







目录
前言
今天学习反向传播再激活层、Affine层的实现。
一、布尔值的理解
先看一个例子:
import numpy as np
a = np.array([[1, 2, -3], [2, 3, 4]])
c = (a<=0)
b = a.copy()
b[c] = 0
print(b)
print(c)结果:
[[1 2 0]
[2 3 4]]
[[False False True]
[False False False]]分析:
(1)c = (a<=0) 表示如果a的值有<=0的存在,就是true,否则是false。此时c为布尔值组成的矩阵
(2)b = a.copy() 表示b = a
(3)b[c] = 0 表示如果c矩阵中有true,则b矩阵的对应位置输出为0,否则输出为b矩阵的原值。
二、激活函数层的实现
1.ReLU层
如果正向传播时的输入x大于0,则反向传播会将上游的值原封不动地传给下游。反过来,如果正向传播时的x小于等于0,则反向传播中传给下游的信号将停留在此处。具体如下图所示:
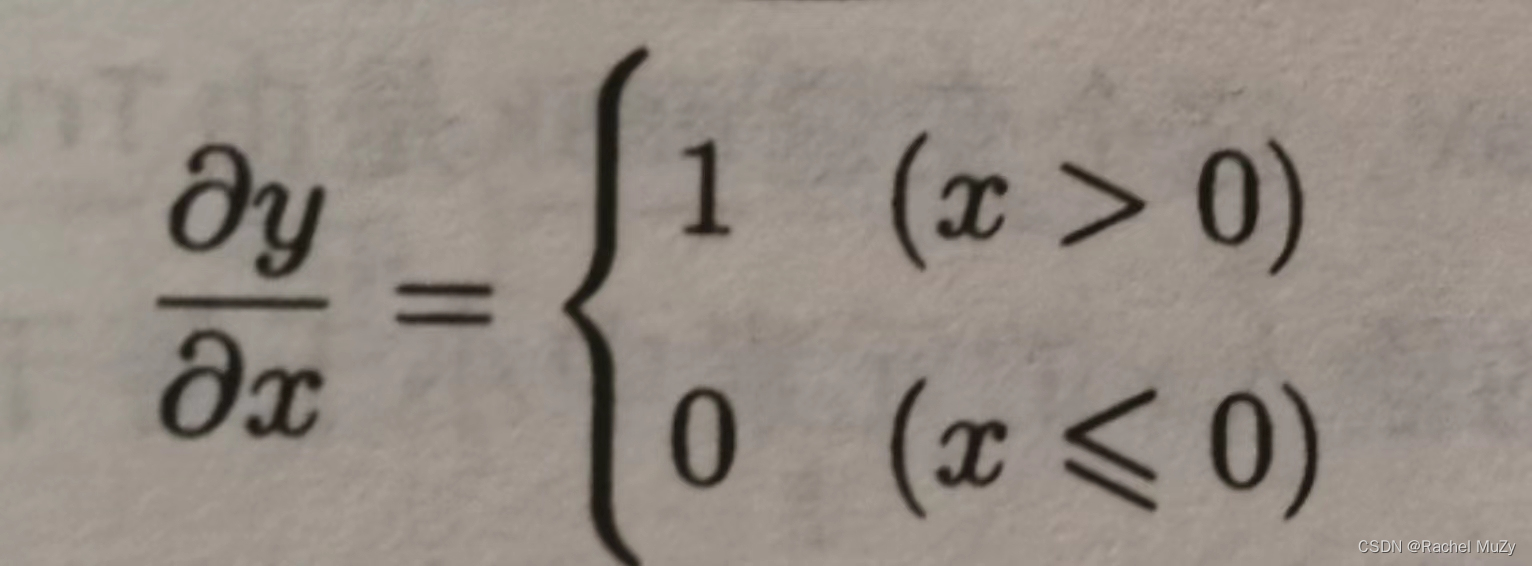
代码:
import numpy as np
class ReLU():
def __init__(self):
self.mask = None
def forward(self, x):
self.mask = (x <= 0)
out = x.copy()
out[self.mask] = 0
return out
def backward(self, dout):
dout[self.mask] = 0
dx = dout
return dx运行示例:
[[1. 0.]
[0. 3.]]自己写的代码:
import numpy as np
class ReLU():
def __init__(self):
self.mask = None
def forward(self, x):
buer_k = []
for i in x:
for k in i:
if k <= 0:
k = 0
buer_k.append(k)
buer_k = np.array(buer_k)
out = buer_k.reshape((2,2))
return out
def backward(self, dout):
dout[self.mask] = 0
dx = dout
return dx
a = np.array([[1.0, -0.5], [-2.0, 3.0]])
relu = ReLU()
out = relu.forward(a)
print(out)输出结果:
[[1. 0.]
