








目录
在本系列文章中,我们将引导您完成将CI/CD应用于AI任务的过程。您最终会得到一个满足Google MLOps 成熟度模型2级要求的功能管道。我们假设您对Python、深度学习、Docker、DevOps和Flask有一定的了解。
在上一篇文章中,我们讨论了CI/CD MLOps Pipeline的模型创建、自动调整和通知。在本节中,我们将查看在ML管道中实现持续训练所需的代码。下图显示了我们在项目流程中的位置。
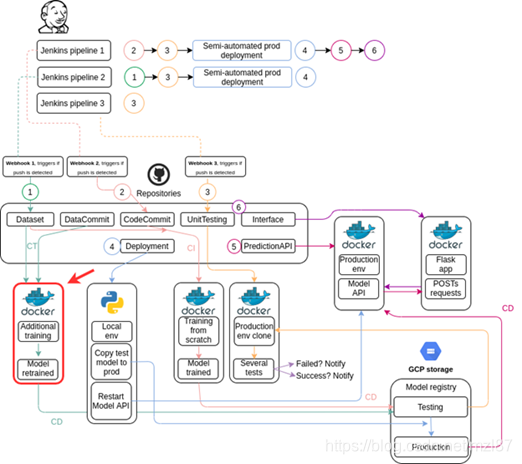
请记住,只要推送到数据集存储库,就会执行此工作流。该脚本将检查生产或测试注册表中是否有可用的模型。然后它会重新训练它找到的模型。这是我们的应用程序文件结构:

我们以精简版本显示代码文件。有关完整版本,请参阅代码存储库。
data_utils.py
该data_utils.py代码不会完全像以前一样。它从存储库加载数据,对其进行转换,并将生成的模型保存到GCS。唯一的区别是现在这个文件包含两个附加功能。其中一个检查测试注册表中是否存在模型,另一个加载该模型。
取上一篇文章中的data_utils.py文件,在文件末尾添加以下函数:
def previous_model(bucket_name,model_type,model_filename):
try:
storage_client = storage.Client() #if running on GCP
bucket = storage_client.bucket(bucket_name)
status = storage.Blob(bucket = bucket, name = '{}/{}'.format(model_type,model_filename)).exists(storage_client)
return status,None
except Exception as e:
print('Something went wrong when trying to check if previous model exists GCS bucket. Exception: ',flush=True)
return None,e
def load_model(bucket_name,model_type,model_filename):
try:
storage_client = storage.Client() #if running on GCP
bucket = storage_client.bucket(bucket_name)
blob1 = bucket.blob('{}/{}'.format(model_type,model_filename))
blob1.download_to_filename('/root/'+str(model_filename))
return True,None
except Exception as e:
print('Something went wrong when trying to load previous model from GCS bucket. Exception: '+str(e),flush=True)
return False,eemail_notifications.py
email_notifications.py代码基本上和以前一样,除了它现在发送不同的消息。
import smtplib
import os
# Variables definition
sender = ‘example@gmail.com’
receiver = ['svirahonda@gmail.com'] #replace this by the owner's email address
smtp_provider = 'smtp.gmail.com' #replace this by your STMP provider
smtp_port = 587
smtp_account = ‘example@gmail.com’
smtp_password = ‘your_password’
def training_result(result,accuracy):
if result == 'old_evaluation_prod':
message = "A data push has been detected. Old model from production has reached more than 0.85 of accuracy. There's no need to retrain it."
if result == 'retrain_prod':
message = 'A data push has been detected. Old model from production has been retrained and has reached more than 0.85 of accuracy. It has been saved into /testing.'
if result == 'old_evaluation_test':
message = "A data push has been detected,. Old model from /testing has reached more than 0.85 of accuracy. There's no need to retrain it."
if result == 'retrain_test':
message = 'A data push has been detected. Old model from /testing has been retrained and reached more than 0.85 of accuracy. It has been saved into /testing.'
if result == 'poor_metrics':
message = 'A data push has been detected. Old models from /production and /testing have been retrained but none of them reached more than 0.85 of accuracy.’
