






具有拉普拉斯图先验的概率嵌入
Väinö Yrjänäinen 1 Måns Magnusson 11 Department of Statistics, Uppsala University, Uppsala, Sweden
摘要
我们使用拉普拉斯先验(PELP)引入概率嵌入。所提出的模型能够将图形侧信息合并到静态单词嵌入中。我们从理论上证明,模型将之前提出的几种嵌入方法统一在一个框架下。PELP概括了图形增强、分组、动态和跨语言静态单词嵌入。PELP还以一种简单的方式实现了这些之前型号的任意组合。此外,我们的经验表明,作为特例,我们的模型与以前模型的性能相匹配。此外,我们还通过将其应用于长期政治社会选择的比较来证明其灵活性。最后,我们提供了TensorFlow实现的代码,可以在不同的设置下进行灵活的估计。
1引言
单词嵌入是量化语言语义属性的常用方法,如单词的分布相似性和相关性[Allen等人,2019]。
单词嵌入已被广泛用于预测模型中的迁移学习[Kim,2014,Iyyer等人,2014],其他下游任务[Lilleberg等人,2015,Ma和Zhang,2015],以及最近,用于分析和测量社会科学和人文学科大型语料库中的意义和偏见[Tahmasebi等人,2018年,Brunet等人,2019年,Nguyen等人,2020年,Rodriguez和Spirling,2022年]。例如,Stoltz和Taylor[2020]在研究社会话语时,使用单词嵌入所跨越的“意义空间”来导航不同的意义结构。因此,单词嵌入已成为探索共同理解和文化意义的方法[Garg等人,2018年,Kozlowski等人,2019年,Hurtado Bodell等人,2019年,Rodman,2020年]。
概率词嵌入模型已经成为科学应用中的模型文本数据【Rudolph等人,2016年,Bamler和Mandt,2017年】。其优点包括灵活地包含先验知识、明确地处理不确定性、直接的估计和决策有用性[Ghahramani,2015]。更通用、更灵活的单词嵌入方法允许越来越复杂的研究用例,例如建模时间结构和数据中的不同作者[Stoltz和Taylor,2020]。事实上,鲁道夫等人[2016]的静态伯努利词嵌入已经扩展到处理社会科学家感兴趣的特定结构的新概率模型,例如动态嵌入[Rudolph and Blei,2018,Bamler and Mandt,2017],基于分组的嵌入[Rudolph et al.,2017],以及可解释的嵌入[Hurtado Bodell et al.,2019]。最近,使用变压器的情境化嵌入也开始使用概率框架对文本数据进行模型[例如,见Hofmann等人,2020年]。包括额外的信息,如单词图、作者或跨语言结构,是人们普遍感兴趣的,因为它进一步促进了对不同现象和关系的建模。然而,目前这种建模缺乏更通用的框架。
1.1概率词嵌入
作为一系列概率嵌入方法的一部分,Rudolph等人【2016】制定了伯努利嵌入模型。在模型中,一个包含N个单词vi的语料库 ∈ W表示为一个热向量
∈ W表示为一个热向量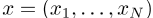 。
。
索引i中的每个单词都有一个对称的M大小的上下文窗口
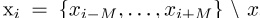
。xiv的条件分布是
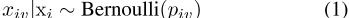
其中

其中σ(·)是逻辑函数。与Mikolov等人类似。
[2013b],伯努利分布用于近似模型中的分类分布。
每个单词类型v都有相应的单词和上下文向量 。ηiv值是嵌入向量ρv和位置i周围单词的上下文向量之和之间的内积。对于所有
。ηiv值是嵌入向量ρv和位置i周围单词的上下文向量之和之间的内积。对于所有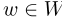 ,单词和上下文向量都遵循球形多元高斯分布,如
,单词和上下文向量都遵循球形多元高斯分布,如
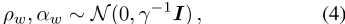
,其中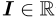 和
和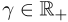 。参数ρ,α构成
。参数ρ,α构成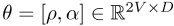 。
。
对于大型语料库,计算整个后验数据的期望值非常昂贵。相反,采用地图估算,其他数量的估算基于点估算进行计算[Rudolph and Blei,2018]。可能性包括所谓的正(x ps)和负(x ns)样本
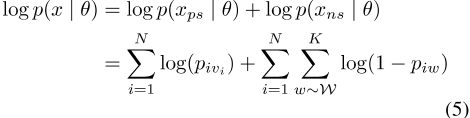
,其中vi是索引i处的单词类型,K是负样本数,W是单词类型的平滑经验分布。对于数据中的每个位置i,从W中抽取K个单词索引。CBOW可能性是伯努利嵌入后
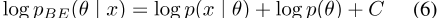
的一部分,其中先验p(θ)的定义如式(4)所示。Bamler和Mandt【2017】独立提出了一个使用SGNS可能性的类似概率嵌入模型。
1.2拉普拉斯图先验
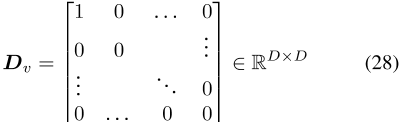
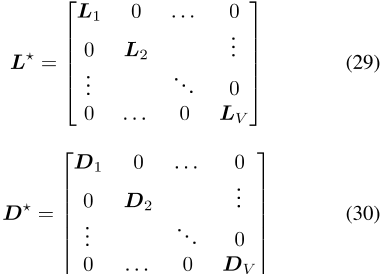
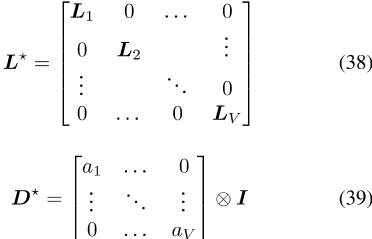
图G的拉普拉斯矩阵L(E为边集)定义为L=D− A,其中A是图的邻接矩阵,dis是图的度矩阵。拉普拉斯矩阵可以推广到加权图和有符号图,根据定义,所有这些拉普拉斯矩阵都是半正定的[Merris,1994,Das和Bapat,2005]。通过对拉普拉斯矩阵和任何正对角矩阵(最常见的是缩放单位矩阵)求和,增广拉普拉斯矩阵变得严格正定,并且是一个有效的精度矩阵∑− 1对于多元高斯分布[Strahl等人,2019]。我们用L+
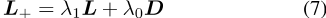
表示这种拉普拉斯精度矩阵,其中λ1,λ0∈ R+。任何可以呈现为无向图的边信息都可以用作先验信息。