[0. 3.]]这样不好,因为需要提前知道输入a的维度。
2.Sigmoid层
sigmoid函数的反向传播:
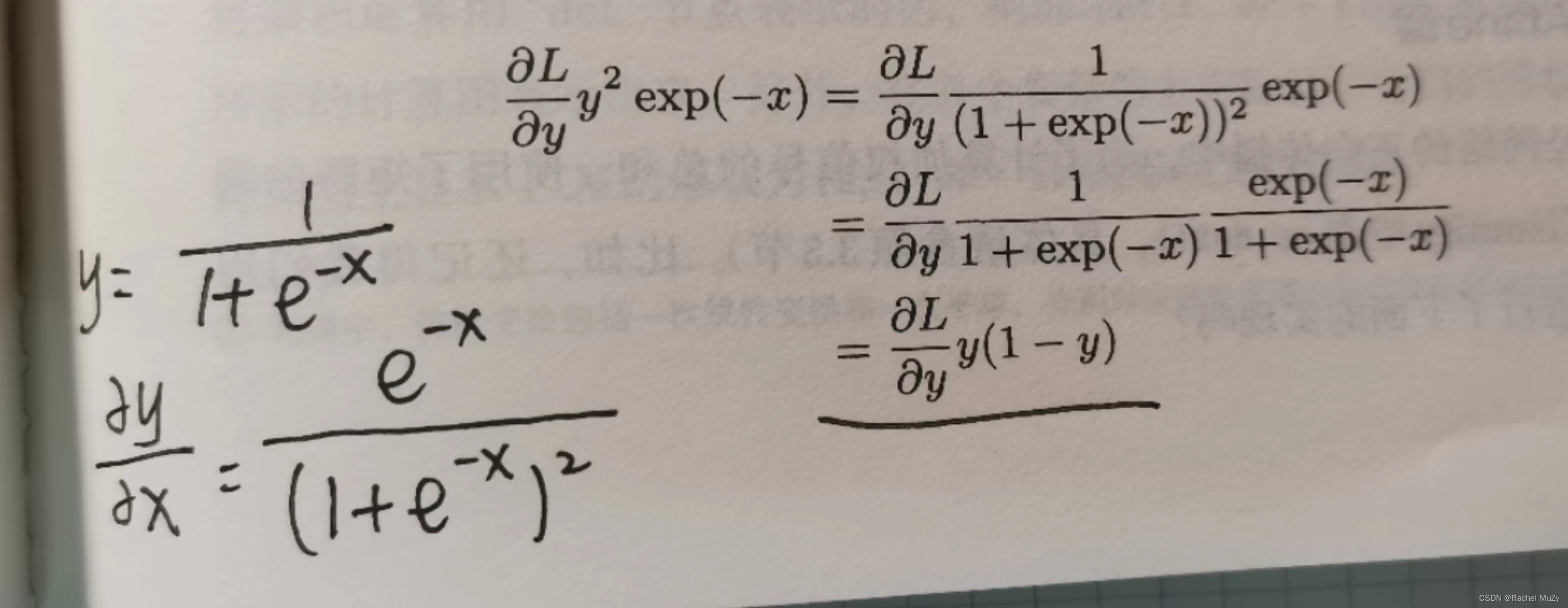
L表示损失函数。损失函数的输入是y(神经网络的输出),t(监督数据)。神经网络的梯度是 L 对 W (权重)的偏导,Y = np.dot(X, W) + B,Y再经过激活函数后的值,才是损失函数的输入y。因此想要反向传播,要先求激活函数的导。而上图中的x指的是np.dot(X, W) + B,并不是最原始的输入数据。
代码实现:
import numpy as np
class Sigmoid():
def __init__(self):
self.out = None
def forward(self, x):
out = 1 / (1 + np.exp(-x))
self.out = out
return out
def backward(self, dout):
dx = dout * self.out * (1 - self.out)
#并不理解dout表示的是什么,是损失函数对输出的偏导吗?但是此处用dout,是对输出求导。感到非常迷惑
