







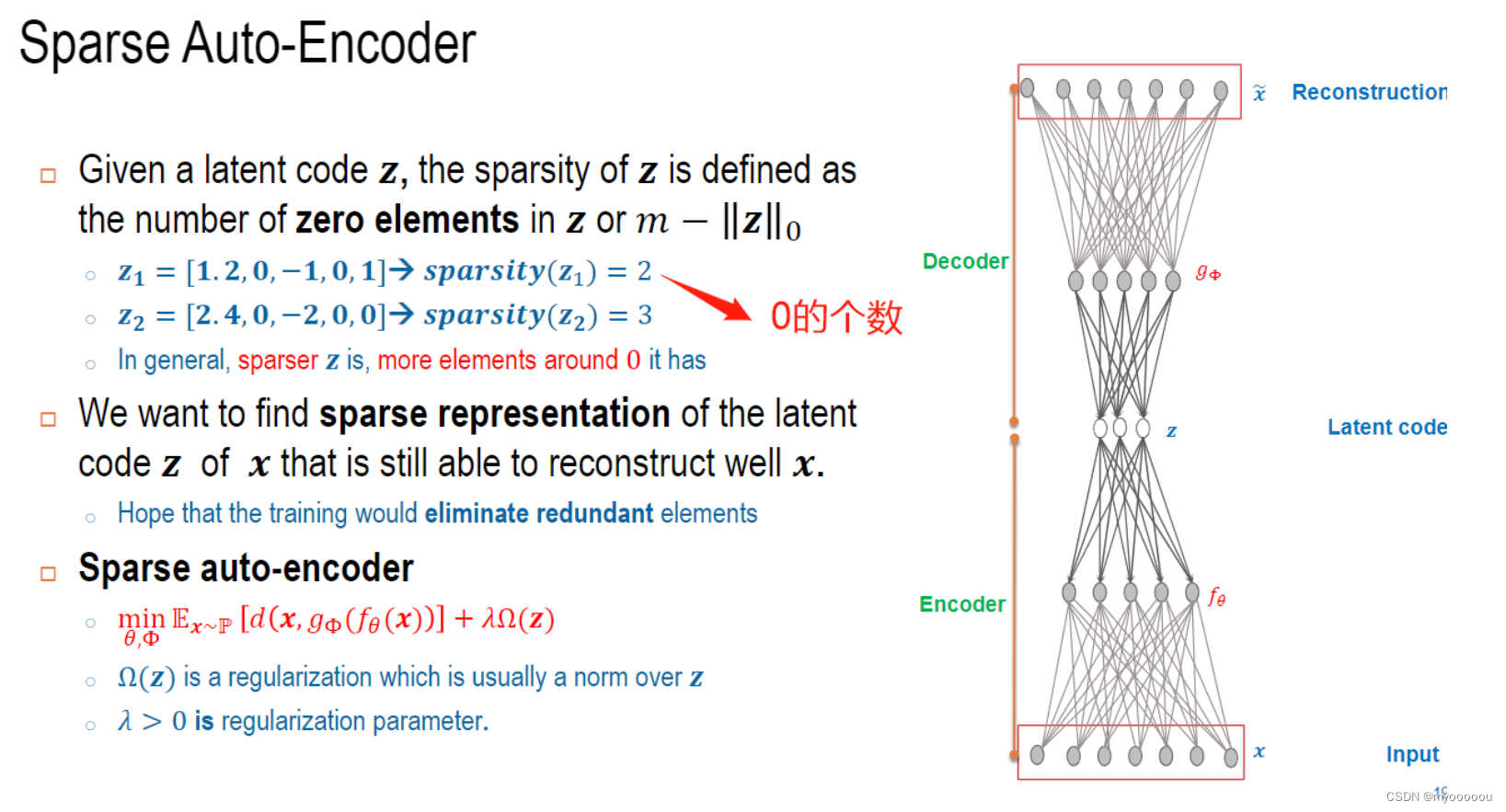
Auto-Encoder
什么是AE? 资料:【【变分自编码器VAE】可视化讲明白】 https://www.bilibili.com/video/BV1f34y1e7EK?share_source=copy_web&vd_source=078ecc13a0655f48c14ea779210b8653
相对熵 交叉熵
- 离散情况:给定两个离散分布p和q
Kullback-Leibler (KL) divergence 相对熵: K L ( p , q ) = ∑ i = 1 d p i log p i q i K L(p, q)=\sum_{i=1}^{d} p_{i} \log \frac{p_{i}}{q_{i}} KL(p,q)=∑i=1dpilogqipi
Cross-entropy (CE) 交叉熵:
C E ( p , q ) = − ∑ i = 1 d p i log q i = K L ( p , q ) + H ( p ) where H ( p ) = − ∑ i = 1 d p i log p i is the entropy of p . C E(p, q)=-\sum_{i=1}^{d} p_{i} \log q_{i}=K L(p, q)+H(p) \text { where } H(p)=-\sum_{i=1}^{d} p_{i} \log p_{i} \text { is the entropy of } p \text {. } CE(p,q)=−∑i=1dpilogqi=KL(p,q)+H(p) where H(p)=−∑i=1dpilogpi is the entropy of p.
