









本文主要说明ZooKeeper在集群模式下是怎样运作的,其中主要包括选举过程以及选举过程中使用到的线程模型是什么。
当服务状态为Looking时,采用FastLeaderElection算法进行Leading选举,选举结束后设置当前服务的状态,然后继续循环。
当服务状态为Leading时,设置该服务为Leading节点,然后处理作为Leading节点的相关工作。
当服务状态为Observing时,设置该服务为Observing节点,然后处理作为Observing节点的相关工作。
当服务状态为Following时,设置该服务为Following节点,然后处理作为Following节点的相关工作。
当Leading节点处理出现异常情况时,该节点状态会变为Looking状态,从而再次触发Leading选举。
当Observing,Following节点与Leading节点通信或处理出现异常情况时,该节点状态会变为Looking状态,从而再次触发Leading选举。
在这些实例中,都重写了setupRequestProcessors()方法,该方法会构建出对应实例对应的请求处理责任链,从而保证了每个实例都有不同的请求处理方法。
对应源码如下:
1、在配置文件Zoo.cfg中设置如下信息,第一个端口是集群之间交换信息使用,第二个端口是选举使用:
server.1=localhost:2282:2283
server.2=localhost:2382:2383
server.3=localhost:2482:2483
2、在dataDir对应的文件夹中增加myid文件,并在文件中标明服务归属的序号。
在ZooKeeper启动时,会加载Zoo.cfg及myid文件。在加载完成完成后,会知道有多少台服务器共同组成一个服务集群。在构建FastLeaderElection实例时,先构建QuorumCnxManager实例,再构建FastLeaderElection实例。QuorumCnxManage实例主要是用于管理本地服务与其它集群服务之间的连接,FastLeaderElection实例会启动两个线程分别用来处理选举过程中需要发送和接收到消息,并提供Leading选举服务。
WorkSender是FastLeaderElection实例中的发送消息线程,主要负责从需要发送的消息队列获取消息,并将消息分发到本地服务与该消息对应的一个服务的消息队列。
WorkerReceiver是FastLeaderElection实例中处理接收消息的线程,主要负责从接收到的消息队列中获取消息,并将该消息转换为Notification,放入队列,为FastLeaderElection算法做准备。
QuorumCnxManage实例中会维护本地服务到其它集群服务之间的消息队列及连接。SendWorker线程主要负责从消息队列中获取消息并发送到与之对应的服务。
RecvWorker线程主要负责从对应的服务端接收消息,并将接收到的消息放到Message消息队列。
一、集群选举过程
1.1选举流程
我们先通过一张流程图(图一),来对集群的选举过程做一个初步认识。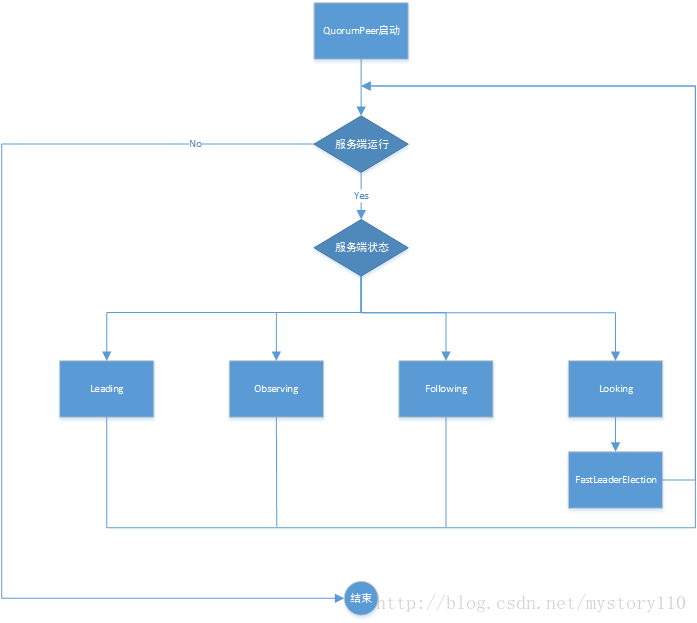
图一
