








今天突发奇想,想要爬取一下知乎专栏文章的标题和链接,看看某个作者到底在这大几百几千篇文章中写了什么。
1. 观察网页
以https://zhuanlan.zhihu.com/c_1034016963944755200为例,我们所需要的每篇文章的所有信息,都被分别包括在一个类名为 ContentItem ArticleItem 的 div 标签对中:
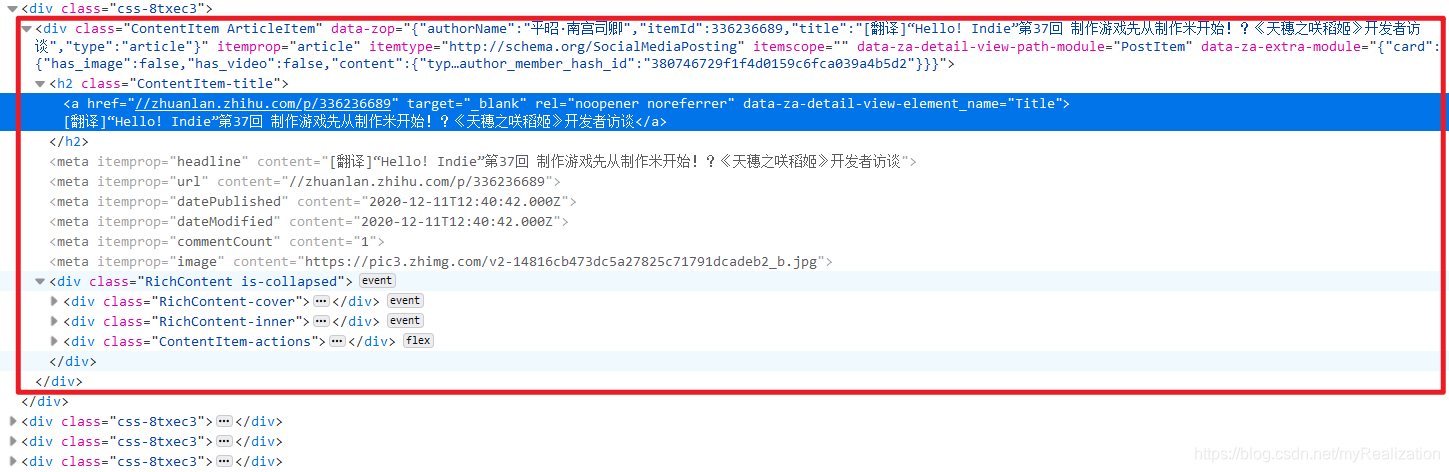
更准确的说,是一个类名为 ContentItem-title 的 <h2></h2> 标题元素中:
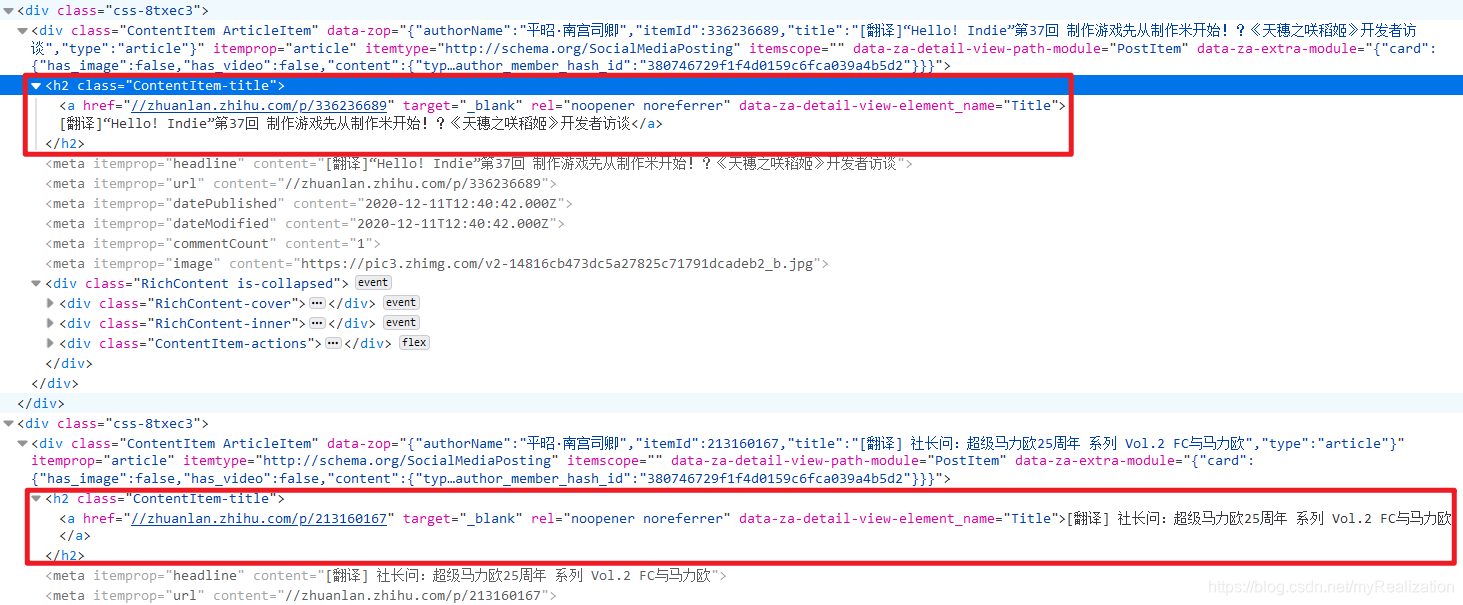
此外,还发现知乎专栏并不是一次性加载完该专栏的所有文章,而是随着侧滑栏向下滑动而逐渐加载,滑动到底部时以每10篇文章为单位进行加载,并在HTML文档中生成新的 <div></div> 元素:
这就有点麻烦了,不过也不算太难。进一步观察发现,每次加载新文章时会发送一个 GET 请求,返回的是JSON数据:

其中包含了我们想要的所有信息,包括文章标题、链接、摘要、作者等等:
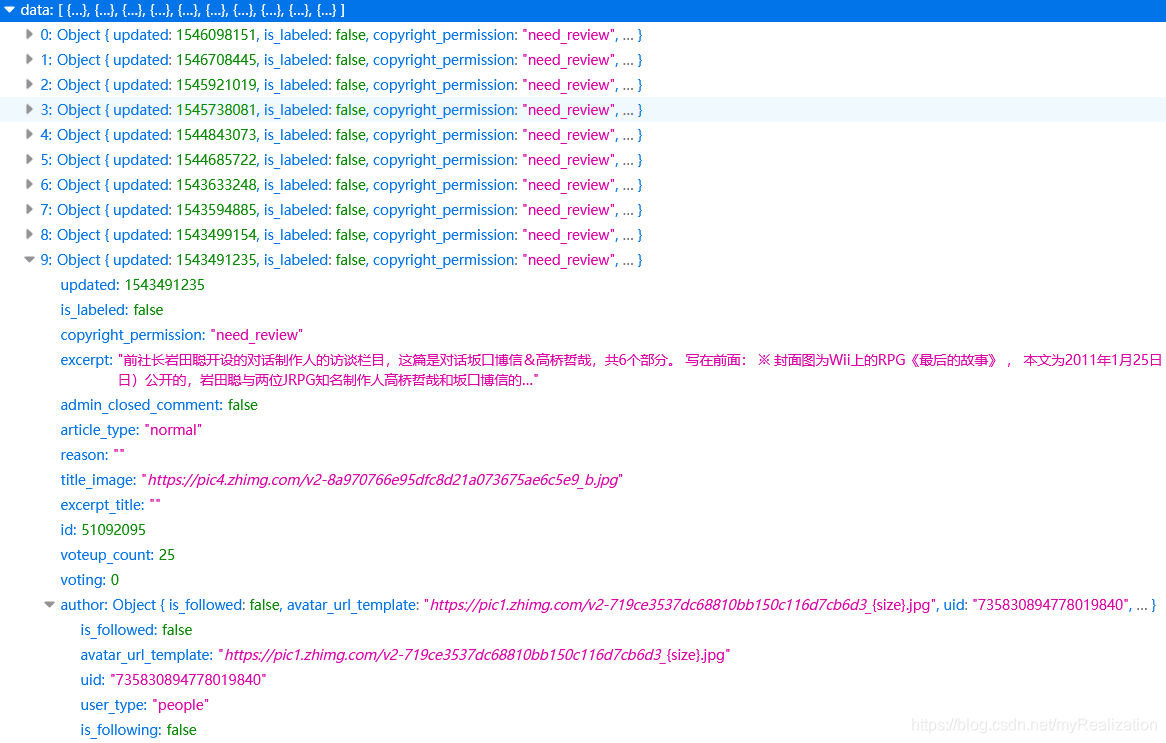
因此我们只需要不断请求这些JSON数据,进行解析得到结果,最后写入文件即可。
2. 实际代码
代码如下,就不仔细讲解了,反正很简单:
# -*- coding: utf-8 -*-
import os
import time
import requests
import csv
zhihuColumn = "c_1034016963944755200" # 自行替换专栏编号,此处是自娱自乐的游戏访谈录( 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1961
1961

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