熵的计算:

Cross-entropy between two Bernoulli distributions:
- Given 0≤𝑎,𝑏 ≤1, we have two Bernoulli distributions 𝐵𝑒𝑟(𝑎)and 𝐵𝑒𝑟(𝑏), the CE divergence between them is: C E ( [ a , 1 − a ] , [ b , 1 − b ] ) = − a log b − ( 1 − a ) log ( 1 − b ) C E([a, 1-a],[b, 1-b])=-a \log b-(1-a) \log (1-b) CE([a,1−a],[b,1−b])=−alogb−(1−a)log(1−b)
- 连续情况:给定两个连续分布p和q
相对熵 KL divergence between 𝒑and 𝒒 公式: K L ( p , q ) = ∫ p ( x ) log p ( x ) q ( x ) d x K L(p, q)=\int p(\boldsymbol{x}) \log \frac{p(\boldsymbol{x})}{q(\boldsymbol{x})} d \boldsymbol{x} KL(p,q)=∫p(x)logq(x)p(x)dx
相对熵基于高斯分布的公式: K L ( N ( μ , diag ( σ 2 ) ) , N ( 0 , I ) ) = 1 2 ( ∥ σ ∥ 2 2 + ∥ μ ∥ 2 2 − 1 − ∑ i = 1 d log ( σ i 2 ) ) K L\left(N\left(\mu, \operatorname{diag}\left(\sigma^{2}\right)\right), N(0, I)\right)=\frac{1}{2}\left(\|\sigma\|_{2}^{2}+\|\mu\|_{2}^{2}-1-\sum_{i=1}^{d} \log \left(\sigma_{i}^{2}\right)\right) KL(N(μ,diag(σ2)),N(0,I))=21(∥σ∥22+∥μ∥22−1−∑i=1dlog(σi2))
高斯分布: N ( x ∣ μ , Σ ) = 1 det ( 2 π Σ ) 1 / 2 exp { − 1 2 ( x − μ ) T Σ − 1 ( x − μ ) } N(x \mid \mu, \Sigma)=\frac{1}{\operatorname{det}(2 \pi \Sigma)^{1 / 2}} \exp \left\{-\frac{1}{2}(x-\mu)^{T} \Sigma^{-1}(x-\mu)\right\} N(x∣μ,Σ)=det(2πΣ)1/21exp{−21(x−μ)TΣ−1(x−μ)}
KL证明过程:


PCA
定义
一种常见的线性降维方法,广泛应用于图像处理、人脸识别、数据压缩、信号去噪等领域。
原理
- 设原数据大小为 N × M,****经过PCA降维****后的数据大小为 N × K,其中 K < M。
- PCA的中心思想是:**将高维数据投影到具有最大方差的低维空间中,**只要将数据投影到方差最大的低维(K维)空间中就行。
PCA执行步骤
- 分别求每个维度的平均值,然后对于所有的样例,都减去对应维度的均值,得到去中心化的数据;
- 求协方差矩阵C:用去中心化的数据矩阵乘上它的转置,然后除以(N-1)即可,N为样本数量;
- 求协方差的特征值和特征向量;
- 将特征值按照从大到小排序,选择前k个,然后将其对应的k个特征向量分别作为列向量组成特征向量矩阵;
- 将样本点从原来维度投影到选取的k个特征向量,得到低维数据;
- 通过逆变换,重构低维数据,进行复原。
PCA实例求解
步骤1:数据去中心化:

步骤2:计算协方差矩阵:

步骤3:对协方差矩阵进行奇异值分解:(也成矩阵的相似对角化)

步骤4:取最大的 K 个特征值与特征向量构成一个变换矩阵 PK (取 K = 1)

步骤5:将原始数据投影到 K 维空间:

最后结果的投影线如图所示:

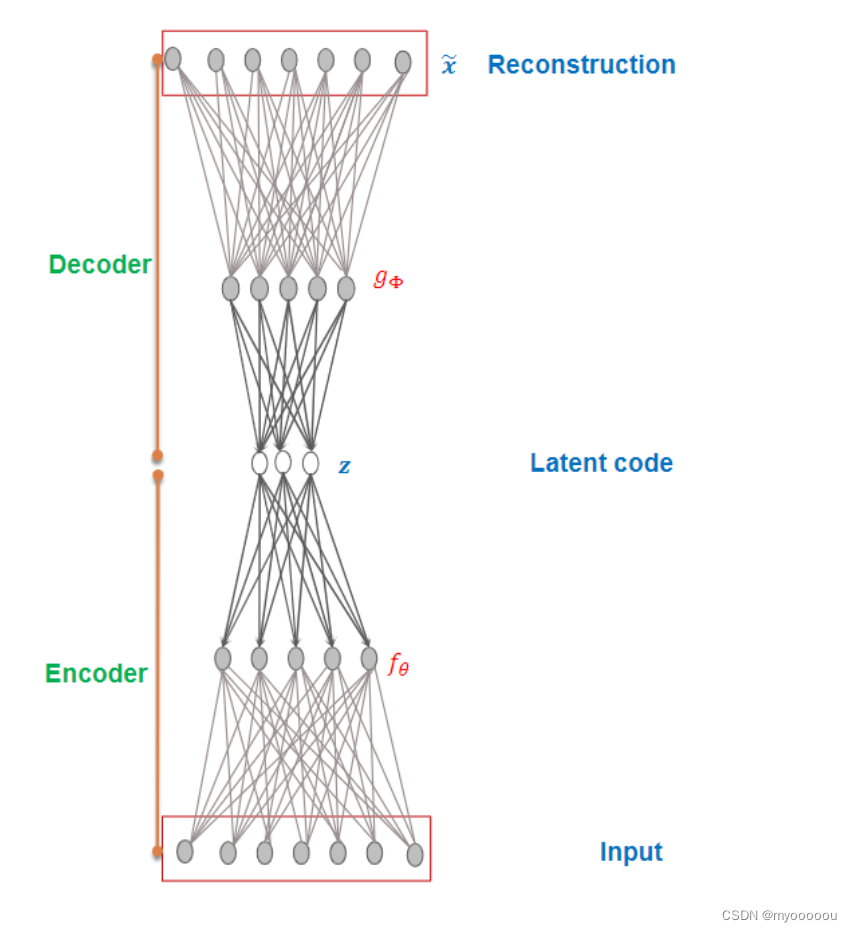
Auto-Encoder
