







 本文提出了RM操作,一种新型方法,用于消除ResNet和MobileNetV2等深度神经网络中的残差连接,同时保持模型性能。RM操作通过保留输入特征映射并合并信息,能够在不改变输出的情况下移除残差连接。这种方法不仅有助于提高网络的并行度,而且有利于网络修剪,尤其是在ResNet和RepVGG等模型中。实验表明,RMNet在速度-精度权衡上优于ResNet,并且能帮助RepVGG克服深度限制。此外,RM操作还能将MobileNetV2转换为更高效的MobileNetV1结构。
本文提出了RM操作,一种新型方法,用于消除ResNet和MobileNetV2等深度神经网络中的残差连接,同时保持模型性能。RM操作通过保留输入特征映射并合并信息,能够在不改变输出的情况下移除残差连接。这种方法不仅有助于提高网络的并行度,而且有利于网络修剪,尤其是在ResNet和RepVGG等模型中。实验表明,RMNet在速度-精度权衡上优于ResNet,并且能帮助RepVGG克服深度限制。此外,RM操作还能将MobileNetV2转换为更高效的MobileNetV1结构。
知乎解析:图解RMNet - 知乎
ABSTRACT:
尽管残差连接可以训练非常深度的神经网络,但由于其多分支拓扑结构,它不利于在线推理。这促使许多研究人员致力于设计DNN,在推理时不存在残余连接。例如,RepVGG在部署时将多分支拓扑重新参数化为类似VGG(单分支)的模型,在网络相对较浅时表现出良好的性能。然而,RepVGG无法将ResNet等效地转换为VGG,因为重新参数化方法只能应用于线性块,并且非线性层(ReLU)必须放在剩余连接之外,这导致表示能力有限,尤其是对于较深的网络。在本文中,我们旨在解决这个问题,并提出通过ResBlock上的保留和合并(RM)操作等效地移除普通ResNet中的残余连接。具体来说,RM操作允许输入特征映射在保留其信息的同时通过块,并合并每个块末尾的所有信息,这可以在不改变原始输出的情况下删除剩余连接。作为一种插件方法,RM操作基本上有三个优点:1)它的实现使其对高比率网络修剪自然友好。2) 它有助于打破RepVGG的深度限制。3) 与ResNet和RepVGG相比,它可以获得更好的精度-速度权衡网络(RMNet)。我们相信RM操作的思想可以启发人们对未来社区模型设计的许多见解。
1 INTRODUCTION
自AlexNet Krizhevsky等人(2012)问世以来,最先进的CNN变得越来越深。例如,AlexNet只有5个卷积层,VGG网络Simonyan&Zisserman(2015)和GoogLeNetSzegedy等人(2015;2016;2017)很快分别将其扩展到19层和22层。然而,由于梯度消失和爆炸问题,仅堆叠层的深度网络很难训练-随着梯度反向传播到早期层,重复乘法可能会使梯度无限小或无限大。规范化初始化LeCun等人(2012)在很大程度上解决了这个问题;Glorot和Bengio(2010);Saxe等人(2013);He等人(2015)和中间归一化层Ioffe&Szegedy(2015),这使得具有数十层的网络能够收敛。