拉普拉斯先验以这种方式用于矩阵分解[Cai等人,2010]、图像分类[Zheng等人,2010]和图像去噪[Liu等人,2014]等任务。
1.3单词嵌入中的图形侧信息
已经有几次尝试将旁白信息合并到单词嵌入中。Faruqui等人[2014]通过对WordNet图上的嵌入进行事后更正或改进,在多个任务中提高了单词嵌入性能。后来,Tissier等人(2017年)通过使用dict2vec嵌入模型从字典中获取的辅助信息来增强单词嵌入的准确性。他们的方法是基于单词定义中的倒数出现。然后,他们用链接对气体阳性样本x ps,G修正其可能性,得出以下可能性函数
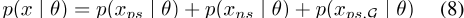
这种方法大大提高了模型在单词相似性任务上的性能[Tissier等人,2017年]。

表1:在dict2vec方法中,意识和意识这两个词在彼此的定义中都有提及,因此它们在图中形成了一条边。
1.4动态和分组嵌入模型
基于伯努利嵌入模型,Rudolph和Blei【2018】提出了动态伯努利模型(DBM),其中每个词向量被建模为随机游走。先验地,单词向量att=0分布在所有单词类型w的
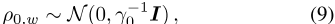
中∈ 适用于所有时间步t的魔杖∈ {1,2…,T}
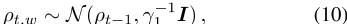
对于所有单词类型w∈ W,而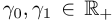 和I是一维单位矩阵。上下文向量在时间步之间共享,并按等式分布。
和I是一维单位矩阵。上下文向量在时间步之间共享,并按等式分布。
(4) 对于所有单词类型w∈ W可能性与等式(5)相似,使用每个相关数据点的时间步长。
分层分组伯努利模型(GBM)[鲁道夫等人,2017年]与DBM相似,但语料库不是分时间步,而是分为两个或多个组∈ s每个单词w对应一组单词向量ρ0,w,以及实际单词向量ρs,w,s∈ S是正态分布的,群向量作为平均值
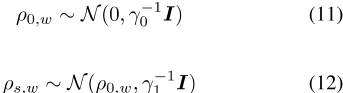
,其中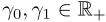 ],I是一维单位矩阵。
],I是一维单位矩阵。
上下文向量在组之间共享,并且对于所有单词类型w,如等式(4)所示分布∈ W该可能性与等式(5)中的相似,使用每个相关数据点的相应组。
1.5跨语言单词嵌入
跨语言单词嵌入嵌入两种或两种以上语言的单词{A,B,…}进入一个共享的嵌入空间。这可以通过使用多语言语料库和一个翻译对的图表来实现,这些翻译对组合在一组单词中。。。用语言A,B。
常用的映射方法首先分别训练单语嵌入,例如使用word2vec,然后找到使单词翻译对之间的平方差最小的映射 ,其中
,其中 是语言X中的一种单词类型[Ruder等人,2019年]。
是语言X中的一种单词类型[Ruder等人,2019年]。
已发现线性变换在实践中效果良好,例如优于前馈神经网络[Mikolov等人,2013a,Ruder等人,2019]。最佳线性变换最小化
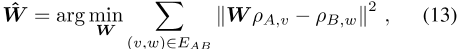
,其中ρA,v是语言A中v的词向量,ρB,w是语言B中的词向量。一些变体进一步限制线性变换矩阵是正交的,这已被发现可以改善嵌入的双语词典归纳性能[Xing等人,2015],同时保持单语距离[Smith等人,2017]。线性和正交映射的最优解具有闭式解[Artetxe等人,2016]。另一种常见的跨语言方法是伪多语言语料库方法。它使用常规嵌入方法,以12种概率随机交换翻译对E AB[Gouws and Søgaard,2015]。这种方法已被证明相当于对翻译对的词向量使用参数共享[Ruder等人,2019]。
1.6贡献和限制
本文介绍了拉普拉斯先验(PELP)模型的概率嵌入。我们将主要贡献总结如下:。
-
1、我们介绍了PELP模型,该模型可以使用连续词包(CBOW)或带负样本的跳跃图(SGNS)似然来包含任何无向图结构的边信息。
-
我们引入了一个跨语言的PELP模型来处理多种语言。
-
3.我们证明了PELP推广了许多以前的单语和跨语单词嵌入模型。
-
4.我们证明了PELP能够将多个先前的嵌入模型组合到联合模型中(例如,动态和组嵌入模型)。
-
5.我们提供了一个TensorFlow实现来估计具有不同拉普拉斯先验的概率单词嵌入。该实现允许GPU在大型语料库上对任何加权和未加权拉普拉斯算子进行并行处理。
虽然提议的PELP模型灵活且通用,但也有局限性。主要的限制是,如果我们将模型解释为先验,则图拉普拉斯先验中的边必然是对称的。因此,如果将有向图边信息作为先验信息正式包含在模型中,则必须将其视为无向信息。此外,与Hofmann等人[2020]中的transformer神经网络的上下文嵌入相比,本文中提出的嵌入是静态的。
2具有拉普拉斯先验的概率词嵌入
我们提出了具有拉普拉斯先验的概率嵌入(PELP)。模型将鲁道夫(Rudolph)等人[2016]提出的伯努利嵌入模型与拉普拉斯先验图相结合,既适用于CBOW模型,也适用于SGNS模型。然后将模型扩展到跨语言环境。本章描述了这些模型,并展示了它们的性质以及对以前模型的理论概括。
2.1单语PELP
设G是一个图(W,E),在W的词类集中有一组边
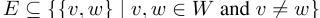
。我们可以根据公式(7)来建立一个拉普拉斯矩阵,从而得到一个正定拉普拉斯矩阵。由于每个单词类型v都有其专用的单词和上下文向量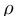
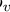

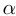
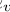 ,我们可以将其设置为
,我们可以将其设置为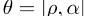 asp
asp
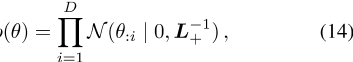
