









目录
在前面的文章中,我们尝试了通过 Ollama/LM Studio 来集成本地大型语言模型(LLM)。
在本文中,我们将深入探讨如何在纯.NET环境中集成和运行这些强大的模型,而无需依赖任何外部服务。
微软最近发布的Phi-3 Mini模型的ONNX版本,为.NET开发者打开了新的大门。这个版本不仅支持多种硬件平台,还为在.NET环境下本地运行LLM提供了实际的可能性。这意味着开发者现在可以在他们自己的系统中直接运行和集成LLM,享受到更快的响应速度和更高的数据隐私保护。
Demo
为了演示这一过程,我们首先创建一个新的控制台应用程序,并安装必要的NuGet包。
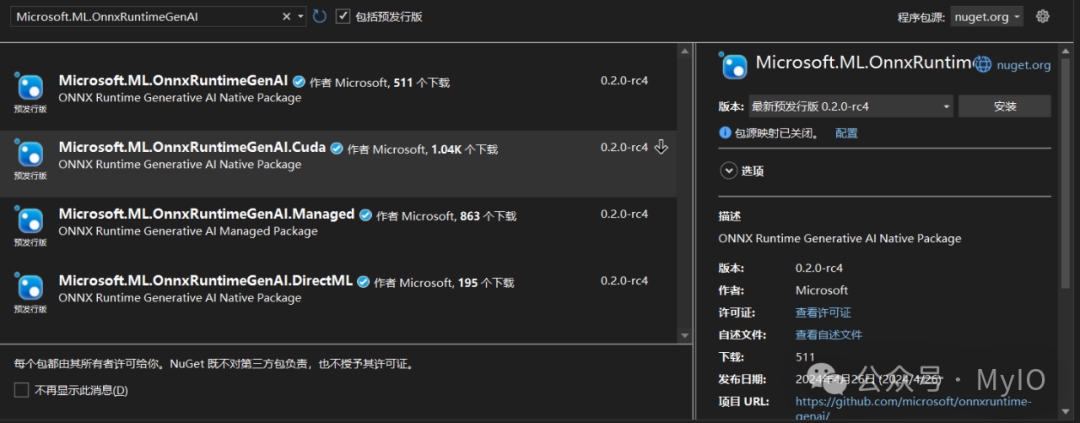
Microsoft.ML.OnnxRuntimeGenAI 包允许我们的应用程序利用ONNX运行时库调用ONNX模型,这是一个高效的运行时库,支持从CPU到GPU等多种硬件平台。
接下来,我们可以到https://huggingface.co/microsoft/Phi-3-mini-4k-instruct-onnx下载Phi-3 Mini的ONNX模型
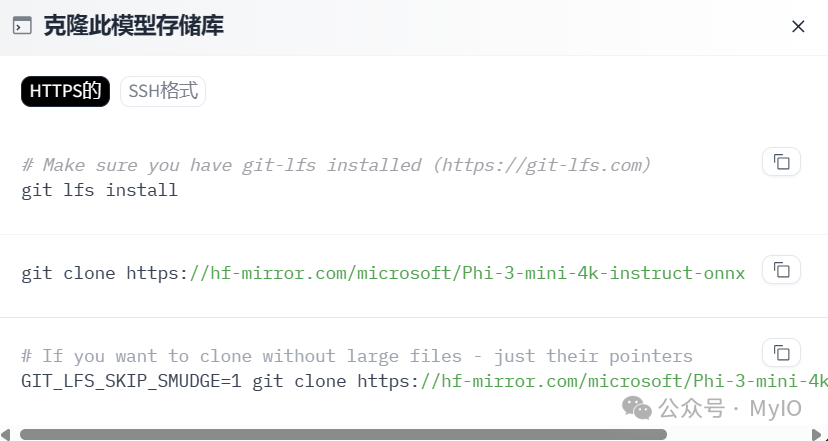
它提供了支持cpu_and_mobile、cuda或者directml的版本,你可以选择适合你硬件的模型版本。
接下来,我们就可以开始编码,代码示例展示了如何加载模型、处理输入问题、设置生成器参数,并最终生成模型的响应。
var modelPath = @"d:\Phi-3-mini-4k-instruct-onnx\cpu_and_mobile\cpu-int4-rtn-block-32";
var model = new Model(modelPath);
var tokenizer = new Tokenizer(model);
var input = "who are you?";
var prompt = $"<|user|>\n{input} <|end|>\n<|assistant|>\n";
var tokens = tokenizer.Encode(prompt);
var generatorParams = new GeneratorParams(model);
generatorParams.SetSearchOption("max_length", 2048);
generatorParams.SetInputSequences(tokens);
var generator = new Generator(model, generatorParams);
while (!generator.IsDone())
{
generator.ComputeLogits();
generator.GenerateNextToken();
var outputTokens = generator.GetSequence(0);
var newToken = outputTokens.Slice(outputTokens.Length - 1, 1);
var output = tokenizer.Decode(newToken);
Console.Write(output);
}
结论
通过使用Phi-3 Mini模型的ONNX版本,.NET开发者可以完全控制数据和模型的运行环境,这不仅减少了对外部服务的依赖,还大大降低了延迟,提高了响应速度。更重要的是,它为开发者提供了一个安全的环境,他们可以在其中运行和集成LLM,而不必担心数据隐私泄露的风险。















 36
36











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









