







在annamalai-nr/drebin: Drebin - NDSS 2014 Re-implementation (github.com)基础上修改了一点点
本地文件所在位置E:\0.code\2014drebin\drebin-master
把原本的androguard文件删除,导入了androguard库
运行代码(cd到了src目录)

python E:\0.code\2014drebin\drebin-master\src\Main.py --holdout 0 --maldir 'E:\\0.code\\2014drebin\\drebin-master\\data\\small_pro
to_apks\\malware' --gooddir 'E:\\0.code\\2014drebin\\drebin-master\\data\\small_proto_apks\\goodware' --ncpucores 4 --testsize 0.3 --numfeatforexp 30
main.py
导入库
from GetApkData import GetApkData # 导入获取APK数据的模块
from RandomClassification import RandomClassification # 导入随机分类模块
from HoldoutClassification import HoldoutClassification # 导入保持分类模块
import psutil # 导入psutil库,用于获取系统信息
import argparse # 导入argparse库,用于解析命令行参数
import logging # 导入logging库,用于记录日志设置日志记录器
# 配置日志记录的基本设置,并创建一个名为 'main.stdout' 的记录器
logging.basicConfig(level=logging.INFO)
Logger = logging.getLogger('main.stdout')需要设置的各种参数
def ParseArgs():
Args = argparse.ArgumentParser(description="Classification of Android Applications")
# 要执行的分类类型(0表示随机分类,1表示滞留分类”)
Args.add_argument("--holdout", type= int, default= 0,
help="Type of Classification to be performed (0 for Random Classification and 1 for Holdout Classification")
# 包含恶意软件apk的目录的绝对路径
Args.add_argument("--maldir", default= "../data/small_proto_apks/malware",
help= "Absolute path to directory containing malware apks")
# 包含良性apk的目录的绝对路径
Args.add_argument("--gooddir", default= "../data/small_proto_apks/goodware",
help= "Absolute path to directory containing benign apks")
# 执行Holdout Classification时用于测试的包含恶意软件apk的目录的绝对路径
Args.add_argument("--testmaldir", default= "../data/apks/malware",
help= "Absolute path to directory containing malware apks for testing when performing Holdout Classification")
# 执行Holdout Classification时用于测试的包含goodware apk的目录的绝对路径
Args.add_argument("--testgooddir", default="../data/apks/goodware",
help= "Absolute path to directory containing goodware apks for testing when performing Holdout Classification")
# 将用于处理的CPU数量
Args.add_argument("--ncpucores", type= int, default= psutil.cpu_count(),
help= "Number of CPUs that will be used for processing")
# 由Scikit Learn的列车测试拆分模块拆分时的测试集大小
Args.add_argument("--testsize", type= float, default= 0.3,
help= "Size of the test set when split by Scikit Learn's Train Test Split module")
# 保存的模型文件的绝对路径(扩展名.pkl)
Args.add_argument("--model",
help= "Absolute path to the saved model file(.pkl extension)")
# 每个测试样本要显示的顶级功能的数量
Args.add_argument("--numfeatforexp", type= int, default = 30,
help= "Number of top features to show for each test sample")
return Args.parse_args()运行函数入口
其中GetApkData函数生成了所需的.data文件 其中包含特征;RandomClassification函数使用了支持向量机对数据进行分类。
def main(Args, FeatureOption):
'''
Main function for malware and goodware classification
:param args: arguments acquired from command lines(refer to ParseArgs() for list of args)
:param FeatureOption: False
'''
# 获取命令行参数并赋值给变量
MalDir = Args.maldir # 恶意软件APK文件夹路径
GoodDir = Args.gooddir # 良性软件APK文件夹路径
NCpuCores = Args.ncpucores # 使用的CPU核心数量
Model = Args.model # 模型文件路径
NumFeatForExp = Args.numfeatforexp # 用于实验的特征数量
# 判断是否执行随机分类
if Args.holdout == 0:
# 执行随机分类
TestSize = Args.testsize # 获取测试集划分的大小 默认30%
# 添加记录
Logger.debug("MalDir: {}, GoodDir: {}, NCpuCores: {}, TestSize: {}, FeatureOption: {}, NumFeatForExp: {}"
.format(MalDir, GoodDir, NCpuCores, TestSize, FeatureOption, NumFeatForExp))
GetApkData(NCpuCores, MalDir, GoodDir) # 获取APK数据 参数是使用的CPU核心数量,恶意和良性文件夹地址
# 参数是恶意、良性文件夹地址、划分比例、是否进行特征选择、已经训练好的模型地址(没有的话False)、用于实验的特征数量(用于解释特征权重)
RandomClassification(MalDir, GoodDir, TestSize, FeatureOption, Model, NumFeatForExp) # 执行随机分类
else:
# 执行保持分类
TestMalDir = Args.testmaldir # 获取测试集恶意软件APK文件夹路径
TestGoodDir = Args.testgooddir # 获取测试集良性软件APK文件夹路径
Logger.debug("MalDir: {}, GoodDir: {}, TestMalDir: {}, TestGoodDir: {} NCpuCores: {}, FeatureOption: {}, NumFeatForExp: {}"
.format(MalDir, GoodDir, TestMalDir, TestGoodDir, NCpuCores, FeatureOption, NumFeatForExp))
GetApkData(NCpuCores, MalDir, GoodDir, TestMalDir, TestGoodDir) # 获取APK数据
HoldoutClassification(MalDir, GoodDir, TestMalDir, TestGoodDir, FeatureOption, Model, NumFeatForExp) # 执行保持分类运行main函数
if __name__ == "__main__":
main(ParseArgs(), True)main里面的完整代码
# -*- coding: utf-8 -*-
from GetApkData import GetApkData # 导入获取APK数据的模块
from RandomClassification import RandomClassification # 导入随机分类模块
from HoldoutClassification import HoldoutClassification # 导入保持分类模块
import psutil # 导入psutil库,用于获取系统信息
import argparse # 导入argparse库,用于解析命令行参数
import logging # 导入logging库,用于记录日志
# 配置日志记录的基本设置,并创建一个名为 'main.stdout' 的记录器
logging.basicConfig(level=logging.INFO)
Logger = logging.getLogger('main.stdout')
def main(Args, FeatureOption):
'''
Main function for malware and goodware classification
:param args: arguments acquired from command lines(refer to ParseArgs() for list of args)
:param FeatureOption: False
'''
# 获取命令行参数并赋值给变量
MalDir = Args.maldir # 恶意软件APK文件夹路径
GoodDir = Args.gooddir # 良性软件APK文件夹路径
NCpuCores = Args.ncpucores # 使用的CPU核心数量
Model = Args.model # 模型文件路径
NumFeatForExp = Args.numfeatforexp # 用于实验的特征数量
# 判断是否执行随机分类
if Args.holdout == 0:
# 执行随机分类
TestSize = Args.testsize # 获取测试集划分的大小 默认30%
# 添加记录
Logger.debug("MalDir: {}, GoodDir: {}, NCpuCores: {}, TestSize: {}, FeatureOption: {}, NumFeatForExp: {}"
.format(MalDir, GoodDir, NCpuCores, TestSize, FeatureOption, NumFeatForExp))
GetApkData(NCpuCores, MalDir, GoodDir) # 获取APK数据
RandomClassification(MalDir, GoodDir, TestSize, FeatureOption, Model, NumFeatForExp) # 执行随机分类
else:
# 执行保持分类
TestMalDir = Args.testmaldir # 获取测试集恶意软件APK文件夹路径
TestGoodDir = Args.testgooddir # 获取测试集良性软件APK文件夹路径
Logger.debug("MalDir: {}, GoodDir: {}, TestMalDir: {}, TestGoodDir: {} NCpuCores: {}, FeatureOption: {}, NumFeatForExp: {}"
.format(MalDir, GoodDir, TestMalDir, TestGoodDir, NCpuCores, FeatureOption, NumFeatForExp))
GetApkData(NCpuCores, MalDir, GoodDir, TestMalDir, TestGoodDir) # 获取APK数据
HoldoutClassification(MalDir, GoodDir, TestMalDir, TestGoodDir, FeatureOption, Model, NumFeatForExp) # 执行保持分类
def ParseArgs():
Args = argparse.ArgumentParser(description="Classification of Android Applications")
# 要执行的分类类型(0表示随机分类,1表示滞留分类”)
Args.add_argument("--holdout", type= int, default= 0,
help="Type of Classification to be performed (0 for Random Classification and 1 for Holdout Classification")
# 包含恶意软件apk的目录的绝对路径
Args.add_argument("--maldir", default= "../data/small_proto_apks/malware",
help= "Absolute path to directory containing malware apks")
# 包含良性apk的目录的绝对路径
Args.add_argument("--gooddir", default= "../data/small_proto_apks/goodware",
help= "Absolute path to directory containing benign apks")
# 执行Holdout Classification时用于测试的包含恶意软件apk的目录的绝对路径
Args.add_argument("--testmaldir", default= "../data/apks/malware",
