







##读取学生成绩数据
ReportCard<-read.table(file="ReportCard.txt",header=TRUE,sep=" ")
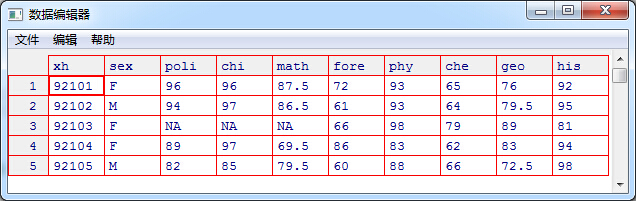
fix(ReportCard)
attach是将数据添加上内存中,一般用于数据框,添加之后就可以直接提取数据框的,否则用 $ 访问 ,但是一般用完都会detach()删除掉。
##计算政治课程的描述统计量A
attach(ReportCard)
(Av.Poli<-mean(poli)) ## Av.Poli是个整体,Av表示求均值,Sd表示求方差,Sum表示求和,只是一种命名方式
(Av.Poli<-mean(poli,na.rm=TRUE)) ## na.rm是个逻辑变量,表示是否去除空值
(Sd.Poli<-sd(poli,na.rm=TRUE))
(N<-length(poli[!is.na(poli)]))
(Skew.Poli<-sum((poli[!is.na(poli)]-Av.Poli)^3/Sd.Poli^3)/N)
(Kurt.Poli<-sum((poli[!is.na(poli)]-Av.Poli)^4/Sd.Poli^4)/N-3)
summary(poli)
detach(ReportCard)
###############利用Contrib包计算描述统计量
install.packages("psych")
library("psych")
> describe(ReportCard$poli) vars n mean sd median trimmed mad min max range skew kurtosis se 1 1 58 79.64 10.58 82.5 80.81 8.15 40 96 56 -1.31 2.05 1.39
关于apply的相关函数参见:
R中利用apply、tapply、lapply、sapply、mapply、table等函数进行分组统计
(Av.Course<-sapply(ReportCard[,3:10],FUN=mean,na.rm=TRUE))
(Sd.Course<-sapply(ReportCard[,3:10],FUN=sd,na.rm=TRUE))
也可以采用行列函数处理:
Av.Course<-colMeans(ReportCard[,3:10],na.rm=TRUE) ##均值
Sum.Course<-colSums(ReportCard[,3:10],na.rm=TRUE) ##计算总和
相关函数还有:
colSums (x, na.rm = FALSE, dims = 1) rowSums (x, na.rm = FALSE, dims = 1) colMeans(x, na.rm = FALSE, dims = 1) rowMeans(x, na.rm = FALSE, dims = 1)
也可以自定义函数实现自己需要的功能:
#########方便地计算每门课程的描述统计量(用户自定义函数的定义和调用)
Des.Fun<-function(x,...){
Av<-mean(x,na.rm=TRUE)
Sd<-sd(x,na.rm=TRUE)
N<-length(x[!is.na(x)])
Sk<-sum((x[!is.na(x)]-Av)^3/Sd^3)/N
Ku<-sum((x[!is.na(x)]-Av)^4/Sd^4)/N-3
result<-list(avg=Av,sd=Sd,skew=Sk,kurt=Ku)
return(result)
}
DesRep<-sapply(ReportCard[,3:10],FUN=Des.Fun,na.rm=TRUE) ##调用Des.Fun函数,x 赋值为ReportCard[,3:10],空值去掉。
subset函数
利用subset()函数进行访问和选取数据框的数据更为灵活,subset函数将满足条件的向量、矩阵和数据框按子集的方式返回。
Subset函数的三种应用方式:
subset(x,subset, ...)
subset(x,subset, select, drop = FALSE, ...)
subset(x,subset, select, drop = FALSE, ...)
x是对象,subset是保留元素或者行列的逻辑表达式,对于缺失值用NA代替。
Select
>x<-data.frame(matrix(1:30,nrow=5,byrow=T))
>rownames(x)=c("one","two","three","four","five")
>colnames(x)=c("a","b","c","d","e","f")
>x
>new<-subset(x,a>=14,select=a:f)
>new
MaleCard<-subset(ReportCard,ReportCard$sex=="M")
(Des.Male<-sapply(MaleCard[3:10],FUN=Des.Fun,na.rm=TRUE))
FeMaleCard<-subset(ReportCard,ReportCard$sex=="F")