if result == 'not_found':
message = 'No previous models were found at GCS. '
message = 'Subject: {}\n\n{}'.format('An automatic training job has ended recently', message)
try:
server = smtplib.SMTP(smtp_provider,smtp_port)
server.starttls()
server.login(smtp_account,smtp_password)
server.sendmail(sender, receiver, message)
return
except Exception as e:
print('Something went wrong. Unable to send email: 'str(e),flush=True)
return
def exception(e_message):
try:
message = 'Subject: {}\n\n{}'.format('An automatic training job has failed recently', e_message)
server = smtplib.SMTP(smtp_provider,smtp_port)
server.starttls()
server.login(smtp_account,smtp_password)
server.sendmail(sender, receiver, message)
return
except Exception as e:
print('Something went wrong. Unable to send email.',flush=True)
print('Exception: ',e)
returntask.py
该task.py上述文件的代码编排执行。和以前一样,它检查主机上是否存在GPU,初始化GPU(如果找到),处理传递给代码执行的参数,并加载数据。并开始重新训练。再培训结束后,代码会将生成的模型推送到测试注册中心并通知产品所有者。让我们看看代码是什么样的:
import tensorflow as tf
from tensorflow.keras.callbacks import ModelCheckpoint
from tensorflow.keras.models import load_model
import argparse
import data_utils
import data_utils, email_notifications
import sys
import os
from google.cloud import storage
import datetime
# general variables declaration
model_name = 'best_model.hdf5'
def initialize_gpu():
if len(tf.config.experimental.list_physical_devices('GPU')) > 0:
tf.config.set_soft_device_placement(True)
tf.debugging.set_log_device_placement(True)
return
def start_training(args):
# Loading splitted data
X_train, X_test, y_train, y_test = data_utils.load_data(args)
# Initializing GPU if available (if available)
initialize_gpu()
# Checking if there's any model saved at testing or production folders in GCS
model_gcs_prod = data_utils.previous_model(args.bucket_name,'production',model_name)
model_gcs_test = data_utils.previous_model(args.bucket_name,'testing',model_name)
# If any model exists at production, load it, test it on data and if it doesn't reach good metric then retrain it and save it to testing folder
if model_gcs_prod[0] == True:
train_prod_model(X_train, X_test, y_train, y_test,args)
if model_gcs_prod[0] == False:
if model_gcs_test[0] == True:
train_test_model(X_train, X_test, y_train, y_test,args)
if model_gcs_test[0] == False:
email_notifications.training_result('not_found',' ')
sys.exit(1)
if model_gcs_test[0] == None:
email_notifications.exception('Something went wrong when trying to check if old testing model exists. Exception: '+model_gcs_test[1]+'. Aborting automatic training.')
sys.exit(1)
if model_gcs_prod[0] == None:
email_notifications.exception('Something went wrong when trying to check if old production model exists. Exception: '+model_gcs_prod[1]+'. Aborting automatic training.')
sys.exit(1)
def train_prod_model(X_train, X_test, y_train, y_test,args):
model_gcs_prod = data_utils.load_model(args.bucket_name,'production',model_name)
if model_gcs_prod[0] == True:
try:
cnn = load_model(model_name)
model_loss, model_acc = cnn.evaluate(X_test, y_test,verbose=2)
if model_acc > 0.85:
saved_ok = data_utils.save_model(args.bucket_name,model_name)
if saved_ok[0] == True:
email_notifications.training_result('old_evaluation_prod', model_acc)
sys.exit(0)
else:
email_notifications.exception(saved_ok[1])
sys.exit(1)
else:
cnn = load_model(model_name)
checkpoint = ModelCheckpoint(model_name, monitor='val_loss', verbose=1, save_best_only=True, mode='auto', save_freq="epoch")
cnn.fit(X_train, y_train, epochs=args.epochs,validation_data=(X_test, y_test), callbacks=[checkpoint])
model_loss, model_acc = cnn.evaluate(X_test, y_test,verbose=2)
if model_acc > 0.85:
saved_ok = data_utils.save_model(args.bucket_name,model_name)
if saved_ok[0] == True:
email_notifications.training_result('retrain_prod',model_acc)
sys.exit(0)
else:
email_notifications.exception(saved_ok[1])
sys.exit(1)
else:
return
except Exception as e:
email_notifications.exception('Something went wrong when trying to retrain old production model. Exception: '+str(e))
sys.exit(1)
else:
email_notifications.exception('Something went wrong when trying to load old production model. Exception: '+str(model_gcs_prod[1]))
sys.exit(1)
def train_test_model(X_train, X_test, y_train, y_test,args):
model_gcs_test = data_utils.load_model(args.bucket_name,'testing',model_name)
if model_gcs_test[0] == True:
try:
cnn = load_model(model_name)
model_loss, model_acc = cnn.evaluate(X_test, y_test,verbose=2)
if model_acc > 0.85: # Nothing to do, keep the model the way it is.
