







我们编写的MapReduce程序不一定都是高效的,我们需要确定MapReduce的瓶颈在什么地方。Hadoop框架提供对HPROF的支持,HPROF能够跟踪CPU、堆的使用以及线程的生命周期,对于确定程序的瓶颈能够提供很大的帮助。
为了使用HPROF我们需要在JobConf中进行一些设置,具体操作如下:
JobConf jobConf = new JobConf(conf);
jobConf.setProfileEnabled(true);//开启HPROF
jobConf.setProfileParams("-agentlib:hprof=depth=8,cpu=sampl es,heap=sites,force=n,"+ "thread=y,verbose=n,file=%s");
//这里面8指堆栈调用深度,可以由用户指定
jobConf.setProfileTaskRange(true, "0-5");
//需要profile的Map Task的ID
jobConf.setProfileTaskRange(false, "0-5");
//需要profile的Reduce Task的ID
通过上面的设置,就可以开启HPROF。MapReduce Job完成后可以在提交作业的目录下看到多个Profile文件。打开每一个profile文件,在文件的最底部我们可以看到最重要的两个统计,一个是对象所占用的内存,一个是堆栈调用所消耗的时间。

内存对象统计以及产生该对象的堆栈调用(由大到小排序)
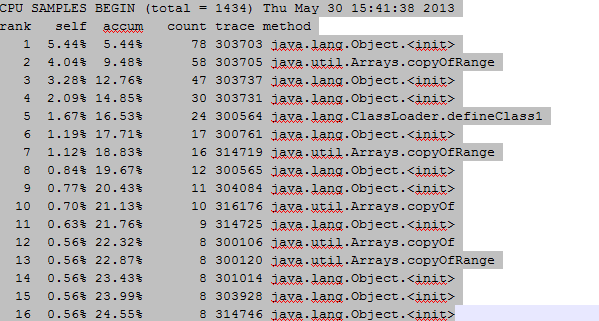
堆栈调用所消耗时间的排序(由大到小排序)
下面是排名第一的303703的堆栈调用,基本可以看出函数调用的顺序,如下图所示:

转自:http://blog.csdn.net/zuochanxiaoheshang/article/details/8996162















 1629
1629

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









