);
- 3、最后用len()返回列表的长度。
- 定义好 类 以后,后面就可以实例化这个类,定义参数(本例其实是一个路径,一个夹名称了),名称可以和定义类中的不一样,但是位置要对应(奥,这可能是Python课程里说的位置参数?)。
- 引用之前定义的类,把上述参数,传递进去。
- 最后打印自定义数据列表的长度。
常见的数据集的三种形式
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fDJmLVzc-1679482636674)(C:\Users\23972\AppData\Roaming\Typora\typora-user-images\image-20230319210348474.png)]](https://i-blog.csdnimg.cn/blog_migrate/d5fb202020fc32a85d2802719b157cbd.png)
可运行的代码
import os
from PIL import Image
from torch.utils.data import Dataset
# dataset有两个作用:1、加载每一个数据,并获取其label;2、用len()查看数据集的长度
class MyData(Dataset):
def __init__(self, root_dir, label_dir): # 初始化,为这个函数用来设置在类中的全局变量
self.root_dir = root_dir
self.label_dir = label_dir
self.path = os.path.join(self.root_dir,self.label_dir) # 单纯的连接起来而已,背下来怎么用就好了,因为在win下和linux下的斜线方向不一样,所以用这个函数来连接路径
self.img_path = os.listdir(self.path) # img_path 的返回值,就已经是一个列表了
def __getitem__(self, idx): # 获取数据对应的 label
img_name = self.img_path[idx] # img_name 在上一个函数的最后,返回就是一个列表了
img_item_path = os.path.join(self.root_dir, self.label_dir, img_name) # 这行的返回,是一个图片的路径,加上图片的名称了,能够直接定位到某一张图片了
img = Image.open(img_item_path) # 这个步骤看来是不可缺少的,要想 show 或者 操作图片之前,必须要把图片打开(读取),也就是 Image.open()一下,这可能是 PIL 这个类型图片的特有操作
label = self.label_dir # 这个例子中,比较特殊,因为图片的 label 值,就是图片所在上一级的目录
return img, label # img 是每一张图片的名称,根据这个名称,就可以使用查看(直接img)、print、size等功能
# label 是这个图片的标签,在当前这个类中,标签,就是只文件夹名称,因为我们就是这样定义的
def __len__(self):
return len(self.img_path) # img_path,已经是一个列表了,len()就是在对这个列表进行一些操作
if __name__ == '__main__':
root_dir = "F:\\PhD\\01-Python_In_One\\Project\\【B_up】XiaoTuDui\\data\\train"
# root_dir = "data/train"
ants_label_dir = "ants_image"
bees_label_dir = "bees_image"
ants_dataset = MyData(root_dir, ants_label_dir)
bees_dataset = MyData(root_dir, bees_label_dir)
train_dataset = ants_dataset + bees_dataset
完整代码 P6-7_read_data.py
# from torch.utils.tensorboard import SummaryWriter
# !usr/bin/env python3
# -*- coding:utf-8 -*-
"""
author :24nemo
date :2021年07月12日
"""
'''
Dataset:
能把数据进行编号
提供一种方式,获取数据,及其label,实现两个功能:
1、如何获取每一个数据,及其label
2、告诉我们总共有多少个数据
数据集的组织形式,有两种方式:
1、文件夹的名字,就是数据的label
2、文件名和label,分别处在两个文件夹中,label可以用txt的格式进行存储
在jupyter中,可以查看,help,两个方式:
1、help(Dataset)
2、Dataset??
Dataloader:
为网络提供不同的数据形式,比如将0、1、2、3进行打包
这一节内容很重要
'''
'''
# writer = SummaryWriter("logs")
class MyData(Dataset):
def __init__(self, root_dir, image_dir, label_dir, transform):
# 初始化,为这个函数用来设置在类中的全局变量
self.root_dir = root_dir
self.image_dir = image_dir
self.label_dir = label_dir
self.label_path = os.path.join(self.root_dir, self.label_dir)
self.image_path = os.path.join(self.root_dir, self.image_dir)
self.image_list = os.listdir(self.image_path)
self.label_list = os.listdir(self.label_path)
self.transform = transform
# 因为 label 和 Image文件名相同,进行一样的排序,可以保证取出的数据和label是一一对应的
self.image_list.sort()
self.label_list.sort()
def __getitem__(self, idx):
img_name = self.image_list[idx]
label_name = self.label_list[idx]
img_item_path = os.path.join(self.root_dir, self.image_dir, img_name)
label_item_path = os.path.join(self.root_dir, self.label_dir, label_name)
img = Image.open(img_item_path)
with open(label_item_path, 'r') as f:
label = f.readline()
# img = np.array(img)
img = self.transform(img)
sample = {'img': img, 'label': label}
return sample
def __len__(self):
# assert len(self.image_list) == len(self.label_list)
return len(self.image_list)
if __name__ == '__main__':
transform = transforms.Compose([transforms.Resize((256, 256)), transforms.ToTensor()])
root_dir = "dataset/train"
image_ants = "ants_image"
label_ants = "ants_label"
ants_dataset = MyData(root_dir, image_ants, label_ants, transform)
image_bees = "bees_image"
label_bees = "bees_label"
bees_dataset = MyData(root_dir, image_bees, label_bees, transform)
train_dataset = ants_dataset + bees_dataset
# transforms = transforms.Compose([transforms.Resize(256, 256)])
dataloader = DataLoader(train_dataset, batch_size=1, num_workers=2)
# writer.add_image('error', train_dataset[119]['img'])
# writer.close()
# for i, j in enumerate(dataloader):
# # imgs, labels = j
# print(type(j))
# print(i, j['img'].shape)
# # writer.add_image("train_data_b2", make_grid(j['img']), i)
# writer.close()
# jupyter notebook 等方法,可以查看 help
'''
'''
以下内容是视频中完全一样的代码,截图,在 20210713 的笔记中,包括 python console 的代码也有保存
'''
P8-9 Tensorboard使用
完整笔记
-
使用这个工具,可以看到具体某一步骤时的输入和输出。

-
需要指定一个文件夹,把创建的事件文件存下来。这是Summarywriter的init当中做的。
-
还有其他参数可以设置,略了。
- 一般使用这两个方法:

注意add_scalar里面的参数,代表了图中横纵坐标的轴名称(global_step为横坐标、scalar_value为纵坐标):

- 一般使用这两个方法:
-
举例子:SummaryWriter是个class,需要将它实例化:

-
如何打开浏览器看图?
Port那里是为了避免跟别人冲突,自己定义一个数值【端口冲突】:

-
如果出现“刷新之后产生了以外变化”,就把原来的logs文件夹删掉,重新运行就好了:
-
在summarywrite上执行的新的操作就会生成一个新的log文件,所以如果针对同一个log_dir有多个操作的话,不同操作之间的接壤处会产生拟合现象。
-

-
add_image方法的使用:注意输入类型的要求:
print(type(img)),PIL读取的类型不行;
-
-
视频中,用PIL转成了numpy类型作为输入了。

-
以上代码出的问题是:通道(H,W,C)需要转换:
那个20行最后一个参数 dataformats 可以把这个顺序转换过来。
可以运行的代码
# !usr/bin/env python3
# -*- coding:utf-8 -*-
"""
author :24nemo
date :2021年07月07日
"""
import numpy as np
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter("logs")
image_path = "data/train/ants_image/6240329_72c01e663e.jpg"
img_PIL = Image.open(image_path)
img_array = np.array(img_PIL)
print(type(img_array))
print(img_array.shape)
writer.add_image("train", img_array, 1, dataformats='HWC') # 数字 1 代表一共有几个步骤,网页中会出现滑块,可以拖动
# y = 2x
for i in range(100):
writer.add_scalar("y=2x", 3 * i, i)
# writer.add_scalar("y=x^2", i**2, i)
writer.close()
'''
终端:
tensorboard --logdir=logs --port=6007
## 【【【将logs的路径换为绝对路径】】】
logs文件可以删除,重新运行
'''
## 完整目录
- [P6-P7 数据加载](https://blog.csdn.net/weixin_42306148/article/details/123240796?spm=1001.2014.3001.5501)
- [P8-9 Tensorboard使用](https://blog.csdn.net/weixin_42306148/article/details/123363465?spm=1001.2014.3001.5501)
- [P10-11 Transform的用法](https://blog.csdn.net/weixin_42306148/article/details/123363623?spm=1001.2014.3001.5501)
- [P12-13 常用的tranforms](https://blog.csdn.net/weixin_42306148/article/details/123363722?spm=1001.2014.3001.5501)
- [P14 torchvision中的数据集的使用](https://blog.csdn.net/weixin_42306148/article/details/123363855?spm=1001.2014.3001.5501)
- [P15 dataloader的使用](https://blog.csdn.net/weixin_42306148/article/details/123363917?spm=1001.2014.3001.5501)
- [P16 nn.Module](https://blog.csdn.net/weixin_42306148/article/details/123363946?spm=1001.2014.3001.5501)
- [P17 卷积](https://blog.csdn.net/weixin_42306148/article/details/123363982?spm=1001.2014.3001.5501)
- [P18 卷积层使用](https://blog.csdn.net/weixin_42306148/article/details/123364030?spm=1001.2014.3001.5501)
- [P19 池化](https://blog.csdn.net/weixin_42306148/article/details/123364108?spm=1001.2014.3001.5501)
- [P20 ReLU](https://blog.csdn.net/weixin_42306148/article/details/123364138?spm=1001.2014.3001.5501)
- [P21线性层和其它层](https://blog.csdn.net/weixin_42306148/article/details/123364409?spm=1001.2014.3001.5501)
- [P22 squential和小实战](https://blog.csdn.net/weixin_42306148/article/details/123364481?spm=1001.2014.3001.5501)
- [P23 loss function](https://blog.csdn.net/weixin_42306148/article/details/123364558?spm=1001.2014.3001.5501)
- [P24 优化器](https://blog.csdn.net/weixin_42306148/article/details/123364628?spm=1001.2014.3001.5501)
- [P25 pytorch中现有模型](https://blog.csdn.net/weixin_42306148/article/details/123364730?spm=1001.2014.3001.5501)
- [P26 网络模型的保存和加载](https://blog.csdn.net/weixin_42306148/article/details/123364775?spm=1001.2014.3001.5501)
- [P27、28、29 完整的模型套路](https://blog.csdn.net/weixin_42306148/article/details/123364846?spm=1001.2014.3001.5501)
- [P30 GPU加速](https://blog.csdn.net/weixin_42306148/article/details/123364938?spm=1001.2014.3001.5501)
- [P31 GPU加速_2](https://blog.csdn.net/weixin_42306148/article/details/123364998?spm=1001.2014.3001.5501)
- [P32 完整的模型验证套路](https://blog.csdn.net/weixin_42306148/article/details/123365042?spm=1001.2014.3001.5501)
- [P33 github的使用](https://blog.csdn.net/weixin_42306148/article/details/123365062?spm=1001.2014.3001.5501)
P10-11 Transform的用法
- 他就是一个.py的模块,里面有很多工具,可以理解为一个工具箱
查看transform的structure
-
查看transform的structure[pycharm左下边],看看他们都有什么内容