自编码器(autoencoder, AE)是一类在半监督学习和非监督学习中使用的人工神经网络(Artificial Neural Networks, ANNs),其功能是通过将输入信息作为学习目标,对输入信息进行表征学习(representation learning)。如果算法把x作为监督信号来学习,这里算法称为自监督学习(Self-supervised Learning)。特征降维(Dimensionality Reduction)在机器学习中有广泛的应用, 比如文件压缩(Compression)、 数据预处理(Preprocessing)等。 最常见的降维算法有主成分分析法(Principal components analysis, 简称 PCA),通过对协方差矩阵进行特征分解而得到数据的主要成分,但是 PCA 本质上是一种线性变换,提取特征的能力极为有限。
Deep Auto-encoder
编码器和解码器共同完成了输入数据𝒙的编码和解码过程,把整个网络模型叫做自动编码器(Auto-Encoder),简称自编码器。 如果使用深层神经网络来参数化
和
函数, 则称为深度自编码器(Deep Auto-encoder)。
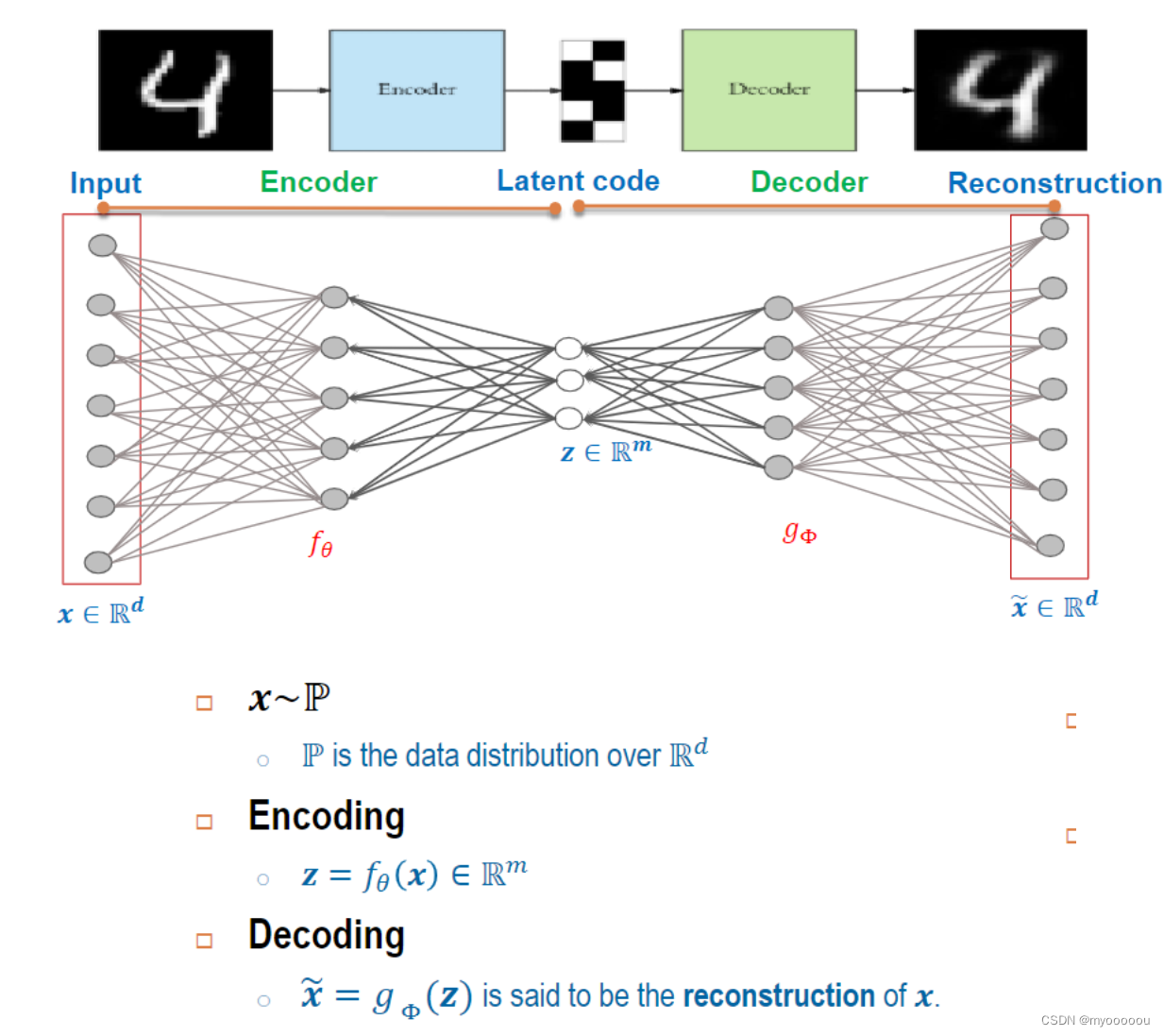
- Reconstruction error
Q1:如何证明latent code 𝒛 可以保留x中的关键信息?
Q2:如何计算重构的x(即 x ~ = g Φ ( z ) \tilde{x}=g_{\Phi}(z) x~=gΦ(z))与原x的准确度?
A:计算 Reconstruction error: d ( x , x ~ ) d(x,\tilde{x}) d(x,x~),然后最小化reconstruction error
1. 距离的定义方式: d为x与 x ~ \tilde{x} x~的距离,可以用L2 distance表示 : d ( x , x ~ ) = 1 2 ∥ x − x ~ ∥ 2 2 d(\boldsymbol{x}, \tilde{\boldsymbol{x}})=\frac{1}{2}\|\boldsymbol{x}-\tilde{\boldsymbol{x}}\|_{2}^{2} d(x,x~)=21∥x−x~∥22
-
交叉熵的定义方式:将x与 x ~ \tilde{x} x~控制在[0,1]范围内(applied sigmoid on the output)
那么
d ( x , x ~ ) = ∑ i = 1 d C E ( [ x i , 1 − x i ] , [ x ~ i , 1 − x ~ i ] ) = ∑ i = 1 d [ − x i log x ~ i − ( 1 − x i ) log ( 1 − x ~ i ) ] \begin{aligned} d(\boldsymbol{x}, \tilde{\boldsymbol{x}}) &=\sum_{i=1}^{d} C E\left(\left[x_{i}, 1-x_{i}\right],\left[\tilde{x}_{i}, 1-\tilde{x}_{i}\right]\right) \\ &=\sum_{i=1}^{d}\left[-x_{i} \log \tilde{x}_{i}-\left(1-x_{i}\right) \log \left(1-\tilde{x}_{i}\right)\right] \end{aligned} d(x,x~)=i=1∑dCE([xi,1−xi],[x~i,1−x~i])=i=1∑d[−xilogx~i−(1−xi)log(1−x~i)]
Undercomplete Auto-Encoder
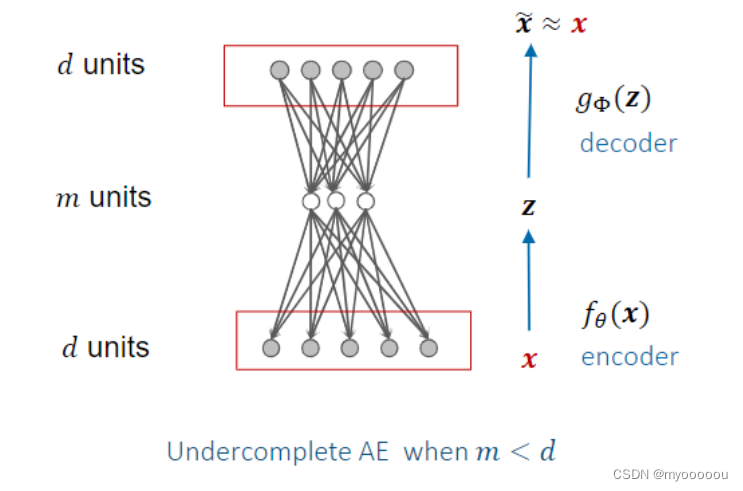
- Q:Why would one want to learn to copy the input to the output 为什么要学习将输入复制到输出
A:
-
We are not actually interested in the output
-
The hope is that by learning to perform copying from input to output via the intermediate code 𝑧, this code will capture useful and key properties of the data
希望通过学习通过中间代码从输入到输出进行复制,此代码将捕获数据的有用和关键属性
-
Ensure the code 𝑧learn useful information is through ‘compression’
-
Letting dimension of the code 𝑧 to be smaller than the dimension of the input.