help= "Absolute path to directory containing malware apks for testing when performing Holdout Classification")
# 执行Holdout Classification时用于测试的包含goodware apk的目录的绝对路径
Args.add_argument("--testgooddir", default="../data/apks/goodware",
help= "Absolute path to directory containing goodware apks for testing when performing Holdout Classification")
# 将用于处理的CPU数量
Args.add_argument("--ncpucores", type= int, default= psutil.cpu_count(),
help= "Number of CPUs that will be used for processing")
# 由Scikit Learn的列车测试拆分模块拆分时的测试集大小
Args.add_argument("--testsize", type= float, default= 0.3,
help= "Size of the test set when split by Scikit Learn's Train Test Split module")
# 保存的模型文件的绝对路径(扩展名.pkl)
Args.add_argument("--model",
help= "Absolute path to the saved model file(.pkl extension)")
# 每个测试样本要显示的顶级功能的数量
Args.add_argument("--numfeatforexp", type= int, default = 30,
help= "Number of top features to show for each test sample")
return Args.parse_args()
if __name__ == "__main__":
main(ParseArgs(), True)GetApkData.py
用于数据预处理
导入库
# -*- coding: utf-8 -*-
import sys
reload(sys)
sys.setdefaultencoding("utf-8") # 设置默认编码为utf-8
import os # 导入os模块,用于文件和目录操作
import time # 导入time模块,用于时间相关操作
sys.path.append("Modules") # 将Modules目录添加到系统路径
sys.path.append("Androguard") # 将Androguard目录添加到系统路径
import re # 导入正则表达式模块
import multiprocessing as mp # 导入多进程模块
import CommonModules as CM # 导入CommonModules模块并简写为CM
from CommonModules import logger # 从CommonModules模块中导入logger
from androguard.misc import AnalyzeAPK
# import androlyze # 导入androlyze模块,用于APK分析
from Modules import BasicBlockAttrBuilder as BasicBlockAttrBuilder # 导入BasicBlockAttrBuilder模块并简写
from Modules import PScoutMapping as PScoutMapping # 导入PScoutMapping模块并简写
from xml.dom import minidom # 导入minidom,用于解析XML
from lxml import etreeGetFromXML函数先获得apk的andromanifest.xml文件
返回请求的权限集合, 活动集合, 服务集合, 内容提供者集合, 广播接收器集合, 硬件组件集合, 意图过滤器集合
try: # 反编译apk文件 并存储xml文件
ApkFile = os.path.abspath(ApkFile) # 获取以.APK为后缀的文件的绝对路径
a, d, dx = AnalyzeAPK(ApkFile) # 正确解包AnalyzeAPK返回的元组 # 使用androlyze分析APK文件
# 写入AndroidManifest.xml到文件
# 使用 lxml 获取 AndroidManifest.xml 并格式化输出
manifest_xml = a.get_android_manifest_xml()
pretty_manifest_xml = etree.tostring(manifest_xml, pretty_print=True, encoding='UTF-8').decode('utf-8')
# 写入AndroidManifest.xml到文件
with open(os.path.splitext(ApkFile)[0] + ".xml", "w") as f:
f.write(pretty_manifest_xml)
# 打开一个新文件,用于存储解析后的XML
f.close() # 关闭文件利用生成的xml文件得到7个数据特征
(
请求的权限集合, 活动集合, 服务集合, 内容提供者集合, 广播接收器集合, 硬件组件集合, 意图过滤器集合
)
try:
f = open(ApkFileName + ".xml", "r") # 打开之前保存的XML文件 'E:\\0.code\\2014drebin\\drebin-master\\data\\small_proto_apks\\malware\\SMS0016.xml'
Dom = minidom.parse(f) # 解析XML文件
DomCollection = Dom.documentElement # 获取文档的根元素
# 1/获取uses-permission标签中的权限
DomPermission = DomCollection.getElementsByTagName("uses-permission")
for Permission in DomPermission:
if Permission.hasAttribute("android:name"):
RequestedPermissionSet.add(Permission.getAttribute("android:name"))
# 2、获取activity标签中的活动
DomActivity = DomCollection.getElementsByTagName("activity")
for Activity in DomActivity:
if Activity.hasAttribute("android:name"):
ActivitySet.add(Activity.getAttribute("android:name"))
# 3、获取service标签中的服务
DomService = DomCollection.getElementsByTagName("service")
for Service in DomService:
if Service.hasAttribute("android:name"):
ServiceSet.add(Service.getAttribute("android:name"))
# 4、获取provider标签中的内容提供者
DomContentProvider = DomCollection.getElementsByTagName("provider")
for Provider in DomContentProvider:
if Provider.hasAttribute("android:name"):
ContentProviderSet.add(Provider.getAttribute("android:name"))
# 5、获取receiver标签中的广播接收器
DomBroadcastReceiver = DomCollection.getElementsByTagName("receiver")
for Receiver in DomBroadcastReceiver:
if Receiver.hasAttribute("android:name"):
BroadcastReceiverSet.add(Receiver.getAttribute("android:name"))
# 6、获取uses-feature标签中的硬件组件
DomHardwareComponent = DomCollection.getElementsByTagName("uses-feature")
for HardwareComponent in DomHardwareComponent:
if HardwareComponent.hasAttribute("android:name"):
HardwareComponentsSet.add(HardwareComponent.getAttribute("android:name"))
# 7、获取intent-filter标签中的意图过滤器
DomIntentFilter = DomCollection.getElementsByTagName("intent-filter")
DomIntentFilterAction = DomCollection.getElementsByTagName("action")
for Action in DomIntentFilterAction:
if Action.hasAttribute("android:name"):
IntentFilterSet.add(Action.getAttribute("android:name"))
except Exception as e:
logger.error(e) # 记录错误信息
logger.error("Cannot resolve " + ApkDirectoryPath + "'s AndroidManifest.xml File!") # 记录特定错误信息
return RequestedPermissionSet, ActivitySet, ServiceSet, ContentProviderSet, BroadcastReceiverSet, HardwareComponentsSet, IntentFilterSet
finally:
f.close() # 关闭文件
return RequestedPermissionSet, ActivitySet, ServiceSet, ContentProviderSet, BroadcastReceiverSet, HardwareComponentsSet, IntentFilterSet完整的GetFromXML函数
返回请求的权限集合, 活动集合, 服务集合, 内容提供者集合, 广播接收器集合, 硬件组件集合, 意图过滤器集合
# 获取信息,APK文件目录路径, .APK文件路径 # 获得了7个信息
def GetFromXML(ApkDirectoryPath, ApkFile):
'''
从APK文件的Manifest文件中获取请求的权限等信息。
:param String ApkDirectoryPath: APK文件目录路径
:param String ApkFile: APK文件名
:return 请求的权限集合, 活动集合, 服务集合, 内容提供者集合, 广播接收器集合, 硬件组件集合, 意图过滤器集合
:rtype Set([String])
'''
ApkDirectoryPath = os.path.abspath(ApkDirectoryPath) # 获取绝对路径'E:\\0.code\\2014drebin\\drebin-master\\data\\small_proto_apks\\malware'
ApkFileName = os.path.splitext(ApkFile)[0] # 获取不带扩展名的文件名 'E:\\0.code\\2014drebin\\drebin-master\\data\\small_proto_apks\\malware\\SMS0016'
# 初始化集合,用于存储不同类型的信息
RequestedPermissionSet = set() # 请求的权限集合
ActivitySet = set() # 活动集合
ServiceSet = set() # 服务集合
ContentProviderSet = set() # 内容提供者集合
BroadcastReceiverSet = set() # 广播接收器集合
HardwareComponentsSet = set() # 硬件组件集合
IntentFilterSet = set() # 意图过滤器集合
try: # 反编译apk文件 并存储xml文件
ApkFile = os.path.abspath(ApkFile) # 获取APK文件的绝对路径
a, d, dx = AnalyzeAPK(ApkFile) # 正确解包AnalyzeAPK返回的元组 # 使用androlyze分析APK文件
# 写入AndroidManifest.xml到文件
# 使用 lxml 获取 AndroidManifest.xml 并格式化输出
manifest_xml = a.get_android_manifest_xml()
pretty_manifest_xml = etree.tostring(manifest_xml, pretty_print=True, encoding='UTF-8').decode('utf-8')
# 写入AndroidManifest.xml到文件
with open(os.path.splitext(ApkFile)[0] + ".xml", "w") as f:
f.write(pretty_manifest_xml)
# 打开一个新文件,用于存储解析后的XML
f.close() # 关闭文件
except Exception as e:
print(e)
logger.error(e) # 记录错误信息
logger.error("Executing Androlyze on " + ApkFile + " to get AndroidManifest.xml Failed.") # 记录特定错误信息
return
try:
f = open(ApkFileName + ".xml", "r") # 打开之前保存的XML文件 'E:\\0.code\\2014drebin\\drebin-master\\data\\small_proto_apks\\malware\\SMS0016.xml'
Dom = minidom.parse(f) # 解析XML文件
DomCollection = Dom.documentElement # 获取文档的根元素
# 1/获取uses-permission标签中的权限
DomPermission = DomCollection.getElementsByTagName("uses-permission")
for Permission in DomPermission:
if Permission.hasAttribute("android:name"):
RequestedPermissionSet.add(Permission.getAttribute("android:name"))
# 2、获取activity标签中的活动
DomActivity = DomCollection.getElementsByTagName("activity")
for Activity in DomActivity:
if Activity.hasAttribute("android:name"):
ActivitySet.add(Activity.getAttribute("android:name"))
# 3、获取service标签中的服务
DomService = DomCollection.getElementsByTagName("service")
for Service in DomService:
if Service.hasAttribute("android:name"):
ServiceSet.add(Service.getAttribute("android:name"))
# 4、获取provider标签中的内容提供者
DomContentProvider = DomCollection.getElementsByTagName("provider")
for Provider in DomContentProvider:
if Provider.hasAttribute("android:name"):
ContentProviderSet.add(Provider.getAttribute("android:name"))
# 5、获取receiver标签中的广播接收器
DomBroadcastReceiver = DomCollection.getElementsByTagName("receiver")
for Receiver in DomBroadcastReceiver:
if Receiver.hasAttribute("android:name"):
BroadcastReceiverSet.add(Receiver.getAttribute("android:name"))
# 6、获取uses-feature标签中的硬件组件
DomHardwareComponent = DomCollection.getElementsByTagName("uses-feature")
for HardwareComponent in DomHardwareComponent:
if HardwareComponent.hasAttribute("android:name"):
HardwareComponentsSet.add(HardwareComponent.getAttribute("android:name"))
# 7、获取intent-filter标签中的意图过滤器
DomIntentFilter = DomCollection.getElementsByTagName("intent-filter")
DomIntentFilterAction = DomCollection.getElementsByTagName("action")
for Action in DomIntentFilterAction:
if Action.hasAttribute("android:name"):
IntentFilterSet.add(Action.getAttribute("android:name"))
except Exception as e:
logger.error(e) # 记录错误信息
logger.error("Cannot resolve " + ApkDirectoryPath + "'s AndroidManifest.xml File!") # 记录特定错误信息
return RequestedPermissionSet, ActivitySet, ServiceSet, ContentProviderSet, BroadcastReceiverSet, HardwareComponentsSet, IntentFilterSet
finally:
f.close() # 关闭文件
return RequestedPermissionSet, ActivitySet, ServiceSet, ContentProviderSet, BroadcastReceiverSet, HardwareComponentsSet, IntentFilterSet
获得指令信息GetFromInstructions函数
返回使用的权限集合, 受限API集合, 可疑API集合, URL域名集合
Instructions是返回的这个方法中的指令
'sput-object v0, Lru/alpha/Alpha;->apiKey Ljava/lang/String;'
APIList: 这个方法指令中,有invoke-且是Landroid开头 就加到api列表里面
SuspiciousApiSet(可疑api) :SuspiciousApiSet的样子 ApiClass+"."+ApiName、OtherSuspiciousApiNameList、NotLikeApiNameList(提前定义了可以的api名称,只需要看这个方法有没有在那些可以api中)
调用的方法是否申请了权限
- 在上面的APIList中查看这个类加方法名字,有没有在pscout中有对应的权限,如果有的话,
- 查看这个权限是否在申请的权限里面,在的话就添加到使用的权限,使用的权限PermissionSet
- 如果这个所需的权限不在申请的权限里面,不在的话就将’‘类名+方法名‘’添加到受限API集合里面(说明这个api没有申请权限)
def GetFromInstructions(ApkDirectoryPath, ApkFile, PMap, RequestedPermissionList):
'''
获取APK文件所需的权限、使用的API和HTTP信息。
重载版本的GetPermissions。
:param String ApkDirectoryPath: APK文件目录路径
:param String ApkFile: APK文件名
:param PScoutMapping.PScoutMapping PMap: API映射
:param RequestedPermissionList List([String]): 请求的权限列表
:return 使用的权限集合, 受限API集合, 可疑API集合, URL域名集合
:rtype Set([String])
'''
UsedPermissions = set() # 1、使用的权限集合
RestrictedApiSet = set() # 2、受限API集合
SuspiciousApiSet = set() # 3、可疑API集合
URLDomainSet = set() # 4、URL域名集合
try:
ApkFile = os.path.abspath(ApkFile) # 获取APK文件的绝对路径
a, d, dx = AnalyzeAPK(ApkFile) # 分析APK文件
except Exception as e:
print(e)
logger.error(e) # 记录错误信息
logger.error("Executing Androlyze on " + ApkFile + " Failed.") # 记录特定错误信息
return
for cls in d:
for method in cls.get_methods():
g = dx.get_method(method)
for BasicBlock in g.get_basic_blocks().get():
Instructions = BasicBlockAttrBuilder.GetBasicBlockDalvikCode(BasicBlock) # 获取指令
Apis, SuspiciousApis = BasicBlockAttrBuilder.GetInvokedAndroidApis(Instructions)
Permissions, RestrictedApis = BasicBlockAttrBuilder.GetPermissionsAndApis(Apis, PMap,
RequestedPermissionList)
UsedPermissions = UsedPermissions.union(Permissions)
RestrictedApiSet = RestrictedApiSet.union(RestrictedApis)
SuspiciousApiSet = SuspiciousApiSet.union(SuspiciousApis)
for Instruction in Instructions:
URLSearch = re.search("https?://([\da-z\.-]+\.[a-z\.]{2,6}|[\d.]+)[^'\"]*", Instruction, re.IGNORECASE)
if URLSearch:
URL = URLSearch.group()
Domain = re.sub("https?://(.*)", "\g<1>",
re.search("https?://([^/:\\\\]*)", URL, re.IGNORECASE).group(), 0, re.IGNORECASE)
URLDomainSet.add(Domain)
# 得到Drebin论文中描述的集合S6, S5, S7
return UsedPermissions, RestrictedApiSet, SuspiciousApiSet, URLDomainSetProcessingDataForGetApkData函数
为给定的APK文件生成.data文件。
# 参数是apk文件的大地址, .apk文件的地址,pscout的映射
def ProcessingDataForGetApkData(ApkDirectoryPath, ApkFile, PMap):
'''
为给定的APK文件生成.data文件。
:param String ApkDirectoryPath: APK文件目录的绝对路径
:param String ApkFile: APK文件的绝对路径
:param PScoutMapping.PScoutMapping() PMap: API映射
:return Tuple(String, Boolean) 处理结果: (ApkFile, True/False)
True表示成功,False表示失败。
'''
try:
StartTime = time.time() # 记录开始时间
logger.info("Start to process " + ApkFile + "...") # 记录处理开始信息
print("Start to process " + ApkFile + "...") # 打印处理开始信息
DataDictionary = {}
# 从XML中获取相关信息
RequestedPermissionSet, ActivitySet, ServiceSet, ContentProviderSet, BroadcastReceiverSet, HardwareComponentsSet, IntentFilterSet = GetFromXML(
ApkDirectoryPath, ApkFile)
# 将集合转换为列表并存储在字典中
RequestedPermissionList = list(RequestedPermissionSet)
ActivityList = list(ActivitySet)
ServiceList = list(ServiceSet)
ContentProviderList = list(ContentProviderSet)
BroadcastReceiverList = list(BroadcastReceiverSet)
HardwareComponentsList = list(HardwareComponentsSet)
IntentFilterList = list(IntentFilterSet)
# 放到数据字典里面
DataDictionary["RequestedPermissionList"] = RequestedPermissionList
DataDictionary["ActivityList"] = ActivityList
DataDictionary["ServiceList"] = ServiceList
DataDictionary["ContentProviderList"] = ContentProviderList
DataDictionary["BroadcastReceiverList"] = BroadcastReceiverList
DataDictionary["HardwareComponentsList"] = HardwareComponentsList
DataDictionary["IntentFilterList"] = IntentFilterList
# 得到集合S2及其他
# 从指令中获取相关信息
UsedPermissions, RestrictedApiSet, SuspiciousApiSet, URLDomainSet = GetFromInstructions(ApkDirectoryPath,
ApkFile, PMap,
RequestedPermissionList)
# 将集合转换为列表并存储在字典中
UsedPermissionsList = list(UsedPermissions)
RestrictedApiList = list(RestrictedApiSet)
SuspiciousApiList = list(SuspiciousApiSet)
URLDomainList = list(URLDomainSet)
DataDictionary["UsedPermissionsList"] = UsedPermissionsList
DataDictionary["RestrictedApiList"] = RestrictedApiList
DataDictionary["SuspiciousApiList"] = SuspiciousApiList
DataDictionary["URLDomainList"] = URLDomainList
# 得到集合S6, S5, S7, S8
# 导出数据到JSON文件
CM.ExportToJson(os.path.splitext(ApkFile)[0] + ".data", DataDictionary)
except Exception as e:
FinalTime = time.time() # 记录结束时间
logger.error(e) # 记录错误信息
logger.error(ApkFile + " processing failed in " + str(FinalTime - StartTime) + "s...") # 记录特定错误信息
print(ApkFile + " processing failed in " + str(FinalTime - StartTime) + "s...")