-
常用的有**ToTensor、ToPILImage这些class**,tranform是工具箱,这些class是工具,用来加工数据(比如图片)

Transform的用法:


为什么要用tensor数据类型:
先看ndarray类型:
1、左边输入import cv2,给他一个图片的地址 img_path;
2、看到右边的cv_img的数据类型变成了ndarray了。
3、这样的类型,**就可以作为tranform.Tensor()的输入**了(要求这两种类型PIL和ndarray,也对应了PIL库和opencv库)。
我们需要的输入格式一般就是PIL Image 和 numpy.ndarry 两种,对应的就是from PIL import Image 和 import cv2


实例全部内容:

可以运行的代码
# !usr/bin/env python3
# -*- coding:utf-8 -*-
"""
author :24nemo
date :2021年07月07日
"""
# 这个模块里面的代码,没有在P10-11中敲,可能是后面的敲的
import os
from PIL import Image
from torch.utils.data import Dataset
from torchvision import transforms
class MyData(Dataset):
def __init__(self, root_dir, image_dir, label_dir, transform=None):
self.root_dir = root_dir
self.image_dir = image_dir
self.label_dir = label_dir
self.label_path = os.path.join(self.root_dir, self.label_dir)
self.image_path = os.path.join(self.root_dir, self.image_dir)
self.image_list = os.listdir(self.image_path)
self.label_list = os.listdir(self.label_path)
self.transform = transform
# 因为label 和 Image 文件名相同,进行一样的排序,可以保证取出的数据和label是一一对应的
self.image_list.sort()
self.label_list.sort()
def __getitem__(self, idx):
img_name = self.image_list[idx]
label_name = self.label_list[idx]
img_item_path = os.path.join(self.root_dir, self.image_dir, img_name)
label_item_path = os.path.join(self.root_dir, self.label_dir, label_name)
img = Image.open(img_item_path)
with open(label_item_path, 'r') as f:
label = f.readline()
if self.transform:
img = transform(img)
return img, label
def __len__(self):
assert len(self.image_list) == len(self.label_list)
return len(self.image_list)
transform = transforms.Compose([transforms.Resize(400), transforms.ToTensor()])
root_dir = "D:\\Python_In_One\\Project\\XiaoTuDui\\data\\train"
image_ants = "ants_image"
label_ants = "ants_label"
ants_dataset = MyData(root_dir, image_ants, label_ants, transform=transform)
image_bees = "bees_image"
label_bees = "bees_label"
bees_dataset = MyData(root_dir, image_bees, label_bees, transform=transform)

★方法讲解
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
write = SummaryWriter("logs")
img = Image.open("../images/微信图片_20220621163018.jpg")
print(img)
# ToTensor
trans_totensor = transforms.ToTensor()
img_tensor = trans_totensor(img)
write.add_image("ToTensor", img_tensor)
# Normalize
print(img_tensor[0][0][0])
tran_norm = transforms.Normalize([0.5,0.5,0.5],[0.5,0.5,0.5])
img_norm = tran_norm(img_tensor)
print(img_norm[0][0][0])
write.add_image("normalize",img_norm)
#
print(img.size)
tran_resize = transforms.Resize((218,218))
# img PIL -> resize -> img_resize PIL
img_resize = tran_resize(img)
img_resize = trans_totensor(img_resize)
# img PIL -> trans_totensor -> img_resize tensor
write.add_image("Resize", img_resize,0)
print(img_resize)
# compose
# compose就是将函数进行组合(流水线工作--前一个函数的输出是下一个函数的输入,减少代码量)。同比例缩放只要resize里续一个数字就行
tran_resize_2 = transforms.Resize(512) # 同比例缩放只要resize里续一个数字就行
trans_compose = transforms.Compose([tran_resize_2,trans_totensor]) # 可以交换顺序,resize的tensor和PIL都可以
# trans_compose = transforms.Compose([trans_totensor,tran_resize_2])
img_resize_2 = trans_compose(img)
write.add_image("resize",img_resize_2,1)
# RandomCrop
trans_random = transforms.RandomCrop(512) # 这里的int不是等比例缩放,而是==resize(512,512)
trans_compose_2 = transforms.Compose([trans_random,trans_totensor])
for i in range(10):
img_crop = trans_compose_2(img)
write.add_image("randomcrop",img_crop,i)
write.close()
P14 torchvision中的数据集的使用
pytorch官网 正对文本的数据集:https://pytorch.org/text/stable/index.html
-
P14 torchvision中的数据集的使用
这个数据集,就在torchvision.dataset.CIFAR10…这个母子文件中

-
**数据类型的预处理,**可以建立一个工具,再放进dataset当中:(第12行是工具,16行中,引用了这个工具),将原来的PIL(CIFAR10默认类型)转为了tensor类型:

-
数据集当中,有的会加入下载地址,在线下载太慢的话,可以找一找,用别的方法下载。(迅雷直接复制链接下载,导入预设置的路径之后 运行命令可以自行解压)
-

可以运行的结果
# !usr/bin/env python3
# -*- coding:utf-8 -*-
"""
author :24nemo
date :2021年07月07日
"""
import torchvision
from torch.utils.tensorboard import SummaryWriter
dataset_transform = torchvision.transforms.Compose([torchvision.transforms.ToTensor()])
# 后面要对数据做一个预处理,做一次transform的变化,这里的意思是,先建立一个工具,在后面的dataset当中,加入这个工具,直接就可以做预处理了,本例是将原始数据转为tensor类型
# CIFAR数据集中的数据,类型是PIL,需要转为tensor,才能进行处理
train_set = torchvision.datasets.CIFAR10(root="./dataset", train=True, transform=dataset_transform, download=True)
# train_set = torchvision.datasets.CIFAR10(root="./dataset", train=True, transform=dataset_transform, download=False)
test_set = torchvision.datasets.CIFAR10(root="./dataset", train=False, transform=dataset_transform, download=True)
# test_set = torchvision.datasets.CIFAR10(root="./dataset", train=False, transform=dataset_transform, download=False)
print(test_set[0])
print(test_set.classes)
img, target = test_set[0]
print(img)
print(target)
print(test_set.classes[target])
img.show()
print(test_set[0])
writer = SummaryWriter("p10")
for i in range(10):
img, target = test_set[i]
writer.add_image("test_set", img, i)
writer.close()
P15 dataloader的使用
dataloader与dataset

dataloader 就是控制**在dataset得到的数据集中如何拿数据的方式**(通过其参数)
dataloader参数

-
dataset :就是我们上节设置的dataset
-
batch_size :每次抓牌的数目
-
shuffle:是否迭代的时候打乱顺序,默认情况设置为false,但是我们一般将其设置为true,即为第二局的时候牌的顺序是一样的
-
num_work: 多进程,默认情况设置为0即为设置为主进程(单进程)进行加载,
- 设置报错(broken pipe)可能是因为设置的数字太高了。电脑性能不支持可以0逐步开始加

- 设置报错(broken pipe)可能是因为设置的数字太高了。电脑性能不支持可以0逐步开始加
-
drop_last: 即为如果我们一副牌有100张,每次取3张,经过多轮后最后一张是否还取的问题。设置为true就是不取,
-
CIFAR数据集的固定返回内容:

可以运行的代码
# !usr/bin/env python3
# -*- coding:utf-8 -*-
"""
author :24nemo
date :2021年07月07日
"""
import torchvision
# 准备的测试数据集
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
test_data = torchvision.datasets.CIFAR10("./dataset", train=False, transform=torchvision.transforms.ToTensor())
test_loader = DataLoader(dataset=test_data, batch_size=4, shuffle=True, num_workers=0, drop_last=True)
# 测试数据集中第一张图片及target
img, target = test_data[0]
print(img.shape) # torch.Size([3, 32, 32]) 单张图片的尺寸和通道数
print(target) # 输出为 3
writer = SummaryWriter("dataloader")
# 测试数据集上所有的图片 imgs 是复数
for epoch in range(2): # 进行两轮,上面的 shuffle,是对这个位置有影响,而不是 for data 那个循环有影响
step = 0
for data in test_loader: # 这个loader,返回的内容,就已经是包含了 img 和 target 两个值了,这个在 cifar 数据集的 getitem 函数里,写了
imgs, targets = data
# print(imgs.shape) # torch.Size([4, 3, 32, 32]) 这个输出的结果,其中的 4 ,是 batch_size 设定的值, 后面的 3, 32, 32 是单张图片的尺寸和通道数
# print(targets) # tensor([2, 8, 0, 2]) 这4个数字,是对 target 的打包,是随机的,数值代表所在的分类;debug一下,可以看到 sampler中的取值方式,是 RandomSampler
# 随机从 Data 中,抓取 4 个数据
writer.add_images("Epoch: {}".format(epoch), imgs, step)
step = step + 1
writer.close()



P16 神经网络的基本骨架–nn.Module
torch.nn

-
Containers : 搭建一个神经网络的骨架。骨架搭好了之后,就向里面填充东西。
- Convolution Layers :卷积层---- 》 DataParallel Layers (multi-GPU, distributed) 数据并行层(多GPU,分布式)
-
注意这个module在哪里:把结构摆出来,然后自己重写里面两个方法,就可以用了:

-
里面的forward函数,就是一个单纯的前向传播:
-

-
forward函数内部原理
-
-

可以运行的代码
# !usr/bin/env python3
# -*- coding:utf-8 -*-
"""
author :24nemo
date :2021年07月07日
"""
'''
这个部分的重点,在于了解 nn.Module 的使用,找好 官网上的 位置,注意以下 import 的内容,和 nn 与 torch 的关系
我不能 debug ,所以没有体会一次这个过程,之前不能用debug的原因,是numpy和python的版本不对齐,原来是pyhton3.6,而装了numpy1.9,我重新安装了numpy1.5.1就可以用了
'''
'''
以下是视频中的代码,另外把 官网上的代码敲一遍。这部分很重要的,还需要再看,了解清楚输入和调用神经网络模型的步骤,视频第15分钟的时候,再看看,尤其是调用forward的时候
'''
import torch
from torch import nn
class Tudui(nn.Module):
def __init__(self): # 这里是有操作的,code -> generate -> override methods -> --init__(self.Module) 可以快速重写这部分内容补全
super().__init__()
def forward(self, input):
output = input + 23
return output
tudui = Tudui() # 用 Tudui 为模板,创建的神经网络实例
x = torch.tensor(1.0) # 这一步,处理x,使其成为 tensor 形式,这里不仅可以输入数字,还可以是图像或者其他内容
output = tudui(x) # 这一步是把 x 放进神经网络当中,命名为 output
print(output)
P17 卷积
卷积
-
在torch.nn.function当中,能够看到跟视频一样的结果,所以,要对torch官网很熟悉,经常去查:
- torch.nn其实就可以理解为torch.nn.function的封装,所以使用原理我们可以去torch.nn.function,但是实际上我们学会torch.nn就可以了。
-
卷积就是一个滤波器
-
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Fp3rMFjO-1679482636699)(C:\Users\23972\AppData\Roaming\Typora\typora-user-images\image-20230321104450078.png)]](https://i-blog.csdnimg.cn/blog_migrate/0c39db1d1bb1e327412a89bd3e7308e9.png)
- stride: 步长, stride – the stride of the convolving kernel. Can be a single number:横向和纵向的步长一致 or a tuple (sH, sW):同时分别控制横向和纵向的步长. Default: 1
- padding –: implicit paddings on both sides of the input. Can be a string {‘valid’, ‘same’}, single number or a tuple (padH, padW). Default: 0
padding='valid'is the same as no padding.padding='same'pads the input so the output has the same shape as the input. However, this mode doesn’t support any stride values other than 1.- 四周边缘填充,可以让卷积后的大小不变【补零或者对称】
- padding的大小一般是卷积核大小的一半向下取整。
- 四周边缘填充,可以让卷积后的大小不变【补零或者对称】
- as打的
- stride: 步长, stride – the stride of the convolving kernel. Can be a single number:横向和纵向的步长一致 or a tuple (sH, sW):同时分别控制横向和纵向的步长. Default: 1
-
torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True, padding_mode=‘zeros’, device=None, dtype=None)
- in_channels, out_channels 输入输出的通道数
- 输出的通道数等于卷积核数乘以输入通道数
-

- 卷积核内的具体数值是随机取的,不需要初始化,给出卷积核大小即可,卷积核的具体的数值是通过学习得到的,
- 但是卷积核也可以人工初始化,有时候会收敛好点,设置卷积核有种子函数seed()
- kernel_size 卷积核的大小
- stride=1 步长为1
- padding=0 用0来填充,使得卷积操作之后大小不变
- dilation=1 控制内核点之间的间距;也称为àtrous算法。这很难描述,但这个链接很好地展示了扩张的作用。
- groups=1 很少改动,改动就是分组卷积
- bias=True 偏置常年设置为true,是否对卷积之后的结果加上一个常数
- padding_mode=‘zeros’, 在选择padding进行填充的时候,这里设置其按照什么模式进行填充
- device=None
- in_channels, out_channels 输入输出的通道数
-
代码中说的,kernel和input的四个参数,含义不一样了,指的是这个:

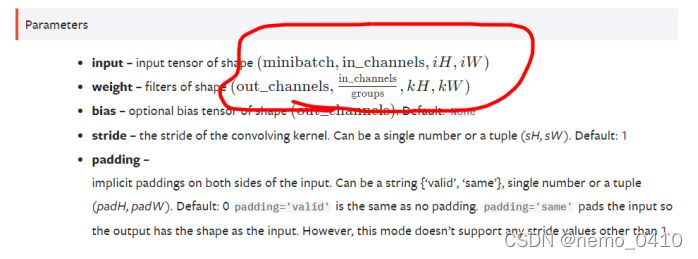
可以运行的代码
# !usr/bin/env python3
# -*- coding:utf-8 -*-
"""
author :24nemo
date :2021年07月07日
"""
'''
torch.nn 和 torch.nn.functional 是包含关系,functional 指的是具体的函数源代码,而 torch.nn 是封装好的,可以直接使用
他们的区别,从conv的大小写(Conv和conv),也能看出来。而且,torch.nn.functional中,带着 functional,torch.nn 是不用加的
本节的内容,都是结合torch.nn.functional 实现的,具体的查看 :
https://pytorch.org/docs/stable/generated/torch.nn.functional.conv2d.html#torch.nn.functional.conv2d
具体的函数,以及参数,都有讲到
torch.nn.functional.conv2d(input, weight, bias=None, stride=1, padding=0, dilation=1, groups=1) → Tensor
'''
import torch
import torch.nn.functional as F # 制作一个函数的句柄,后面方便直接使用了
input = torch.tensor([[1, 2, 0, 3, 1],
[0, 1, 2, 3, 1],
[1, 2, 1, 0, 0],
[5, 2, 3, 1, 1],
[2, 1, 0, 1, 1]])
kernel = torch.tensor([[1, 2, 1],
[0, 1, 0],
[2, 1, 0]])
print("input:", input)
print("kernel:", kernel)
print("input.shape:", input.shape)
print("kernel.shape:", kernel.shape)
# 要想用 torch.nn.functional.conv2d 这个函数,就必须满足形状的要求,上述的尺寸不满足,要做处理
# 上述的尺寸,只有input.shape: torch.Size([5, 5]), kernel.shape: torch.Size([3, 3]),并没有4个通道
input = torch.reshape(input, (1, 1, 5, 5)) # 注意这4个数字的意义,分别是:batch_size, in_channel, H, W , 变换形状之后,重新赋值给 input
# 【batch_size就是批次大小(每次送入网络的图片数量),channel数是定义几维数据的】
kernel = torch.reshape(kernel, (1, 1, 3, 3)) # 注意这4个数字的意义,跟上面的不一样了
print("input.shape:", input.shape)
print("kernel.shape:", kernel.shape)
output = F.conv2d(inpu t, kernel, stride=1)
print(output)
output2 = F.conv2d(input, kernel, stride=2)
print(output2)
output3 = F.conv2d(input, kernel, stride=1, padding=1) # padding 设置的值,是往外扩充的行列数,值都是0,至于想要修改这个值,还有另外一个参数,一般不改
# 【我们会发现输出的tensor是四维的,因为reshape后的即input就是四维tensor了,那么输出自然也是四维的】
print(output3)
output4 = F.conv2d(input, kernel, stride=1, padding=0) # padding 默认值是 0
print(output4)
P18 卷积层使用
卷积层使用
- 看到 CONV2D是大写的字母,就应该知道这个网页是在哪里[torch.nn]:我之前说要回头看怎么做卷积的,就是在这里看到的:

- 上图中有一个link,里面有:

- 参数介绍:其中kernel可以选择其他形状的,在kernel_size中的tuple,可以自己设置特殊的形状:

关于channel
- 当图像是1个channel,而kernel是两个:于是,当input不止一个channel,kernel也不止一个,那么需要训练的东西就多了:
in_channels, out_channels 输入输出的通道数
- 输出的通道数等于卷积核数乘以输入通道数
-
- 卷积核内的具体数值是随机取的,不需要初始化,给出卷积核大小即可,卷积核的具体的数值是通过学习得到的,
- 但是卷积核也可以人工初始化,有时候会收敛好点,设置卷积核有种子函数seed()
真是清清爽爽:

- 为了看,输入和输出的channel变化:(28-29行):batch_size都是64,没有变化,输入是3channel,输出是6channel,通道数多了,但是尺寸变小了,这就是卷积的作用和处理结果:


- 根据这个公式去计算,里面的padding和stride,以及channel和batch_size:他们之间是有一个方程关系的,能够严格计算出来:

-
卷积过程中 通道数目的reshape
-
step = 0 for data in dataloader: imgs, targets = data output = tudui(imgs) print(imgs.shape) # torch.Size([64, 3, 32, 32]) print(output.shape) # torch.Size([64, 6, 30, 30]) writer.add_images("input", imgs, step) # torch.Size([64, 6, 30, 30]) -> [xxx, 3, 30, 30] output = torch.reshape(output, (-1, 3, 30, 30)) # 【【【batch_size设置为-1 后期系统自动计算出来】】】 print(output.shape) # 我们设置reshape之后的得到的是一个out_channels=3,大小为(30,30)的输出,而输出的个数也就是其batch_size系统会自动计算出来 writer.add_images("output", output, step) step = step + 1 -
结果如下
torch.Size([64, 3, 32, 32]) torch.Size([64, 6, 30, 30]) torch.Size([128, 3, 30, 30])
-
-
Vgg的框架,他的输出跟输入(前两层)是一样的大小,所以应该是做了padding来保证的:
- 1*1的卷积用作全连接