同时,另一个退化问题也暴露出来:随着网络深度的增加,精度达到饱和,然后迅速下降。ResNet-He等人(2016a;b)解决了退化问题,并通过添加从块输入到输出的剩余连接来实现1K+层模型。ResNet不希望每个堆叠层直接适合所需的底层映射,而是让这些层适合剩余映射。当单位映射是最优的时,将残差推到零比通过一堆非线性层拟合单位映射更容易。随着ResNet越来越普及,研究人员提出了许多新的架构,例如Hu等人(2018);李等(2019);谭(2019;2021),基于ResNet,从不同角度解读成功。
然而,李等人(2020年)指出,ResNet-50中的剩余连接约占特征图上整个内存使用量的40%,这将减缓推理过程。此外,网络中的剩余连接对于“网络修剪”丁等人(2021b)来说并不友好。相比之下,类似VGG的模型,在本文中也称为平原模型,只有一条路径,并且速度快、内存经济、并行友好。RepVGG Ding等人(2021b)提出了一种强大的方法,通过在推理时重新参数化来移除剩余连接。具体来说,RepVGG将3×3卷积、1×1卷积和身份加在一起进行训练。在每个分支的末端添加BN层,并在添加操作后添加ReLU。在训练过程中,RepVGG只需要学习残差映射,而在推理阶段,利用重新参数化将RepVGG的基本块转换为3×3卷积层加ReLU运算的堆栈,与ResNet相比,具有良好的速度精度权衡。然而,我们发现当网络深入时,RepVGG的性能会严重下降,我们在第3节提供了实验来验证这一观察结果。
在本文中,我们介绍了一种称为RM操作的新方法,该方法可以消除与其中非线性层的残余连接,并保持模型的结果不变。RM操作通过第一卷积层、BN层和ReLU层保留输入特征映射,然后通过ResBlock中的最后一次卷积将其与输出特征映射合并。通过这种方法,我们可以将预先训练好的ResNet或MobileNetV2等效地转换为RMNet模型,以提高并行度。此外,RMNet的体系结构使其易于修剪,因为不存在残余连接。我们将主要贡献总结如下:
我们发现,通过重新参数化方法消除残余连接有其局限性,尤其是当模型深度较大时。它存在于非线性操作中,不能放在剩余连接中。进行重新参数化我们提出了一种称为RM操作的新方法,该方法通过保留输入特征映射并将其与输出特征映射合并,可以消除非线性层之间的残余连接,而不改变输出通过RM操作,我们可以将ResBlocks转换为卷积和relu的堆栈,这有助于获得更深层的网络,而不存在残余连接,并且非常便于修剪。
2 RELATED WORK