return ApkFile, False
else:
FinalTime = time.time() # 记录结束时间
logger.info(ApkFile + " processed successfully in " + str(FinalTime - StartTime) + "s") # 记录处理成功信息
print(ApkFile + " processed successfully in " + str(FinalTime - StartTime) + "s")
return ApkFile, TrueGetAPK函数(设置进程池,调用上面生成.data的函数)
# 参数是# 使用的CPU核心数量 、恶意软件文件夹、良性软件文件夹
# 这段代码的功能是获取指定目录中的APK文件,并对其进行分析,提取相关数据并存储。每个APK文件将被处理,提取的数据显示在进度条中。
# 这个函数通过使用多进程处理来提高处理大量APK文件的效率,并使用进度条来显示处理进度。具体的处理逻辑在ProcessingDataForGetApkData函数中实现。
def GetApkData(ProcessNumber, *ApkDirectoryPaths):
'''
获取Apk文件的数据字典,并将其存储在ApkDirectoryPath中。
用于下一步的分类。
:param Tuple<string> *ApkDirectoryPaths: 包含Apk文件的目录的绝对路径
'''
ApkFileList = [] # 得到所有 .apk 文件列表
for ApkDirectoryPath in ApkDirectoryPaths:
ApkFileList.extend(CM.ListApkFiles(ApkDirectoryPath)) # 列出目录中后缀是.apk的APK文件
ApkFileList.extend(CM.ListFiles(ApkDirectoryPath, "")) # 列出目录中后缀不是.apk的所有文件
# 因为有些apk文件可能没有扩展名....
CWD = os.getcwd() # 获取当前工作目录 'E:\\0.code\\2014drebin\\drebin-master\\src'
os.chdir(os.path.join(CWD, "Modules")) # 切换到Modules目录
''' 切换当前工作目录以导入映射 '''
PMap = PScoutMapping.PScoutMapping() # 创建PScoutMapping对象 ,得到一个PermApiDictFromJson其中键是类名+方法名,值是权限名
os.chdir(CWD) # 切换回原来的工作目录
pool = mp.Pool(int(ProcessNumber)) # 创建进程池 ProcessNumber是设定并行处理任务的进程数
ProcessingResults = []
ScheduledTasks = []
ProgressBar = CM.ProgressBar() # 创建进度条对象
for ApkFile in ApkFileList: # ApkFile:'E:\\0.code\\2014drebin\\drebin-master\\data\\small_proto_apks\\malware\\000a067df9235aea987cd1e6b7768bcc1053e640b267c5b1f0deefc18be5dbe1.apk'
if CM.FileExist(os.path.splitext(ApkFile)[0] + ".data"): # 返回文件是否存在 检查是否已经存在对应的数据文件
pass
else:
# 获取APK文件所在目录路径
ApkDirectoryPath = os.path.split(ApkFile)[0]# 'E:\\0.code\\2014drebin\\drebin-master\\data\\small_proto_apks\\malware'
ScheduledTasks.append(ApkFile) # 将APK文件添加到计划任务列表
# 异步处理APK文件,使用apply_async方法将任务分配到进程池
ProcessingResults = pool.apply_async(ProcessingDataForGetApkData, args=(ApkDirectoryPath, ApkFile, PMap),
callback=ProgressBar.CallbackForProgressBar)
pool.close() # 关闭进程池并显示进度条:
if ProcessingResults:
ProgressBar.DisplayProgressBar(ProcessingResults, len(ScheduledTasks), type="hour")# 显示进度条
pool.join()
return测试main函数
if __name__ == '__main__':
# 设置测试参数
process_number = 4 # 设定并行处理任务的进程数
apk_directory_paths = ("../data/small_proto_apks/malware", "../data/small_proto_apks/goodware") # 设置包含 APK 文件的目录路径列表
# 调用 GetApkData 函数进行测试
GetApkData(process_number, *apk_directory_paths)GetApkData.py的完整代码
# -*- coding: utf-8 -*-
import sys
reload(sys)
sys.setdefaultencoding("utf-8") # 设置默认编码为utf-8
import os # 导入os模块,用于文件和目录操作
import time # 导入time模块,用于时间相关操作
sys.path.append("Modules") # 将Modules目录添加到系统路径
sys.path.append("Androguard") # 将Androguard目录添加到系统路径
import re # 导入正则表达式模块
import multiprocessing as mp # 导入多进程模块
import CommonModules as CM # 导入CommonModules模块并简写为CM
from CommonModules import logger # 从CommonModules模块中导入logger
from androguard.misc import AnalyzeAPK
# import androlyze # 导入androlyze模块,用于APK分析
from Modules import BasicBlockAttrBuilder as BasicBlockAttrBuilder # 导入BasicBlockAttrBuilder模块并简写
from Modules import PScoutMapping as PScoutMapping # 导入PScoutMapping模块并简写
from xml.dom import minidom # 导入minidom,用于解析XML
from lxml import etree
# 获取信息,APK文件目录路径, .APK文件路径 # 获得了7个信息
def GetFromXML(ApkDirectoryPath, ApkFile):
'''
从APK文件的Manifest文件中获取请求的权限等信息。
:param String ApkDirectoryPath: APK文件目录路径
:param String ApkFile: APK文件名
:return 请求的权限集合, 活动集合, 服务集合, 内容提供者集合, 广播接收器集合, 硬件组件集合, 意图过滤器集合
:rtype Set([String])
'''
ApkDirectoryPath = os.path.abspath(ApkDirectoryPath) # 获取绝对路径'E:\\0.code\\2014drebin\\drebin-master\\data\\small_proto_apks\\malware'
ApkFileName = os.path.splitext(ApkFile)[0] # 获取不带扩展名的文件名 'E:\\0.code\\2014drebin\\drebin-master\\data\\small_proto_apks\\malware\\SMS0016'
# 初始化集合,用于存储不同类型的信息
RequestedPermissionSet = set() # 请求的权限集合
ActivitySet = set() # 活动集合
ServiceSet = set() # 服务集合
ContentProviderSet = set() # 内容提供者集合
BroadcastReceiverSet = set() # 广播接收器集合
HardwareComponentsSet = set() # 硬件组件集合
IntentFilterSet = set() # 意图过滤器集合
try: # 反编译apk文件 并存储xml文件
ApkFile = os.path.abspath(ApkFile) # 获取APK文件的绝对路径
a, d, dx = AnalyzeAPK(ApkFile) # 正确解包AnalyzeAPK返回的元组 # 使用androlyze分析APK文件
# 写入AndroidManifest.xml到文件
# 使用 lxml 获取 AndroidManifest.xml 并格式化输出
manifest_xml = a.get_android_manifest_xml()
pretty_manifest_xml = etree.tostring(manifest_xml, pretty_print=True, encoding='UTF-8').decode('utf-8')
# 写入AndroidManifest.xml到文件
with open(os.path.splitext(ApkFile)[0] + ".xml", "w") as f:
f.write(pretty_manifest_xml)
# 打开一个新文件,用于存储解析后的XML
f.close() # 关闭文件
except Exception as e:
print(e)
logger.error(e) # 记录错误信息
logger.error("Executing Androlyze on " + ApkFile + " to get AndroidManifest.xml Failed.") # 记录特定错误信息
return
try:
f = open(ApkFileName + ".xml", "r") # 打开之前保存的XML文件 'E:\\0.code\\2014drebin\\drebin-master\\data\\small_proto_apks\\malware\\SMS0016.xml'
Dom = minidom.parse(f) # 解析XML文件
DomCollection = Dom.documentElement # 获取文档的根元素
# 1/获取uses-permission标签中的权限
DomPermission = DomCollection.getElementsByTagName("uses-permission")
for Permission in DomPermission:
if Permission.hasAttribute("android:name"):
RequestedPermissionSet.add(Permission.getAttribute("android:name"))
# 2、获取activity标签中的活动
DomActivity = DomCollection.getElementsByTagName("activity")
for Activity in DomActivity:
if Activity.hasAttribute("android:name"):
ActivitySet.add(Activity.getAttribute("android:name"))
# 3、获取service标签中的服务
DomService = DomCollection.getElementsByTagName("service")
for Service in DomService:
if Service.hasAttribute("android:name"):
ServiceSet.add(Service.getAttribute("android:name"))
# 4、获取provider标签中的内容提供者
DomContentProvider = DomCollection.getElementsByTagName("provider")
for Provider in DomContentProvider:
if Provider.hasAttribute("android:name"):
