






目录
九、DeepSeek-R1 怎么达到和 OpenAI 的 o1 差不多的效果?
十、DeepSeek-R1 与其他推理模型的主要区别是什么?

一、DeepSeek 创始人是谁?
DeepSeek 的创始人是梁文锋,1985 年出生。他的职业生涯分为两个大的阶段,先做金融,再做 AI。
1、2015 年: 创立杭州幻方科技,专注于通过数学和 AI 进行量化投资 3、2023 年 5 月: 宣布进军通用人工智能 (AGI) 领域 3、2023 年 7 月: 成立大模型公司 DeepSeek,致力于前沿 AI 技术研发
梁文锋与其他 AI 模型的研究者不同,没有海外经历,毕业于浙江大学电子工程系人工智能方向。整个 DeepSeek 的研发团队也基本都是本土成员。
下面是梁文锋的一些访谈资料:
https://www.bilibili.com/video/BV1LQFQeFEAZ https://mp.weixin.qq.com/s/Cajwfve7f-z2Blk9lnD0hA
二、为什么 DeepSeek 能出圈?
1、DeepSeek R1 的效果从测试数据上看,和 o1 差不多,有的方面甚至超过了 o1 。
2、DeepSeek 的 R1 是开源的,而且还是最宽松的 MIT 协议。
3、在技术上有创新,而不只是 Follow 国外的技术。
4、因为创新,成本大幅降低,所以 API 的接口相比 OpenAI 也便宜得离谱。
5、最重要的,DeepSeek 是一家中国公司。
三、DeepSeek 的发展历程是什么样的?
1、2023 年 5 月,DeepSeek(深度求索)成立。
2、2023 年 11 月,DeepSeek Coder 发布,现在依然是开源代码模型的标杆。
3、2024 年 2 月,DeepSeek Math 发布,7B 模型逼近 GPT-4 的能力。
4、2024 年 3 月,DeepSeek VL 发布,作为自然语言到多模态的初探。
5、2024 年 5 月,DeepSeek V2 发布,成为全球最强开源通用 MoE 模型。
6、2024 年 6 月,DeepSeek Code V2 发布,成为最强开源代码模型。
7、2024 年 9 月,DeepSeek V2.5 发布,融合通用和代码能力的全新开源模型。
8、2024 年 11 月,DeepSeek R1 Lite 预览版上线,展现了公开的完整思考过程,没错,就是 OpenAI o1 藏着掖着的那个。
9、2024 年 12 月 10 日,DeepSeek V2.5-1210 发布,V2 模型收官,官网上线了联网搜索。
10、2024 年 12 月 26 日,DeepSeek V3 发布,性能接近顶级闭源模型,生成速度提升至 60 TPS,比 V2 快 3 倍。
11、2025 年 1 月 20 日,DeepSeek R1 发布,性能对标 OpenAI o1 ,同时发布了从 1.5B 到 70B 蒸馏的小模型。
12、2025 年 2 月 24 日到 2 月 28 日,DeepSeek 的开源周,连续开源了 FlashMLA、DeepEP、DeepGEMM、DualPipe、EPLP、3FS、Smallpond 。
四、推理模型和非推理模型是什么?
在 DeepSeek 发布的模型中 V3 和 R1 是被大家所熟知的。这两个模型正好代表了两种模型的类型,V3 是非推理模型,R1 是推理模型。
非推理模型:通过训练,自身拥有丰富的知识,能根据之前学到的知识直接给出答案,不需要复杂的思考过程,运行速度更快。例如:基于知识库的总结、翻译等场景。
推理模型:会逐步分析问题,考虑多种可能性,就像人做数学题一样,一步步推导,最后给出结果。使用 R1 时会显示思考的过程,其实光是看看这个思考过程也能学习到不少。DeepSeek 频繁出现服务器无响应,一个原因就是用户不管问什么问题都会勾选上深度思考,导致算力紧张。
DeepSeek 是因为发布 R1 后才开始爆火的,导致很多人以为 R1 能解决所有问题,这其实是不对的,比如在 RAG 场景下就不太适合,除非思考效率有显著提高。
五、DeepSeek-R1-Zero 是什么?
常规的模型开发中,强化学习(RL)加上监督微调(SFT)是首选方法。
但 DeepSeek 在 R1-Zero 模型上进行了创新尝试,以 V3 模型作为基础,进行纯强化学习,没有进行任何的监督微调。
采用组相对策略优化(GRPO)框架和基于规则的奖励系统(包括准确性奖励和格式奖励)。模型自然展现出自我验证、反思和生成长思维链等能力。
通过这种方式让模型自己生成推理能力,还出现了啊哈时刻,如下图:
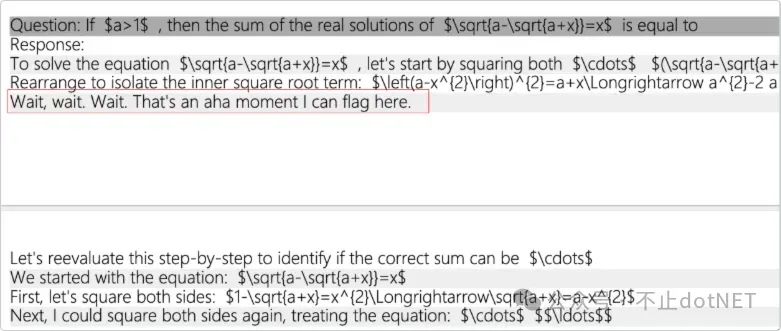
虽然 R1-Zero 具有很强的推理能力,但存在输出内容语言混杂、格式混乱等缺点,所以才会有后面的 R1 模型。
六、DeepSeek-R1 是什么?