从图一中我们可以看到,在服务端启动后,QuorumPeer线程进入循环,判断服务是否继续运行,如果服务停止,则结束该线程,如果服务继续运行,则判断该服务的状态。服务的状态分别为Leading、Observing、Following、Looking。当服务状态为Looking时,采用FastLeaderElection算法进行Leading选举,选举结束后设置当前服务的状态,然后继续循环。
当服务状态为Leading时,设置该服务为Leading节点,然后处理作为Leading节点的相关工作。
当服务状态为Observing时,设置该服务为Observing节点,然后处理作为Observing节点的相关工作。
当服务状态为Following时,设置该服务为Following节点,然后处理作为Following节点的相关工作。
当Leading节点处理出现异常情况时,该节点状态会变为Looking状态,从而再次触发Leading选举。
当Observing,Following节点与Leading节点通信或处理出现异常情况时,该节点状态会变为Looking状态,从而再次触发Leading选举。
1.2集群模式类图
集群模式下,服务启动时主要涉及图二相关的类。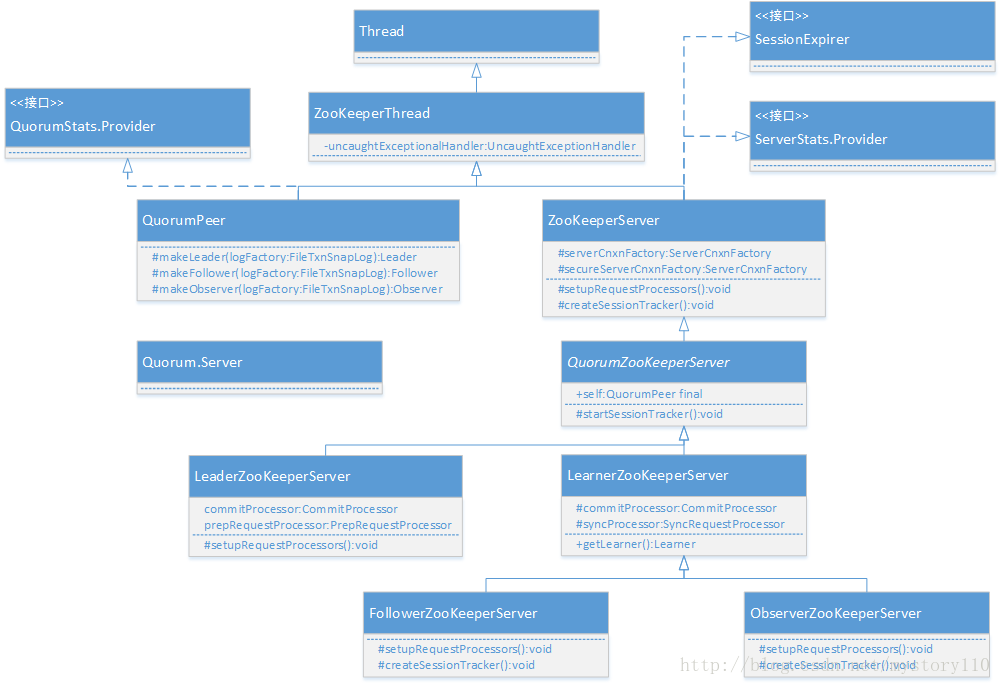
图二
服务启动时,服务状态都为Looking状态,QuorumPeer线程开始运行后,首先进行选举,在选举结束后,会根据选举结果设置不同的服务处理方式。如果选举结束后,服务状态为Leading,则会实例化出LeadZooKeeperServer;服务状态为Following,则会实例化出FollowerZooKeeperServer;服务状态为Observing,则会实例化出ObserverZooKeeperServer。在这些实例中,都重写了setupRequestProcessors()方法,该方法会构建出对应实例对应的请求处理责任链,从而保证了每个实例都有不同的请求处理方法。
对应源码如下:
public void run() {
......
try {
/*
* Main loop
*/
while (running) {
switch (getPeerState()) { //获取当前服务状态
case LOOKING:
LOG.info("LOOKING");
if (Boolean.getBoolean("readonlymode.enabled")) { //启动前是否开启只读模式
LOG.info("Attempting to start ReadOnlyZooKeeperServer");
// Create read-only server but don't start it immediately
final ReadOnlyZooKeeperServer roZk =
new ReadOnlyZooKeeperServer(logFactory, this, this.zkDb);
// Instead of starting roZk immediately, wait some grace
// period before we decide we're partitioned.
