






IO多路复用是一种网络IO方式,通常也就是服务器接受客户端连接和请求的一种数据处理方式 。学习IO多路复用我们首先从传统网络IO开始谈起才能更好的理解多路复用IO。
阻塞IO
阻塞IO,服务器端在接受用户用户请求和读取用户数据都会受到阻塞,也就是我们的accept函数和read函数。
accept函数的阻塞无可厚非。我们来看看read函数阻塞点。IO多路复用也就是从read函数细节进行改进。
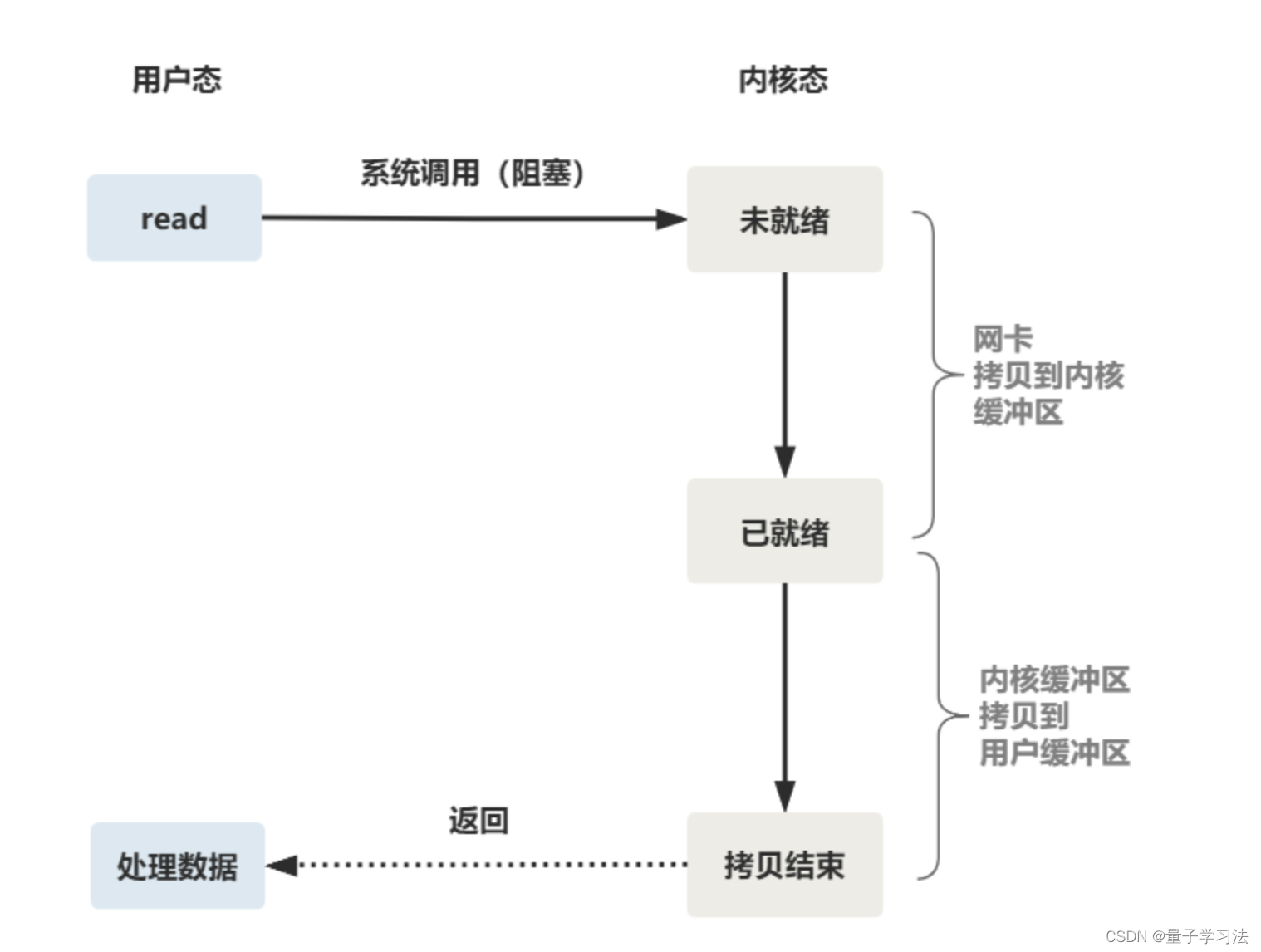
可以发现,阻塞点在于数据从网卡到内核缓冲区,再从内核缓冲区到用户缓冲区。因此,若用户一直不发送数据,我们的线程就一直卡在read函数上,这就是阻塞IO。
非阻塞IO
解决阻塞IO的方式,是每次在监听到客户端连接后,我们新创建一个线程去read客户数据。也就是说,此时,监听accept是一个线程,监听到后处理数据的是新创建的一个处理数据线程。伪代码:
while(1) {
connfd = accept(listenfd); // 阻塞建立连接
pthread_create(doWork); // 创建一个新的线程
}
void doWork() {
int n = read(connfd, buf); // 阻塞读数据
doSomeThing(buf); // 利用读到的数据做些什么
close(connfd); // 关闭连接,循环等待下一个连接
}这样我们的主线程函数(封装accept的函数)就不会卡在等待用户发送数据上。 不过,这不是非阻塞IO ,非阻塞IO也在于我们的操作系统在read函数上进行改进。这个 非阻塞IO的read 函数的效果是,如果没有数据到达时(到达网卡并拷贝到了内核缓冲区),立刻返回一个错误值(-1),而不是阻塞地等待。这里值得注意的是:非阻塞的 read,指的是在数据到达前,即数据还未到达网卡,或者到达网卡但还没有拷贝到内核缓冲区之前,这个阶段是非阻塞的。当数据已到达内核缓冲区,此时调用 read 函数仍然是阻塞的,需要等待数据从内核缓冲区拷贝到用户缓冲区,才能返回。 这样一个巨大好处就是:处理数据线程不会因为等待客户的数据而收到阻塞,因为我们拿到错误值-1了可以做其他事(这里的其他事就是下面IO多路复用遍历fd这件事)了,这就是所谓的非阻塞。
非阻塞IO的弊端是:每个客户端创建一个处理数据线程,服务器端的线程资源很容易被耗光。
所以我们将每 accept 一个客户端连接后,将这个文件描述符(connfd)放到一个数组里,然后弄一个新的线程去不断遍历这个数组,调用每一个元素的非阻塞 read 方法,若返回-1则继续遍历,否则则处理数据。
(3种多路复用开始!!!!!)
select
非阻塞IO这种方式每次遍历检查都需要调用系统read函数,若还碰到-1是极不划算的。所以,我们将遍历的事情交给OS内核来做,这样就不需要在用户态进行系统调用来遍历了。而这就是我们的select。
具体地,我们将一批文件描述符通过一次系统调用传给内核,由内核层去遍历,看看哪个数据已到达。