return dx
此处需要一个具体的例子让我理解,但是书上并没由给出。
此处存疑。。。。。。。。。。。。。。。。。。。。。。。。。。。
三、Affine/Softmax层的实现
1. Affine层
前面对激活函数进行了求导,现在该对np.dot(X, W) + B进行求偏导了。
神经网络的正向传播中进行的矩阵的乘积运算称为“仿射变换”,将这种处理实现为“Affine层”:
Y = np.dot(X, W) + B
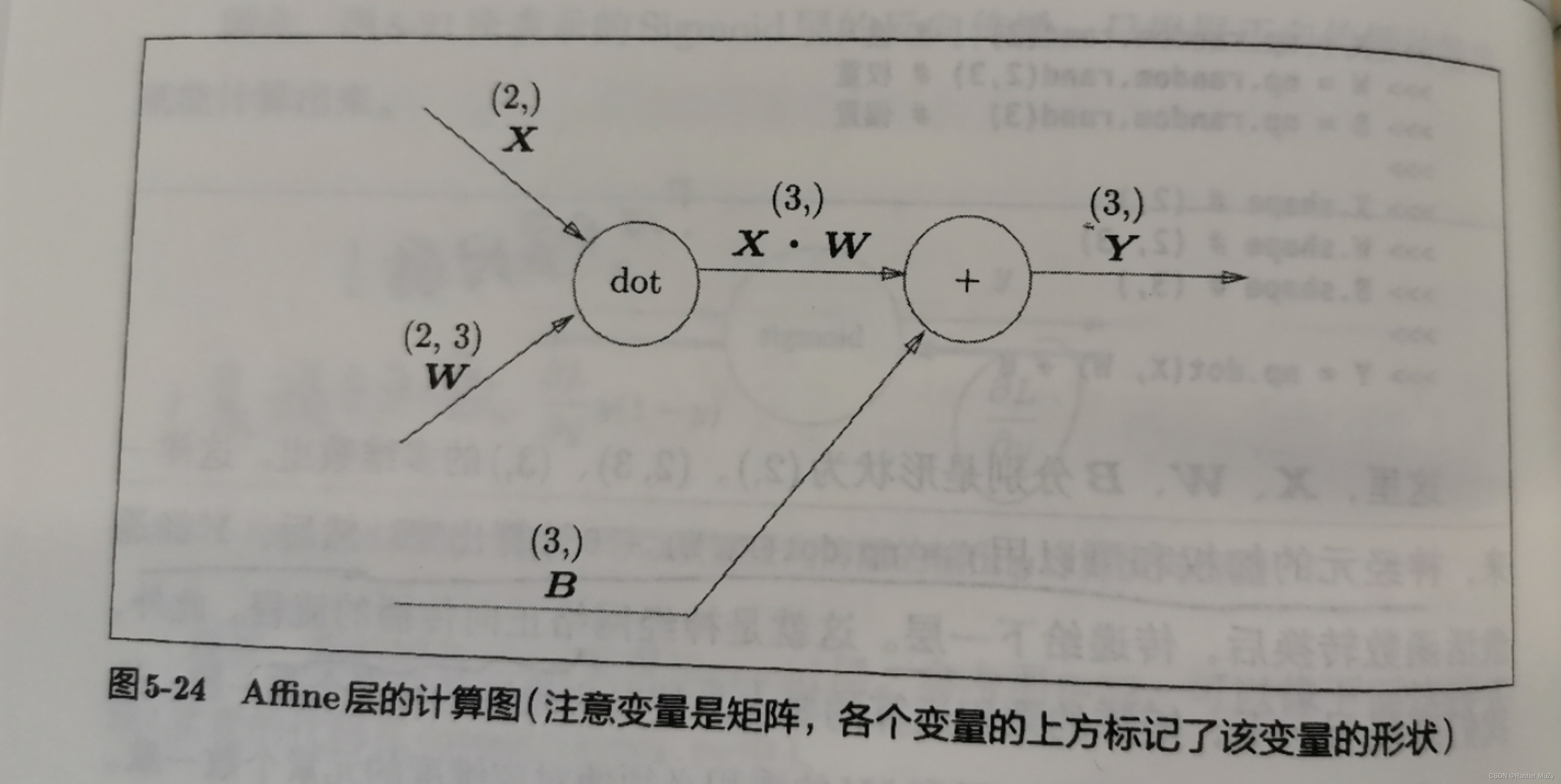
注意节点间传播的是矩阵。
现在考虑反向传播:
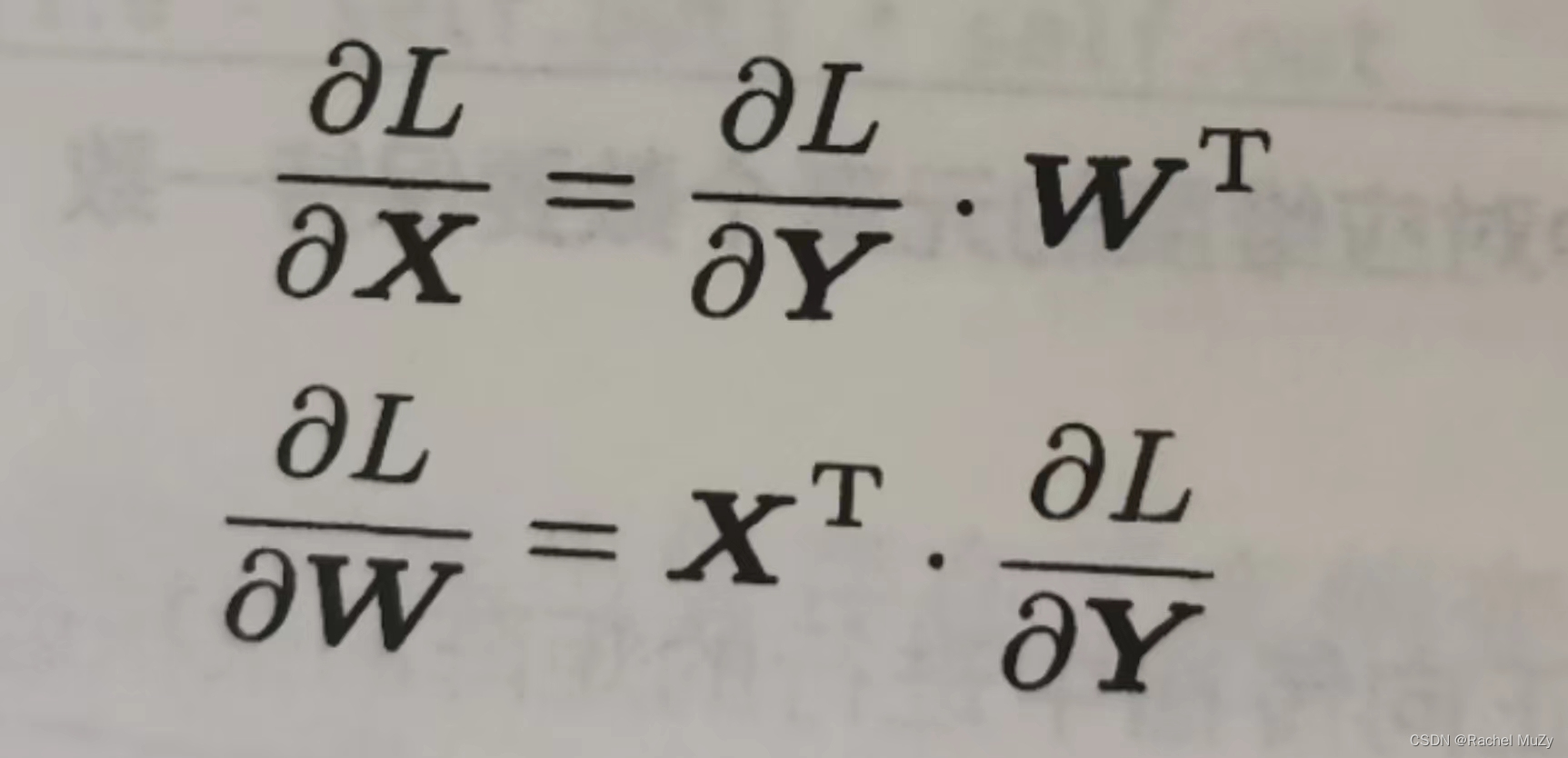
具体求导原则详见链接:
https://zhuanlan.zhihu.com/p/349469914![]() https://zhuanlan.zhihu.com/p/349469914 前面介绍的Affine层的输入 X 是以单个数据为对象的,现在我们考虑N个数据一起进行正反向传播的情况,即批版本的Affine层。