可以运行的代码
# !usr/bin/env python3
# -*- coding:utf-8 -*-
"""
author :24nemo
date :2021年07月07日
"""
'''
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("../dataset", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
dataloader = DataLoader(dataset, batch_size=64)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.conv1 = Conv2d(in_channels=3, out_channels=6, kernel_size=3, stride=1, padding=0)
def forward(self, x):
x = self.conv1(x)
return x
tudui = Tudui()
writer = SummaryWriter("../logs")
step = 0
for data in dataloader:
imgs, targets = data
output = tudui(imgs)
print(imgs.shape)
print(output.shape)
# torch.Size([64, 3, 32, 32])
writer.add_images("input", imgs, step)
# torch.Size([64, 6, 30, 30]) -> [xxx, 3, 30, 30]
output = torch.reshape(output, (-1, 3, 30, 30))
writer.add_images("output", output, step)
step = step + 1
'''
'''
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d
from torch.utils.data import DataLoader
dataset = torchvision.datasets.CIFAR10("../data", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
dataloader = DataLoader(dataset, batch_size=64)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.conv1 = Conv2d(in_channels=3, out_channels=6, kernel_size=3, stride=1, padding=0) # 初始化中,有一个卷积层
def forward(self, x):
x = self.conv1(x) # x 已经放到了卷积层 conv1当中了
return x
tudui = Tudui() # 初始化网络
print(tudui)
# 下面把每一张图像都进行卷积
for data in dataloader:
imgs, targets = data # data 由 imgs 和 targets 组成的,已经获得了图片,并且经过了 ToTensor的转换,已经是tensor类型,可以直接放进 网络 当中
# 疑问,targets 是什么? 为什么 data 由 imgs 和 targets 共同组成?前面有?
output = tudui(imgs)
print(imgs.shape) # 输出的结果为 torch.Size([64, 6, 30, 30]), torch.Size([64, 6, 30, 30])
print(output.shape) # 其中的 64,就是指的 DataLoader 中的 batch_size = 64
# channel 变成了 6
'''
'''
以下是加入了 logs 的版本
'''
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("../data", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
dataloader = DataLoader(dataset, batch_size=64)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.conv1 = Conv2d(in_channels=3, out_channels=6, kernel_size=3, stride=1, padding=0) # 初始化中,有了一个卷积层
def forward(self, x):
x = self.conv1(x) # x 已经放到了卷积层 conv1当中了
return x
tudui = Tudui() # 初始化网络
print(tudui)
# 下面把每一张图像都进行卷积
writer = SummaryWriter("logs")
step = 0
for data in dataloader:
imgs, targets = data # data 由 imgs 和 targets 组成的,已经获得了图片,并且经过了 ToTensor的转换,已经是tensor类型,可以直接放进 网络 当中
# 疑问,targets 是什么? 为什么 data 由 imgs 和 targets 共同组成?前面有?
output = tudui(imgs)
print("imgs.shape:", imgs.shape) # 输出的结果为 torch.Size([64, 3, 30, 30]), torch.Size([64, 6, 30, 30])
print("output.shape:", output.shape) # 其中的 64,就是指的 DataLoader 中的 batch_size = 64, channel 由 3 变成了 6
# torch.Size([64, 3, 32, 32])
writer.add_images("input", imgs, step)
# torch.Size([64, 6, 30, 30]) 由于 6 个 channel 的图像,是无法显示的,所以,对这个图像进行处理,这里是通过batch_size来调整channel的,理论其实是有些站不住脚的
# torch.Size([xxx, 3, 30, 30])
output = torch.reshape(output, (-1, 3, 30, 30)) # 这个方法不是很严谨,目的是将 batch_size 降低,当不知道设置为多少合适时,设置为 -1 ,后面的参数会自己计算的
writer.add_images("output", output, step)
step += 1
writer.close()
P19 池化
最大池化
池化函数使用某一位置的相邻输出的总体统计特征来代替网络在该位置的输出。本质是 降采样,可以大幅度减少网络的参数量。 浓缩的就是精华
CLASS torch.nn.MaxPool2d(kernel_size, stride=None, padding=0, dilation=1, return_indices=False, ceil_mode=False)

- 池化的卷积核没有参数,只是形式上的卷积核
- dilation
- 可以获得更大的感受野

-
ceil_mode
- ceil向上取整 floor向下取整【ceil:允许有出界部分、floor:不允许】
-

-
结合代码,看pooling需要注意的地方:
stride滑动的默认值,是kernel的大小,跟conv不一样,注意! -
池化过程
-

- 池化函数使用某一位置的相邻输出的总体统计特征来代替网络在该位置的输出。本质是 降采样,可以大幅度减少网络的参数量。
-
-
Pooling这,一般只有一个参数需要设置:

-
最大池化的作用:
- 【【【保留特征的同时,还能减小数据尺寸,加快训练】】
- 往往 卷积之后,加一层池化,再归一化(归一化要在非线性激活也就是激活函数之前),后面再非线性激活,也就是:conv ——> pooling ——> batch normalization ——> relu
- 卷积层用来提取特征,一般有相应特征的位置是比较大的数字,最大池化可以提出来这一部分有信息。
- 池化之后不会有多个channel,池化前后其channel不发生变化。
- 【【【保留特征的同时,还能减小数据尺寸,加快训练】】
-
结果:

可以运行的代码
# !usr/bin/env python3
# -*- coding:utf-8 -*-
"""
author :24nemo
date :2021年07月07日
"""
from torch import nn
from torch.nn.modules.pooling import MaxPool2d
'''
通过官方文档介绍参数,一般只需要设置 kernel size
【【【其中,ceil_mode是一个重要参数,当kernel滑动,省下的位置,不够kernel的大小,那这组数据还要不要,就是通过ceil_mode来选择的】】】
stride滑动的默认值,是kernel的大小,跟conv不一样,注意
'''
import torch
input = torch.tensor([[1, 2, 0, 3, 1],
[0, 1, 2, 3, 1],
[1, 2, 1, 0, 0],
[5, 2, 3, 1, 1],
[2, 1, 0, 1, 1]], dtype=torch.float32) # 这里要指定input的数据类型,否则报错,long(我们处理的一般都是float)
# input = torch.tensor([[1, 2, 0, 3, 1],
# [0, 1, 2, 3, 1],
# [1, 2, 1, 0, 0],
# [5, 2, 3, 1, 1],
# [2, 1, 0, 1, 1]]) # 这里要指定input的数据类型,否则报错,long
input = torch.reshape(input, (-1, 1, 5, 5)) # -1 仍然是让他自己计算batch_size,1是channel数
print("input.shape:", input.shape)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.maxpool1 = MaxPool2d(kernel_size=3, ceil_mode=True)
def forward(self, input):
output = self.maxpool1(input)
return output
tudui = Tudui()
output = tudui(input)
print("output:", output)
'''
这里输出的是:
torch.Size([1, 1, 5, 5])
tensor([[[[2., 3.],
[5., 1.]]]])
当 ceil_mode = False 时,输出就只有:
torch.Size([1, 1, 5, 5])
tensor([[[[2.]]]])
'''
'''
最大池化的作用:
【【【保留特征的同时,还能减小数据尺寸,加快训练】】
往往 卷积之后,加一层池化,再归一化(归一化要在非线性激活也就是激活函数之前),后面再非线性激活,也就是:conv ——> pooling ——> batch normalization ——> relu
'''
'''
还有其他的内容,见上面代码,比如tensorboard显示处理结果
'''
P20 非线性激活
- Padding Layers:就是对我们输入的input进行填充的各种方式,几乎用不到。
- 非线性变换的目的:
- 给网络中,引入非线性的特征,非线性特征多的话,才能训练出符合各种曲线或特征的模型否则,泛化能力不好
ReLU
-
Replace的设置:
- inplace (bool) – can optionally do the operation in-place【是否进行原地操作】. Default:
False - 深拷贝和浅拷贝
-
- inplace (bool) – can optionally do the operation in-place【是否进行原地操作】. Default:
-
激活函数,只有一个batch_size参数需要设置。
-
效果:


可以运行的代码
# !usr/bin/env python3
# -*- coding:utf-8 -*-
"""
author :24nemo
date :2021年07月07日
"""
import torch
import torchvision
from torch import nn
from torch.nn import ReLU, Sigmoid
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
'''
非线性激活层,只有一个batch_size一个参数需要设置
'''
input = torch.tensor([[1, -0.5],
[-1, 3]])
input = torch.reshape(input, (-1, 1, 2, 2))
print(input.shape)
dataset = torchvision.datasets.CIFAR10("../dataset", train=False, download=True,
transform=torchvision.transforms.ToTensor())
dataloader = DataLoader(dataset, batch_size=64)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.relu1 = ReLU()
self.sigmoid1 = Sigmoid()
def forward(self, input):
output = self.sigmoid1(input)
return output
tudui = Tudui()
writer = SummaryWriter("../logs_relu")
step = 0
for data in dataloader:
imgs, targets = data
writer.add_images("input", imgs, global_step=step)
output = tudui(imgs)
writer.add_images("output", output, step)
step += 1
writer.close()
'''
实现的效果就是:
torch.Size([1, 1, 2, 2])
tensor([[1., 0.],
[0., 3.]])
'''
'''
非线性变换的目的:
给网络中,引入非线性的特征,非线性特征多的话,才能训练出符合各种曲线或特征的模型
否则,泛化能力不好
'''
global_step★
writer = SummaryWriter("../logs_relu")
step = 0
for data in dataloader:
imgs, targets = data
writer.add_images("input", imgs, global_step=step)
output = tudui(imgs)
writer.add_images("output", output, step)
step += 1
writer.close()
step
是tensorboard里面显示照片的位置一样。他们都显示在”input”这个板块下(可以看成一本书)。这么多份照片。不能叠放在一起。所以用step来分开,就好像页数一样。
P21线性层和其它层
P21线性层和其它层
- Normalization Layers: 批处理归一化层,减少过拟合
- relularization 正则化
- Recurrent Layers: 特定的层,运用了文字识别
- Transformer Layers:
- Linear Layers:
- Dropout Layers:随机失活,是为了防止过拟合,意思就是针对训练集与测试集的拟合效果都很棒,但投入实际却发生效果一般。
- During training, randomly zeroes some of the elements of the input tensor with probability
pusing samples from a Bernoulli distribution.- Distance Functions: 计算两个向量之间的误差。
- Loss Functions:
- 官方文档有一些写好的网络:

- 线性层:这里的线性层,跟非线性激活,形成对比:线性层,是k和b,对输入数据x,进行一次函数的处理,而非线性激活(激活函数)是在对神经元或者输入,做非线性处理:

- Recurrent Layers 不太用
- Transformer Layer
- Linear Layer 重点讲完了
- Dropout Layer 不难 为了防止过拟合
- sparse layer 用于自然语言处理
可以运行的代码
# !usr/bin/env python3
# -*- coding:utf-8 -*-
"""
author :24nemo
date :2021年07月07日
"""
import torch
import torchvision
from torch import nn
from torch.nn import Linear
from torch.utils.data import DataLoader
dataset = torchvision.datasets.CIFAR10("../dataset", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
dataloader = DataLoader(dataset, batch_size=64)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.linear1 = Linear(196608, 10)
def forward(self, input):
output = self.linear1(input)
return output
tudui = Tudui()
for data in dataloader:
imgs, targets = data
print(imgs.shape)
# output = torch.reshape(imgs, (1, 1, 1, -1))
output = torch.flatten(imgs) # 扁平化处理
print(output.shape)
output = tudui(output)
print(output.shape)
'''
正则化层 Normalization Layers nn.BatchNorm2d
有一篇论文,意思是正则化层可以提高训练速度
参数只有一个,channel中的C,num_feature, 令其跟 channel 数相同即可,官方文档有个事例:
>>> # With Learnable Parameters
>>> m = nn.BatchNorm2d(100)
>>> # Without Learnable Parameters # 不含可学习参数
>>> m = nn.BatchNorm2d(100, affine=False) # 这里的 100,是跟着下一行的100(channel)设置的
>>> input = torch.randn(20, 100, 35, 45)
>>> output = m(input)
'''
'''
官方文档有一些写好的网络
'''
P22 squential和小实战
squential
- Sequential能把网络集成在一起,方便使用: (类似于transform.compose())