的先验分布的精度矩阵,其中dis是嵌入的维数,L+是等式(7)中定义的增广拉普拉斯矩阵。
在对数形式中,拉普拉斯先验成为加权图

的参数
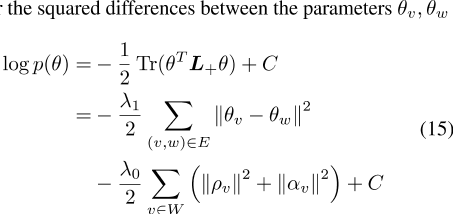
之间的平方差之和,
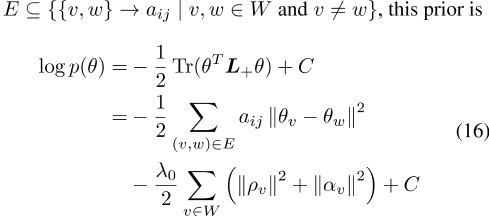
全后验是
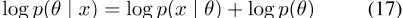
,其中似然对数p(x |θ)可以是CBOW或SGNS似然。在任何一种情况下,都使用负采样(等式5)。
2.2跨语言PELP
对于跨语言数据,PELP可以很容易地扩展到跨语言环境。对于两种语言A和B,跨语言PELP具有参数ρ=(ρA,ρB)和α=(αA,αB)以及θ=(ρA,ρB,αA,αB),这些参数也可以组织为θA=(ρA,αA)和θB=(ρB,αB)。可能性由单语可能性组成,其中x A、x分别表示语言A和B的数据。拉普拉斯曲线图由平移对组成,但也可以包含其他图形信息。跨语言拉普拉斯先验值可以表示为,其中λ1∈ R+是一个超参数,C是一个归一化常数。完全后验法是以前方法的
2.3推广
许多单词嵌入模型可以被视为特定拉普拉斯先验的特例,或者与具有特定图的拉普拉斯先验密切相关。在下一节中,我们将使用以下假设来证明以前的许多单词嵌入方法都是PELP模型的特例。
-
(a) 所比较的两个模型的似然函数是相同的,即都是第1.1节中定义的CBOW或SGN。
-
(b) 存在一个最大后验估计θ̂=arg maxθlog(θ| x)。
通过惩罚单词对之间的平方差,PELP与Faruqui(2014)的改进具有显著的相似性。然而,与Faruqui等人[2014]不同的是,在估计过程中应用了图形结构附加约束,这与Faruqui的方法不同,可能会间接影响边信息图之外的单词。此外,PELP与dict2vec密切相关[Tissier等人,2017年]。虽然dict2vec临时添加强对的正样本,但这些对的图结构可以用作拉普拉斯先验。我们用下面的命题来阐述这种理论关系。
命题1让dict2vec模型如等式(8)所示定义,并用所有单词类型v的前缀进行扩充∈ W此外,将PELP模型定义为定义2.1。进一步假设假设(a)-(b)成立,并假设G是dict2vec和PELP模型与增广拉普拉斯函数共享的图。
然后,对于dict2vec模型中的任何θ̂,都存在一个PELP模型,该模型具有特定的加权拉普拉斯函数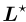 ,且增广对角矩阵
,且增广对角矩阵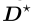 ,具有与dict2vec模型相同的平稳点。
,具有与dict2vec模型相同的平稳点。
证据1见附录。
文献中先前提出的一些先验也可以看作是PELP模型的特例。DBM Preor[Rudolph and Blei,2018]的图形表示将是跨越时间步的每个单词的链。这本质上是一个具有特定拉普拉斯L?的图。我们用以下命题来总结这个结果。
命题2将动态伯努利-模型(DBM)定义为等式(9-10)。此外,让PELP模型如式(14)-(17)所示定义,以便精度矩阵是图的拉普拉斯矩阵加上对角矩阵。假设两个模型中的参数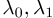 相同,并且假设(a)-(b)成立,则DBM和PELP模型是相同的。
相同,并且假设(a)-(b)成立,则DBM和PELP模型是相同的。
证据2见附录。
与DBM类似,第1.4节的GBM模型也可以被视为PELP模型的特例,使用另一个特定的拉普拉斯先验L。我们在下面的命题中总结了这一理论结果。
命题3让分组伯努利模型(GBM)如等式(11)-(12)中所定义的群s∈ S,设PELP模型定义为(14)-(17),并设G为PELP的拉普拉斯先验图。假设(a)-(b)和(c)图G只由每个群s的全连通子图组成∈ S,则存在精度矩阵为L?+DGBM与之相同。
证据3见附录。
在跨语言的情况下,完整的数据集由两种或两种以上语言的数据集组成{A,B…}。根据Ruder等人[2019]的说法,鉴于使用了相同的语料库和优化方法,一些跨语言方法是相似的。我们扩展了他们的结果并提出了以下两个命题,表明Gouws和Søgaard【2015】以及Artetxe等人【2016】是跨语言PELP模型的两个不同特例。我们将这些结果总结为以下两个命题。
命题4将跨语言PELP定义为定义2.2,将Gouws和Søgaard【2015】的伪多语言语料库模型(PML)定义为第1.5节,并将G简化为两个模型共享的翻译对图。如果假设(a)-(b)成立,那么跨语言PELP和PML在极限值上是相同的,如证据4所示。
命题5将定义2.2中定义的跨语言PELP和Artetxe等人[OMM 2016]的正交映射方法定义为定义13。另外,让G abbe表示两个模型共享的翻译对图。如果假设(a)-(b)成立,则跨语言PELP和OMM模型的MAP估计值在极限范围内相同,如证据5所示。
2.4 PELP模型的灵活性
拉普拉斯先验使PELP模型能够规范单词和上下文嵌入之间的关系,这在命题1中使用。一些辅助信息捕捉到的是两个单词之间的关联性,而不是相似性,这将有利于单词与上下文的连接,而不是单词之间的连接[Kiela等人,2015]。此外,对于未加权图和加权图都定义了PELP。这种总体结构可以包含不同信心或强度的旁侧信息。
此外,如第2.3节所示,许多先前提出的模型本质上是PELP模型的特例。这一事实使我们能够直接将以前的模型组合成新的联合模型,这些模型结合了不同的群体、动态、图形或跨语言结构。
事实上,我们在第3节中利用了这一点,在那里我们使用加权拉普拉斯算子为社会选民创建了一个动态模型,并引入了一个概率跨语言嵌入模型。
3个实验
我们的实证实验有两个目的。首先,我们想演示如何将PELP轻松地应用于一个新的社会科学用例。其次,我们希望通过实证建立与其他理论推导模型的联系,以便更好地理解潜在的差异。
PELP模型已使用TensorFlow实现,以简化使用GPU并行的大型语料库分析。
实现是一般的,任何加权或非加权拉普拉斯矩阵可以用于大语料库的大语料库,并与以前的实现速度一致。我们用来运行实验的代码可以在https://anonymous.