Advantage of Residual Networks over Plain Model:He等人。He等人(2016a)介绍了用于解决退化问题的ResNet。此外,PreActResNet He等人(2016b)中的层梯度即使在权重任意小的情况下也不会消失,这导致了良好的反向传播特性。Weinan(2017)展示了动力系统与深度学习之间的联系。Lu等人(2018)将ResNet视为常微分方程(ODE)的Euler离散化。NODEs Chen等人(2018年)用神经常微分方程替换剩余块,以更好地训练极深网络。Balduzzi等人(2017年)确定了导致DNN训练困难的破碎梯度问题。他们表明,标准前馈网络中梯度之间的相关性随深度呈指数衰减。相比之下,ResNet中的梯度更能抵抗破碎和亚线性衰减。Veit等人(2016)表明,剩余网络可以被视为许多不同长度路径的集合。从这个角度来看,n个块的ResNet有O()个连接输入和输出的隐式路径,添加一个块会使路径数加倍。
DNNs Without Residual Connection:最近的一项工作Oyedotun等人(2020年)结合了几种技术,Leaky ReLU, max-norm, and careful initialization,以训练30层平面ConvNet,其最高精度可达74.6%,比其基线低2%。Xiao等人(2018)提出了一种基于平均场理论的方法来训练无分支的极深神经网络。然而,1K层平面网络在CIFAR-10上仅达到82%的精度。Balduzzi等人(2017年)使用“外观线性”初始化方法和CReLUs Shang等人(2016年)在CIFAR-10上训练198层平面模型,使其精度达到85%。虽然理论贡献很有见地,但这些模型并不实用。可以以重新参数化的方式获得没有剩余连接的DNN:重新参数化丁等人(2019;2021a)意味着使用结构的参数来参数化另一组参数。这些方法首先训练具有剩余连接的模型。并在推理时通过重新参数化去除残余连接。DiracNet Zagoruyko和Komodakis(2017)使用单位矩阵和卷积矩阵的加法进行转发传播,卷积参数只需学习ResNet之类的残差函数。训练后,DiracNet将单位矩阵添加到卷积矩阵中,并使用重新参数化的模型进行推理。然而,DiracNet只能训练多达34层的平面模型,在ImageNet上的精度为72.83%。RepVGG Ding等人(2021b)仅在训练时部署残差神经网络。在推理过程中,RepVGG可以通过重新参数化将剩余块转换为由3×3卷积和ReLU堆栈组成的普通模块。DiracNet和RepVGG之间的区别是DiracNet中的每个块有两个分支(没有BN的恒等式和3×3 ConvBN),而RepVGG有三个分支(有BN的恒等式、3×3 ConvBN和1×1 ConvBN)。然而,那些使用交换特性的重新参数化方法只能应用于线性层,即非线性层必须在剩余连接之外,这限制了神经网络在大深度下的潜力。
Filter Pruning:滤波器剪枝是加速神经网络的一种很有前途的解决方案。许多鼓舞人心的作品通过评估过滤器的重要性来修剪过滤器。提出了启发式指标,如卷积核的大小李等人(2017),零激活的平均百分比(APoZ)胡等人(2016)。还有一些工作可以让网络自动选择重要的过滤器。例如,刘等人(2017a)稀疏化BN层中的权重,以自动找到哪些滤波器对网络性能贡献最大。然而,对于基于ResNet的体系结构,残余连接的存在限制了剪枝的能力,因为通过残余连接的输入和输出的维度必须保持相同。因此,ResNet的剪枝率不大于平原模型的剪枝率。由于RM操作可以等效地将ResNet转换为普通模型,因此传递模型(RMNet)在剪枝方面也具有很大的优势。