email_notifications.training_result('old_evaluation_test',model_acc)
sys.exit(0)
else:
cnn = load_model(model_name)
checkpoint = ModelCheckpoint(model_name, monitor='val_loss', verbose=1, save_best_only=True, mode='auto', save_freq="epoch")
cnn.fit(X_train, y_train, epochs=args.epochs, validation_data=(X_test, y_test), callbacks=[checkpoint])
model_loss, model_acc = cnn.evaluate(X_test, y_test,verbose=2)
if model_acc > 0.85:
saved_ok = data_utils.save_model(args.bucket_name,model_name)
if saved_ok[0] == True:
email_notifications.training_result('retrain_test',model_acc)
sys.exit(0)
else:
email_notifications.exception(saved_ok[1])
sys.exit(1)
else:
email_notifications.training_result('poor_metrics',model_acc)
sys.exit(1)
except Exception as e:
email_notifications.exception('Something went wrong when trying to retrain old testing model. Exception: '+str(e))
sys.exit(1)
else:
email_notifications.exception('Something went wrong when trying to load old testing model. Exception: '+str(model_gcs_test[1]))
sys.exit(1)
def get_args():
parser = argparse.ArgumentParser()
parser.add_argument('--bucket-name', type=str, default = 'automatictrainingcicd-aiplatform',help='GCP bucket name')
parser.add_argument('--epochs', type=int, default=2, help='Epochs number')
args = parser.parse_args()
return args
def main():
args = get_args()
start_training(args)
if __name__ == '__main__':
main()Dockerfile
该Dockerfile处理Docker容器构建。它从其存储库加载数据集,从其存储库加载代码文件,并定义容器执行应从何处开始:
FROM gcr.io/deeplearning-platform-release/tf2-cpu.2-0
WORKDIR /root
RUN pip install pandas numpy google-cloud-storage scikit-learn opencv-python
RUN apt-get update; apt-get install git -y; apt-get install -y libgl1-mesa-dev
ADD "https://www.random.org/cgi-bin/randbyte?nbytes=10&format=h" skipcache
RUN git clone https://github.com/sergiovirahonda/AutomaticTraining-Dataset.git
ADD "https://www.random.org/cgi-bin/randbyte?nbytes=10&format=h" skipcache
RUN git clone https://github.com/sergiovirahonda/AutomaticTraining-DataCommit.git
RUN mv /root/AutomaticTraining-DataCommit/task.py /root
RUN mv /root/AutomaticTraining-DataCommit/data_utils.py /root
RUN mv /root/AutomaticTraining-DataCommit/email_notifications.py /root
ENTRYPOINT ["python","task.py"]您会注意到代码中的ADD指令。这些强制构建过程在构建容器时始终提取存储库内容——而不是在本地注册表中兑现它们。
在本地构建并运行容器后,您应该能够使用新收集的数据重新训练模型。我们还没有谈到触发这个工作。我们将在稍后讨论GitHub webhooks和Jenkins时介绍这一步,但本质上,只要在相应的存储库中检测到推送,Jenkins就能够触发此工作流程。推送是通过Webhook检测到的,Webhook是一种在存储库本身中配置的方法。
在该过程结束时,您应该会找到存储在GCS测试注册表中的模型文件。
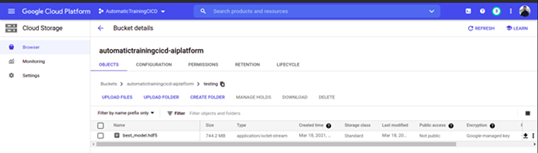
下一步
在接下来的文章中,我们将建立一个模型单元测试容器。敬请关注!
https://www.codeproject.com/Articles/5301648/Continuous-Training-in-an-MLOps-Pipeline















 1365
1365











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