-
This is called an undercomplete AE
-
-
When the decoder is linear and mean squared error loss is used, this is identical to Principal Component Analysis (PCA)
当decoder 是线性的并且使用平均平方误差损失时,这与主组件分析(PCA)相同
Overcomplete Auto-Encoder 过度完备自编码
-
Overcomplete AE is when the latent code dimension 𝑚 is greater than the input dimension 𝑑
Overcomplete AE 是潜在代码z维度𝑚大于输入维度𝑑
-
In undercomplete AE, 𝑚<𝑑, hence the code can learn salient features of the data,
在过度完备自编码中,𝑚<𝑑,因此代码可以学习数据的显着特征
For overcomplete case, the encoder/decoder could be too powerful, hence it can copy (even perfectly) without learning any useful code 𝑧
对于 overcomplete 的情况,编码器/解码器可能太强大了,因此它可以复制(甚至完美)而无需学习任何有用的代码𝑧
ft代码:
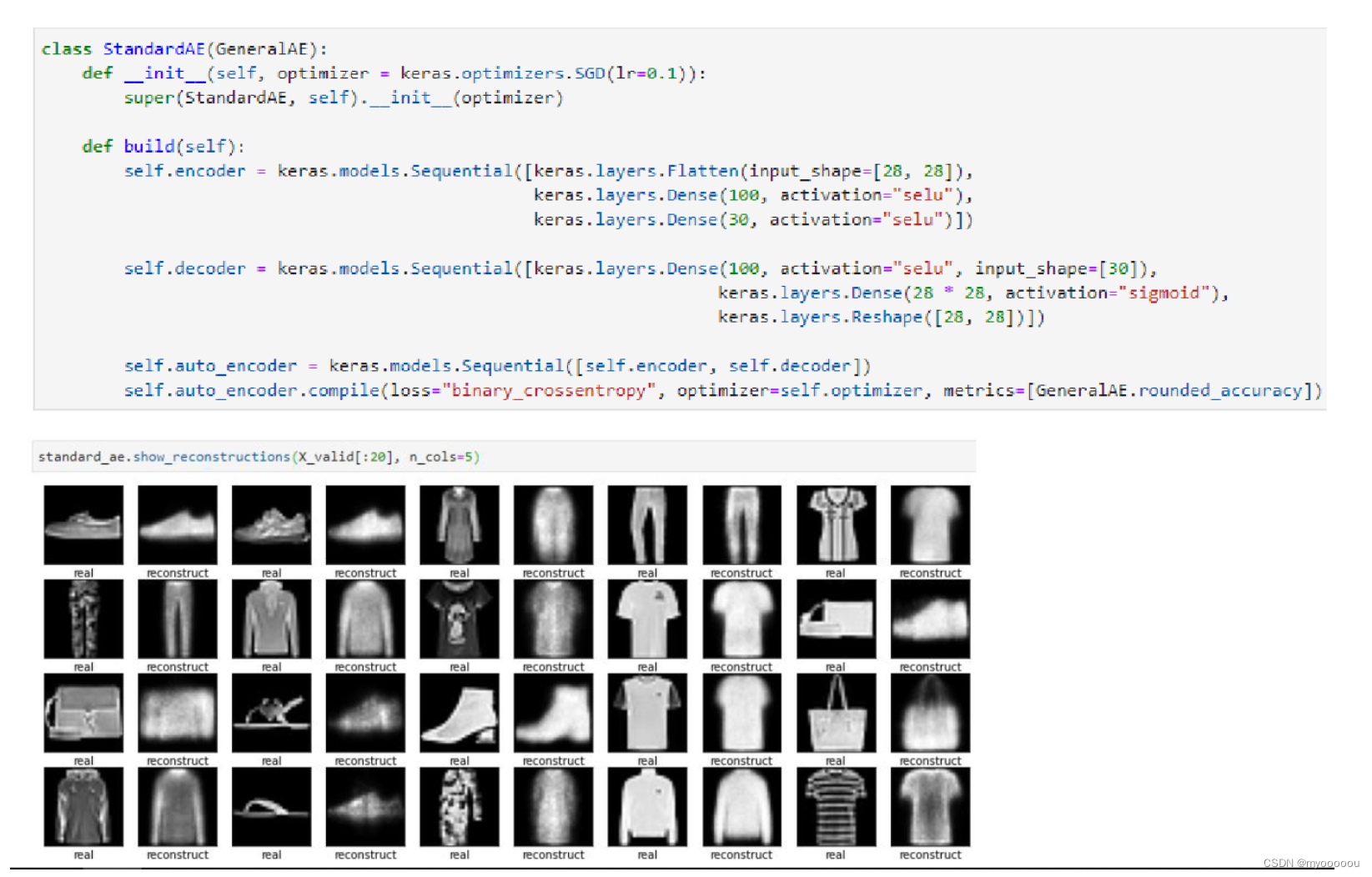