3 PRELIMINARY
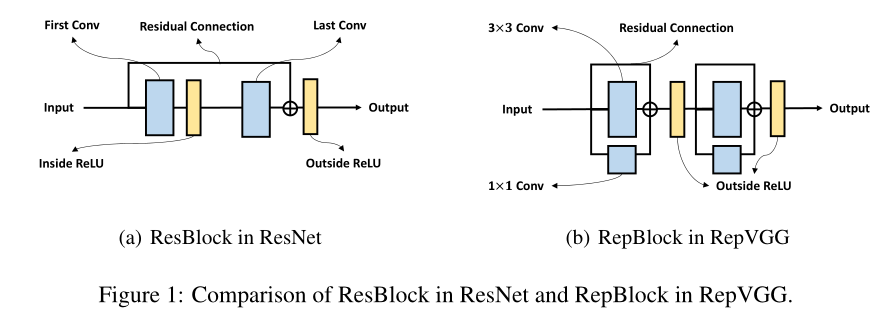
我们在图1中描述了ResNet和RepVGG中使用的基本块。在ResBlock(图1(a))中,两个relu分别位于剩余连接的内部和外部。而在RepBlock(图1(b))中,由于重新参数化基于乘法的交换定律,两个RELU必须都位于剩余连接之外。通过用两个repblock替换每个ResBlock,可以从基本ResNet架构构建RepVGG。接下来,我们分析了为什么RepVGG不能像ResNet那样从向前和向后传播中进行深度训练:
forward path: Veit等人(2016年)假设ResNet的成功可以归功于“模型集成”。我们可以将ResNet视为多条不同长度路径的集合。因此,n块的ResNet具有O()条连接输入和输出的隐式路径。然而,与ResNet不同的是,块中的两个分支是可分离的且不能合并,RepVGG中的多个分支可以由一个分支表示,其可以显示为:
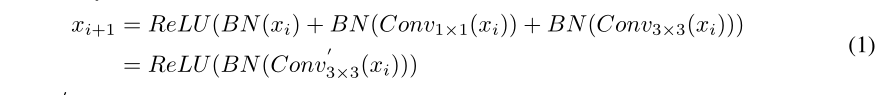
其中,是分支中每个Conv的合并卷积。因此,RepVGG不具有ResNet的隐式“集成假设”,并且RepVGG和ResNet之间的表示差距随着块数的增加而增加。
backward path:Balduzzi等人(2017)分析了深度神经网络中的“破碎梯度问题”。当反向路径中存在更多RELU时,梯度的相关性表现为“高斯白噪声”。假设ResNet和RepVGG都有n层。从图1(a)可以看出,ResNet中的信息可以通过残差,而不需要通过每个块中的ReLU内部。然而,RepVGG中的每个ReLU都位于主路径中。因此,反向路径中ResNet的relu数为n/2,而路径中RepVGG的relu数为n,这表明当深度较大时,ResNet中的梯度更抗破碎,从而比RepVGG具有更好的性能.
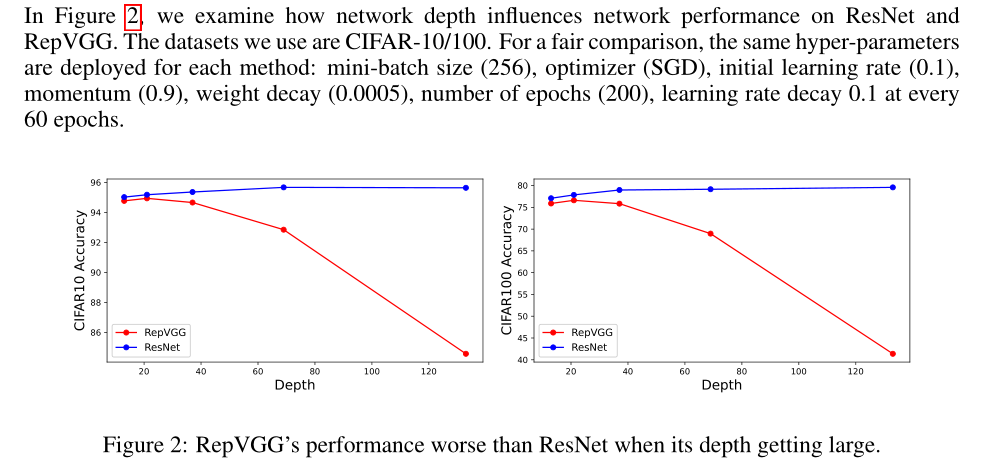
表1显示了RepVGG和ResNet在ImageNet数据集上的性能。我们可以看到,在相同的网络结构下,ResNet-18比RepVGG-18高0.5%,ResNet-34在top-1精度方面比RepVGG高0.8%。因此,RepVGG以失去表示能力为代价提高了速度。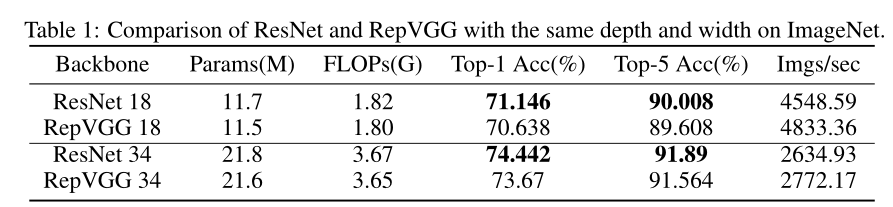
4 RM OPERATION AND RMNET: TOWARDS AN EFFICIENT PLAIN NETWORK
4.1 RM OPERATION
图3显示了通过RM操作等效删除剩余连接的过程。为简单起见,我们在图中未显示BN层,输入通道、介质通道和输出通道的数量相同,并分配为C