ContentProviderSet.add(Provider.getAttribute("android:name"))
# 5、获取receiver标签中的广播接收器
DomBroadcastReceiver = DomCollection.getElementsByTagName("receiver")
for Receiver in DomBroadcastReceiver:
if Receiver.hasAttribute("android:name"):
BroadcastReceiverSet.add(Receiver.getAttribute("android:name"))
# 6、获取uses-feature标签中的硬件组件
DomHardwareComponent = DomCollection.getElementsByTagName("uses-feature")
for HardwareComponent in DomHardwareComponent:
if HardwareComponent.hasAttribute("android:name"):
HardwareComponentsSet.add(HardwareComponent.getAttribute("android:name"))
# 7、获取intent-filter标签中的意图过滤器
DomIntentFilter = DomCollection.getElementsByTagName("intent-filter")
DomIntentFilterAction = DomCollection.getElementsByTagName("action")
for Action in DomIntentFilterAction:
if Action.hasAttribute("android:name"):
IntentFilterSet.add(Action.getAttribute("android:name"))
except Exception as e:
logger.error(e) # 记录错误信息
logger.error("Cannot resolve " + ApkDirectoryPath + "'s AndroidManifest.xml File!") # 记录特定错误信息
return RequestedPermissionSet, ActivitySet, ServiceSet, ContentProviderSet, BroadcastReceiverSet, HardwareComponentsSet, IntentFilterSet
finally:
f.close() # 关闭文件
return RequestedPermissionSet, ActivitySet, ServiceSet, ContentProviderSet, BroadcastReceiverSet, HardwareComponentsSet, IntentFilterSet
def GetFromInstructions(ApkDirectoryPath, ApkFile, PMap, RequestedPermissionList):
'''
获取APK文件所需的权限、使用的API和HTTP信息。
重载版本的GetPermissions。
:param String ApkDirectoryPath: APK文件目录路径
:param String ApkFile: APK文件名
:param PScoutMapping.PScoutMapping PMap: API映射
:param RequestedPermissionList List([String]): 请求的权限列表
:return 使用的权限集合, 受限API集合, 可疑API集合, URL域名集合
:rtype Set([String])
'''
UsedPermissions = set() # 1、使用的权限集合
RestrictedApiSet = set() # 2、受限API集合
SuspiciousApiSet = set() # 3、可疑API集合
URLDomainSet = set() # 4、URL域名集合
try:
ApkFile = os.path.abspath(ApkFile) # 获取APK文件的绝对路径
a, d, dx = AnalyzeAPK(ApkFile) # 分析APK文件
except Exception as e:
print(e)
logger.error(e) # 记录错误信息
logger.error("Executing Androlyze on " + ApkFile + " Failed.") # 记录特定错误信息
return
for cls in d:
for method in cls.get_methods():# method 是encodemethod类型 Lru/alpha/Alpha;-><clinit>()V [access_flags=static constructor] @ 0x2418
g = dx.get_method(method) #g是methodAnalysis类型 <analysis.MethodAnalysis Lru/alpha/Alpha;-><clinit>()V [access_flags=static constructor] @ 0x2418>
for BasicBlock in g.get_basic_blocks().get(): # DVMBasicBlock类型 <androguard.core.analysis.analysis.DVMBasicBlock instance at 0x000000001965A508>
Instructions = BasicBlockAttrBuilder.GetBasicBlockDalvikCode(BasicBlock) # 获取指令
Apis, SuspiciousApis = BasicBlockAttrBuilder.GetInvokedAndroidApis(Instructions)
Permissions, RestrictedApis = BasicBlockAttrBuilder.GetPermissionsAndApis(Apis, PMap,
RequestedPermissionList)
UsedPermissions = UsedPermissions.union(Permissions)
RestrictedApiSet = RestrictedApiSet.union(RestrictedApis)
SuspiciousApiSet = SuspiciousApiSet.union(SuspiciousApis)
for Instruction in Instructions:
URLSearch = re.search("https?://([\da-z\.-]+\.[a-z\.]{2,6}|[\d.]+)[^'\"]*", Instruction, re.IGNORECASE)
if URLSearch:
URL = URLSearch.group()
Domain = re.sub("https?://(.*)", "\g<1>",
re.search("https?://([^/:\\\\]*)", URL, re.IGNORECASE).group(), 0, re.IGNORECASE)
URLDomainSet.add(Domain)
# 得到Drebin论文中描述的集合S6, S5, S7
return UsedPermissions, RestrictedApiSet, SuspiciousApiSet, URLDomainSet
# 参数是apk文件的大地址, .apk文件的地址,pscout的映射
def ProcessingDataForGetApkData(ApkDirectoryPath, ApkFile, PMap):
'''
为给定的APK文件生成.data文件。
:param String ApkDirectoryPath: APK文件目录的绝对路径
:param String ApkFile: APK文件的绝对路径
:param PScoutMapping.PScoutMapping() PMap: API映射
:return Tuple(String, Boolean) 处理结果: (ApkFile, True/False)
True表示成功,False表示失败。
'''
try:
StartTime = time.time() # 记录开始时间
logger.info("Start to process " + ApkFile + "...") # 记录处理开始信息
print("Start to process " + ApkFile + "...") # 打印处理开始信息
DataDictionary = {}
# 从XML中获取相关信息
RequestedPermissionSet, ActivitySet, ServiceSet, ContentProviderSet, BroadcastReceiverSet, HardwareComponentsSet, IntentFilterSet = GetFromXML(
ApkDirectoryPath, ApkFile)
# 将集合转换为列表并存储在字典中
RequestedPermissionList = list(RequestedPermissionSet)
ActivityList = list(ActivitySet)
ServiceList = list(ServiceSet)
ContentProviderList = list(ContentProviderSet)
BroadcastReceiverList = list(BroadcastReceiverSet)
HardwareComponentsList = list(HardwareComponentsSet)
IntentFilterList = list(IntentFilterSet)
# 放到数据字典里面
DataDictionary["RequestedPermissionList"] = RequestedPermissionList
DataDictionary["ActivityList"] = ActivityList
DataDictionary["ServiceList"] = ServiceList
DataDictionary["ContentProviderList"] = ContentProviderList
DataDictionary["BroadcastReceiverList"] = BroadcastReceiverList
DataDictionary["HardwareComponentsList"] = HardwareComponentsList
DataDictionary["IntentFilterList"] = IntentFilterList
# 得到集合S2及其他
# 从指令中获取相关信息
UsedPermissions, RestrictedApiSet, SuspiciousApiSet, URLDomainSet = GetFromInstructions(ApkDirectoryPath,
ApkFile, PMap,
RequestedPermissionList)
# 将集合转换为列表并存储在字典中
UsedPermissionsList = list(UsedPermissions)
RestrictedApiList = list(RestrictedApiSet)
SuspiciousApiList = list(SuspiciousApiSet)
URLDomainList = list(URLDomainSet)
DataDictionary["UsedPermissionsList"] = UsedPermissionsList
DataDictionary["RestrictedApiList"] = RestrictedApiList
DataDictionary["SuspiciousApiList"] = SuspiciousApiList
DataDictionary["URLDomainList"] = URLDomainList
# 得到集合S6, S5, S7, S8
# 导出数据到JSON文件
CM.ExportToJson(os.path.splitext(ApkFile)[0] + ".data", DataDictionary)
except Exception as e:
FinalTime = time.time() # 记录结束时间
logger.error(e) # 记录错误信息
logger.error(ApkFile + " processing failed in " + str(FinalTime - StartTime) + "s...") # 记录特定错误信息
print(ApkFile + " processing failed in " + str(FinalTime - StartTime) + "s...")
