








概述
深度学习模型通常具有在训练之前必须设置的可变参数,称为超参数。这些值有效地影响模型的结果。因此,应找到这些参数的最佳值以获得最佳结果。寻找最佳组合称为超参数优化。
介绍
超参数调优是为神经网络的超参数找到最佳值的过程。超参数会影响模型的性能,并在训练前设置。超参数调优可以提高神经网络的准确性和效率,对于获得良好的结果至关重要。
例如,模型的学习率可以决定模型的学习速度。仅当学习率超参数太小或太大时,模型才能很好地拟合数据。因此,神经网络超参数的正确平衡对于模型的性能非常重要。
超参数优化的几种方法包括手动优化、网格搜索和随机搜索。
什么是超参数调优?
超参数优化涉及测试超参数值的各种组合,并返回产生最佳性能的组合。
它有什么作用?
超参数优化使用算法和工具,搜索 Epochs、Batch Size、学习率等值,以找到最佳值组合。
例如,假设要测试的纪元值范围为50−50050−5 0 0.在这种情况下,超参数优化过程将使用每个值评估模型的性能,并返回最佳纪元值。
它是如何工作的?
假设我们正在构建一个神经网络来对动物图像进行分类。我们想要调整的一些神经网络超参数包括学习率、网络中的层数和批量大小。
我们可以使用网格搜索来查找这些超参数的最佳值。为此,我们首先为要调整的每个超参数定义一个值范围。例如,我们可以定义以下范围:
- 学习率:0.001 至 0.1。
- 层数:1 至 5 层
- 批量大小:32 至 128
接下来,我们创建一个包含这些值的所有可能组合的网格。例如,如果我们有以下值:
- 学习率:0.001、0.01、0.1
- 层数:1、3、5
- 批量大小:32、64、128
然后网格将有27(3�3�3)27(3 x 3 x3)总组合。 然后,我们训练神经网络,评估每个组合的模型,并记录结果。例如,我们可以在验证集上记录每个模型的准确性。
最后,我们选择了产生最佳结果的组合。结合 0.01 的学习率、3 层和 64 的批量大小产生了最高的准确度。这种组合将是超参数的最佳值,我们将使用这些值来训练最终模型。
调音
隐藏层数
隐藏层的数量是一个超参数,可以显著影响模型的性能。增加隐藏层可以使模型学习数据中更复杂的关系。尽管如此,它也可能增加过度拟合的风险,并需要更多的计算资源。
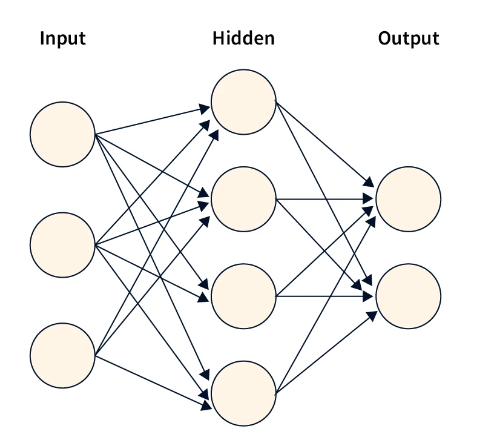
隐藏层的最佳数量可能因问题的复杂性和数据集的大小而异。一般来说,更大的数据集和更复杂的问题需要更深层次的网络和更多的隐藏层。较小的数据集和更简单的问题可能需要较少的隐藏层。
每个隐藏层的神经元数
每个隐藏层的神经元数的行为与层数类似。神经元的数量随着数据的复杂性而增加。神经网络中的神经元数量可能因所选架构而异。增加神经元有助于更好地拟合数据。而减少层数有助于减少偏差和加快训练速度。通常,神经元的数量会增加,直到性能没有改善。需要注意的是,这个参数也容易过拟合。
学习率
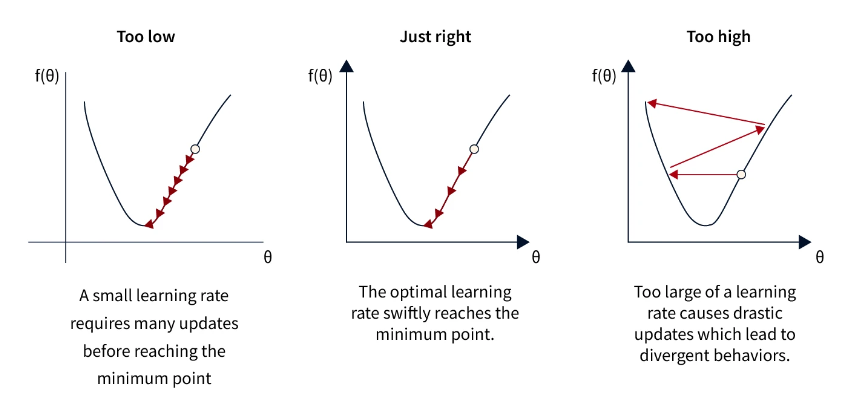
学习率是神经网络中的一个超参数,它决定了优化器在训练期间更新模型权重的步长。学习率会显著影响模型的性能,因为较低的学习率可能会导致收敛速度变慢,但模型更准确。相比之下,较大的学习率可能会导致更快的收敛,但模型的准确性较低。
批量大小
批处理大小可能会影响模型的泛化性能。较大的批处理大小可能会带来更好的泛化,使模型能够对更多示例进行平均,并减少模型的权重方差。但是,非常大的批量大小也可能导致模型收敛到次优解,因为它可能会导致学习速率变慢和梯度噪声较小。