Reserving:我们首先在Conv 1中插入几个狄拉克初始化滤波器(输出通道)。狄拉克初始化滤波器的数量与卷积层中输入通道的数量相同。狄拉克初始化滤波器定义为四维矩阵:
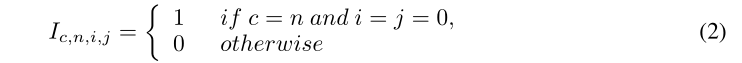
上
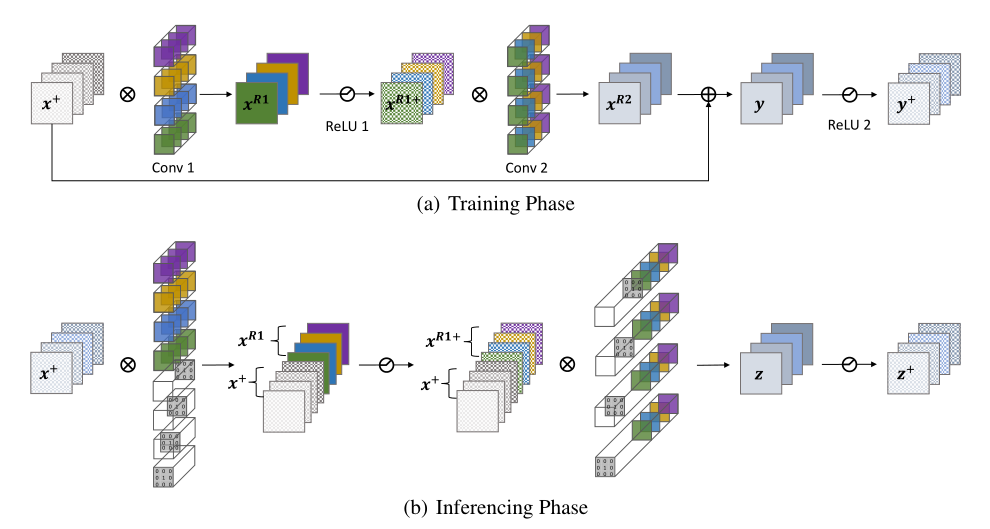 图显示了训练阶段的ResBlock。下图是用于推理的已转换RMBlock,它没有剩余连接。给定相同的输入,两个块具有相同的输出。我们可以在图3(b)中查看这些过滤器。每个滤波器只有一个元素为1,可以通过卷积保留输入特征映射的相应信道信息。
图显示了训练阶段的ResBlock。下图是用于推理的已转换RMBlock,它没有剩余连接。给定相同的输入,两个块具有相同的输出。我们可以在图3(b)中查看这些过滤器。每个滤波器只有一个元素为1,可以通过卷积保留输入特征映射的相应信道信息。
对于BN层,为了保留输入特征映射,需要调整BN中的权重w和偏差b,以使BN层表现为Identity function。假设特征映射的运行均值和运行方差分别为µ和,我们设置w=
偏差b=µ。然后,对于通过BN层的任何输入x,输出为:

For the ReLU layer, There are two cases to be considered:
当通过剩余连接的输入值为非负时(即在ResNet中,每个ResBlock都有一个后续的ReLU层,该层保持输入值均为非负),我们可以直接使用ReLU来保留信息。因为ReLU不会改变非负值
当通过剩余连接的输入值可能为负时(例如,在MobileNetV2中,ReLU仅位于ResBlock的中间),我们使用PReLU而不是ReLU来保留信息。有关附加通道的PReLU参数设置为1。这样,PReLU表现为一个Identity function。
从上述分析中可以看出,输入特征映射可以由ResBlock中的Conv 1、BN和ReLU很好地保留。

4.2 PRUNING RMNET
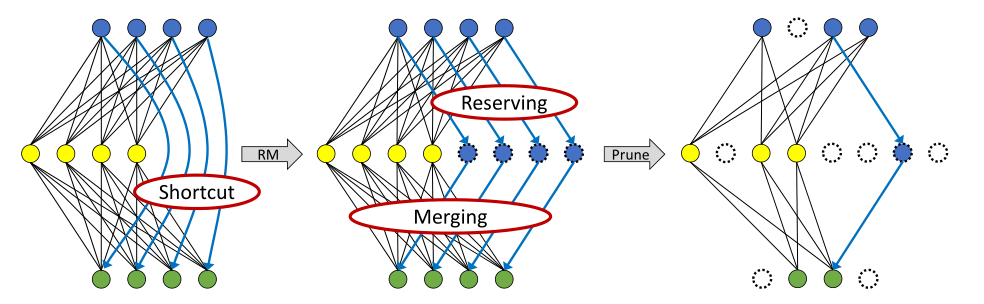
图4:ResNet上的修剪过程。在此过程中,RMNet可以作为一种过渡,以获得更大的剪枝率。
由于RMNet没有任何剩余连接,因此它对过滤器修剪更为友好。在本文中,我们采用网络瘦身(Liu等人,2017b)来修剪RMNet,因为它简单有效。具体来说,我们首先在BN层训练ResNet和稀疏权重。注:在训练期间,应在剩余连接中添加额外的BN层,因为我们还需要确定RM操作后哪些额外的滤波器是重要的。训练后,我们将ResNet转换为RMNet,并根据BN层中的权重修剪过滤器,这与vanilla网络瘦身相同。图4显示了修剪的整个过程。与传统方法不同,RMNet可以作为一种过渡,以获得更大的剪枝率。
4.3 IMPROVING REPVGG WITH RM OPERATION