return ApkFile, False
else:
FinalTime = time.time() # 记录结束时间
logger.info(ApkFile + " processed successfully in " + str(FinalTime - StartTime) + "s") # 记录处理成功信息
print(ApkFile + " processed successfully in " + str(FinalTime - StartTime) + "s")
return ApkFile, True
# 参数是# 使用的CPU核心数量 、恶意软件文件夹、良性软件文件夹
# 这段代码的功能是获取指定目录中的APK文件,并对其进行分析,提取相关数据并存储。每个APK文件将被处理,提取的数据显示在进度条中。
# 这个函数通过使用多进程处理来提高处理大量APK文件的效率,并使用进度条来显示处理进度。具体的处理逻辑在ProcessingDataForGetApkData函数中实现。
def GetApkData(ProcessNumber, *ApkDirectoryPaths):
'''
获取Apk文件的数据字典,并将其存储在ApkDirectoryPath中。
用于下一步的分类。
:param Tuple<string> *ApkDirectoryPaths: 包含Apk文件的目录的绝对路径
'''
ApkFileList = [] # 得到所有 .apk 文件列表
for ApkDirectoryPath in ApkDirectoryPaths:
ApkFileList.extend(CM.ListApkFiles(ApkDirectoryPath)) # 列出目录中后缀是.apk的APK文件
ApkFileList.extend(CM.ListFiles(ApkDirectoryPath, "")) # 列出目录中后缀不是.apk的所有文件
# 因为有些apk文件可能没有扩展名....
CWD = os.getcwd() # 获取当前工作目录 'E:\\0.code\\2014drebin\\drebin-master\\src'
os.chdir(os.path.join(CWD, "Modules")) # 切换到Modules目录
''' 切换当前工作目录以导入映射 '''
PMap = PScoutMapping.PScoutMapping() # 创建PScoutMapping对象 ,得到一个PermApiDictFromJson其中键是类名+方法名,值是权限名
os.chdir(CWD) # 切换回原来的工作目录
pool = mp.Pool(int(ProcessNumber)) # 创建进程池 ProcessNumber是设定并行处理任务的进程数
ProcessingResults = []
ScheduledTasks = []
ProgressBar = CM.ProgressBar() # 创建进度条对象
for ApkFile in ApkFileList: # ApkFile:'E:\\0.code\\2014drebin\\drebin-master\\data\\small_proto_apks\\malware\\000a067df9235aea987cd1e6b7768bcc1053e640b267c5b1f0deefc18be5dbe1.apk'
if CM.FileExist(os.path.splitext(ApkFile)[0] + ".data"): # 返回文件是否存在 检查是否已经存在对应的数据文件
pass
else:
# 获取APK文件所在目录路径
ApkDirectoryPath = os.path.split(ApkFile)[0]# 'E:\\0.code\\2014drebin\\drebin-master\\data\\small_proto_apks\\malware'
ScheduledTasks.append(ApkFile) # 将APK文件添加到计划任务列表
# 异步处理APK文件,使用apply_async方法将任务分配到进程池
ProcessingResults = pool.apply_async(ProcessingDataForGetApkData, args=(ApkDirectoryPath, ApkFile, PMap),
callback=ProgressBar.CallbackForProgressBar)
pool.close() # 关闭进程池并显示进度条:
if ProcessingResults:
ProgressBar.DisplayProgressBar(ProcessingResults, len(ScheduledTasks), type="hour")# 显示进度条
pool.join()
return
if __name__ == '__main__':
# 设置测试参数
process_number = 4 # 设定并行处理任务的进程数
apk_directory_paths = ("../data/small_proto_apks/malware", "../data/small_proto_apks/goodware") # 设置包含 APK 文件的目录路径列表
# 调用 GetApkData 函数进行测试
GetApkData(process_number, *apk_directory_paths)
生成了.data文件和xml文件

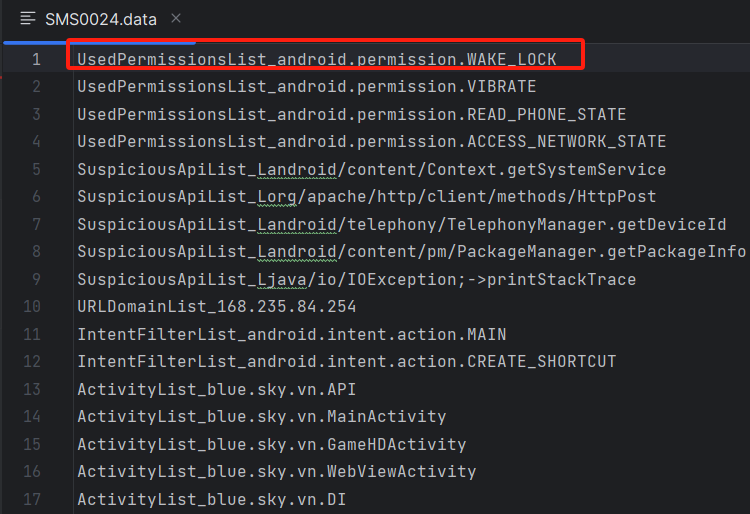
RandomClassification.py函数
导入类
# -*- coding: utf-8 -*-
import numpy as np
import time
from sklearn.model_selection import train_test_split # 用于将数据集拆分为训练集和测试集
from sklearn.feature_extraction.text import TfidfVectorizer as TF # 用于将文本转换为TF-IDF特征向量
from sklearn.model_selection import GridSearchCV # 用于进行网格搜索,以优化模型的参数
from sklearn.svm import LinearSVC # 用于训练线性支持向量机模型
from sklearn import metrics # 用于评估模型的性能
from sklearn.metrics import accuracy_score # 用于计算模型的准确率
import logging # 用于记录日志
import random # 用于生成随机数
import CommonModules as CM # 自定义模块,用于处理文件操作
from joblib import dump, load # 用于保存和加载模型
import json, os # 用于处理JSON文件和操作系统路径
from sklearn.feature_extraction.text import CountVectorizer as CVcustom_tokenizer函数按照行划分文本
def custom_tokenizer(text):
tokens = text.split('\n')
# 去掉每个 token 末尾的 '\r' 和前后的空格
tokens = [token.strip() for token in tokens]
print("Original text:\n{}".format(text))
print("Tokens after splitting by newline and stripping:\n{}".format(tokens))
return tokens加载数据
Logger.debug("Loading Malware and Goodware Sample Data")
AllMalSamples = CM.ListFiles(MalwareCorpus, ".data") # 列出所有恶意软件样本文件 以.data为后缀的地址
AllGoodSamples = CM.ListFiles(GoodwareCorpus, ".data") # 列出所有良性软件样本文件 以.data为后缀的地址
AllSampleNames = AllMalSamples + AllGoodSamples # 合并所有样本文件名
Logger.info("Loaded samples")二值划分特征,其中filename是一个列表(测试文档的地址列表)
E:\0.code\2014drebin\drebin-master\other1进行测试使用tfidf或者cv(记录在文档中)二值
FeatureVectorizer = CV(input='filename', tokenizer=custom_tokenizer, binary=True)
x = FeatureVectorizer.fit_transform(AllMalSamples + AllGoodSamples)加载标签
# 标签恶意软件为1,良性软件为-1
Mal_labels = np.ones(len(AllMalSamples)) # 为所有恶意软件样本创建标签
Good_labels = np.empty(len(AllGoodSamples)) # 为所有良性软件样本创建标签
Good_labels.fill(-1) # 将良性软件样本标签填充为-1
y = np.concatenate((Mal_labels, Good_labels), axis=0) # 合并标签数组
Logger.info("Label array - generated")划分数据集
所有样本列表前面是恶意的,后面是良性的,标签也是这样,所以一一对应了。
# 第二步:将所有样本拆分为训练集和测试集 # 返回的是训练和测试的样本地址和标签
x_train_samplenames, x_test_samplenames, y_train, y_test = train_test_split(AllSampleNames, y, test_size=TestSize,
random_state=random.randint(0,
100)) # 随机拆分样本生成训练和测试的特征向量
x_train = FeatureVectorizer.fit_transform(x_train_samplenames) # 生成训练集特征向量
x_test = FeatureVectorizer.transform(x_test_samplenames) # 生成测试集特征向量转换(transform):根据已经拟合好的模型(词汇表),将新数据转换为特征向量。
Logger.debug("Test set split = %s", TestSize)
Logger.info("train-test split done")使用GridSearchCV 和 LinearSVC 来进行网格搜索和交叉验证,以找到最佳的支持向量机 (SVM) 模型
# 第三步:训练模型
Logger.info("Perform Classification with SVM Model")
# 这里你定义了 C 参数的范围。C 是 SVM 的一个重要超参数,它决定了对错误分类的惩罚力度。值越大,对错误分类的惩罚越大。
Parameters = {'C': [0.001, 0.01, 0.1, 1, 10, 100, 1000]} # 定义超参数范围
T0 = time.time()
if not Model: # 使用 GridSearchCV 和 LinearSVC 来进行网格搜索和交叉验证,以找到最佳的支持向量机 (SVM) 模型