//
// Thread is used here because otherwise it would require
// changes in each of election strategy classes which is
// unnecessary code coupling.
Thread roZkMgr = new Thread() {
public void run() {
try {
// lower-bound grace period to 2 secs
sleep(Math.max(2000, tickTime));
if (ServerState.LOOKING.equals(getPeerState())) {
roZk.startup();
}
} catch (InterruptedException e) {
LOG.info("Interrupted while attempting to start ReadOnlyZooKeeperServer, not started");
} catch (Exception e) {
LOG.error("FAILED to start ReadOnlyZooKeeperServer", e);
}
}
};
try {
roZkMgr.start();
reconfigFlagClear();
if (shuttingDownLE) {
shuttingDownLE = false;
startLeaderElection();
}
setCurrentVote(makeLEStrategy().lookForLeader()); //构建选举算法,并进行选举
} catch (Exception e) {
LOG.warn("Unexpected exception", e);
setPeerState(ServerState.LOOKING); //异常处理,设置服务状态为Looking,以便进行重新选举
} finally {
// If the thread is in the the grace period, interrupt
// to come out of waiting.
roZkMgr.interrupt();
roZk.shutdown();
}
} else {
try {
reconfigFlagClear(); //标记清除->false,当调用updateServerState时,服务状态会更新为Looking
if (shuttingDownLE) {
shuttingDownLE = false;
startLeaderElection();
}
setCurrentVote(makeLEStrategy().lookForLeader());
} catch (Exception e) {
LOG.warn("Unexpected exception", e);
setPeerState(ServerState.LOOKING); //异常处理,设置服务状态为Looking,以便进行重新选举
}
}
break;
case OBSERVING:
try {
LOG.info("OBSERVING");
setObserver(makeObserver(logFactory)); //构建Observer
observer.observeLeader(); //Observer进行工作处理
} catch (Exception e) {
LOG.warn("Unexpected exception",e );
} finally {
observer.shutdown();
setObserver(null);
updateServerState(); //更新服务状态
}
break;
case FOLLOWING:
try {
LOG.info("FOLLOWING");
setFollower(makeFollower(logFactory)); //构建Follower
follower.followLeader(); //Follower进行工作处理
} catch (Exception e) {
LOG.warn("Unexpected exception",e);
} finally {
follower.shutdown();
setFollower(null);
updateServerState(); //更新服务状态
}
break;
case LEADING:
LOG.info("LEADING");
try {
setLeader(makeLeader(logFactory)); //构建Leader
leader.lead(); //Leader开始处理工作
setLeader(null);
} catch (Exception e) {
LOG.warn("Unexpected exception",e);
} finally {
if (leader != null) {
leader.shutdown("Forcing shutdown");
setLeader(null);
}
updateServerState(); //更新服务状态
}
break;
}
start_fle = Time.currentElapsedTime();
}
} finally {
......