Implementation of Standard Auto-Encoder
Sparse Auto-Encoder
稀疏自编码器简单地在训练时结合编码层的稀疏惩罚 Ω(h) 和重构误差:L(x,g(f(x))) + Ω(h),其中 g(h) 是解码器的输出,通常 h 是编码器的输出,即 h = f(x)。稀疏自编码器一般用来学习特征,以便用于像分类这样的任务。稀疏正则化的自编码器必须反映训练数据集的独特统计特征,而不是简单地充当恒等函数。以这种方式训练,执行附带稀疏惩罚的复制任务可以得到能学习有用特征的模型。
****稀疏惩罚Ω(𝒛)有以下选择方式
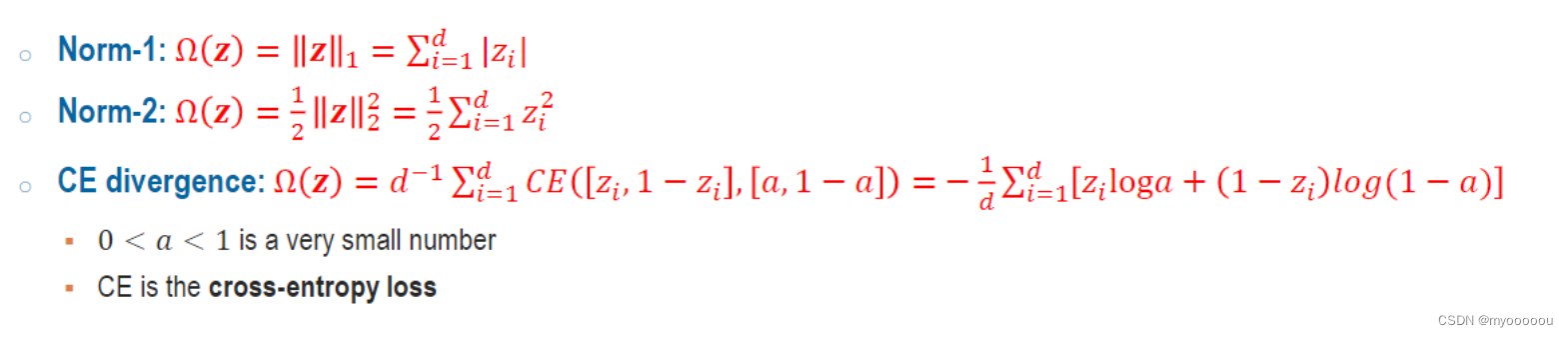
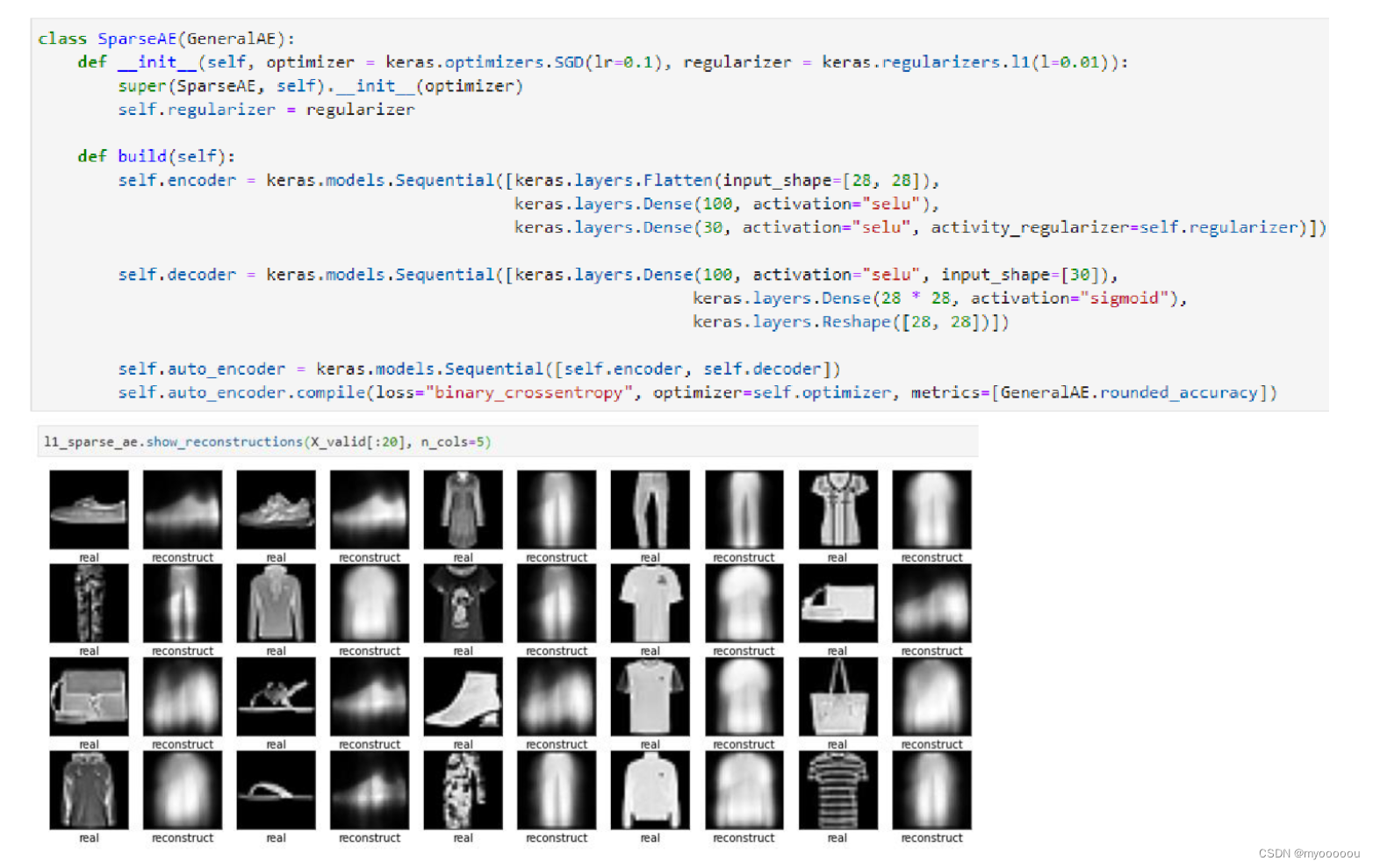
Sparse Auto-Encoder代码实现:
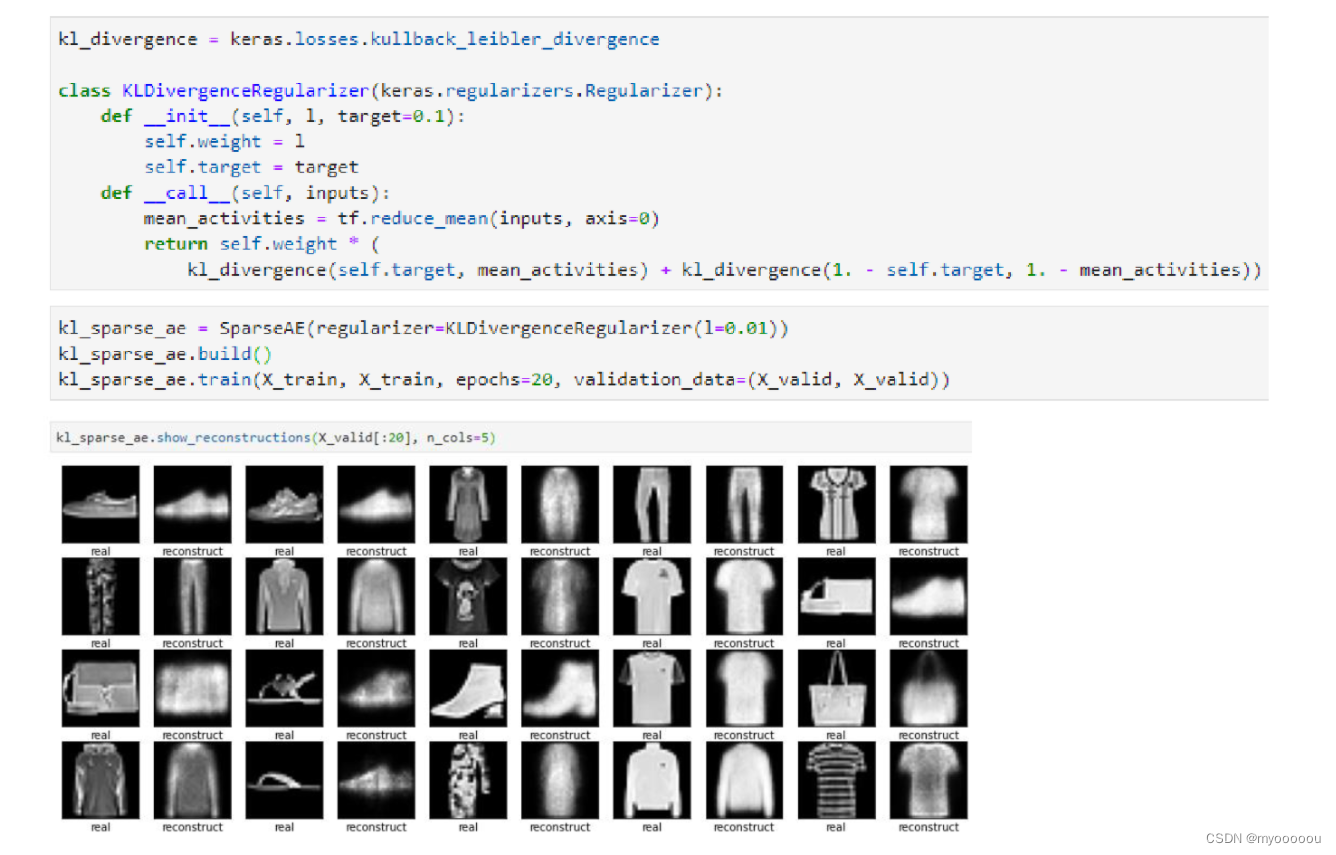
正则化参数的影响:

Contractive Auto-Encoder (CAE-收缩自编码)
-
正则化AE:
$ \min {\theta, \Phi} \mathbb{E}{\boldsymbol{x} \sim \mathbb{P}}\left[d\left(\boldsymbol{x}, g_{\Phi}\left(f_{\theta}(\boldsymbol{x})\right)\right]+\lambda \Omega(\boldsymbol{x}, \boldsymbol{z})\right.