# LinearSVC():使用线性支持向量分类器。 Parameters:超参数的取值范围。 cv=5:使用 5 折交叉验证。scoring='f1':使用 F1 分数作为评估标准。
# n_jobs=1:使用单线程进行计算。你可以将其改为 -1 以使用所有可用的CPU核心。
Clf = GridSearchCV(LinearSVC(), Parameters, cv=5, scoring='f1', n_jobs=1) # 使用网格搜索和交叉验证寻找最佳模型
# 使用网格搜索和交叉验证寻找最佳模型
SVMModels = Clf.fit(x_train, y_train) # 训练模型
Logger.info(
"Processing time to train and find best model with GridSearchCV is %s sec." % (round(time.time() - T0, 2)))
BestModel = SVMModels.best_estimator_ # 获取最佳模型
Logger.info("Best Model Selected : {}".format(BestModel))
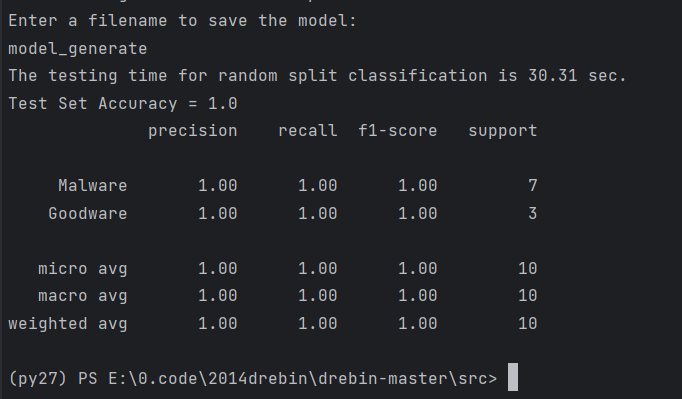
print "The training time for random split classification is %s sec." % (round(time.time() - T0, 2))
print "Enter a filename to save the model:"保存模型
print "The training time for random split classification is %s sec." % (round(time.time() - T0, 2))
print "Enter a filename to save the model:"
'''
为什么保存的是 Clf 而不是 BestModel
Clf 是 GridSearchCV 对象,它不仅包含了最佳模型 (best_estimator_),还包含了所有模型的评估结果、最佳参数组合等信息。
BestModel 是 Clf.best_estimator_,它是已经训练好的最佳模型实例,但不包含其他信息。
当你保存 Clf 时,你实际上保存了整个 GridSearchCV 对象,其中包括:
最佳模型 (best_estimator_)。
所有超参数组合的评估结果。
网格搜索的参数设定等。
'''
filename = raw_input() # 获取保存模型的文件名
dump(Clf, filename + ".pkl") # 保存模型,保存整个 GridSearchCV 对象可以让你在以后加载时看到所有尝试过的参数组合及其得分,而不仅仅是最佳模型。如果有保存好的模型,那么加载模型
else:
SVMModels = load(Model) # 加载已有模型
BestModel = SVMModels.best_estimator # 加载网格搜索里面的最佳模型
# 第四步:在测试集上评估最佳模型
# SVMModels 内部会调用最佳模型 best_estimator_ 的 predict 方法。因此,使用 SVMModels.predict(x_test) 实际上是通过最佳模型 best_estimator_ 进行预测。
y_pred = SVMModels.predict(x_test) # 预测测试集标签
print "The testing time for random split classification is %s sec." % (round(time.time() - T0, 2))
Accuracy = accuracy_score(y_test, y_pred) # 计算准确率
print "Test Set Accuracy = {}".format(Accuracy)
print(metrics.classification_report(y_test,
y_pred, labels=[1, -1],
target_names=['Malware', 'Goodware'])) # 打印分类报告
Report = "Test Set Accuracy = " + str(Accuracy) + "\n" + metrics.classification_report(y_test,
y_pred,
labels=[1, -1],
target_names=['Malware',
'Goodware'])对模型的特征进行解释(这部分写了一个单独的文档进行解释)
# 点乘权重和特征向量
w = BestModel.coef_
w = w[0].tolist()
v = x_test.toarray()
vocab = FeatureVectorizer.get_feature_names()
# 键是 'SMS0014.data'
explanations = {os.path.basename(s): {} for s in x_test_samplenames} # 初始化解释字典os.path.basename(s) 会返回路径 s 的基本名称(即文件名),去掉了任何目录路径。
for i in range(v.shape[0]):
wx = v[i, :] * w # 计算每个特征的权重
# zip(wx, vocab) 生成的迭代器包含以下元组:[(0.1, 'feature1'), (-0.03, 'feature2'), (0.08, 'feature3')]。
wv_vocab = list(zip(wx, vocab))
if y_pred[i] == 1:
wv_vocab.sort(reverse=True) # 对特征权重排序
explanations[os.path.basename(x_test_samplenames[i])]['top_features'] = wv_vocab[
:NumTopFeats] # 取前NumTopFeats个特征
elif y_pred[i] == -1:
wv_vocab.sort()
explanations[os.path.basename(x_test_samplenames[i])]['top_features'] = wv_vocab[-NumTopFeats:]
explanations[os.path.basename(x_test_samplenames[i])]['original_label'] = y_test[i]
explanations[os.path.basename(x_test_samplenames[i])]['predicted_label'] = y_pred[i]
with open('explanations_RC.json', 'w') as FH:
json.dump(explanations, FH, indent=4) # 保存解释字典为JSON文件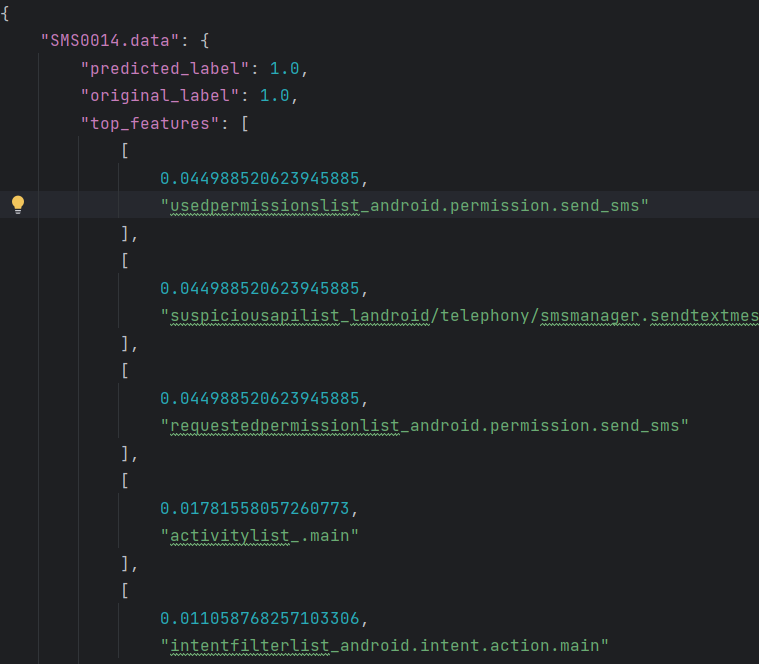
RandomClassification.py全部代码
# -*- coding: utf-8 -*-
import numpy as np
import time
from sklearn.model_selection import train_test_split # 用于将数据集拆分为训练集和测试集
from sklearn.feature_extraction.text import TfidfVectorizer as TF # 用于将文本转换为TF-IDF特征向量
from sklearn.model_selection import GridSearchCV # 用于进行网格搜索,以优化模型的参数
from sklearn.svm import LinearSVC # 用于训练线性支持向量机模型
from sklearn import metrics # 用于评估模型的性能
from sklearn.metrics import accuracy_score # 用于计算模型的准确率
import logging # 用于记录日志
import random # 用于生成随机数
import CommonModules as CM # 自定义模块,用于处理文件操作
from joblib import dump, load # 用于保存和加载模型
import json, os # 用于处理JSON文件和操作系统路径
from sklearn.feature_extraction.text import CountVectorizer as CV
# 配置日志记录
logging.basicConfig(level=logging.INFO)
Logger = logging.getLogger('RandomClf.stdout')
Logger.setLevel("INFO")
# 这行代码创建或获取一个名为 'RandomClf.stdout' 的日志记录器。这个命名日志记录器可以独立于根日志记录器进行配置。
# 命名日志记录器的好处是可以更细粒度地控制不同部分代码的日志记录行为,例如不同模块可以有不同的日志配置(日志记录级别)。
def custom_tokenizer(text):
tokens = text.split('\n')
# 去掉每个 token 末尾的 '\r' 和前后的空格
tokens = [token.strip() for token in tokens]
# print("Original text:\n{}".format(text))
# print("Tokens after splitting by newline and stripping:\n{}".format(tokens))
return tokens
def RandomClassification(MalwareCorpus, GoodwareCorpus, TestSize, FeatureOption, Model, NumTopFeats):
'''
使用支持向量机技术训练一个分类器,用于分类恶意软件和良性软件。
计算分类器的预测准确率和f1分数。
从Jiachun的代码修改而来。
:param String MalwareCorpus: 恶意软件语料库的绝对路径
:param String GoodwareCorpus: 良性软件语料库的绝对路径
:param String FeatureOption: tfidf或binary,指定如何构建特征向量
:rtype String Report: 结果报告
'''
# 第一步:创建特征向量
Logger.debug("Loading Malware and Goodware Sample Data")
AllMalSamples = CM.ListFiles(MalwareCorpus, ".data") # 列出所有恶意软件样本文件 以.data为后缀的地址
AllGoodSamples = CM.ListFiles(GoodwareCorpus, ".data") # 列出所有良性软件样本文件 以.data为后缀的地址
AllSampleNames = AllMalSamples + AllGoodSamples # 合并所有样本文件名
Logger.info("Loaded samples")