DeepSeek-R1 是在 R1-Zero 基础上进一步发展的模型,结合少量冷启动数据和多阶段训练流程,解决了 R1-Zero 的可读性和语言混杂问题。
第一阶段:冷启动数据是 R1-Zero 生成的(数千条高质量的思维链 CoT 数据),使用这些数据对基础模型进行微调。
第二阶段:大规模强化学习,这个强化学习过程中保留了 R1-Zero 的准确性奖励和格式奖励,并且添加了一致性奖励来防止语言混乱。
第三阶段:进行了又一轮的监督微调(SFT)数据收集,这个数据分为两个部分:推理数据和非推理数据。
-
推理数据:在第二阶段训练强化学习的基础上生成了 60 万个思维链(CoT)示例数据
-
非推理数据:使用 V3 基础模型生成了 20 万个通用知识的示例数据
使用这 80 万的数据以 V3 为基础进行微调。
第四阶段:额外的强化学习训练,考虑来自所有场景的提示,最终得到了 R1 。
这种多阶段流程解决了 R1-Zero 的可读性和语言混杂问题,同时进一步提升了推理性能,使 DeepSeek-R1 达到与 OpenAI-o1-1217 相当的水平。
七、R1 和 R1-Zero 是什么关系?
1、R1-Zero 是 DeepSeek 的初步实验模型,目的就是为了验证强化学习(RL)在推理任务中的潜力,并为进一步训练提供数据。
2、DeepSeek R1 是在 R1-Zero 的基础上通过多阶段训练优化得到的。
3、可以这么来理解,R1-Zero 是技术验证,而 R1 是面向实际应用的成熟产品。
八、可以本机安装的 R1 小模型怎么回事?
R1 的满血版本有 671B,个人电脑是没办法部署的,现在常说的在私有部署 DeepSeek R1 通常指的是 R1 的蒸馏小模型,一共有 6 个:
-
DeepSeek-R1-Distill-Qwen-1.5B
-
DeepSeek-R1-Distill-Qwen-7B
-
DeepSeek-R1-Distill-Llama-8B
-
DeepSeek-R1-Distill-Qwen-14B
-
DeepSeek-R1-Distill-Qwen-32B
-
DeepSeek-R1-Distill-Llama-70B
这六个模型分别对应 Qwen 和 Llama 的:
-
Qwen2.5-Math-1.5B
-
Qwen2.5-Math-7B
-
Llama-3.1-8B
-
Qwen2.5-14B
-
Qwen2.5-32B
-
Llama-3.3-70B-Instruct
上面第六点中提到,R1 训练的第三个阶段产生了 80 万的数据。这个数据以 V3 这种大模型为基础,进行微调和强化学习,最终得到了 R1 。
以这 80 万数据放到 Qwen 和 Llama 的小模型上面进行指令微调,就得到了最后的蒸馏版本的 R1 。
R1 满血版和蒸馏版都是基于同样的 80 万数据,区别是一个是满血版使用的是 V3 模型为基础模型,蒸馏版使用的是 Qwen 和 Llama 作为基础模型。
九、DeepSeek-R1 怎么达到和 OpenAI 的 o1 差不多的效果?
首先,采用组相对策略优化(GRPO)强化学习框架,减少传统强化学习中的方差问题。
其次,实施多阶段训练流程,包括冷启动数据微调、强化学习、拒绝采样和再次微调。
第三,设计精细的基于规则的奖励系统,包括准确性奖励和格式奖励。
第四,优化测试时计算,允许模型生成长思维链解决复杂问题。
最后,DeepSeek-R1 基于混合专家架构(MoE),拥有 6710 亿参数,同时通过算法创新(如 MLA、DeepSeekMoE)和工程优化(如 FP8 精度训练)大幅提升了训练效率。这种方法使 R1 在数学、代码和推理任务上表现出与 o1 相当的能力。
十、DeepSeek-R1 与其他推理模型的主要区别是什么?