where \Omega(\boldsymbol{x}, \boldsymbol{z})=\sum_{i=1}^{d}\left|\nabla_{x} \mathbf{Z}{i}\right|^{2}=\left|\frac{\partial f{\theta}(x)}{\partial x}\right|_{F}^{2} .$ -
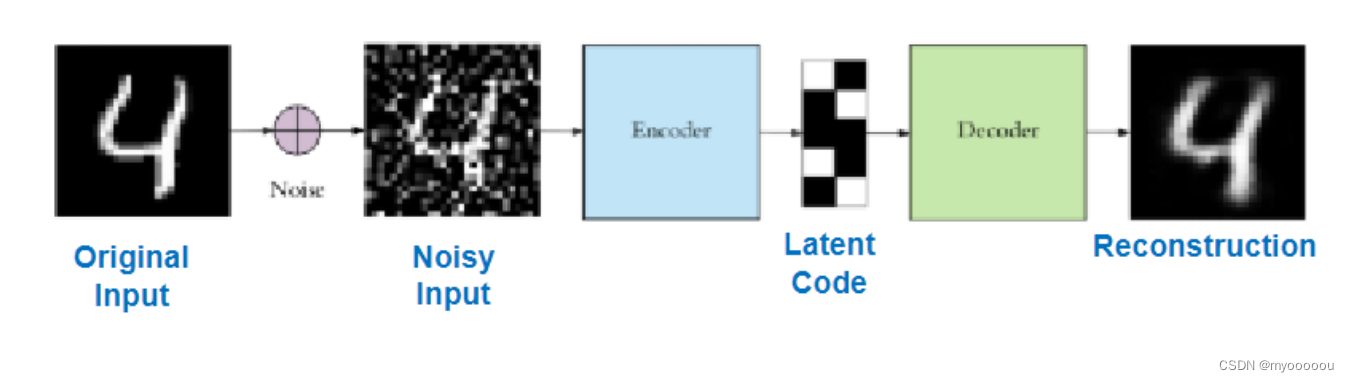
这种类型的自动编码器适用于部分损坏的输入,并训练以恢复原始未失真的图像。
-
目标是网络将能够复制图像的原始版本。通过将损坏的数据与原始数据进行比较,网络可以了解数据的哪些特征最重要,哪些特征不重要/损坏。换句话说,为了让模型对损坏的图像进行去噪,它必须提取图像数据的重要特征。
-
为了防止神经网络记忆住输入数据的底层特征, Denoising Auto-Encoders 给输入数据添加随机的噪声扰动,如给输入𝒙添加采样自高斯分布的噪声𝜀: x ′ = x + ϵ where ϵ ∼ N ( 0 , η I ) and learn such that g Φ ( f θ ( x ′ ) ) ≈ x x^{\prime}=x+\epsilon \text { where } \epsilon \sim N(0, \eta I) \text { and learn such that } g_{\Phi}\left(f_{\theta}\left(x^{\prime}\right)\right) \approx x x′=x+ϵ where ϵ∼N(0,ηI) and learn such that gΦ(fθ(x′))≈x,
添加噪声后,网络需要从学习到数据的真实隐藏变量 z,并还原出原始的输入𝒙。也就是Denoising auto-encoder:$\min {\theta, \Phi} \mathbb{E}{\boldsymbol{x} \sim \mathbb{P}}\left[\mathbb{E}{\boldsymbol{x}^{\prime} \sim N(\boldsymbol{x}, \eta I)}\left[d\left(\boldsymbol{x}, g{\Phi}\left(f_{\theta}\left(\boldsymbol{x}^{\prime}\right)\right)\right]\right]\right. $