4打开。science/r/pelp-1740,补充材料中详细阐述了数据和硬件。
3.1动态党派关系嵌入
许多语料库自然地划分为多个感兴趣的子集。可以为此类设置配置PELP,例如利用与分组模型的连接。利用美国国会演讲语料库[Gentzkow et al.,2018],我们在分组和分组的动态环境中比较了共和党和民主党在演讲中使用的语言,使用我们的PELP实现来研究政治极化,这是政治学的一个重要领域[Monroe et al.,2017]。
我们的方法在为整个数据集分配一组上下文向量的同时,为每个单词在数据集的每个分区分配一个向量(例如,向量ρcat/R、向量ρcat/D)。我们用拉普拉斯先验对模型进行正则化。由于每个字符串都被分配了两个不同的词向量,我们将它们连接起来,在双方之间形成一个二部图。这组边E将由以下几对组成:(cat/D,cat/R),(狗/D,狗/R)。然后基于该图构造拉普拉斯先验,形成一个群体动态概率嵌入模型。
在获得点估计值后,我们使用欧几里德距离探索了向量空间,如Rudolph等人[2017]所述。
然后我们计算了双方之间最不一致的词语。如表2所示,估计的两极分化词是合理的,包括争议话题,如“税收”、“枪支”和“堕胎”,以及政党名称和州。没有拉普拉斯先验知识的参考模型提取了一些罕见的单词,这些单词具有一些看似合理的组差异,但显著性有限,限制了其在应用分析中的使用。
此外,我们通过简单地添加时间边(即
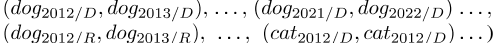
),将Socioloct模型推广到动态环境中。
在图表中。据我们所知,dynamicgroup嵌入模型在几年前还没有被研究过。我们在2004年至2011年间对演讲进行了实验,分为四个两年期。
作为参考,我们估计了一个伯努利嵌入模型,该模型与PELP共享上下文向量,但没有使用拉普拉斯先验。与静态情况类似,我们计算了双方之间差异最大的单词,如表3所示。考虑到时间框架和党派差异,从社会科学的角度来看,许多研究结果在几年内都具有积极意义。例如,次贷危机可以从2008-2009年“救济”的两极分化中看出。2010年美国医疗改革(平价医疗法案,ACA)反映了2010-2011年“健康”的两极分化。此外,“里根”在21世纪初是一个两极分化的词,而“奥巴马”在2010-2011年则更加两极分化。有些词看似两极分化,但并不具体到具体时间,例如“共和党”、“民主党”、“工会”和“债务”。如表4所示,具有模糊先验的参考模型拾取了大量噪声,表明了正则化在动态分组嵌入模型中的重要性。
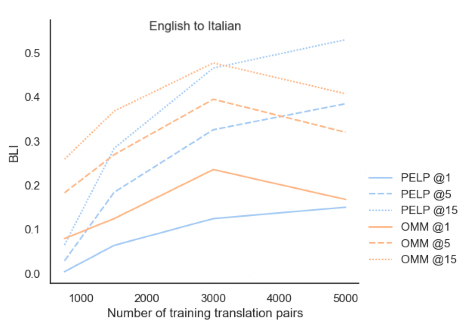
此外,我们在图1中可视化了一些两极分化的单词。我们可以看到共和党和民主党之间政治两极分化的暂时发展。
里根和奥巴马的两极分化反映了他们任期的时间距离。在ACA期间,“健康”的两极分化有所上升,而“恐怖主义”则在同一时期略有下降。

表2:ρw,R和ρw,D之间距离最大的前15个单词w。上面的PELP模型,下面的参考模型Bernoulli嵌入。
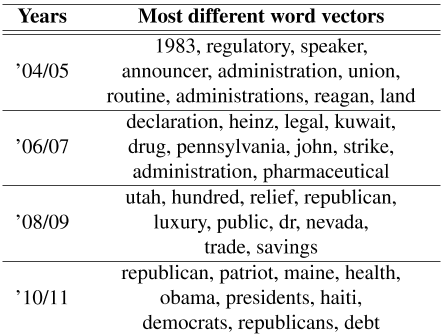
表3:随着时间的推移,ρw,R和ρw,D之间欧几里得距离最大的前10个最不同的单词w。
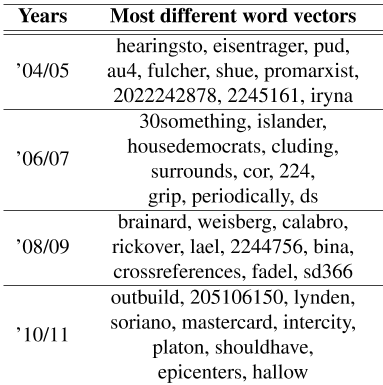
表4:参考模型:随着时间的推移,欧几里得距离最大的前10个最不同的单词w。
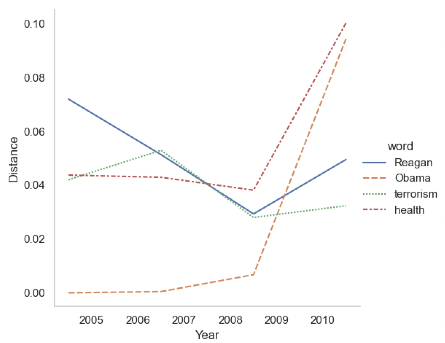
图1:随着时间的推移,一些词之间的党派差异。ρv,R和ρv,D之间的欧几里德距离。
3.2利用基于图形的信息改进单词嵌入
使用Tissier et al.(2017)的方法提取边信息,我们尝试使用字典知识来扩充模型。
我们从牛津大学、柯林斯大学、剑桥大学和字典下载了我们词汇表中所有可用的词汇定义。com字典。图表本身包括定义中的相互提及,如表1所示。由于单词出现在彼此的定义中,即上下文中,我们将单词和上下文向量联系起来。给定单词v和w之间的一条边,单词向量ρv和上下文向量αw被连接在一起,反之亦然。
这类似于Tissier等人[2017]中的单词上下文连接。
作为基线,我们运行了dict2vec【Tissier et al.,2017】模型和标准word2vec SGNS【Mikolov et al.,2013b】实现,这两种实现均由Tissier et al.提供。
[2017]. 我们只使用了Tissier等人[2017]所说的“强对”,正如前面所述,简单。dict2vec和PELP模型均省略了其模型中的“弱对”。word2vec实现是在标准配置下运行的。当我们比较PELP和dict2vec的性能时,我们在λ0上使用了类似的超参数搜索∈ { 0 . 1 , 0 . 5 , 1 , 2 . 5 , 5 } , λ 1 ∈ {1,2,4,6,8,10,12}以找到Tissier等人[2017]中所述的单词相似性任务的最佳性能。
我们使用了与Tissier等人[2017]用于dict2vec的评估方案相同的评估方案。这包括计算人类评估和嵌入空间中距离之间的斯皮尔曼等级相关性。使用了相同的评估集,即MC-30[Miller and Charles,1991]、MEN[Bruni et al.,2014]、MTurk-287[Radinsky et al.,2011]、MTurk-771[Halawi et al.,2012]、RG-65[rubenstein and Goodenough,1965]、RW[Luong et al.,2013]、SimVerb-3500[Gerz et al.,2016]、WordSim-353[finkelstein et al.,2001]和YP-130[Yang and Powers,2006]。
正如预期的那样,PELP和dict2vec在单词相似性任务上的表现都显著优于word2vec基线。
如表6所示,在大多数评估集上,PELP与人类评估的等级相关性略高于dict2vec。然而,正如我们的理论所预期的那样,总体差异很小。
有趣的是,Faruqui等人【2014年】发现,在训练期间,将平方误差正则化与相似图相结合的结果不佳。另一方面,PELP的类似正则化提高了性能。对此的一个可能解释是,我们实验中的PELP和dict2vec都使用单词上下文连接,而不是单词向量之间的连接。
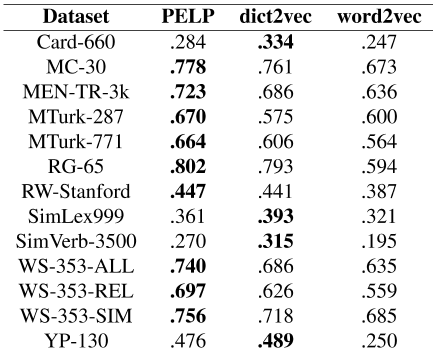
表5:每个评估数据集的单词相似性性能。在维基百科数据集上运行。
3.3跨语言PELP
为了评估第2节中介绍的跨语言PELP,我们估计了英语-意大利语的双语嵌入。
我们从维基百科语料库中统计了5000个最常见的意大利语单词,并从translate中获得了它们的英文翻译。谷歌。与Mikolov等人[2013a]类似。第5001到6000个最常见的单词用于评估。
作为基线,我们对使用Rudolph等人[2016]的Bernoulli嵌入模型估计的向量执行正交映射方法。我们使用标准设置,背景大小和阴性样本均为五个[Mikolov等人,2013b]。此外,我们对PELP的超参数进行了网格搜索,并像之前的实验一样选择了性能最好的参数。
为了评估跨语言嵌入的准确性,我们使用了双语词典归纳(BLI)任务,即从共享向量空间归纳单词翻译。如果通过余弦距离将正确的平移包含在k近邻中,则认为归纳成功,k是精度水平[Ruder等人,2019]。我们计算了精度级别1、5和15的BLI分数,如表7所示,在5000个翻译对中,PELP的表现略好于正交映射法。从意大利语到英语的翻译比从意大利语到英语的翻译要好,这可能是因为意大利语的词汇量更大,因此任务中的目标类也更多。如表7所示,PELP在大多数精度水平方向组合上都更好。观察到的差异是可以理解的,因为PELP仅在极限λ1内接近正交法→ 0(见提案5)。在某种意义上,PELP似乎是正交法和参数共享法之间的一个很好的中间模型,因为λ1值适中的PELP比λ1值较高的正交法和PELP产生的结果更好(更接近参数共享)。
