







目录

Chinese-LLaMA-Alpaca-3开源大模型项目正式发布,开源Llama-3-Chinese-8B(基座模型)和Llama-3-Chinese-8B-Instruct(指令/chat模型)。这些模型在原版Llama-3-8B的基础上使用了大规模中文数据进行增量预训练,并且利用高质量指令数据进行精调,进一步提升了中文基础语义和指令理解能力,相比一代和二代相关模型获得了显著性能提升。
相关模型已在🤗Hugging Face、🤖ModelScope、机器之心SOTA!社区、Gitee等平台同步上线。同步提供了GGUF量化版本模型(2bit~8bit),供用户快速便捷地体验相关模型。
项目地址:https://github.com/ymcui/Chinese-LLaMA-Alpaca-3
Llama-3 简介
2024年4月19日,Meta发布了最新一代开源大模型Llama-3,其中包括两个模型大小:8B、70B,并在未来会进一步开放400B+模型。每个模型均包括基座模型Llama-3以及经过对齐的对话模型Llama-3-Instruct。这些模型相比Llama-2在多个评测集上获得了显著的性能提升。相比Llama-2的主要区别:
-
词表大小:从32K提升至128K,并且使用了BPE词表
-
训练数据量:由2T tokens大幅度提升至15T tokens
-
上下文长度:由4096提升至8192
-
全尺寸均使用了GQA(Grouped-Query Attention)技术以提升效率

中文Llama-3
本项目推出了基于Llama-3开发的中文开源大模型Llama-3-Chinese和Llama-3-Chinese-Instruct,本次开源了8B模型版本。
-
Llama-3-Chinese-8B:基座模型,在Llama-3-8B上使用约120GB语料进行增量中文训练,与一期Plus系列模型、二期模型一致;
-
Llama-3-Chinese-8B-Instruct:指令/chat模型,在Llama-3-Chinese-8B的基础上进一步通过500万高质量指令进行精调获得。
本期模型与中文羊驼一期和二期相关模型最大的区别在于使用了原版Llama-3词表,而未对词表进行扩充。其中主要理由有以下几点:
-
Llama-3原生词表已从二代的32K提升至128K;
-
通过在中文维基百科上的编码实验表明,Llama-3原生词表的中文编码效率相比其二代具有显著提升,其效率约为中文LLaMA-2词表(大小:55296)的95%,因此认为编码效率已不是主要瓶颈;
-
结合我们在中文Mixtral大模型上的相关经验和实验结论,中文词表扩充并非大模型语言迁移的必要条件(见往期推送)
Llama-3生态支持
本项目相关模型已提供常见大模型生态的适配教程。用户可以快速使用熟悉的工具体验和部署大模型,其中包括:
-
llama.cpp:丰富的GGUF量化和高效本地推理
-
🤗transformers:原生transformers推理
-
text-generation-webui:前端WebUI界面部署方式
-
LM Studio:多平台大模型聊天软件(含界面)
-
Ollama:本地运行大模型推理
-
仿OpenAI API:可通过类似OpenAI API的形式部署服务
以及其他兼容Llama-3的相关工具。
主观评价效果
为了更加直观地了解模型的生成效果,本项目仿照Fastchat Chatbot Arena推出了模型在线对战平台,可浏览和评测模型回复质量。对战平台提供了胜率、Elo评分等评测指标,并且可以查看两两模型的对战胜率等结果。题库来自中文羊驼大模型相关项目人工制作的360题,涵盖10个大模型能力评测维度。
📊 模型在线对战:http://llm-arena.ymcui.com
以下是部分输出样例:



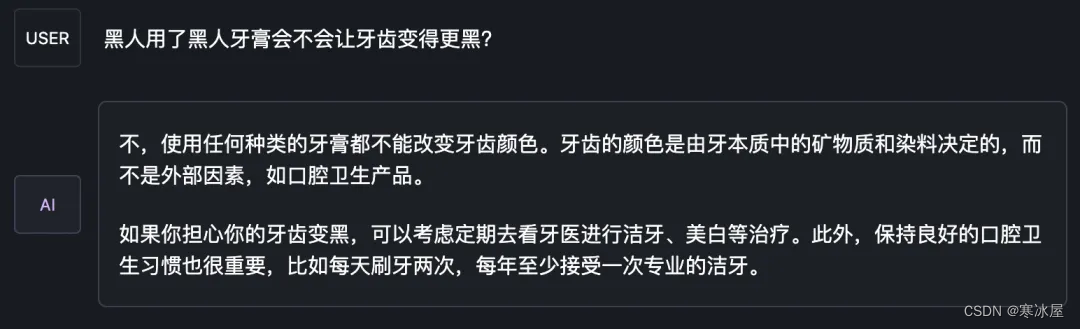
客观评价效果
以下是部分客观评价结果。与中文Mixtral的实验观察一致,中文增量预训练并不会快速提升中文下游任务能力,而是在指令精调之后显现出相应的效果。在英文任务上,部分集合超过了原版模型的性能。详细结果请查阅项目主页。
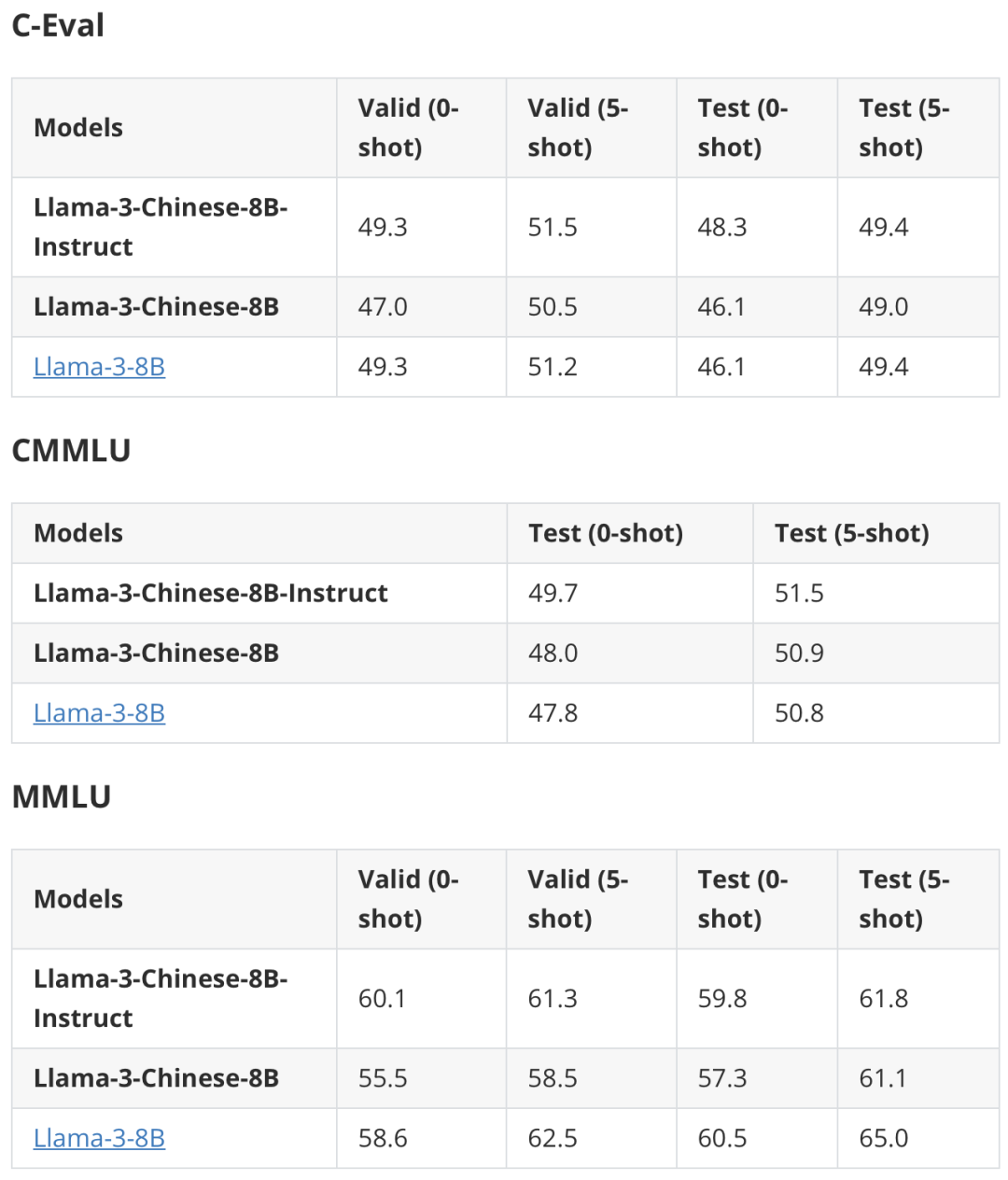
开源指令数据
除了开源模型之外,本项目还开源了部分指令数据,感兴趣的读者可访问项目主页进行下载。
-
alpaca_zh_51k:使用gpt-3.5翻译的Alpaca指令数据,共计51K条
-
stem_zh_instruction:使用gpt-3.5爬取的STEM指令数据,包含物理、化学、医学、生物学、地球科学,共计256K条
-
ruozhiba_gpt4_turbo:使用gpt-4-turbo-2024-04-09获取的ruozhiba问答数据,共计2449条
中文羊驼大模型相关项目
中文羊驼大模型一期项目(Chinese-LLaMA-Alpaca)
-
https://github.com/ymcui/Chinese-LLaMA-Alpaca
中文羊驼大模型二期项目(Chinese-LLaMA-Alpaca-2)
-
https://github.com/ymcui/Chinese-LLaMA-Alpaca-2
中文Mixtral大模型项目(Chinese-Mixtral)
-
https://github.com/ymcui/Chinese-Mixtral















 1751
1751

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