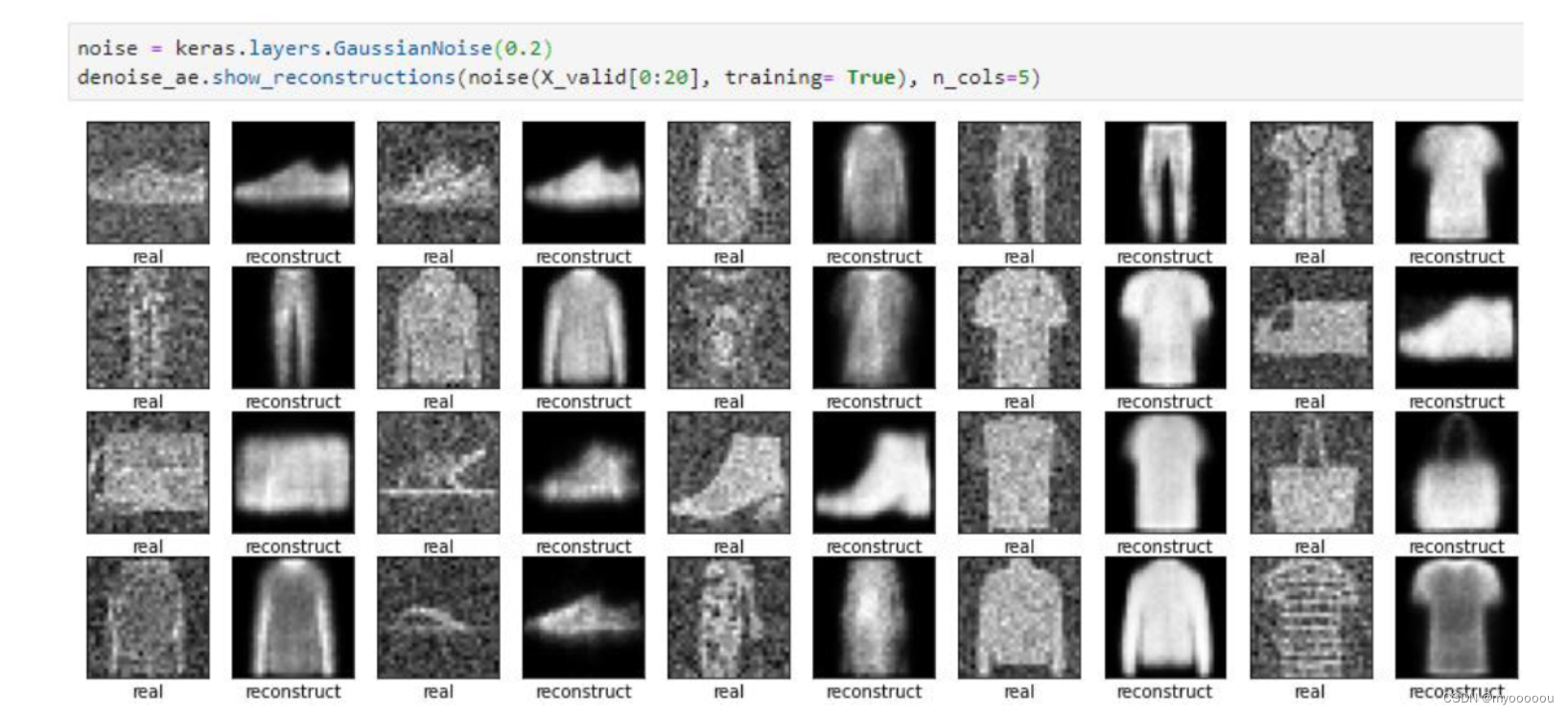
代码实现Denoising Auto-Encoder
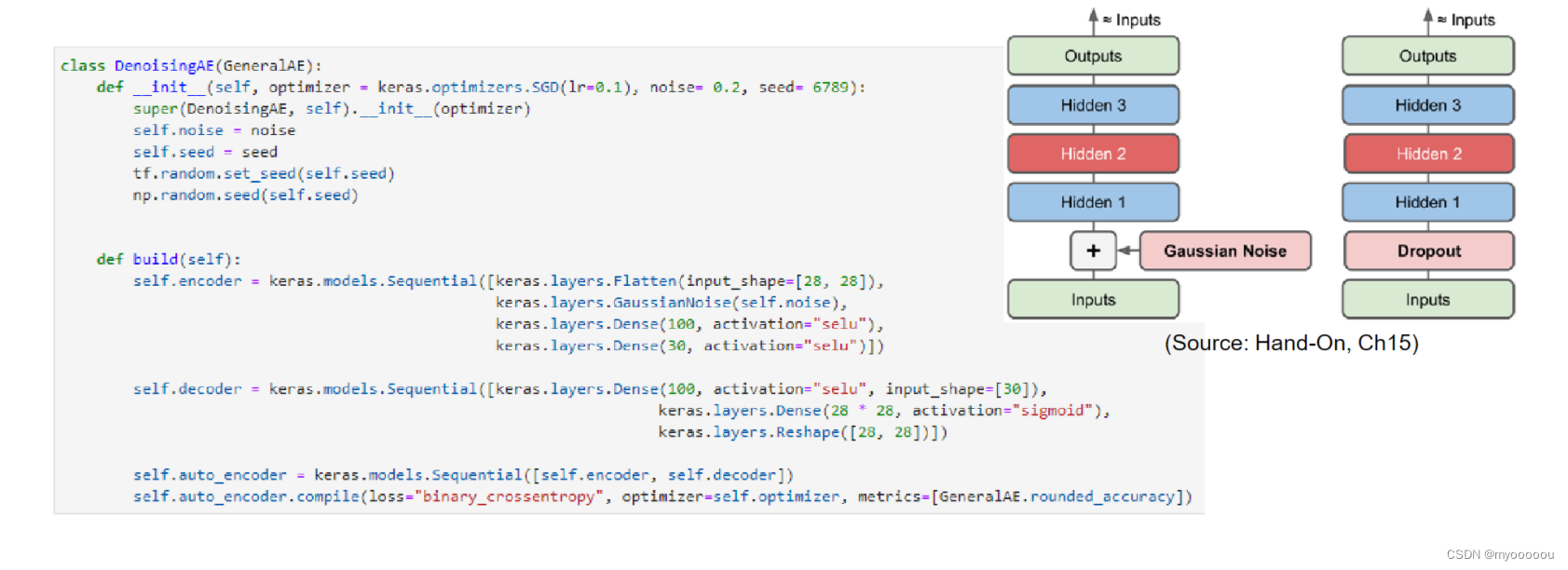
Implementation of Denoising Auto-Encoder
Variational Auto-Encoder (VAE)(变分自编码器)(重点)
基本的自编码器本质上是学习输入𝒙和隐藏变量𝒛之间映射关系, 它是一个判别模型(Discriminative model),并不是生成模型(Generative model)。
变分自编码器(Variational AutoEncoders,VAE):给定隐藏变量的分布P(𝒛), 如何可以学习到条件概率分布P(𝒙|𝒛), 则通过对联合概率分布P(𝒙, 𝒛) = P(𝒙|𝒛)P(𝒛)进行采样, 生成不同的样本:
2
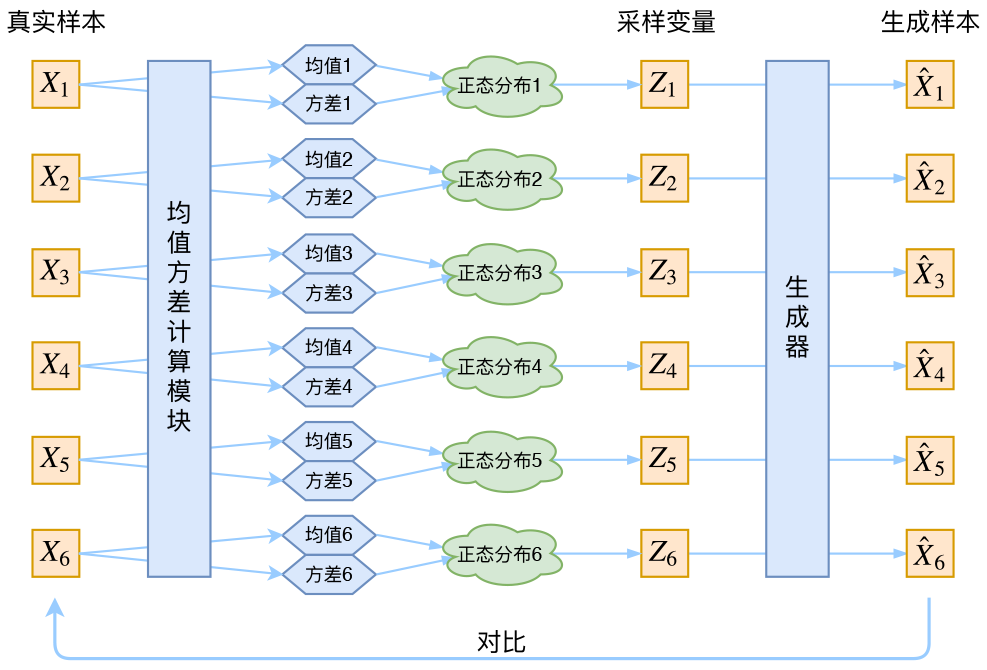
从神经网络的角度来看, VAE 相对于自编码器模型,同样具有编码器和解码器两个子网络。解码器接受输入𝒙, 输出为隐变量𝒛;解码器负责将隐变量𝒛解码为重建的𝒙。 不同的是, VAE 模型对隐变量𝒛的分布有显式地约束,希望隐变量𝒛符合预设的先验分布P(𝒛)。在损失函数的设计上,除了原有的重建误差项外,还添加了隐变量𝒛分布的约束项。
从概率的角度,假设数据集都采样自某个分布𝑝(𝒙|𝒛), 𝒛是隐藏变量,代表了某种内部特征, 比如手写数字的图片𝒙, 𝒛可以表示字体的大小、 书写风格、 加粗、斜体等设定,它符合某个先验分布𝑝(𝒛),在给定具体隐藏变量𝒛的情况下,可以从学到了分布𝑝(𝒙|𝒛)中采样一系列的生成样本,这些样本都具有𝒛所表示的共性。
通常假设𝑝(𝒛)符合已知的分布𝒩(0,1)。 在𝑝(𝒛)已知的条件下, 希望能学会生成概率模型𝑝(𝒙|𝒛)。这里可以采用最大似然估计(Maximum Likelihood Estimation)方法: 一个好的模型,应该拥有很大的概率生成真实的样本𝒙 ∈ 𝔻。 如果生成模型𝑝(𝒙|𝒛)是用𝜃来参数化, 那么的神经网络的优化目标是:
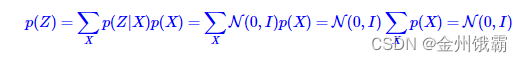
由于z是连续变量,这个积分不能转换为离散形式,不能直接优化。
利用变分推断,再经过一系列化简VAE模型优化目标:
可以用编码器网络参数化𝑞 (𝒛|𝒙)函数,解码器网络参数化𝑝𝜃(𝒙|𝒛)函数,通过计算解码器的输出分布𝑞 (𝒛|𝒙)与先验分布𝑝(𝒛)之间的 KL 散度,以及解码器的似然概率log 𝑝𝜃(𝒙|𝒛)构成的损失函数,即可优化ℒ(𝜃, 𝜙)目标。优化函数转换为:
该项可以基于自编码器中的重建误差函数实现。其中,当𝑞 (z |𝑥)和𝑝(z )都假设为正态分布时:
各分量独立的多元正态分布之间的 KL 散度即为:(最终目标函数-需要记住)
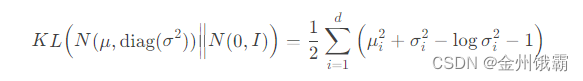
其中,d 是隐变量 Z 的维度。
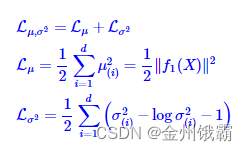
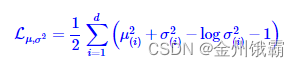
当𝑞 ( |𝑥)为正态分布𝒩(, ), 𝑝( )为正态分布𝒩(0,1)时,即 = 0, =1,此时
也可以把公式写成:(单元的KL散度推导公式-离散变量)
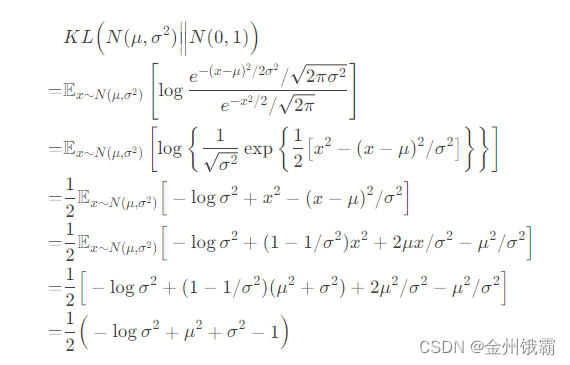
对于连续变量,我们有如下推导过程:

隐变量采样自编码器的输出𝑞 ( |𝑥),当𝑞(z|𝑥)和𝑝(z )都假设为正态分布时, 编码器输出正态分布的均值𝜇和方差𝜎2,解码器的输入采样自𝒩(𝜇, 𝜎2)。由于采样操作的存在,导致梯度传播是不连续的,无法通过梯度下降算法端到端式地训练 VAE 网络:
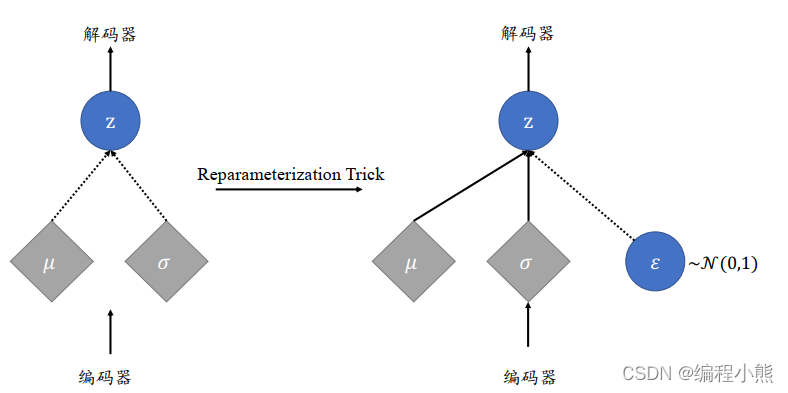
VAE执行过程和结构:















 350
350

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