作为一种“插件”方法,RM操作可以帮助RepVGG实现更好的性能,即使深度很大。如图5所示,我们训练了一个剩余连接跨越非线性层的网络。输入特征图由通道分离为两部分,具有预定义的保留率。输入特征图左侧的信息流表现为RepVGG,右侧的信息流表现为ResNet。通过RM操作,我们可以利用第一层中的一些通道来保留输入特征映射,并且在其之后的ReLU不会改变其值。然后在第二层,即RepBlock,可以将保留的输入特征映射合并到输出特征映射。接下来,我们可以使用重新参数化将RepBlocks转换为PlainBlocks。这种设计的好处是打破了RepVGG的深度限制,因为保留的输入通道可以帮助模型更好地学习(见第5.2节)。
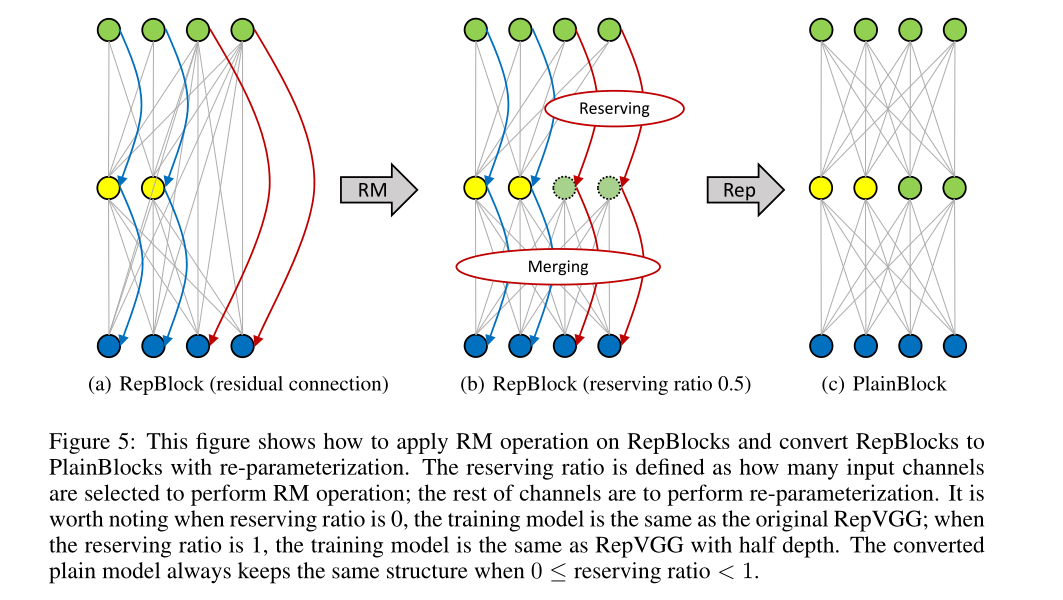
图5:此图显示了如何在RepBlocks上应用RM操作,并通过重新参数化将RepBlocks转换为PlainBlocks。保留率定义为选择多少个输入通道来执行RM操作;其余通道将执行重新参数化。值得注意的是,当保留率为0时,训练模型与原始RepVGG相同;当保留率为1时,训练模型与半深度RepVGG相同。当0时,转换后的平面模型始终保持相同的结构≤reserving ratio<1
4.4 CONVERT MOBILENETV2 TO MOBILENETV1
从技术上讲,使用RM操作转换ResNet和转换mobilenetw2没有区别。然而,MobileNetV2结构的特殊性允许在RM操作后使用参数融合进一步减少推理时间。
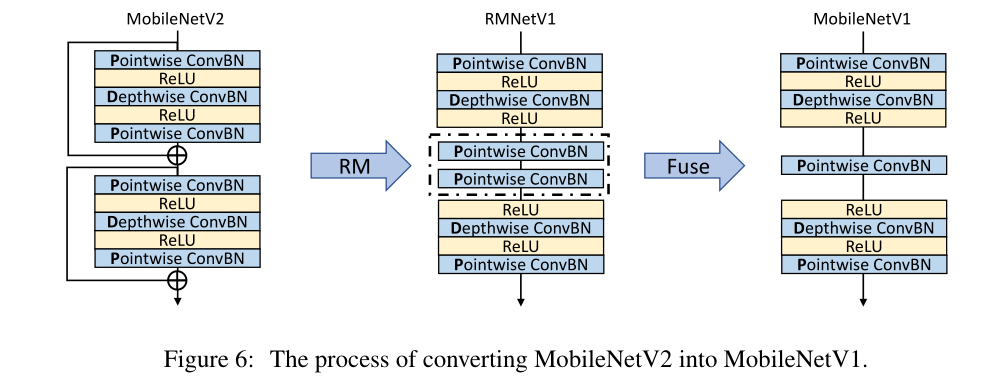
从图6可以看出,在MobileNetV2上应用RM操作后,剩余的连接被删除,剩下两个点式ConvBN层,如虚线框所示。由于卷积和批处理归一化都可以通过矩阵乘法来表示,并且它们之间不存在非线性层,因此这两个点态ConvBN层可以融合。数学上,假设X、Y、W、B是虚线框中第一个点态ConvBN层的输入特征图、输出特征图、权重和偏差,Z、W 0、B 0是虚线框中第二个点态ConvBN层的输出特征图、权重和偏差。融合参数的过程可以表示为:
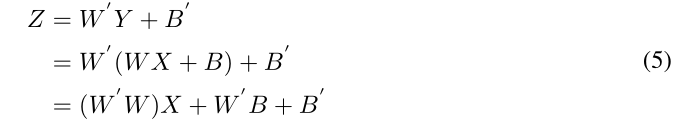
![]() 因此,RM操作提供了另一个通过融合参数来进一步减少推断时间的机会。在参数融合后,RMNet的架构与MobileNetV1相同,这是非常有趣的,因为MobileNetV2的存在是为了通过利用剩余连接来提高MobileNetV1的泛化能力。然而,我们表明RM操作可以逆转这一过程,即将MobileNetV2转换为MobileNetV1,使MobileNetV1再次伟大。我们在第5.3节中提供了实验来验证这种转换的有效性。
因此,RM操作提供了另一个通过融合参数来进一步减少推断时间的机会。在参数融合后,RMNet的架构与MobileNetV1相同,这是非常有趣的,因为MobileNetV2的存在是为了通过利用剩余连接来提高MobileNetV1的泛化能力。然而,我们表明RM操作可以逆转这一过程,即将MobileNetV2转换为MobileNetV1,使MobileNetV1再次伟大。我们在第5.3节中提供了实验来验证这种转换的有效性。