图2:按模型、精度水平和翻译对数划分的双语词典归纳(BLI)性能。
如图2所示,这两种模型主要得益于拥有更多的翻译对。在翻译对较少的情况下,PELP的表现略差于正交法。在较少的翻译对下,较低的性能可能是优化过程的假象,因为与后验概率部分相比,少量翻译对是相对较弱的信号。
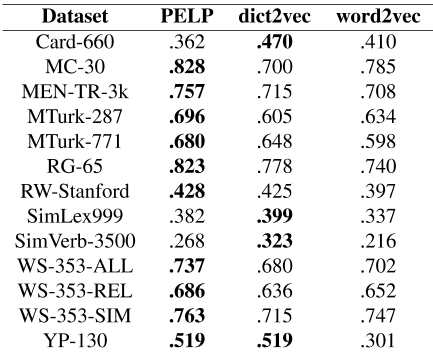
表6:每个评估数据集的单词相似性性能。在200M令牌维基百科数据集上运行。
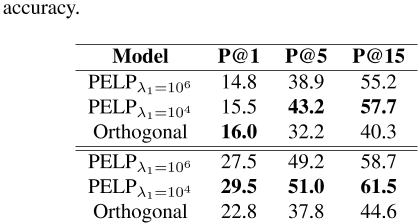
表7:英语双语词汇归纳(BLI)表现→ 它(上图)和它→ EN(见下)5000字对。
4结论
在本文中,我们介绍了一种基于图的先验概率词嵌入模型(PELP),它将以前的许多嵌入方法统一在一个通用的框架下。通过在一个新的用例中使用模型,分析政治社会选择随时间的变化,我们证明了PELP模型在社会科学应用中的灵活性。
此外,我们还表明,这种单一的模型在单语和跨语言的几个不同任务上的表现与以往的许多单词嵌入方法相当或更好。
PELP的通用性通过使用PELP模型为一大类嵌入模型打开了方法学发展的大门。此类未来工作的例子包括改进估计和估计参数不确定性。
此外,基于Hofmann等人[2020]的研究结果,我们相信在未来的工作中,我们有可能将我们的研究结果扩展到情境化嵌入。这将提供重要的见解,因为目前尚不清楚语境化嵌入在推理环境中是否一定优越[Rodriguez et al.,2021]。当前的模型被形式化为一个完全概率的模型,它将边信息限制为无向图。可以将正则化视为惩罚问题,并使用非对称矩阵L,即有向图。我们将这一概括留给未来的工作。
参考文献
Carl Allen, Ivana Balazevic, and Timothy Hospedales. What the vec? towards probabilistically grounded embeddings. In Advances in Neural Information Processing Systems , pages 7465–7475, 2019.
Mikel Artetxe, Gorka Labaka, and Eneko Agirre. Learning principled bilingual mappings of word embeddings while preserving monolingual invariance. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing , pages 2289–2294, 2016.
Robert Bamler and Stephan Mandt. Dynamic word embeddings. In International conference on Machine learning , pages 380–389. PMLR, 2017.
Marc-Etienne Brunet, Colleen Alkalay-Houlihan, Ashton Anderson, and Richard Zemel. Understanding the origins of bias in word embeddings. In Kamalika chaudhuri and Ruslan Salakhutdinov, editors, Proceedings of the 36th International Conference on Machine learning , volume 97 of Proceedings of Machine Learning Research , pages 803–811. PMLR, 09–15 Jun 2019. URL https://proceedings.mlr.press/v97/ brunet19a.html .
Elia Bruni, Nam-Khanh Tran, and Marco Baroni. multimodal distributional semantics. Journal of artificial intelligence research , 49:1–47, 2014.
Deng Cai, Xiaofei He, Jiawei Han, and Thomas S Huang. Graph regularized nonnegative matrix factorization for data representation. IEEE transactions on pattern analysis and machine intelligence , 33(8):1548–1560, 2010.
Kinkar Ch Das and RB Bapat. A sharp upper bound on the largest laplacian eigenvalue of weighted graphs. 2005.
Manaal Faruqui, Jesse Dodge, Sujay K Jauhar, Chris Dyer, Eduard Hovy, and Noah A Smith. Retrofitting word vectors to semantic lexicons. arXiv preprint arXiv:1411.4166 , 2014.
Lev Finkelstein, Evgeniy Gabrilovich, Yossi Matias, Ehud Rivlin, Zach Solan, Gadi Wolfman, and Eytan Ruppin. Placing search in context: The concept revisited. In proceedings of the 10th international conference on World Wide Web , pages 406–414, 2001.
Nikhil Garg, Londa Schiebinger, Dan Jurafsky, and James Zou. Word embeddings quantify 100 years of gender and ethnic stereotypes. Proceedings of the National Academy of Sciences , 115(16):E3635–E3644, 2018.
Matthew Gentzkow, Jesse M Shapiro, and Matt Taddy. congressional record for the 43rd-114th congresses: Parsed speeches and phrase counts. In URL: https://data. stanford. edu/congress text , 2018.
Daniela Gerz, Ivan Vulić, Felix Hill, Roi Reichart, and Anna Korhonen. Simverb-3500: A large-scale evaluation set of verb similarity. arXiv preprint arXiv:1608.00869 , 2016.
