







在统计学的分析中有描述性统计分析和推断性统计分析,二者都是数据挖掘的重要分析方法,但却有着不同之处。
一、描述性统计分析
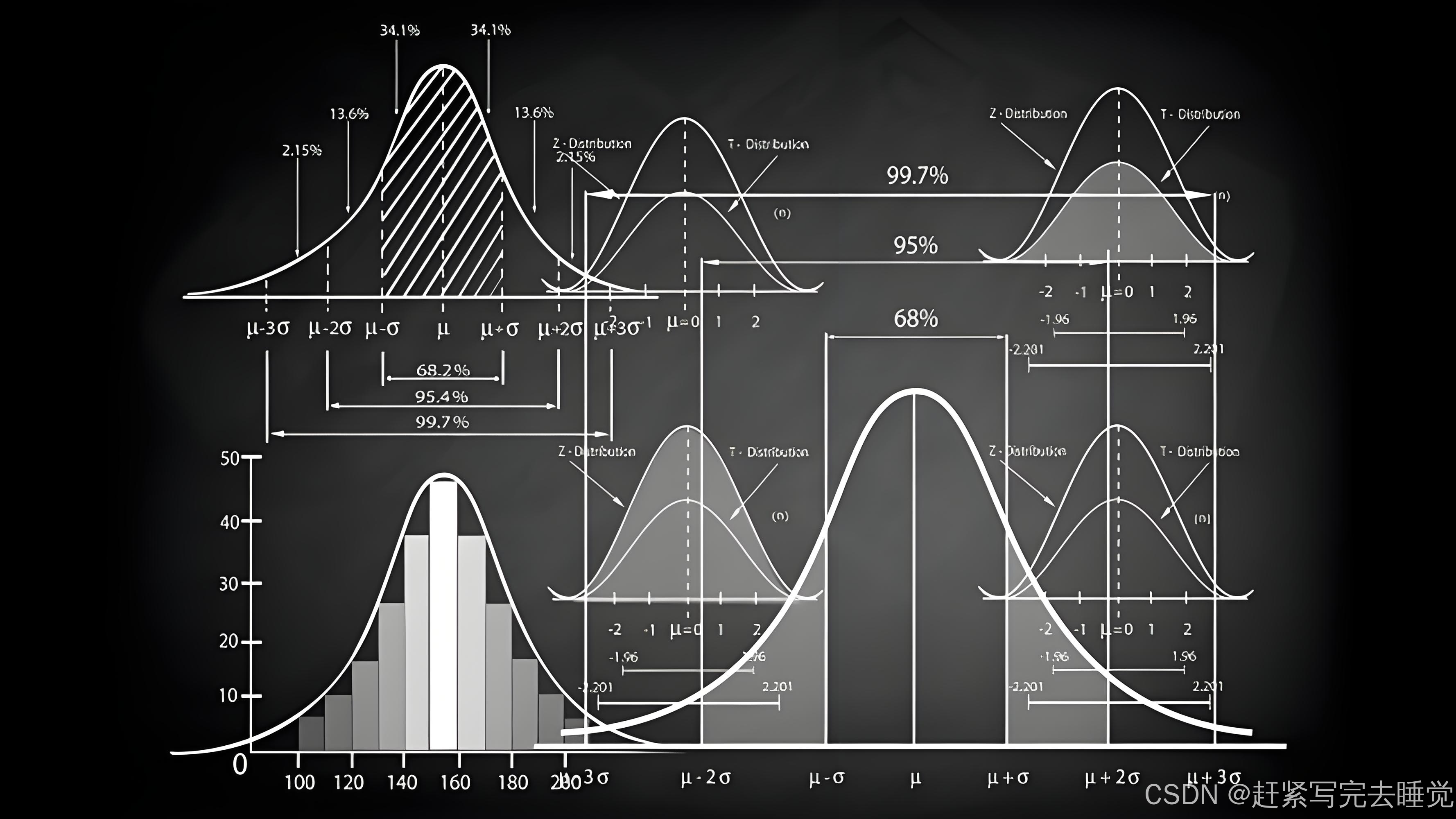
目的:描述性统计分析的核心目的就是对已经收集到的样本数据进行全方位的 “刻画”,将数据的各种特征清晰地呈现出来。它就像是给数据画一幅详细的画像,让我们能直观地知晓这些数据具体是什么样子的。例如,我们可以通过计算均值来了解数据的平均水平,用中位数知晓处于中间位置的数据情况,以众数确定出现频率最高的数据值,这些都体现了数据的集中趋势。同时,借助方差、标准差、极差等指标,能展现数据的离散程度,也就是数据的分散或集中状况。此外,像偏态、峰态这些概念还能帮助我们描述数据的分布形态,是对称的正态分布,还是有偏态、峰态变化的其他分布情况等。
方法:描述性统计分析主要运用两大利器 —— 统计量和可视化工具。在统计量方面,如前文所述,会计算像反映集中趋势的均值、中位数、众数,衡量离散程度的方差、标准差、极差,以及描述分布形态的偏态、峰态系数等众多指标。而在可视化工具上,常用的有直方图,通过不同区间的条形高度来展示数据在各区间的频数分布,让人一眼就能看出数据集中在哪些区间;箱线图可以清晰呈现数据的中位数、四分位数以及异常值情况,帮助我们快速判断数据的离散程度和是否存在偏态;茎叶图则在展示数据分布的同时还能保留原始数据的部分信息,尤其适用于小样本数据的展示与分析。例如,统计某产品不同批次的质量检测数据,我们可以计算各批次数据的均值、标准差,并绘制直方图来查看质量数据在各个区间的分布情况,整个过程都是围绕着对现有样本数据的整理和展示。
二、推断性统计分析
目的:推断性统计分析则有着更为宏大的 “目标”,它主要是依据所抽取的样本数据,去对总体的相关情况进行合理的推测和估计。毕竟在很多实际场景中,我们很难获取到总体的全部数据,这时就需要通过部分样本数据这个 “窗口”,去推断总体的特征,像是总体的均值大概是多少、总体的比例情况如何,或者判断总体的分布形态是否符合某种假设等。例如,想要了解某大型城市全体居民的平均收入水平,不可能去统计每一位居民的收入,那就可以抽取一定数量、具有代表性的居民样本,通过推断性统计分析来估计出整个城市居民的总体收入水平以及收入的分布特点等,其结论是要推广到总体层面的一种判断。
方法:推断性统计分析有着一套严谨的 “流程”。首先要设立假设,包括原假设和备择假设,比如原假设设为总体均值等于某个特定值,备择假设就是总体均值不等于该值这种相互对立的情况。接着,根据抽取的样本数据去计算相应的检验统计量,像在总体方差已知的情况下可能会用到 z 统计量,总体方差未知时常用 t 统计量等,不同的场景会选用不同的合适统计量。然后,要结合特定的概率分布,例如 t 分布、正态分布等来确定拒绝域或者计算 p 值。最后依据拒绝域或者 p 值的大小来决定是接受原假设还是拒绝原假设,从而完成对总体情况的推断。例如,要验证某工厂生产的产品总体合格率是否达到了 90%,就先提出相应假设,抽取产品样本后按照上述流程进行分析,进而得出关于总体合格率的推断结论。

















 8506
8506

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