5 EXPERIMENTS
本节安排如下:在第5.1节中,我们验证了RMNet对网络剪枝任务的有效性。在第5.2节中,我们展示了RM操作可以帮助训练更深层次的RepVGG;在第5.3节中,我们表明RMNet适用于轻型模型;第5.4节。我们表明,RMNet可以在CIFAR10\/100和ImageNet数据集上实现更好的速度-精度权衡;在批量为128的 Tesla V100 GPU上测试,方法是先给50 batches,并记录时间使用情况。
5.1 FRIENDLY FOR PRUNING
我们在图7中进行了一个实验,以验证修剪RMNet的有效性。我们使用L1范数乘以某个稀疏因子来惩罚BN层的权重,并将权重小于某个阈值的信道视为无效。稀疏因子从[1e4,1e-3]中选择,阈值从[5e-4,5e-3]中选择。稀疏度和阈值越大,剪枝率越大。
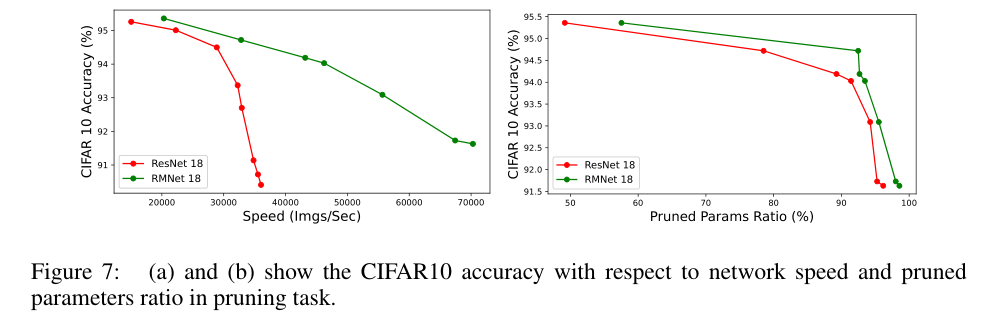
实验表明,在相同的速度下,修剪后的RMNet比修剪后的ResNet保持了更高的精度。由于结构更合理,在剪枝率几乎相同的情况下,修剪后的RMNet的速度比修剪后的ResNet快。因此,与ResNet架构相比,RMNet在修剪任务方面具有更好的准确性和速度权衡。
5.2 BREAK THE DEPTH LIMITATION OF REPVGG
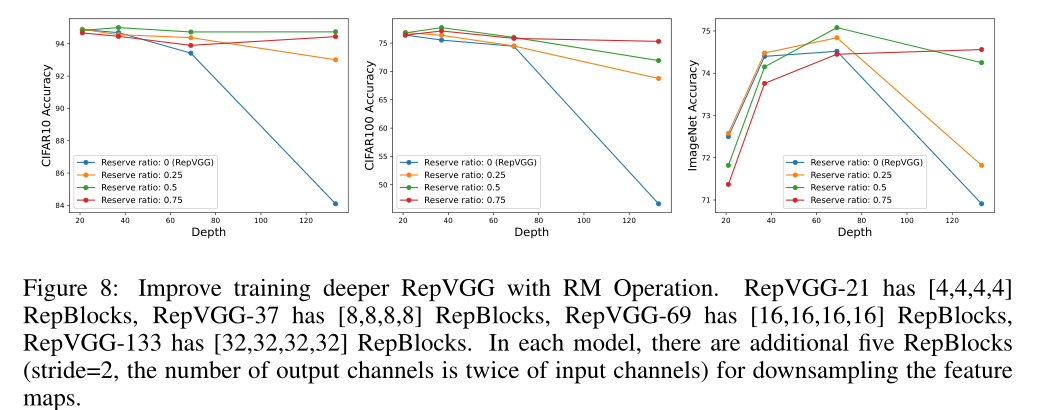
我们在CIFAR-10\/100和ImageNet上进行了一个实验,以评估RM操作是否可以帮助RepVGG在网络深入时实现更好的性能。如图8所示,我们绘制了不同保留率下的性能。为了公平比较,ImageNet上的实验遵循RepVGG 的官方实现。
从第4.3节可以看出,当深度相对较小时,原始RepVGG表现良好,而当深度增加时,性能略有下降。然而,具有RM操作的RepVGG可以随着深度的增加保持良好的性能。例如,当RepVGG为21或37层时,保留25%的输入特征图通道表现更好;当RepVGG为69层时,保留50%通道的输入特征图表现更好;当RepVGG为133层时,保留75%的输入特征图通道表现更好,这些结果表明网络需要更多的参数和较少的剩余连接(较小的保留率),而更深的网络需要更多的剩余连接(较大的保留率)。因此,我们的实验表明,我们的设计可以突破RepVGG的深度限制。
5.3 FRIENDLY FOR LIGHT-WEIGHT MODELS
我们进行了一个实验来验证第4.4节中的分析。我们首先从头开始训练MobileNetV2,并按照第4.4节介绍的过程将其转换为RMNetV1(即MobileNetV1)。注意,必须重新设计MobileNetV2的初始架构,以确保转换后的RMNetV1具有与原始论文中的MobileNetV1相同的架构(深度和宽度)(Howard等人(2017))。因此,图6中的MobileNet V2不同于vanilla MobileNet V2(Sandler等人(2018))。我们还从头开始训练MobileNetV1进行比较。结果如表2所示。