不过,当 select 函数返回后,用户依然需要遍历刚刚提交给操作系统的 list。
只不过,操作系统会将准备就绪的文件描述符做上标识,用户层将不会再有无意义的系统调用开销。

poll
poll和 select 的主要区别就是,去掉了 select 只能监听 1024 个文件描述符的限制。
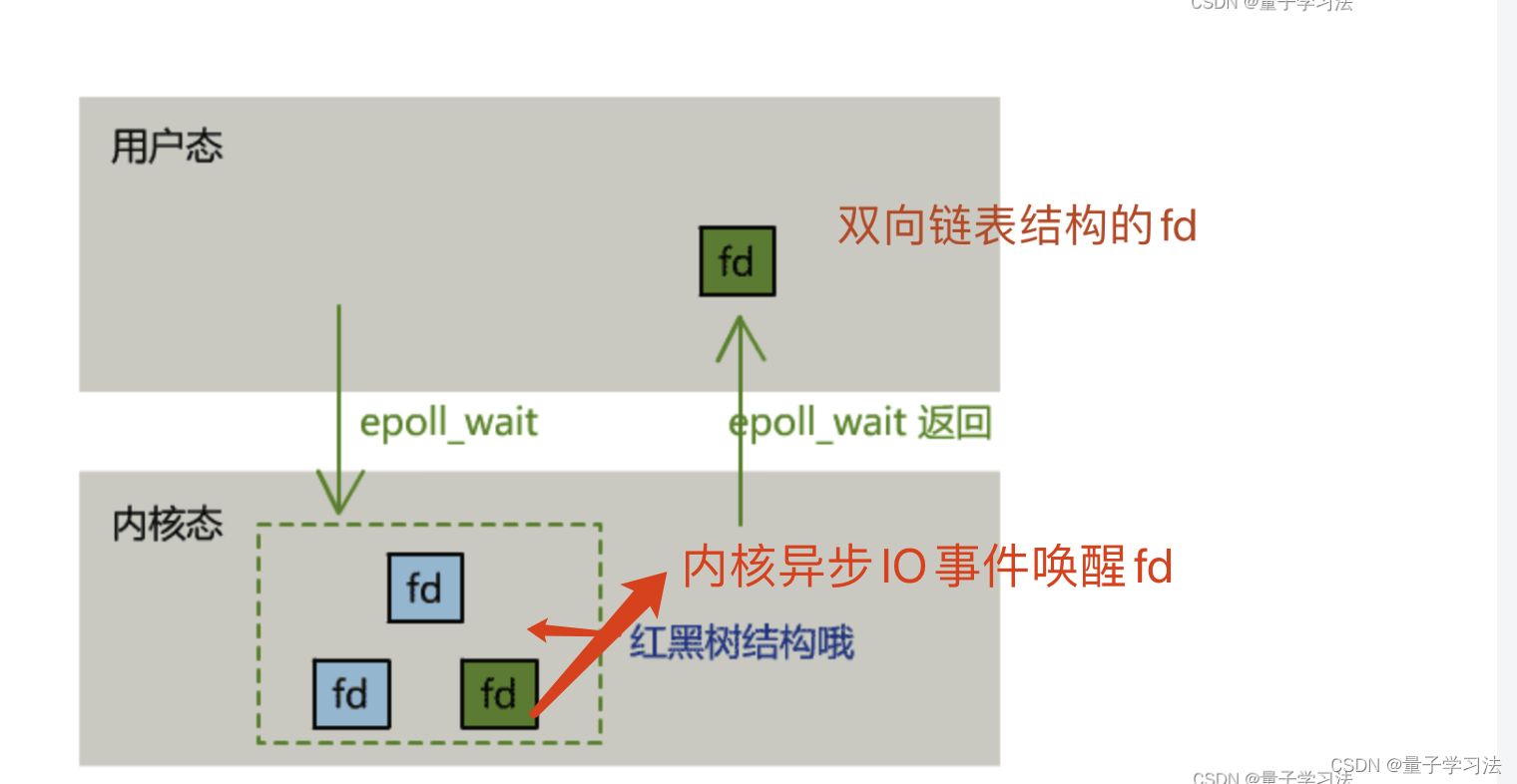
epoll
epoll的出现解决了select的3个细节的问题。

参考文献














 421
421











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