CIFAR10的数据集结构
- 写一个针对CIFAR10的数据集,写一个分类网络:有一个1024层的,以前的没有说:

利用公式计算padding(对于Conv2d):

不需要公式,**奇数卷积核**把中心格子对准图片第一个格子,卷积核在格子外有两层就padding=2呗
- 清清爽爽:

- 可视化:



可以运行的代码
# -*- coding: utf-8 -*-
# 作者:小土堆
# 公众号:土堆碎念
import torch
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
from torch.utils.tensorboard import SummaryWriter
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model1 = Sequential( # 序列化操作 类似于compose()
Conv2d(3, 32, 5, padding=2), # input_channel = 3, output_channel = 32, kernel_size = 5 * 5 ,padding是计算出来的
MaxPool2d(2), # maxpooling只有一个kernel_size参数
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(), # 展平操作
Linear(1024, 64),
Linear(64, 10)
)
def forward(self, x):
x = self.model1(x)
return x
tudui = Tudui()
print(tudui)
input = torch.ones((64, 3, 32, 32)) # 创建一个假象的输入
output = tudui(input)
print(output.shape)
writer = SummaryWriter("./logs_seq")
writer.add_graph(tudui, input)
writer.close()
注意事项【模型设计验证】
我们从数据集中输入的数据经过我们设计的模型之后是否可以产生我们想要的输出。

得到的结果如下:torch. Size([64,10])
验证正确,因为CIFAR10这个数据库就是一个十分类问题,所以结果产生64份十分类结果。

P23 loss function
其实就是**通过求偏导的方式,求出各个权重大小**;然后反向传播去修改原来的公式的各个权重以逐步使得loss最小。
L1LOSS
- 计算输出和目标的差距;为我们更新输出提供一定的依据(反向传播):

- 注意输入和输出形状:


MSELOSS
- 也讲了MSE—lossFunction:(均方误差)


- MAE结果:

CROSSENTROPYLOSS(交叉熵)
It is useful when training a classification problem with C classes.
https://pytorch.org/docs/stable/generated/torch.nn.CrossEntropyLoss.html#torch.nn.CrossEntropyLoss


-
梯度下降:

-
查看反向传播的梯度:
-
要输入 result_loss.backward() 才可以看到
-
loss = nn.CrossEntropyLoss() tudui = Tudui() for data in dataloader: imgs, targets = data outputs = tudui(imgs) result_loss = loss(outputs, targets) result_loss.backward() print("ok")
-


可以执行的代码-1
# !usr/bin/env python3
# -*- coding:utf-8 -*-
"""
author :24nemo
date :2021年07月07日
"""
import torch
from torch import nn
from torch.nn import L1Loss
inputs = torch.tensor([1, 2, 3], dtype=torch.float32)
targets = torch.tensor([1, 2, 5], dtype=torch.float32)
inputs = torch.reshape(inputs, (1, 1, 1, 3)) # batch_size, channel, 1行, 3列
targets = torch.reshape(targets, (1, 1, 1, 3))
loss = L1Loss(reduction='sum') # reduction 设置计算的方式:是求均值还是和
result = loss(inputs, targets)
loss_mse = nn.MSELoss()
result_mse = loss_mse(inputs, targets)
print(result)
print(result_mse)
x = torch.tensor([0.1, 0.2, 0.3])
y = torch.tensor([1])
x = torch.reshape(x, (1, 3))
loss_cross = nn.CrossEntropyLoss()
result_cross = loss_cross(x, y)
print(result_cross)
'''
使用 L1Loss 时,一定要注意 shape 的形状,输入和输出的大小,要看清楚:
Input: (N, *)(N,∗) where *∗ means, any number of additional dimensions
Target: (N, *)(N,∗), same shape as the input
'''
import torch
from torch import nn
from torch.nn import L1Loss
inputs = torch.tensor([1, 2, 3], dtype=torch.float32)
targets = torch.tensor([1, 2, 5], dtype=torch.float32)
inputs = torch.reshape(inputs, (1, 1, 1, 3)) # batch_size, channel, 1行, 3列
targets = torch.reshape(targets, (1, 1, 1, 3))
loss = L1Loss()
result = loss(inputs, targets)
print("result:", result)
'''
MSELoss
'''
loss_mse = nn.MSELoss()
result_mse = loss_mse(inputs, targets)
print("result_mse:", result_mse)
'''
交叉熵,用于分类问题
这里up讲得挺细致
'''
可以运行的代码-2
# !usr/bin/env python3
# -*- coding:utf-8 -*-
"""
author :24nemo
date :2021年07月07日
"""
'''
import torchvision
from torch import nn
from torch.nn import Sequential, Conv2d, MaxPool2d, Flatten, Linear
from torch.utils.data import DataLoader
dataset = torchvision.datasets.CIFAR10("../dataset", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
dataloader = DataLoader(dataset, batch_size=1)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model1 = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self, x):
x = self.model1(x)
return x
loss = nn.CrossEntropyLoss()
tudui = Tudui()
for data in dataloader:
imgs, targets = data
outputs = tudui(imgs)
result_loss = loss(outputs, targets)
result_loss.backward()
print("ok")
'''
import torchvision
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Linear
from torch.nn.modules.flatten import Flatten
from torch.utils.data import DataLoader
'''
如何在之前的写的神经网络中用到Loss Function
'''
dataset = torchvision.datasets.CIFAR10("../dataset", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
dataloader = DataLoader(dataset, batch_size=64)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.conv1 = Conv2d(3, 32, 5, padding=2)
self.maxpool1 = MaxPool2d(2)
self.conv2 = Conv2d(32, 32, 5, padding=2)
self.maxpool2 = MaxPool2d(2)
self.conv3 = Conv2d(32, 64, 5, padding=2)
self.maxpool3 = MaxPool2d(2)
self.flatten = Flatten()
self.linear1 = Linear(64 * 4 * 4, 64)
self.linear2 = Linear(64, 10)
def forward(self, m):
m = self.conv1(m)
m = self.maxpool1(m)
m = self.conv2(m)
m = self.maxpool2(m)
m = self.conv3(m)
m = self.maxpool3(m)
m = self.flatten(m)
m = self.linear1(m)
m = self.linear2(m)
return m
loss = nn.CrossEntropyLoss() # 定义损失函数
tudui = Tudui()
for data in dataloader:
imgs, targets = data
outputs = tudui(imgs)
print("outputs:", outputs)
print("targets:", targets)
result_loss = loss(outputs, targets) # 调用损失函数
result_loss.backward() # 反向传播, 这里要注意不能使用定义损失函数那里的 loss,而要使用 调用损失函数之后的 result_loss
print("OK") # 这部分,在debug中可以看到 grad 通过反向传播之后,才有值,debug修好了之后,再来看这里
P24 优化器
优化器
-
优化器利用反向传播得到的梯度,对参数进行调整。
-
官网中的位置:介绍了优化器的构造过程:
-

-
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9) optimizer = optim.Adam([var1, var2], lr=0.0001)- params (iterable) - 用于优化的参数的可迭代对象或定义参数组的字典
- lr (learning rate)
-
-
optim里面的算法理论很深入,如果不深究,只要parameter和lr需要设置,其他的都是默认参数:
-
optim = torch.optim.SGD(tudui.parameters(), lr=0.01)
-
-
上图关注重点在optim.zero_grad()和后面的两行,用调试功能,查看梯度是否有数值。
-
经过20轮迭代epoch学习之后,我们查看下Optim.Step()之后每轮的一个loss总值的变化:


可以运行的代码
# -*- coding: utf-8 -*-
'''
import torch
import torchvision
from torch import nn
from torch.nn import Sequential, Conv2d, MaxPool2d, Flatten, Linear
from torch.optim.lr_scheduler import StepLR
from torch.utils.data import DataLoader
dataset = torchvision.datasets.CIFAR10("../dataset", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
dataloader = DataLoader(dataset, batch_size=1)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model1 = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self, x):
x = self.model1(x)
return x
loss = nn.CrossEntropyLoss()
tudui = Tudui()
optim = torch.optim.SGD(tudui.parameters(), lr=0.01)
scheduler = StepLR(optim, step_size=5, gamma=0.1)
for epoch in range(20):
running_loss = 0.0
for data in dataloader:
imgs, targets = data
outputs = tudui(imgs)
result_loss = loss(outputs, targets)
optim.zero_grad() # 每次循环,都要把梯度清零
result_loss.backward()
scheduler.step()
running_loss = running_loss + result_loss
print(running_loss)
# -*- coding: utf-8 -*-
'''
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Linear
from torch.nn.modules.flatten import Flatten
from torch.utils.data import DataLoader
dataset = torchvision.datasets.CIFAR10("../dataset", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
dataloader = DataLoader(dataset, batch_size=64)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.conv1 = Conv2d(3, 32, 5, padding=2)
self.maxpool1 = MaxPool2d(2)
self.conv2 = Conv2d(32, 32, 5, padding=2)
self.maxpool2 = MaxPool2d(2)
self.conv3 = Conv2d(32, 64, 5, padding=2)
self.maxpool3 = MaxPool2d(2)
self.flatten = Flatten()
self.linear1 = Linear(64 * 4 * 4, 64)
self.linear2 = Linear(64, 10)
def forward(self, m):
m = self.conv1(m)
m = self.maxpool1(m)
m = self.conv2(m)
m = self.maxpool2(m)
m = self.conv3(m)
m = self.maxpool3(m)
m = self.flatten(m)
m = self.linear1(m)
m = self.linear2(m)
return m
loss = nn.CrossEntropyLoss() # 定义损失函数
tudui = Tudui()
optim = torch.optim.SGD(tudui.parameters(), lr=0.01)
for epoch in range(20): # 进行二十轮学习迭代
running_loss = 0.0
for data in dataloader:
imgs, targets = data
outputs = tudui(imgs)
result_loss = loss(outputs, targets) # 调用损失函数
optim.zero_grad() # 把上一个循环中每个参数对应的梯度清零
result_loss.backward() # 反向传播, 这里要注意不能使用定义损失函数那里的 loss,而要使用 调用损失函数之后的 result_loss【反向传播 得到每个需要更新参数对应的梯度】
optim.step() # 每个参数会根据上一步得到的梯度进行优化【优化器进行调优】
# print("OK") # 这部分,在debug中可以看到 grad 通过反向传播之后,才有值,debug修好了之后,再来看这里
# print(result_loss)
running_loss = running_loss + result_loss
print(running_loss)
P25 现有网络模型的使用及修改
VGG16
这里是针对于torchvision
- 位置:

- 预训练的意思pretrain,是已经在ImageNet数据集上训练好的:progress是对下载的管理(是否显示进度条):

- 使用的dataset,ImageNet:需要安装scipy库:

- 点开这个ImageNet看里面的信息:

- 设置pretrained为true时,模型的参数是训练好的(即conv、pooling layers里面的那些参数已经在ImageNet里面训练好的模型)【输入print(“vgg16_true”)即可看到具体训练好的模型参数】;否则模型参数就是随机初始化的。
对现有模型进行改进
改进目标:使用vgg16,用在CIFAR数据集上,进行分类:
Vgg16训练时,用的是ImageNet数据集,它把数据分为1000个类,而CIFAR把数据分为10类,那么就有两种做法,来利用vgg16来处理 CIFAR数据集:
1、vgg16后面加一个新的线性层,使1000映射到10;
2、直接把vgg16最后的输出层改为10类:这里的add_module是集成 - 在pytorch当中的方法了,直接用:
下图是第一种方法:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-UCXsD7t5-1679482636716)(C:\Users\23972\AppData\Roaming\Typora\typora-user-images\image-20230322105338517.png)]](https://i-blog.csdnimg.cn/blog_migrate/6b890eba22c1081b07bb992d91fc429d.png)
-
还有下面这种写法,可以**把新添加的层,放在classifier的框架底子,变成classifier的子集**,原来是在大的框架vgg的直属下面:
-
下面是第二个方法:替换原来的输出类型数:图中圈2:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-WIBbduah-1679482636716)(C:\Users\23972\AppData\Roaming\Typora\typora-user-images\image-20230322105540944.png)]](https://i-blog.csdnimg.cn/blog_migrate/64297eb7f3dc2ea2d112b006e2669619.png)

可以运行的代码
# -*- coding: utf-8 -*-
import torchvision
train_data = torchvision.datasets.ImageNet("../data_image_net", split='train', download=True,
transform=torchvision.transforms.ToTensor())
from torch import nn
vgg16_false = torchvision.models.vgg16(pretrained=False)
vgg16_true = torchvision.models.vgg16(pretrained=True)
# print(vgg16_true)
'''
print的结果:
VGG(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace=True)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace=True)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace=True)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace=True)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace=True)
(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): ReLU(inplace=True)
(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace=True)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace=True)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): ReLU(inplace=True)
(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(27): ReLU(inplace=True)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace=True)
(30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=1000, bias=True) # 由于 imagenet 数据集,他的分类结果是 1000,所以这里out_features 值为1000
) # 要想用于 CIFAR10 数据集, 可以在网络下面多加一行,转成10分类的输出
)
'''
train_data = torchvision.datasets.CIFAR10('../dataset', train=True, transform=torchvision.transforms.ToTensor(),
download=True)
# vgg16_true.add_module('add_linear',nn.Linear(1000, 10))
# 要想用于 CIFAR10 数据集, 可以在网络下面多加一行,转成10分类的输出,这样输出的结果,跟下面的不一样,位置不一样
vgg16_true.classifier.add_module('add_linear', nn.Linear(1000, 10))
# 层级不同
# 如何利用现有的网络,改变结构
print(vgg16_true)
# 上面是添加层,下面是如何修改VGG里面的层内容
print(vgg16_false)
vgg16_false.classifier[6] = nn.Linear(4096, 10) # 中括号里的内容,是网络输出结果自带的索引,套进这种格式,就可以直接修改那一层的内容
print(vgg16_false)
'''
这个教程,可以自己修改别人已经写好了的模型,或者在里面添加自己的需求
'''
P26 网络模型的保存和加载
P26 网络模型的保存和加载
- 保存方式1:

- 加载模型方式1:

- 可以debug看看每一层都有啥:

- 保存方式2:

加载模型方式2(只加载参数)
(与方式1加载方式一样,但是==没有框架,只有参数==):

由于第2种加载方式中只包含参数,没有模型结构,所以,当vgg16_method2.pth这个保存了参数的文件已经存在了之后,可以用下图第14行中的方法,把参数放入第13行的vgg16框架当中(这个框架是预训练=False的,所以没有参数,只有框架):

保存:torch.save(model.state_dict,“abc.pth”)
调用:model.load_state_dict(torch.load(“abc.pth”))
说白了就是只保存模型参数的时候,我们是将模型参数利用字典的形式进行打包保存的;
所以在加载的时候我们得到的是一堆字典数据,无法直接得到原有的整个模型,所以这个时候我们就需要建立一个空的模型架构[vgg16 = torchvision.models.vgg16(pretrained=False)],然后将模型参数字典导进去即可[vgg16.load_state_dict(torch.load(“vgg16_method2.pth”))]


陷阱
第一种方式有个陷阱:当保存了自己的网络时,想要load这个网络的话,必须要把这个网络,写在load上面,不然会报错:在save模块中保存的,在load模块中调用,就会出现下面两个图的报错:


其实这个报错,是可以避免的,有两个方法:
1、在load模块的最前面,加上图中的from xxx import *,就可以随意使用save模块的内容了;
2、把建立好的模型,也复制过来,注:**跟正常的使用模块相比,不需要再加上实例化tudui=TuDui( )**这个步骤了;一般我们自己在工程中,会把模型放在一个文件夹或者模块里,不需要考虑这个问题;
可以运行的代码-1
# -*- coding: utf-8 -*-
"""
author :24nemo
date :2021年07月16日
"""
import torch
import torchvision
from torch import nn
vgg16 = torchvision.models.vgg16(pretrained=False)
# 保存方式1,模型结构+模型参数 模型 + 参数 都保存
# torch.save(vgg16, "vgg16_method1.pth") # 引号里是保存路径
# 保存方式2,模型参数(官方推荐) ,因为这个方式,储存量小,在terminal中,ls -all可以查看
torch.save(vgg16.state_dict(), "vgg16_method2.pth")
# 把网络模型的参数,保存下来,储存成字典的形式
# 陷阱
# class Tudui(nn.Module):
# def __init__(self):
# super(Tudui, self).__init__()
# self.conv1 = nn.Conv2d(3, 64, kernel_size=3)
#
# def forward(self, x):
# x = self.conv1(x)
# return x
# tudui = Tudui()
# torch.save(tudui, "tudui_method1.pth")
可以运行的代码-2
# -*- coding: utf-8 -*-
"""
author :24nemo
date :2021年07月16日
"""
# 方式1,保存方式1,加载模型
import torch
import torchvision
from P26_1_model_save import *
# model = torch.load("vgg16_method1.pth")
# print(model)
# 方式2,加载模型
vgg16 = torchvision.models.vgg16(pretrained=False)
vgg16.load_state_dict(torch.load("vgg16_method2.pth"))
# model = torch.load("vgg16_method2.pth")
print(vgg16)
# 陷阱,用第一种方式保存时,如果是自己的模型,就需要在加载中,把class重新写一遍,但并不需要实例化,即可
# 【【这个陷阱,也是可以避免的,最上面的 from model_save import *,就是在做这个事情,避免出现错误】】
# class Tudui(nn.Module):
# def __init__(self):
# super(Tudui, self).__init__()
# self.conv1 = nn.Conv2d(3, 64, kernel_size=3)
# def forward(self, x):
# x = self.conv1(x)
# return x
# model = torch.load('tudui_method1.pth')
# print(model)
P27、28、29 完整的模型套路
准备数据,加载数据,准备模型。设置损失函数。设置优化器,开始训练,最后验证,结果聚合展示
P27、28、29 完整的模型套路
-
一步一步跟着做笔记:
-
查看数据集的长度:
-
# length 长度 train_data_size = len(train_data) test_data_size = len(test_data) # 如果train_data_size=10, 训练数据集的长度为:10 print("训练数据集的长度为:{}".format(train_data_size)) print("测试数据集的长度为:{}".format(test_data_size))
-
-
把写好的这部分,单独放在一个模块里,起名叫做model:

- 这个模块,稍加改动,比如添加import,再用一个测试的torch.ones( ),整理如下:

输出为:这是一个分类的网络,里面的10,表示在每一个类别里,所出现的概率是多大:

- 再在train.py中,import刚才写的model,之后,就可以直接实例化了:tudui=TuDui( ):截图略
- 下面是训练结束,准备写测试的过程,注意,这里的缩进,train和val都是在epoch那个for当中的:

- Pycharm里面有刷新!