较大的批处理大小可能允许模型使用可用硬件更有效地执行,因为它可以更好地使用矢量化操作和并行化。但是,较大的批处理大小也可能导致内存问题,因为它可能需要更多的内存来存储梯度和中间激活。
调谐时如何避免过拟合?
过拟合是训练神经网络时的常见问题。在进行超参数调优时,这可能特别成问题,因为它可能导致选择在训练数据上运行良好的超参数,但需要更好地泛化到看不见的数据。
以下是一些可用于避免神经网络超参数优化期间过度拟合的方法:
- 使用单独的验证集在超参数优化期间评估模型的性能。
- 使用正则化技术,例如权重衰减(L2 正则化)或丢弃,可防止模型过度拟合训练数据。
- 如果模型在验证集上的性能开始下降,请提前停止终止训练过程。
- 在训练期间,模型的性能在单独的验证集上进行监视,当模型在验证集上的性能开始下降时,训练过程将终止。这是基于这样的假设,即模型在验证集上的性能通常会随着训练的进行而提高,直到达到模型开始过度拟合训练数据的某个点。通过此时中断训练过程,提前停止有助于防止模型过度拟合训练数据。
超参数优化函数
可以使用多种方法对神经网络执行超参数优化,包括网格搜索、随机搜索和贝叶斯优化。
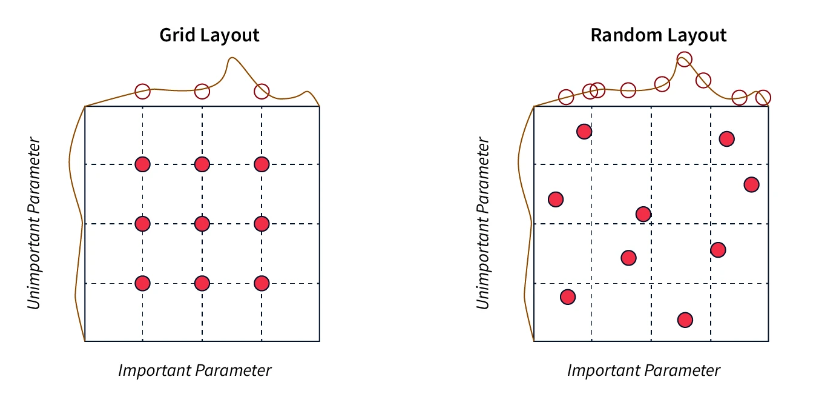
网格搜索
网格搜索是一种超参数优化方法,涉及指定超参数值的网格,并针对每个超参数值组合训练和评估神经网络模型。例如,如果我们想调整神经网络的学习率和批量大小,我们可以为学习率(例如,0.1、0.01、0.001)和批量大小(例如,32、64、128)指定一个可能值的网格,并针对每个值组合训练和评估模型。 然后,在验证集上产生最佳结果的超参数组合被选为最佳超参数集。
随机搜索
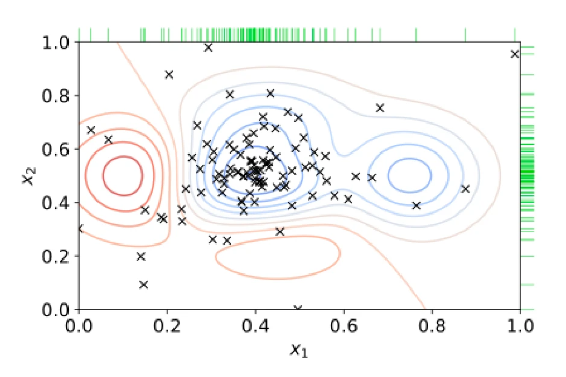
随机搜索是另一种超参数调优方法,涉及对超参数值的随机组合进行采样,并针对每个组合训练和评估神经网络模型。随机搜索可能比网格搜索更有效,因为它不需要评估所有可能的超参数组合。
随机搜索可能比网格搜索更好,尤其是当模型的最佳值介于指定值之间时。例如,如果最优学习率为 0.05,指定值为 0.01 和 0.1,则网格搜索不会给出好的结果,而随机搜索可以得到最优值。
贝叶斯优化
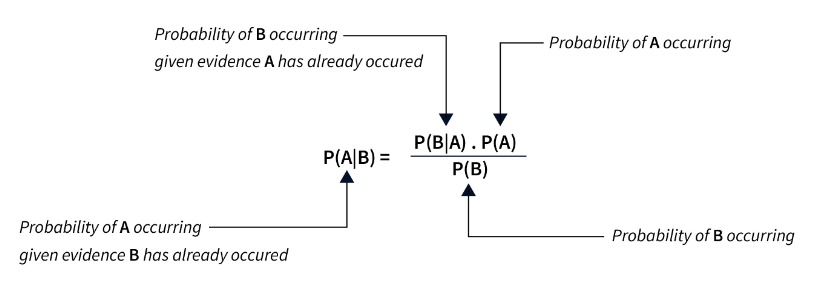
贝叶斯优化是一种更高级的超参数优化方法,它使用基于超参数和准确率分数的概率函数来对超参数的分布及其对模型性能的影响进行建模。
贝叶斯优化使用先前的分数和概率值在后续迭代中做出明智的决策。允许模型关注可以显著改变结果的超参数,而不关注参数不会对结果产生太大影响。
贝叶斯优化可能比网格搜索或随机搜索更有效,因为它可以自适应地选择下一组超参数进行评估,以根据先前的评估进行评估。但是,它的计算成本可能更高,并且需要更多资源。
结论
- 超参数优化为模型超参数选择最佳值以提高其性能。
- 神经网络超参数包括隐藏层的数量、每个隐藏层的神经元数、学习率和批量大小。
- 超参数优化方法包括网格搜索、随机搜索和贝叶斯优化。
- 使用单独的验证集、正则化、提前停止和交叉验证等技术可以避免过拟合。


















 3470
3470

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