Zoubin Ghahramani. Probabilistic machine learning and artificial intelligence. Nature , 521(7553):452–459, 2015.
Stephan Gouws and Anders Søgaard. Simple task-specific bilingual word embeddings. In Proceedings of the 2015
Conference of the North American Chapter of the association for Computational Linguistics: Human Language Technologies , pages 1386–1390, 2015.
Guy Halawi, Gideon Dror, Evgeniy Gabrilovich, and Yehuda Koren. Large-scale learning of word relatedness with constraints. In Proceedings of the 18th ACM SIGKDD international conference on Knowledge discovery and data mining , pages 1406–1414, 2012.
Valentin Hofmann, Janet B Pierrehumbert, and Hinrich Schütze. Dynamic contextualized word embeddings. arXiv preprint arXiv:2010.12684 , 2020.
Miriam Hurtado Bodell, Martin Arvidsson, and Måns magnusson. Interpretable word embeddings via informative priors. arXiv preprint arXiv:1909.01459 , 2019.
Mohit Iyyer, Peter Enns, Jordan Boyd-Graber, and Philip Resnik. Political ideology detection using recursive neural networks. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages 1113–1122, 2014.
Douwe Kiela, Felix Hill, and Stephen Clark. Specializing word embeddings for similarity or relatedness. In proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing , pages 2044–2048, 2015.
Yoon Kim. Convolutional neural networks for sentence classification, 2014.
Austin C Kozlowski, Matt Taddy, and James A Evans. The geometry of culture: Analyzing the meanings of class through word embeddings. American Sociological review , 84(5):905–949, 2019.
Joseph Lilleberg, Yun Zhu, and Yanqing Zhang. Support vector machines and word2vec for text classification with semantic features. In 2015 IEEE 14th International conference on Cognitive Informatics & Cognitive Computing (ICCI* CC) , pages 136–140. IEEE, 2015.
Xianming Liu, Deming Zhai, Debin Zhao, Guangtao Zhai, and Wen Gao. Progressive image denoising through
hybrid graph laplacian regularization: A unified framework. IEEE Transactions on image processing , 23(4): 1491–1503, 2014.
Minh-Thang Luong, Richard Socher, and Christopher D Manning. Better word representations with recursive neural networks for morphology. In Proceedings of the Seventeenth Conference on Computational Natural language Learning , pages 104–113, 2013.
Long Ma and Yanqing Zhang. Using word2vec to process big text data. In 2015 IEEE International Conference on Big Data (Big Data) , pages 2895–2897. IEEE, 2015.
Russell Merris. Laplacian matrices of graphs: a survey. Linear algebra and its applications , 197:143–176, 1994. Tomáš Mikolov, Quoc V Le, and Ilya Sutskever. exploiting similarities among languages for machine translation. arXiv preprint arXiv:1309.4168 , 2013a.
Tomáš Mikolov, Ilya Sutskever, Kai Chen, Greg S Corrado, and Jeff Dean. Distributed representations of words and phrases and their compositionality. In Advances in neural information processing systems , pages 3111–3119, 2013b.
George A Miller and Walter G Charles. Contextual correlates of semantic similarity. Language and cognitive processes , 6(1):1–28, 1991.
Burt L. Monroe, Michael P. Colaresi, and Kevin M. Quinn. Fightin’ words: Lexical feature selection and evaluation for identifying the content of political conflict. political Analysis , 16(4):372–403, 2017. doi: 10.1093/pan/ mpn018.
Dong Nguyen, Maria Liakata, Simon DeDeo, Jacob eisenstein, David Mimno, Rebekah Tromble, and Jane Winters. How we do things with words: Analyzing text as social and cultural data. Frontiers in Artificial Intelligence , 3: 62, 2020.
Kira Radinsky, Eugene Agichtein, Evgeniy Gabrilovich, and Shaul Markovitch. A word at a time: computing word relatedness using temporal semantic analysis. In proceedings of the 20th international conference on World wide web , pages 337–346, 2011.
Emma Rodman. A timely intervention: Tracking the changing meanings of political concepts with word vectors. Political Analysis , 28(1):87–111, 2020. doi: 10.1017/pan. 2019.23.
Pedro L. Rodriguez and Arthur Spirling. Word embeddings: What works, what doesn’t, and how to tell the difference for applied research. The Journal of Politics , 84:101 – 115, 2022.
Pedro L Rodriguez, Arthur Spirling, and Brandon M stewart. Embedding regression: Models for context-specific description and inference. Technical report, Working Paper Vanderbilt University, 2021.
Herbert Rubenstein and John B Goodenough. Contextual correlates of synonymy. Communications of the ACM , 8 (10):627–633, 1965.
Sebastian Ruder, Ivan Vulić, and Anders Søgaard. A survey of cross-lingual word embedding models. Journal of Artificial Intelligence Research , 65:569–631, 2019.
Maja Rudolph and David Blei. Dynamic embeddings for language evolution. In Proceedings of the 2018 World Wide Web Conference , pages 1003–1011, 2018.
Maja Rudolph, Francisco Ruiz, Stephan Mandt, and David Blei. Exponential family embeddings. In Advances in Neural Information Processing Systems , pages 478–486, 2016.
Maja Rudolph, Francisco Ruiz, Susan Athey, and David Blei. Structured embedding models for grouped data. In Advances in neural information processing systems , pages 251–261, 2017.
Samuel L Smith, David HP Turban, Steven Hamblin, and Nils Y Hammerla. Offline bilingual word vectors, orthogonal transformations and the inverted softmax. arXiv preprint arXiv:1702.03859 , 2017.
Dustin S Stoltz and Marshall A Taylor. Cultural cartography with word embeddings. arXiv preprint arXiv:2007.04508 , 2020.
Jonathan Strahl, Jaakko Peltonen, Hiroshi Mamitsuka, and Samuel Kaski. Scalable probabilistic matrix factorization with graph-based priors. arXiv preprint arXiv:1908.09393 , 2019.
Nina Tahmasebi, Lars Borin, and Adam Jatowt. Survey of computational approaches to lexical semantic change. arXiv preprint arXiv:1811.06278 , 2018.
Julien Tissier, Christophe Gravier, and Amaury Habrard. Dict2vec: Learning word embeddings using lexical dictionaries. 2017.
Chao Xing, Dong Wang, Chao Liu, and Yiye Lin. normalized word embedding and orthogonal transform for bilingual word translation. In Proceedings of the 2015
Conference of the North American Chapter of the association for Computational Linguistics: Human Language Technologies , pages 1006–1011, 2015.
Dongqiang Yang and David Martin Powers. Verb similarity on the taxonomy of WordNet . Masaryk University, 2006.
Miao Zheng, Jiajun Bu, Chun Chen, Can Wang, Lijun Zhang, Guang Qiu, and Deng Cai. Graph regularized sparse coding for image representation. IEEE transactions on image processing , 20(5):1327–1336, 2010.