}
}
protected Follower makeFollower(FileTxnSnapLog logFactory) throws IOException { //构建Follower
return new Follower(this, new FollowerZooKeeperServer(logFactory, this, this.zkDb));
}
protected Leader makeLeader(FileTxnSnapLog logFactory) throws IOException {//构建Leader
return new Leader(this, new LeaderZooKeeperServer(logFactory, this, this.zkDb));
}
protected Observer makeObserver(FileTxnSnapLog logFactory) throws IOException {//构建Observer
return new Observer(this, new ObserverZooKeeperServer(logFactory, this, this.zkDb));
}
public synchronized void reconfigFlagClear(){
reconfigFlag = false;
}
private synchronized void updateServerState(){
if (!reconfigFlag) {
setPeerState(ServerState.LOOKING);
LOG.warn("PeerState set to LOOKING");
return;
}
if (getId() == getCurrentVote().getId()) {
setPeerState(ServerState.LEADING);
LOG.debug("PeerState set to LEADING");
} else if (getLearnerType() == LearnerType.PARTICIPANT) {
setPeerState(ServerState.FOLLOWING);
LOG.debug("PeerState set to FOLLOWING");
} else if (getLearnerType() == LearnerType.OBSERVER) {
setPeerState(ServerState.OBSERVING);
LOG.debug("PeerState set to OBSERVER");
} else { // currently shouldn't happen since there are only 2 learner types
setPeerState(ServerState.LOOKING);
LOG.debug("Shouldn't be here");
}
reconfigFlag = false;
}二、选举线程模型
选举过程中,使用到的线程模型如图三。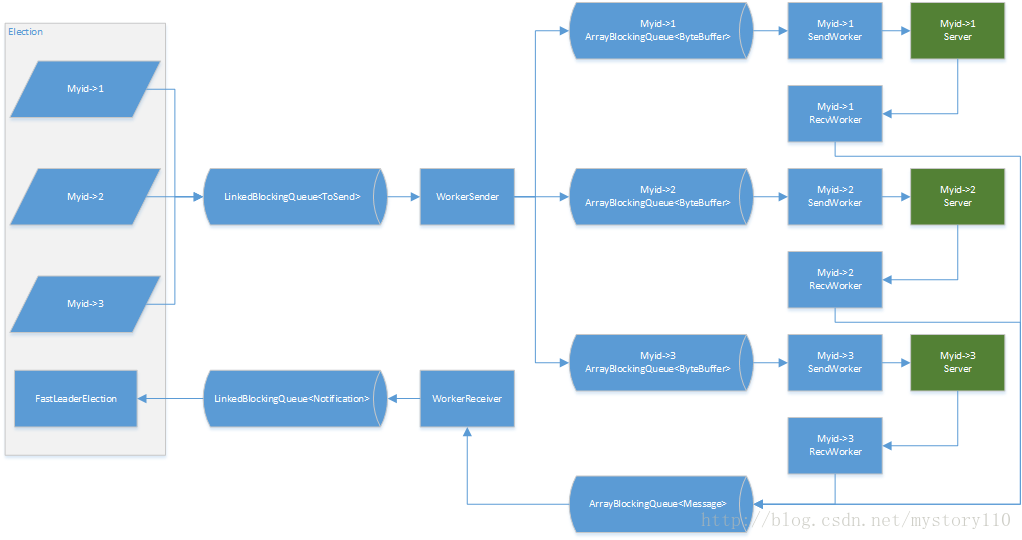
图三
集群模式基本配置:1、在配置文件Zoo.cfg中设置如下信息,第一个端口是集群之间交换信息使用,第二个端口是选举使用:
server.1=localhost:2282:2283
server.2=localhost:2382:2383
server.3=localhost:2482:2483
2、在dataDir对应的文件夹中增加myid文件,并在文件中标明服务归属的序号。
在ZooKeeper启动时,会加载Zoo.cfg及myid文件。在加载完成完成后,会知道有多少台服务器共同组成一个服务集群。在构建FastLeaderElection实例时,先构建QuorumCnxManager实例,再构建FastLeaderElection实例。QuorumCnxManage实例主要是用于管理本地服务与其它集群服务之间的连接,FastLeaderElection实例会启动两个线程分别用来处理选举过程中需要发送和接收到消息,并提供Leading选举服务。
WorkSender是FastLeaderElection实例中的发送消息线程,主要负责从需要发送的消息队列获取消息,并将消息分发到本地服务与该消息对应的一个服务的消息队列。
WorkerReceiver是FastLeaderElection实例中处理接收消息的线程,主要负责从接收到的消息队列中获取消息,并将该消息转换为Notification,放入队列,为FastLeaderElection算法做准备。
QuorumCnxManage实例中会维护本地服务到其它集群服务之间的消息队列及连接。SendWorker线程主要负责从消息队列中获取消息并发送到与之对应的服务。
RecvWorker线程主要负责从对应的服务端接收消息,并将接收到的消息放到Message消息队列。















 798
798

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