(Des.FeMale<-sapply(FeMaleCard[3:10],FUN=Des.Fun,na.rm=TRUE))
Des.Sex<-cbind(Des.Male,Des.FeMale)
cor相关系数
##################计算相关系数
Tmp<-ReportCard[complete.cases(ReportCard),]
(CorMatrix<-cor(Tmp[,c(5,7,8)],use="everything",method="pearson"))
(CovMatrix<-cov(Tmp[,c(5,7,8)],use="complete.obs",method="pearson"))
rm(Tmp)
cor.test(X,Y,method="")
method可以为"spearman","pearson" and "kendall",分别对应三种相关系数的计算和检验。
1 perrson相关系数
> n <- 10
> x <- rnorm(n)
> y <- rnorm(n)
> cor(x,y)
[1] -0.4132864
> cor.test(x,y)
Pearson's product-moment correlation
data: x and y
t = -1.2837, df = 8, p-value = 0.2352
alternative hypothesis: true correlation is not equal to 0
95 percent confidence interval:
-0.8275666 0.2924366
sample estimates:
cor
-0.4132864
上面给出了相关系数的可信度区间和P-value
今天查了一下R语言中set.seed(),该命令的作用是设定生成随机数的种子,种子是为了让结果具有重复性。如果不设定种子,生成的随机数无法重现。
正态分布
###############正态分布
set.seed(12345)
x<-rnorm(1000,0,1)
Ord<-order(x,decreasing=FALSE)
x<-x[Ord]
y<-dnorm(x,0,1)
plot(x,y,type="l",ylab="密度",main="标准正态分布与不同自由度下的t分布密度函数",lwd=1.5)
norm是正态分布,前面加r表示生成随机正态分布的序列,其中rnorm(10)表示随机产生10个数;给定正太分布的均值和方差,pnorm可以输出正态分布的分布函数,dnorm可以输出正态分布的概率密度函数,qnorm给定分为数正太分布
简单的说:dnorm是密度函数,pnorm是分布函数,qnorm是分位函数,rnorm是产生随机数,
dnorm(x,mean = 0, sd = 1, log = FALSE)
pnorm(q,mean = 0, sd = 1, lower.tail = TRUE, log.p = FALSE)
qnorm(p,mean = 0, sd = 1, lower.tail = TRUE, log.p = FALSE)
rnorm(n, mean = 0, sd = 1)
T分布
lc<-2
for(i in c(5,20,30)){
x<-rt(1000,i)
Ord<-order(x,decreasing=FALSE)
x<-x[Ord]
y<-dt(x,i)
lines(x,y,lty=lc)
lc<-lc+1
}
legend("topright",title="自由度",c("标准正态分布","5个","20个","30个"),lty=c(1,2,3,4))

卡方分布:
##############卡方分布
set.seed(12345)
x<-rnorm(1000,0,1)
Ord<-order(x,decreasing=FALSE)
x<-x[Ord]
y<-dnorm(x,0,1)
plot(x,y,xlim=c(-1,35),type="l",ylab="密度",main="标准正态分布与不同自由度下的卡方分布密度函数",lwd=1.5)
#######不同自由度的卡方分布
df<-c(1,5,8,15)
for(i in 1:4){
x<-rchisq(1000,df[i])
Ord<-order(x,decreasing=FALSE)
x<-x[Ord]
y<-dchisq(x,df[i])
lines(x,y,lty=i+1)
}
legend("topright",title="自由度",c("标准正态分布",df),lty=c(1,2,3,4,5))

################卡方检验
Tmp<-ReportCard[complete.cases(ReportCard),]
(CrossTable<-table(Tmp[,c(2,12)]))
(ResChisq<-chisq.test(CrossTable,correct=FALSE))
ResChisq$expected

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