- 还能在summarywriter里看到:

模型测试的正确率和loss的设置
关于分类问题,有一个accuracy正确率的概念:

-
对上面的图,要好好解释一下:
- 首先是 两个输入;模型,做了一个2分类;
- 模型输出,对于第一个输入,是类型一的概率是0.1,是第二个的概率是0.2;对于第二个输入,是类型一“0”的概率是0.3,是第二个的概率是0.4;
- 那么0.1和0.3都是类型“0”对应的概率,后两个0.2、0.4对应类型“1”;
- 所以对于pred预测,也就是模型输出的结果,两次都是属于“1”,也就是类型二【取最大值】;
- 那么这个pred是怎么输出为0或者1的呢?有一个argmax的方法,能够计算出这个结果;
-
跟真实值(target)对比来看,真实值是0和1,并不是pred预测的1和1;
-
下面就是计算accuracy了:判断pred是否等于真实值target:如果相等,记为true,不相等记为false,再把他们的结果,加在一起,获得计算正确的数量,再除以总数量,就是accuracy了。
-
再把这套理论放入整体框架当中:

对于train和eval
-
对于train和eval这两个语句的问题,官方文档说的很清楚了,如果在框架中使用了特殊的层,再调用这两个语句,特殊的层包括,dropout,batchnorm【因为这两个层在测试和训练时候是不一样的】,也就是说,train和eval只对这种层起作用:
- dropout是使指定概率的权重随机失活。作用是加快训练速度。测试的时候是不用的,只在训练时杀死神经元
-

-
这一节的后半段,快速捋了一遍整个网络框架。
-
关于带不带 item()的区别:(12月份这次看视频,没发现视频里讲了这个内容呢)

可以运行的代码-1
# !usr/bin/env python3
# -*- coding:utf-8 -*-
"""
author :24nemo
date :2021年07月16日
"""
import torch
from torch import nn
# 搭建神经网络
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(3, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, 1, 2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(64 * 4 * 4, 64),
nn.Linear(64, 10)
)
def forward(self, x):
x = self.model(x)
return x
if __name__ == '__main__':
tudui = Tudui()
input = torch.ones((64, 3, 32, 32)) # 为什么用ones?前面也是用的ones吗?
output = tudui(input)
print(output.shape)
可以运行的代码-2
# -*- coding: utf-8 -*-
# 作者:小土堆
# 公众号:土堆碎念
import torch
import torchvision
from torch.utils.tensorboard import SummaryWriter
from model import *
# 准备数据集
from torch import nn
from torch.utils.data import DataLoader
train_data = torchvision.datasets.CIFAR10(root="./dataset", train=True, transform=torchvision.transforms.ToTensor(),
download=True)
test_data = torchvision.datasets.CIFAR10(root="./dataset", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
# length 长度
train_data_size = len(train_data)
test_data_size = len(test_data)
# 如果train_data_size=10, 训练数据集的长度为:10
print("训练数据集的长度为:{}".format(train_data_size))
print("测试数据集的长度为:{}".format(test_data_size))
# 利用 DataLoader 来加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
# 创建网络模型
tudui = Tudui()
# 损失函数
loss_fn = nn.CrossEntropyLoss()
# 优化器(随机梯度下降)
# learning_rate = 0.01
# 1e-2=1 x (10)^(-2) = 1 /100 = 0.01
learning_rate = 1e-2
optimizer = torch.optim.SGD(tudui.parameters(), lr=learning_rate) # 这里的参数,SGD里面的,只要定义两个参数,一个是tudui.parameters()本身,另一个是lr
# 设置训练网络的一些参数
# 记录训练的次数
total_train_step = 0
# 记录测试的次数
total_test_step = 0
# 训练的轮数
epoch = 10
# 添加tensorboard
writer = SummaryWriter("./logs_train")
for i in range(epoch):
print("-------第 {} 轮训练开始-------".format(i+1))
# 训练步骤开始
tudui.train() # 这两个层,只对一部分层起作用,比如 dropout层;如果有这些特殊的层,才需要调用这个语句
for data in train_dataloader:
imgs, targets = data
outputs = tudui(imgs)
loss = loss_fn(outputs, targets)
# 优化器优化模型
optimizer.zero_grad() # 优化器,梯度清零
loss.backward() # 反向传播, 这里要注意不能使用定义损失函数那里的 loss,而要使用 调用损失函数之后的 result_loss【反向传播 得到每个需要更新参数对应的梯度】
optimizer.step() # 利用优化器进行优化参数
total_train_step = total_train_step + 1
if total_train_step % 100 == 0:
print("训练次数:{}, Loss: {}".format(total_train_step, loss.item())) # 这里用到的 item()方法,有说法的,其实加不加都行,就是输出的形式不一样而已(eg:加上item()输出的是数据类型是值6,不加输出的是一个tensor(6))
writer.add_scalar("train_loss", loss.item(), total_train_step) # 在画曲线
# 每训练完一轮,进行测试,在测试集上测试,以测试集的损失或者正确率,来评估有没有训练好,测试时,就不要调优了,就是以当前的模型,进行测试,所以不用再使用梯度(with no_grad 那句)
# 测试步骤开始
tudui.eval() # 这两个层,只对一部分层起作用,比如 dropout层;如果有这些特殊的层,才需要调用这个语句
total_test_loss = 0
total_accuracy = 0
with torch.no_grad(): # 这样后面就没有梯度了, 测试的过程中,不需要更新参数,更不需要梯度进行优化
for data in test_dataloader: # 在测试集中,选取数据
imgs, targets = data
outputs = tudui(imgs) # 分类的问题,是可以这样的,用一个output进行绘制
loss = loss_fn(outputs, targets)
total_test_loss = total_test_loss + loss.item() # 为了查看总体数据上的 loss,创建的 total_test_loss,初始值是0
accuracy = (outputs.argmax(1) == targets).sum() # 正确率,这是分类问题中,特有的一种,评价指标,语义分割之类的,不一定非要有这个东西,这里是存疑的,再看。
total_accuracy = total_accuracy + accuracy
print("整体测试集上的Loss: {}".format(total_test_loss))
print("整体测试集上的正确率: {}".format(total_accuracy/test_data_size)) # 即便是输出了上一行的 loss,也不能很好的表现出效果。
# 在分类问题上比较特有,通常使用正确率来表示优劣。因为其他问题,可以可视化地显示在tensorbo中。
# 这里在(二)中,讲了很复杂的,没仔细听。这里很有说法,argmax()相关的,有截图在word笔记中。
writer.add_scalar("test_loss", total_test_loss, total_test_step)
writer.add_scalar("test_accuracy", total_accuracy/test_data_size, total_test_step)
total_test_step = total_test_step + 1
torch.save(tudui, "tudui_{}.pth".format(i)) # 保存方式一,其实后缀都可以自己取,习惯用 .pth。
# 模型保存方式二(官方推荐)
# torch.save(tudui.state_dict(),"tudui_{}.pth".format(i))
print("模型已保存")
writer.close()
tensorboard结果截图



P30 GPU加速
1、调用 .cuda()
- 调用 GPU的两种方法:
- 1、调用 .cuda()
- 在这三个内容后面,**调用他们的 .cuda()方法**然后返回即可

下图中,在原来的三种内容上,分别加上.cuda( ),就可以了:让他们的返回值,继续等于原来的变量名,就可以不用管框架中的其他内容了:
更规范的写法,这样的写法,可以避免没有gpu的电脑上跑不通的弊端:

- 在视频中,还比较了**cup和gpu的计算时间**:
- 注意在哪里添加start_time和end_time,以及做差:
-

Google的GPU加速方法
- 后面说了Google的GPU加速方法:
- 需要登录google账号,再访问:Google.colaboratory.com https://colab.research.google.com/drive/1hlxG28CoQut9EWBIfHVlAjv2whnM7vhu#scrollTo=06k5NEwhYBSA

- 具体操作:
新建笔记本:

print(torch.version)
print(torch.cuda.is_avaiable( )):应该是报错的:按图中位置,找到笔记本设置,选择gpu:

- 选择好了之后,重新载入import torch等环境:

- ==!==nvidia-smi 查看硬件版本(上面的代码都是python代码,直接 + 代码,点击三角运行就行;想要在terminal中运行命令,在最前面加上!就可以)

- 修改 笔记本设置 找到 硬件加速器 设为 GPU




- 还是挺好用的,不过,我最近登录之后被分配的GPU不是T4了,也没有16Gb显存:

可以运行的代码
# !usr/bin/env python3
# -*- coding:utf-8 -*-
"""
author :24nemo
date :2021年07月12日
"""
import time
import torch
import torchvision
# from model import *
# 准备数据集
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
train_data = torchvision.datasets.CIFAR10(root="../dataset", train=True, transform=torchvision.transforms.ToTensor(),
download=True)
test_data = torchvision.datasets.CIFAR10(root="../dataset", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
# length 长度
train_data_size = len(train_data)
test_data_size = len(test_data)
# 如果train_data_size=10, 训练数据集的长度为:10
print("训练数据集的长度为:{}".format(train_data_size))
print("测试数据集的长度为:{}".format(test_data_size))
# 利用 DataLoader 来加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
# 创建网络模型
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(3, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, 1, 2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(64 * 4 * 4, 64),
nn.Linear(64, 10)
)
def forward(self, x):
x = self.model(x)
return x
tudui = Tudui()
if torch.cuda.is_available():
tudui = tudui.cuda() # 这是GPU加速训练的第一部分
# 损失函数
loss_fn = nn.CrossEntropyLoss()
if torch.cuda.is_available():
loss_fn = loss_fn.cuda() # 这是GPU加速训练的第二部分
# 优化器
# learning_rate = 0.01
# 1e-2=1 x (10)^(-2) = 1 /100 = 0.01
learning_rate = 1e-2
optimizer = torch.optim.SGD(tudui.parameters(), lr=learning_rate)
# 设置训练网络的一些参数
# 记录训练的次数
total_train_step = 0
# 记录测试的次数
total_test_step = 0
# 训练的轮数
epoch = 10
# 添加tensorboard
writer = SummaryWriter("../logs_train")
# 添加开始时间
start_time = time.time()
for i in range(epoch):
print("-------第 {} 轮训练开始-------".format(i + 1))
# 训练步骤开始
tudui.train()
for data in train_dataloader:
imgs, targets = data
if torch.cuda.is_available():
imgs = imgs.cuda() # 这两行是GPU加速的第三部分(未完)
targets = targets.cuda()
outputs = tudui(imgs)
loss = loss_fn(outputs, targets)
# 优化器优化模型
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_step = total_train_step + 1
if total_train_step % 100 == 0:
end_time = time.time() # 结束时间
print(end_time - start_time)
print("训练次数:{}, Loss: {}".format(total_train_step, loss.item()))
writer.add_scalar("train_loss", loss.item(), total_train_step)
# 测试步骤开始
tudui.eval()
total_test_loss = 0
total_accuracy = 0
with torch.no_grad():
for data in test_dataloader:
imgs, targets = data
if torch.cuda.is_available(): # 这两行也是必不可少的,GPU加速训练的部分
imgs = imgs.cuda()
targets = targets.cuda()
outputs = tudui(imgs)
loss = loss_fn(outputs, targets)
total_test_loss = total_test_loss + loss.item()
accuracy = (outputs.argmax(1) == targets).sum()
total_accuracy = total_accuracy + accuracy
print("整体测试集上的 Loss: {}".format(total_test_loss))
print("整体测试集上的正确率: {}".format(total_accuracy / test_data_size))
writer.add_scalar("test_loss", total_test_loss, total_test_step)
writer.add_scalar("test_accuracy", total_accuracy / test_data_size, total_test_step)
total_test_step = total_test_step + 1
torch.save(tudui, "tudui_{}.pth".format(i))
print("模型已保存")
writer.close()
'''
两种GPU训练方式
方式一:
网络模型、损失函数、数据(输入、标注)
调用 .cuda
以上三者有cuda方法,能够实现
'''
"""
google的GPU
"""
2、调用.to(device)
.to(device)与.cuda()