DeepSeek-R1 与其他推理模型的主要区别在于训练方法和开放程度。
在训练方法上,R1 创新性地将强化学习直接应用于基础模型,无需大量监督数据,并通过多阶段训练流程解决了纯强化学习模型的缺陷。
在性能上,R1 达到了与 OpenAI-o1 相当的水平,但训练成本仅为后者的约 6%。
在开放程度上,R1 使用了最宽松的 MIT 开源协议,同时详细公开了训练方法和技术细节,而 OpenAI 对 o1 的算法和训练方式保密。
此外,DeepSeek 通过蒸馏技术开源了多个小型模型,使普通用户和小型企业也能使用高性能推理模型,打破了 AI 技术的垄断,降低了行业门槛。
十一、DeepSeek-R1 对 AI 行业有什么影响?
DeepSeek-R1 作为 2025 年 AI 领域的重要突破,通过技术创新重塑了产业格局并带来深远社会影响。
技术革新:DeepSeek-R1 采用混合专家模型 (MoE) 和多投潜注意力 (MLA) 算法,显著提升推理效率,使训练成本仅为 GPT-4 的 1/70,推理成本降至 1/256。它突破了传统 Scaling Law 瓶颈,通过算法优化和训练方式改进,在有限算力条件下持续提升性能。虽然当前以文本处理为主,但结合知识蒸馏技术,其能力可以迁移至轻量化模型,推动端侧 AI 设备发展。
产业重构:低成本高性能的特点使 DeepSeek-R1 在金融、医疗、法律等垂直领域快速渗透。它带动了国产大模型生态崛起,部分模型已超越国际竞品。其 API 定价仅为 OpenAI 的 1/30,大幅降低使用门槛,推动"算力平权"。同时,端侧 AI 部署需求增长激活了国产芯片及 AI 硬件的研发。
社会影响:就业结构方面,AI 接管重复性工作,催生"超级个体",但也可能加剧就业极化。伦理治理方面,AI 决策介入引发权力失衡风险,数据垄断可能形成"模型封建制"。
未来趋势:技术上,多模态能力和训练方法将持续优化;应用上,AI Agent 将普及并深化人机协作;政策上,可能通过 AI 税调节技术红利分配,加大基础设施投入。
DeepSeek-R1 标志着 AI 进入"成本驱动普及、垂直应用爆发"新阶段。未来 AI 竞争不仅在技术性能上,更在于实现技术普惠、人机共生与社会包容性发展。
这一段的内容由 DeepSeek 生成。
十二、DeepSeek 开源周都开了些什么?
2025 年 2 月 24 日到 2 月 28 日是 DeepSeek 的开源周,连续开源了 FlashMLA、DeepEP、DeepGEMM、DualPipe、EPLP、3FS、Smallpond 。
这些开源项目都不是针对普通用户的,但对于研究大模型的公司来说,无疑都是非常厉害的工具。DeepSeek 的 Github 主页地址是:https://github.com/deepseek-ai 。下面分别说说每一个开源项目。
FlashMLA:一款面向 Hopper GPU 的高效 MLA 解码内核,并针对可变长度序列的服务场景进行了优化。
就像给家里的水管装了个智能水龙头,能根据盆的大小自动调节水流。它专门帮电脑的显卡(GPU)省电省水(显存),将资源利用到极致。
https://github.com/deepseek-ai/FlashMLA
DeepEP:第一个用于 MoE 模型训练和推理的开源 EP 通信库。
MoE 是混合专家模型,不同的专家之间是需要进行通信的,专家发言后,其他专家接收后还需要理解然后再发言讨论,效率很低。
DeepEP 就是解决这个问题的,可以让每个专家立即理解其他所有专家想要表达的观点,没有延迟。
https://github.com/deepseek-ai/DeepEP
DeepGEMM:DeepGEMM 是一个为 DeepSeek-V3 专门设计的,用于 FP8 的,通用矩阵乘法(GEMM)库。还支持普通的和专家混合(Mix-of-Experts,MoE)分组 GEMM。
简单理解就是给矩阵计算做加速,就像本来需要算盘来算每一道题,现在直接用电脑了。
https://github.com/deepseek-ai/DeepGEMM
DualPipe 和 EPLP:DualPipe 是一种用于 V3/R1 训练中计算-通信重叠的双向管道并行算法。EPLP 是 V3/R1 的专家级并行负载均衡器。
简单理解就是 DualPipe 打开了多通道进行计算,EPLP 负责调度让这些通道都不闲着,从而提升效率。
https://github.com/deepseek-ai/DualPipe
https://github.com/deepseek-ai/eplb
3FS:所有 DeepSeek 数据访问的推进器,一种并行文件系统,利用现代 SSD 和 RDMA 网络的全部带宽。
相当于给电脑建了个超大智能仓库。比如要存几百万本书的内容,它能瞬间找到任何一本书的某一页,还能让 100 台电脑同时存取数据且不会出现混乱。
https://github.com/deepseek-ai/3FS
Smallpond:基于 3FS 的数据处理框架。能从海量数据(PB 级)中快速找到想要的数据。
https://github.com/deepseek-ai/smallpond

















 1938
1938

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