# input='filename': 指定输入是文件名。这意味着 TfidfVectorizer 将从文件中读取数据,而不是直接传递的文本数据。 tokenizer=lambda x: x.split('\n'): 指定一个自定义的分词器。这里使用一个 lambda 函数,将输入文本按行分割,这样每一行将作为一个单独的词。token_pattern=None: 指定不使用默认的正则表达式分词器,因为我们已经提供了一个自定义的 tokenizer。binary=FeatureOption: 指定是否使用二值化选项。FeatureOption 可以是 True 或 False,如果是 True,则特征向量中的每个元素表示该词是否在文档中出现过(即二值化);如果是 False,则表示 TF-IDF 权重。
# FeatureVectorizer = TF(input='filename', tokenizer=lambda x: x.split('\n'), token_pattern=None,binary=FeatureOption) # 初始化TF-IDF特征向量生成器
# x = FeatureVectorizer.fit_transform(AllMalSamples + AllGoodSamples) # 生成特征向量
# 使用 CountVectorizer 加载文件并生成二值特征向量
FeatureVectorizer = CV(input='filename', tokenizer=custom_tokenizer, binary=True)
x = FeatureVectorizer.fit_transform(AllMalSamples + AllGoodSamples)
# 标签恶意软件为1,良性软件为-1
Mal_labels = np.ones(len(AllMalSamples)) # 为所有恶意软件样本创建标签
Good_labels = np.empty(len(AllGoodSamples)) # 为所有良性软件样本创建标签
Good_labels.fill(-1) # 将良性软件样本标签填充为-1
y = np.concatenate((Mal_labels, Good_labels), axis=0) # 合并标签数组
Logger.info("Label array - generated")
# 第二步:将所有样本拆分为训练集和测试集 # 返回的是训练和测试的样本地址和标签
x_train_samplenames, x_test_samplenames, y_train, y_test = train_test_split(AllSampleNames, y, test_size=TestSize,
random_state=random.randint(0,
100)) # 随机拆分样本
x_train = FeatureVectorizer.fit_transform(x_train_samplenames) # 生成训练集特征向量
x_test = FeatureVectorizer.transform(x_test_samplenames) # 生成测试集特征向量转换(transform):根据已经拟合好的模型(词汇表),将新数据转换为特征向量。
Logger.debug("Test set split = %s", TestSize)
Logger.info("train-test split done")
# 第三步:训练模型
Logger.info("Perform Classification with SVM Model")
# 这里你定义了 C 参数的范围。C 是 SVM 的一个重要超参数,它决定了对错误分类的惩罚力度。值越大,对错误分类的惩罚越大。
Parameters = {'C': [0.001, 0.01, 0.1, 1, 10, 100, 1000]} # 定义超参数范围
'''
iid 参数的作用
iid=True:假设数据是独立同分布的。这意味着在计算交叉验证得分时,会对各个测试集的得分进行加权平均,权重与测试集的大小成比例。
iid=False:不假设数据是独立同分布的。这意味着在计算交叉验证得分时,会对各个测试集的得分直接取平均值,而不考虑测试集的大小。
'''
T0 = time.time()
if not Model: # 使用 GridSearchCV 和 LinearSVC 来进行网格搜索和交叉验证,以找到最佳的支持向量机 (SVM) 模型
# LinearSVC():使用线性支持向量分类器。 Parameters:超参数的取值范围。 cv=5:使用 5 折交叉验证。scoring='f1':使用 F1 分数作为评估标准。
# n_jobs=1:使用单线程进行计算。你可以将其改为 -1 以使用所有可用的CPU核心。
Clf = GridSearchCV(LinearSVC(max_iter=10000), Parameters, cv=5, scoring='f1', n_jobs=1, iid=True) # 使用网格搜索和交叉验证寻找最佳模型
# 使用网格搜索和交叉验证寻找最佳模型
SVMModels = Clf.fit(x_train, y_train) # 训练模型12
Logger.info(
"Processing time to train and find best model with GridSearchCV is %s sec." % (round(time.time() - T0, 2)))
BestModel = SVMModels.best_estimator_ # 获取最佳模型
Logger.info("Best Model Selected : {}".format(BestModel))
print "The training time for random split classification is %s sec." % (round(time.time() - T0, 2))
print "Enter a filename to save the model:"
'''
为什么保存的是 Clf 而不是 BestModel
Clf 是 GridSearchCV 对象,它不仅包含了最佳模型 (best_estimator_),还包含了所有模型的评估结果、最佳参数组合等信息。
BestModel 是 Clf.best_estimator_,它是已经训练好的最佳模型实例,但不包含其他信息。
当你保存 Clf 时,你实际上保存了整个 GridSearchCV 对象,其中包括:
最佳模型 (best_estimator_)。
所有超参数组合的评估结果。
网格搜索的参数设定等。
'''
filename = raw_input() # 获取保存模型的文件名
dump(Clf, filename + ".pkl") # 保存模型,保存整个 GridSearchCV 对象可以让你在以后加载时看到所有尝试过的参数组合及其得分,而不仅仅是最佳模型。
else:
SVMModels = load(Model) # 加载已有模型
BestModel = SVMModels.best_estimator # 加载网格搜索里面的最佳模型
# 第四步:在测试集上评估最佳模型
# SVMModels 内部会调用最佳模型 best_estimator_ 的 predict 方法。因此,使用 SVMModels.predict(x_test) 实际上是通过最佳模型 best_estimator_ 进行预测。
y_pred = SVMModels.predict(x_test) # 预测测试集标签
print "The testing time for random split classification is %s sec." % (round(time.time() - T0, 2))
Accuracy = accuracy_score(y_test, y_pred) # 计算准确率
print "Test Set Accuracy = {}".format(Accuracy)
print(metrics.classification_report(y_test,
y_pred, labels=[1, -1],
target_names=['Malware', 'Goodware'])) # 打印分类报告
Report = "Test Set Accuracy = " + str(Accuracy) + "\n" + metrics.classification_report(y_test,
y_pred,
labels=[1, -1],
target_names=['Malware',
'Goodware'])
# 点乘权重和特征向量
w = BestModel.coef_
w = w[0].tolist()
v = x_test.toarray()
vocab = FeatureVectorizer.get_feature_names()
# 键是 'SMS0014.data'
explanations = {os.path.basename(s): {} for s in x_test_samplenames} # 初始化解释字典os.path.basename(s) 会返回路径 s 的基本名称(即文件名),去掉了任何目录路径。
for i in range(v.shape[0]):
wx = v[i, :] * w # 计算每个特征的权重
# zip(wx, vocab) 生成的迭代器包含以下元组:[(0.1, 'feature1'), (-0.03, 'feature2'), (0.08, 'feature3')]。
wv_vocab = list(zip(wx, vocab))
if y_pred[i] == 1:
wv_vocab.sort(reverse=True) # 对特征权重排序
explanations[os.path.basename(x_test_samplenames[i])]['top_features'] = wv_vocab[
:NumTopFeats] # 取前NumTopFeats个特征
elif y_pred[i] == -1:
wv_vocab.sort()
explanations[os.path.basename(x_test_samplenames[i])]['top_features'] = wv_vocab[-NumTopFeats:]
explanations[os.path.basename(x_test_samplenames[i])]['original_label'] = y_test[i]
explanations[os.path.basename(x_test_samplenames[i])]['predicted_label'] = y_pred[i]
with open('explanations_RC.json', 'w') as FH:
json.dump(explanations, FH, indent=4) # 保存解释字典为JSON文件
return Report # 返回报告
if __name__ == '__main__':
MalwareCorpus = "../data/small_proto_apks/malware"
GoodwareCorpus = "../data/small_proto_apks/goodware"
TestSize = 0.3
FeatureOption = True
Model = False
NumTopFeats = 30
RandomClassification(MalwareCorpus, GoodwareCorpus, TestSize, FeatureOption, Model, NumTopFeats)
结果(用很小的数据跑了一下):

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