https://zhuanlan.zhihu.com/p/349469914 前面介绍的Affine层的输入 X 是以单个数据为对象的,现在我们考虑N个数据一起进行正反向传播的情况,即批版本的Affine层。
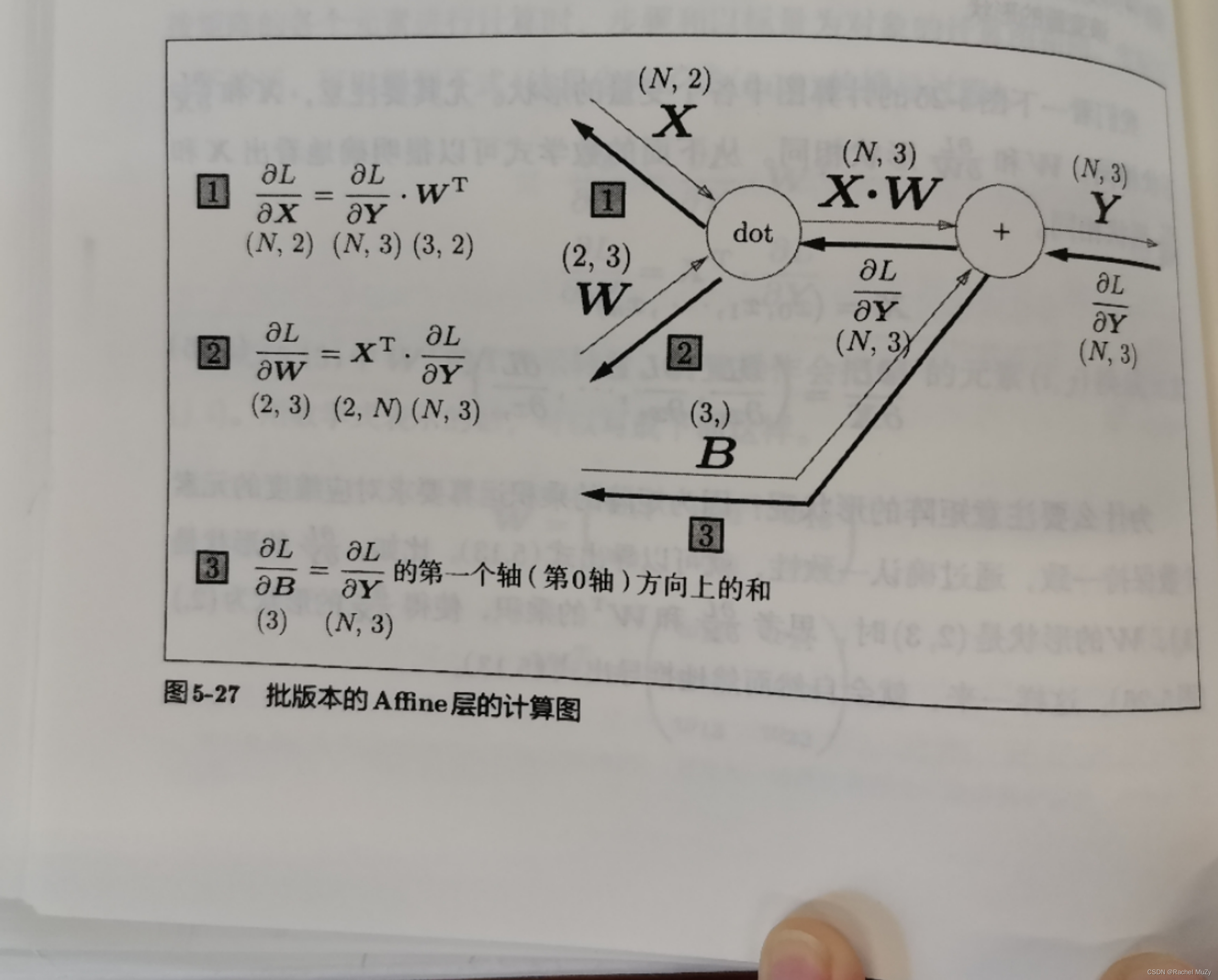
如上图所示,正向传播时,偏置会被加到每一个数据上。反向传播时,各个数据的反向传播值需要汇总为偏置的元素,示例如下:
import numpy as np
#forward
X_DOT_W = np.array([[0, 0, 0], [10, 10, 10]])
B = np.array([1, 2, 3])
Y1 = X_DOT_W + B
print(Y1)
#backward
dY = np.array([[1, 2, 3], [4, 5, 6]])
dB = np.sum(dY, axis = 0)
print(f'dB value is {dB}')结果:
[[ 1 2 3]
[11 12 13]]
dB value is [5 7 9]注意:反向传播要将Y的导数按列求和。
综上所述,Affine的实现如下代码所示:
import numpy as np
class Affine:
def __init__(self, W, b):
self.W = W
self.b = b
self.X = None
self.dW = None
self.db = None
def forward(self, x):
self.x = x
out = np.dot(x, self.W) + self.b
return out
def backward(self, dout):
#dout默认的是L对Y的求导
dx = np.dot(dout, self.W.T)
self.dW = np.dot(self.W.T, dout)
self.db = np.sum(dout, axis = 0)总结
反向传播不是很能理解,不明白其具体应用是什么?为什么在写反向传播时前面一定要有正向传播?已经有正向传播了,为什么还需要反向?矩阵求偏导的机理是什么?以上问题都需要进一步的思考。
















 2309
2309











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