5.4 DESIGN BETTER ACCURACY-SPEED TRADEOFF RMNEXT
从第4.1节中,RMNet消除了带来额外参数的成本中的剩余连接。例如,在图3中,RM操作将原始ResBlock的参数数量增加了一倍。为了缓解这个问题,我们在基于ResNet的架构上使用RM操作,并使用反向残差块来设计RMNet。反向残差块(IRB)主要包含三个连续步骤: point-wise convolution, group-wise convolution and point-wise convolu-tion。第一个“逐点卷积”将使输入特征图的通道数增加T倍,第二个“逐点卷积”将通道数减少到原始数量。对于逐点卷积,RM操作只会将参数和浮点数增加1/ T倍。假设输入特征映射的大小为H×W×C,第一点卷积层的参数表示为T×C×C×1×1。我们只需要额外的C×C×1×1参数来保留输入特征映射,因为RM操作仅保留输入特征映射,“分组卷积”也是参数友好的。例如,对于正常卷积,我们需要C×K×K参数来保留输入通道的信息。而对于分组卷积,我们只需要1 /G倍的参数来保留信息,其中G是分组卷积中的组数。此外,存储和计算的成本不会改变是否使用分组卷积。
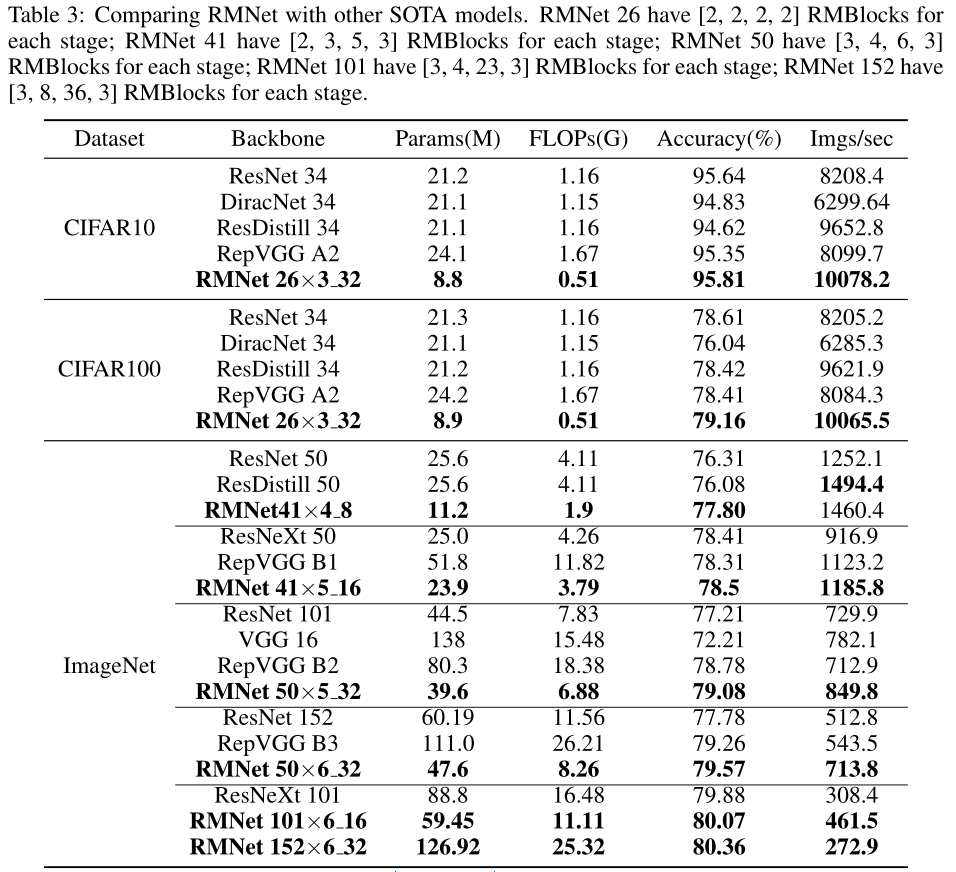
基于IRB的优点,我们设计了一系列RMNet模型。我们首先通过[64、128、256、512]的经典宽度设置来确定输入和输出宽度。我们将头部的7×7 Conv和MaxPooling替换为3×3 Conv、BN和ReLU的两个序列(与RepVGG中使用的方法相同)。RMNet的尾部与ResNet相同。对于RMNet 50x6 32,“50”表示所有Conv层的数量6’表示经典宽度设置的倍数,例如,RMNet 50x6 32中分组卷积层的宽度为[6×64,6×128,6×256,6×512];'32’表示RMBlock中每个组的通道数。我们在A.4中打印了RMNet的详细架构。接下来,我们在CIFAR10/100和ImageNet上将RMNet与SOTA模型进行比较,以测试速度和精度。
6 CONCLUSION AND DISCUSSION
在本文中,我们提出了RM操作来移除剩余连接,并执行RM操作将ResNet和MobileNetV2转换为普通模型(RMNet)。RM操作允许输入特征映射在保留其信息的同时通过块,并合并每个块末尾的所有信息,这可以在不改变原始输出的情况下移除剩余连接。实验表明,RMNet可以实现更好的速度-精度权衡,并且非常适合网络修剪。需要考虑的未来方向有:1)分析基于变压器的架构上的残余连接,并通过RM操作移除此类连接。2) 搜索与NAS的剩余连接较少的网络,并将其转换为高效的RMNet

















 977
977

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









