







这篇论文讲的是一个叫binning(合并)的东西,将不同的rows合并到一起,使用了机器学习的方法。合并后形成一个个bin,每个bin被分配到一个workgroup上(有多个线程,如256个),可以执行不同的kernel。最典型的kernel是一个线程处理一个row,还有x个线程处理一个row的kernel,最后还有所有线程处理一个row的kernel。
文中的方法是基于CSR格式的,CSR通用性比较强,选择CSR格式可以避免格式转换的负担。
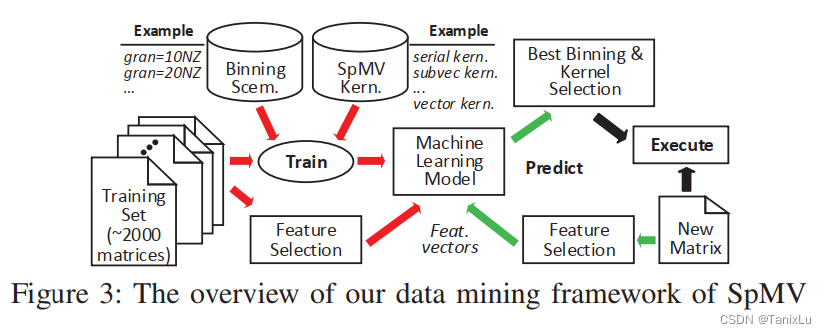
论文使用了决策树模型来训练,图示如下:
这个模型处理的是矩阵的features,列表如下:

有两种vector,一种是{M, N, NNZ, Var NNZ, Avg NNZ, Min NNZ, Max NNZ, U},target是U,这个U是binning的参数,表示多少row合为一个bin。还有一种vector是{M, N, NNZ, Var NNZ, Avg NNZ, Min NNZ, Max NNZ, U, binID, kernelID},target是kernelID(选哪个kernel)。
作者的数据集包含两千多个矩阵,用于训练,训练之后可以进行预测。
我觉得文中的binning有个缺点,就是只能合并相邻的row。前边看到的一篇论文是将row排序,然后再合并,并且按照非零元素数合并,这样不同的bin之间和bin内部都均衡,缺点是排序需要时间,然后选择不连续的row也有负担。
总结一下,这篇论文使用机器学习的方法来解决binning问题,选择合适的U,以及对每个bin选择合适的kernel,以实现不同workgroup之间/内的负载均衡。















 6万+
6万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