-
想要在GPU上运行,只需要定义几处,跟 第一种方法 需要修改的位置是一样的:不同之处在于:在最前面,需要加第20行:如果使用gpu,就用“cuda”,如果使用cpu,就直接用“cpu”:
-
使用GPU加速的第二种方法: .to(device):
-
先定义:device = torch.device(“cpu”)
-
在损失函数、网络模型两个位置,可以简略地写:如62和66行,不必再返回给原来的变量:


-
只有在数据的位置,是必须要把imgs.to(device)再返回给imgs的,target同理:

-
==torch.device(“cuda:0”)==有**多个显卡**时使用
-
等效
device = torch.device("cuda") device = torch.device("cuda:0")
-
-
GPU_2 这种方式更多见:另外,经常这样用,来简写 GPU 和 CPU 的使用:
-
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
-
可以运行的代码
# !usr/bin/env python3
# -*- coding:utf-8 -*-
"""
author :24nemo
date :2021年07月12日
"""
import time
import torch
import torchvision
# from model import *
# 准备数据集
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
# 定义训练的设备
# device = torch.device("cuda") # 定义训练的设备
# device = torch.device("cuda:0")
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(device)
train_data = torchvision.datasets.CIFAR10(root="../dataset", train=True, transform=torchvision.transforms.ToTensor(),
download=True)
test_data = torchvision.datasets.CIFAR10(root="../dataset", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
# length 长度
train_data_size = len(train_data)
test_data_size = len(test_data)
# 如果train_data_size=10, 训练数据集的长度为:10
print("训练数据集的长度为:{}".format(train_data_size))
print("测试数据集的长度为:{}".format(test_data_size))
# 利用 DataLoader 来加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
# 创建网络模型
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(3, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, 1, 2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(64 * 4 * 4, 64),
nn.Linear(64, 10)
)
def forward(self, x):
x = self.model(x)
return x
tudui = Tudui()
tudui.to(device) # 这里新添加了gpu加速的内容 这里,其实不用另外赋值 tudui = xxx,直接调用 tudui.to(device)就可以的
# 损失函数
loss_fn = nn.CrossEntropyLoss()
loss_fn.to(device) # 这里添加了加速设备,其实也是不需要重新赋值的,直接调用就可以了
# 优化器
# learning_rate = 0.01
# 1e-2=1 x (10)^(-2) = 1 /100 = 0.01
learning_rate = 1e-2
optimizer = torch.optim.SGD(tudui.parameters(), lr=learning_rate)
# 设置训练网络的一些参数
# 记录训练的次数
total_train_step = 0
# 记录测试的次数
total_test_step = 0
# 训练的轮数
epoch = 10
# 添加tensorboard
writer = SummaryWriter("../logs_train")
start_time = time.time()
for i in range(epoch):
print("-------第 {} 轮训练开始-------".format(i + 1))
# 训练步骤开始
tudui.train()
for data in train_dataloader:
imgs, targets = data
imgs = imgs.to(device) # 这里是数据,需要重新赋值
targets = targets.to(device) # 这里一样
outputs = tudui(imgs)
loss = loss_fn(outputs, targets)
# 优化器优化模型
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_step = total_train_step + 1
if total_train_step % 100 == 0:
end_time = time.time()
print(end_time - start_time)
print("训练次数:{}, Loss: {}".format(total_train_step, loss.item()))
writer.add_scalar("train_loss", loss.item(), total_train_step)
# 测试步骤开始
tudui.eval()
total_test_loss = 0
total_accuracy = 0
with torch.no_grad():
for data in test_dataloader:
imgs, targets = data
imgs = imgs.to(device)
targets = targets.to(device)
outputs = tudui(imgs)
loss = loss_fn(outputs, targets)
total_test_loss = total_test_loss + loss.item()
accuracy = (outputs.argmax(1) == targets).sum()
total_accuracy = total_accuracy + accuracy
print("整体测试集上的Loss: {}".format(total_test_loss))
print("整体测试集上的正确率: {}".format(total_accuracy / test_data_size))
writer.add_scalar("test_loss", total_test_loss, total_test_step)
writer.add_scalar("test_accuracy", total_accuracy / test_data_size, total_test_step)
total_test_step = total_test_step + 1
torch.save(tudui, "tudui_{}.pth".format(i))
print("模型已保存")
writer.close()
'''
GPU加速的第二个方法
.to(device)
device = torch.device(“cpu”)
torch.device(“cuda”)也可以
torch.device(“cuda:0”)有多个显卡时使用
'''
P32 完整的模型验证套路
测试、demo

- 利用已经训练好的模型train.py,给他一个输入,在test.py上进行测试:

- 实际验证过程:

-报错处理:在gpu上训练的结果,想要用在cpu电脑上,做test,需要第38行,这一步叫:做映射(map):

可以运行的代码
# !usr/bin/env python3
# -*- coding:utf-8 -*-
"""
author :24nemo
date :2021年07月07日
"""
import torch
import torchvision
from PIL import Image
from torch import nn
image_path = "../imgs/airplane.png"
# image_path = "TuDui/imgs/airplane.png" # 复制相对路径,就是对的了
image = Image.open(image_path) # PIL类型的图片
print(image)
image = image.convert('RGB') # 这里在word中,有截图,是跟png的通道数有关系的
# 图像大小,只能是模型中的32,32,然后转为 totensor 数据类型
transform = torchvision.transforms.Compose([torchvision.transforms.Resize((32, 32)),
torchvision.transforms.ToTensor()])
image = transform(image) # 应用 transform
print(image.shape) # 打印图像大小
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(3, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, 1, 2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(64 * 4 * 4, 64),
nn.Linear(64, 10)
)
def forward(self, x):
x = self.model(x)
return x
model = torch.load("tudui_0.pth", map_location=torch.device('cpu')) # 加载训练模型[如果你是gpu训练的模型就要放到gpu中去预测 ]
print(model)
image = torch.reshape(image, (1, 3, 32, 32)) # 当我们不知道转化之后的batch_size多大时,可以直接令其为-1 (-1, 3, 32, 32)
model.eval() # 如上小节所示:为了同样适用在一些特殊的情况下预测(dropout,,,)
with torch.no_grad(): # 这步可以节约内存,提高性能[因为这里是预测,而非train,所以不需要梯度]
output = model(image)
print(output)
print(output.argmax(1)) # 通过argmax()将预测的得分换成one-hot编码【横轴】
P33 github的使用
P33 github的使用
-
在github上搜索项目的技巧:按照获得的star数量,排序。推荐下面的project。
-
开源代码的使用技巧:把代码中,参数设置为require的内容,全部改成default,并设置一个默认值;这样就可以在pycharm中,直接运行了。

- 例如这里的将“
__dataroot__”这行中的require=True删掉,添加default=“./datasets/maps”.
可以运行的代码
# !usr/bin/env python3
# -*- coding:utf-8 -*-
"""
author :24nemo
date :2021年07月12日
"""
import time
import torch
import torchvision
# 准备数据集
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
train_data = torchvision.datasets.CIFAR10(root="../dataset", train=True, transform=torchvision.transforms.ToTensor(),
download=True)
test_data = torchvision.datasets.CIFAR10(root="../dataset", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
# length 长度
train_data_size = len(train_data)
test_data_size = len(test_data)
# 如果train_data_size=10, 训练数据集的长度为:10
print("训练数据集的长度为:{}".format(train_data_size))
print("测试数据集的长度为:{}".format(test_data_size))
# 利用 DataLoader 来加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
# 创建网络模型
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(3, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, 1, 2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(64 * 4 * 4, 64),
nn.Linear(64, 10)
)
def forward(self, x):
x = self.model(x)
return x
tudui = Tudui()
# 损失函数
loss_fn = nn.CrossEntropyLoss()
# 优化器
# learning_rate = 0.01
# 1e-2=1 x (10)^(-2) = 1 /100 = 0.01
learning_rate = 1e-2
optimizer = torch.optim.SGD(tudui.parameters(), lr=learning_rate)
# 设置训练网络的一些参数
# 记录训练的次数
total_train_step = 0
# 记录测试的次数
total_test_step = 0
# 训练的轮数
epoch = 10
# 添加tensorboard
writer = SummaryWriter("../logs_train")
# 添加开始时间
start_time = time.time()
for i in range(epoch):
print("-------第 {} 轮训练开始-------".format(i + 1))
# 训练步骤开始
tudui.train()
for data in train_dataloader:
imgs, targets = data
outputs = tudui(imgs)
loss = loss_fn(outputs, targets)
# 优化器优化模型
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_step = total_train_step + 1
if total_train_step % 100 == 0:
end_time = time.time()
print(end_time - start_time)
print("训练次数:{}, Loss: {}".format(total_train_step, loss.item()))
writer.add_scalar("train_loss", loss.item(), total_train_step)
# 测试步骤开始
tudui.eval()
total_test_loss = 0
total_accuracy = 0
with torch.no_grad():
for data in test_dataloader:
imgs, targets = data
outputs = tudui(imgs)
loss = loss_fn(outputs, targets)
total_test_loss = total_test_loss + loss.item()
accuracy = (outputs.argmax(1) == targets).sum()
total_accuracy = total_accuracy + accuracy
print("整体测试集上的Loss: {}".format(total_test_loss))
print("整体测试集上的正确率: {}".format(total_accuracy / test_data_size))
writer.add_scalar("test_loss", total_test_loss, total_test_step)
writer.add_scalar("test_accuracy", total_accuracy / test_data_size, total_test_step)
total_test_step = total_test_step + 1
torch.save(tudui, "tudui_{}.pth".format(i))
print("模型已保存")
writer.close()

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