A.证据
这里我们列出了将在整个证明中使用的假设。
-
(a) 所比较的两个模型的似然函数是相同的,即都是第1.1节中定义的CBOW或SGN。
-
(b) 存在一个最大后验估计θ̂=arg maxθlog(θ| x)。
A.1命题1的证明
命题1将dict2vec模型定义为等式(8),并用ρv,αv进行扩充∼ N(0,γ)− 10 I)所有单词类型的优先顺序v∈ W此外,将PELP模型定义为定义2.1。进一步假设假设(a)-(b)成立,并假设G是dict2vec和PELP模型共享的图,其中增广拉普拉斯L+=L+D。
那么,对于dict2vec模型中的任何θ̂,都存在一个具有特定加权拉普拉斯L?增广对角矩阵D?与dict2vec模型具有相同的固定点。
证明1正则化Dict2Vec模型的后验值
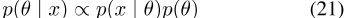
,其具有对数形式
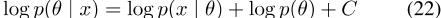
,其中C是常数。替换词对的正样本,我们得到
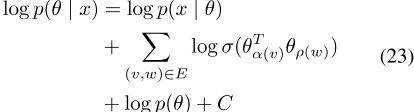
其中
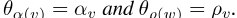
区分对数后验结果
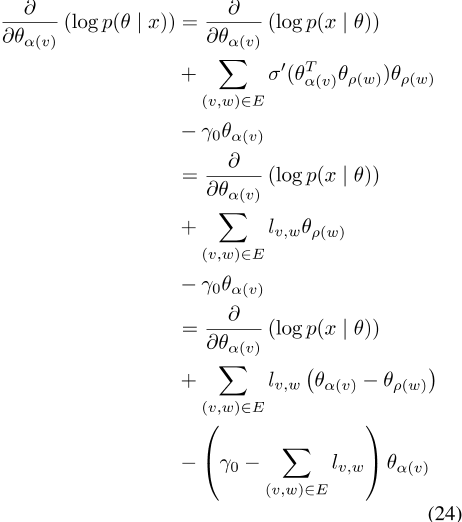
其中Ld2相对于由权重Lv,w定义的拉普拉斯矩阵,以及dis对角矩阵,其中Dv,v=γ0(如果词v没有连接)和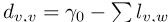 如果有连接。
如果有连接。
另一方面,加权SGNS PELP模型具有以下梯度
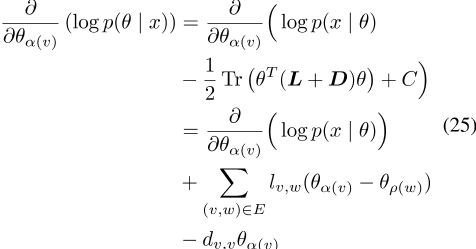
设置
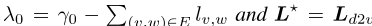
这些梯度相同。注意,你可以交换ρ(w)和α(v),这个关系成立。
此外,这两个损失函数在整个域中都是连续的,并且随着θ的增大,它们在所有方向上都接近负无穷大。因此,最大值出现在任一模型损失函数的临界点。由于另一个损失函数在任意点具有相同的梯度,因此它也在该最大值处共享零梯度。
A、 2命题2的证明:动态模型
命题2将动态伯努利-模型(DBM)定义为等式(9-10)。此外,让PELP模型如式(14)-(17)所示定义,以便精度矩阵是图的拉普拉斯矩阵加上对角矩阵。假设两个模型中的参数λ0、λ1相同,且假设(a)-(b)成立,则DBM和PELP模型相同。
证明2:在所有时间步t中,单个单词类型v的优先顺序∈ {1,2,…,T}是
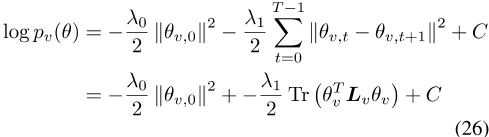
式中,L相对于边ev={(0,1),(1,2),…,(T)的图的拉普拉斯矩阵− 与v有关,C是常数。此外,第一项可以表示为对角线矩阵
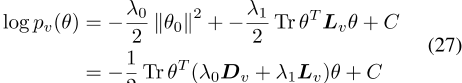
的轨迹,其中
 ]
]
基于单个词类型的先验信息,为所有词类型
构造拉普拉斯分布,并将θ的先验分布表示为高斯分布,拉普拉斯矩阵加对角线矩阵
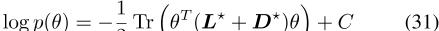
作为精度矩阵。
A、 3命题3的证明:分组模型
命题3让分组伯努利模型(GBM)如等式(11)-(12)中所定义的群s∈ S,设PELP模型定义为(14)-(17),并设G为PELP的拉普拉斯先验图。假设(a)-(b)和(c)图G只由每个群s的全连通子图组成∈ S,则存在精度矩阵为L?+DGBM与之相同。
证明3 GBM中的v类单词具有以下对数先验值
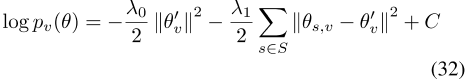
由于组参数不出现在似然函数中,它们的MAP估计值可以通过分析

获得,其中
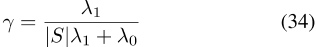
将通过分析获得的θ̂′v代入方程32,其MAP估计值可以表示为参数的平方差加上参数的范数之和
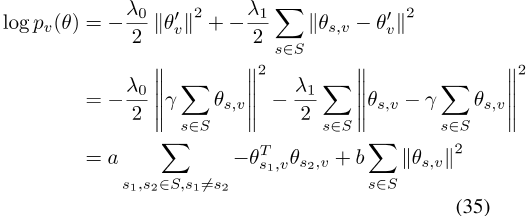
,其中,纯负常数。这反过来又可以组织成
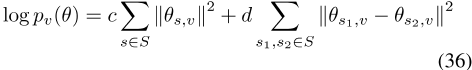
,其中c为负常数。这对应于拉普拉斯先验
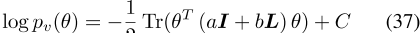
,其中I是ar D×D单位矩阵,L是群完全连通的图的拉普拉斯。基于单个单词类型的优先顺序v∈ W,为所有组
构造一个拉普拉斯矩阵,并将θ
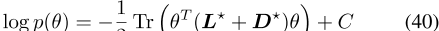
的先验分布表示为高斯分布,拉普拉斯矩阵加上对角线矩阵作为精度矩阵。
A、 4命题4的证明:跨语言模型A
命题4将跨语言PELP定义为定义2.2,将Gouws和Søgaard【2015】的伪多语言语料库模型(PML)定义为第1.5节,并将G简化为两个模型共享的翻译对图。如果假设(a)-(b)成立,则跨语言PELP和PML在限制范围内相同,如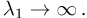 定义1跨语言PELP超过两种语言a、b,参数为
定义1跨语言PELP超过两种语言a、b,参数为
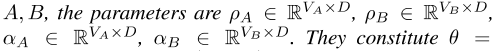
。它们构成θ=
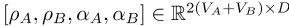
似然随后定义为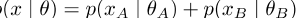 ]
]
,而之前的Tr(θtl+θ)由增广拉普拉斯算子定义,并在两个词上应用翻译对图(ρAi∼ ρBj)和上下文向量。
证明4跨语言PELP模型的后验值可以分解为似然值,而ρ和α的先验值可以分解为似然值,其中x是数据。ρ上的拉普拉斯先验是
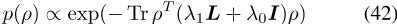
,可以进一步分解为
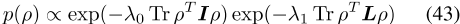
作为λ1→ ∞ , 前面的后一个因子接近0
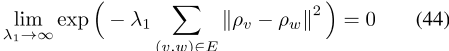
iff
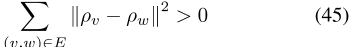
,其中E是翻译对的集合。当且仅当翻译对的所有词向量彼此相等时,此和为零。此外,如果和为零,则优先级为1。因此,只有在这种情况下,后验值才是非零的,这迫使向量是相同的。如Ruder等人【2019年】所示,Gouws和Søgaard【2015年】中提出的模型迫使翻译对在地图估计中保持一致。此外,Gouws和Søgaard【2015】的模型使用了与PELP相同的CBOW损失函数。因此,PELP和Gouws以及Søgaard【2015】的模型在极限上是等效的。
A.5命题5的证明:
跨语言模型B命题5将定义2.2中定义的跨语言PELP和正交映射方法Artetxe等人【OMM 2016】定义为定义13。另外,让G abbe表示两个模型共享的翻译对图。如果假设(a)-(b)成立,则跨语言PELP和OMM模型的MAP估计值在极限范围内相同,如证据5所示。PELP模型的后验值可以分解,其中x是数据。让没有拉普拉斯因子的后验概率为p0(θ| x)
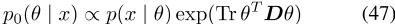
让我们进一步将其全局最优定义为集合H
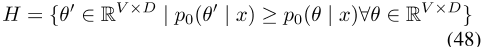
此外,让我们用一个简写的
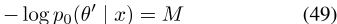
来表示全局最优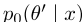 的值,现在让PELP的log posterior
的值,现在让PELP的log posterior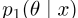 为
为
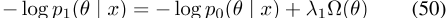
,其中拉普拉斯先验 为
为
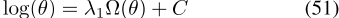
,
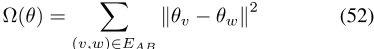
为对数拉普拉斯先验。asp 0(θ| x)是wrt不变的。θ在集合H中,完整的后部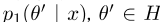 可以用
可以用
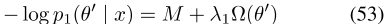
的形式表示,因为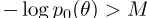 (严格地)对于所有
(严格地)对于所有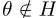 ,并且
,并且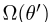 在集合H中对于所有θ/∈ H存在一个δ>0,对于所有λ1<δ,不等式
在集合H中对于所有θ/∈ H存在一个δ>0,对于所有λ1<δ,不等式
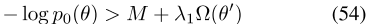
成立。因为所有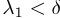 随后都认为
随后都认为
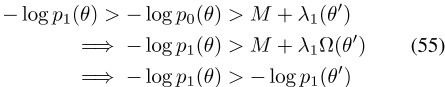
,因此,与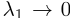 一样,no
一样,no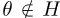 可以是
可以是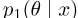 的全局最优值,因此其全局最优值必须在集合H中。
的全局最优值,因此其全局最优值必须在集合H中。
一种语言A的引理1p0是wrt不变的。正交变换
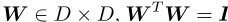
。
证明6语言A上的W变换P0是
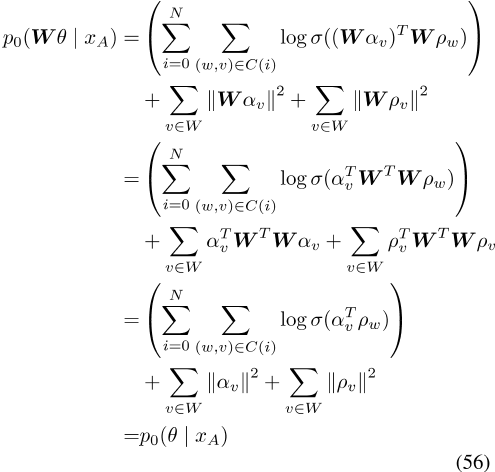
,这是原始的后验值。
引理2后p0是wrt不变的。仅适用于语言集合{A,B}中的语言A的正交变换。
证明7由于引理1,
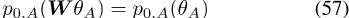
我们可以用语言A
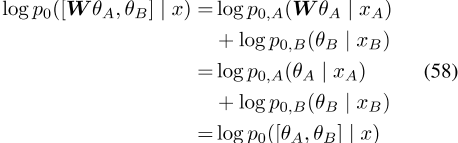
上的变换写出完整的句子,因此,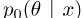 的每个单独的全局最优对应于它的一组正交变换。这些旋转只影响H中的总和
的每个单独的全局最优对应于它的一组正交变换。这些旋转只影响H中的总和
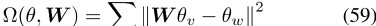
Ω -最小化旋转W是最佳选择。因此,旋转矩阵W最小的最优解也使集合H中的后验值最小。
正交映射法首先找到p0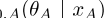 和
和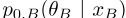 的单语最优θ′。由于双语版
的单语最优θ′。由于双语版
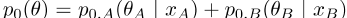
,这相当于优化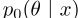 ,以及两个优化版的串联
,以及两个优化版的串联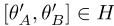 。因此,这一步在两种模型中都是相同的。
。因此,这一步在两种模型中都是相同的。
然后选择最小化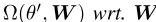 的正交映射。如图所示,PELP选择θ′∈ 其正交旋转也使
的正交映射。如图所示,PELP选择θ′∈ 其正交旋转也使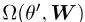 最小化,使两种方法在极限上相等。
最小化,使两种方法在极限上相等。
B数据、硬件和运行时
对于所有实验,使用了一个580 RX GPU和8GB的VRAM来运行实验。采用TensorFlow ROCm 3.8和TensorFlow概率0.11。每次运行时间大约为2到8分钟。这就意味着在15个时间点上有30分钟到2小时的完整运行时间。
该实现在CPU上进行了测试,不过在GPU上要快得多。
所有数据都转换为小写。标点符号和其他特殊字符被删除,但数字被保留。
意大利语保留了重音字符(如“è”)。
在第一个实验中,使用了美国国会的演讲数据。
根据提供的元数据,它被分为共和党和民主党的演讲。对于静态用例,使用了1.2亿个令牌子集。对于动态用例,使用了1.16亿个令牌子集,对应于8年的数据。
在第二个实验中,使用了最新英文维基百科的5000万和2亿个令牌分区。
在第三个实验中,使用了最新的英语和意大利语维基百科的5000万个令牌分区。对于这些模型,我们运行了200个时代以确保收敛。这在我们的硬件上花费了大约9个小时。















 839
839











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









