







💫《博主介绍》:✨又是一天没白过,我是奈斯,从事IT领域✨
💫《擅长领域》:✌️擅长阿里云AnalyticDB for MySQL(分布式数据仓库)、Oracle、MySQL、Linux、prometheus监控;并对SQLserver、NoSQL(MongoDB)有了解✌️
💖💖💖大佬们都喜欢静静的看文章,并且也会默默的点赞收藏加关注💖💖💖

前两天在群聊中交流技术,大家聊着聊着就聊到了一条SQL语句在Oracle中的执行流程,四个人聊出了3种执行流程😅,自己也想发言一下居然有些忘记了,看来理论知识还是时不时需要看一看的。自己就在官方文档手册找了找相关知识点,Oracle的官方文档手册很庞大,接近上万页了,花了30分钟终于算是找到了这个知识点了。对于《一条 SQL 语句的执行流程》这个知识点其实也是很重要的,之前面试的时候也被问到过,并且还有一点非常非常重要,只有清楚一条SQL语句都经过了哪些流程都干了什么,才能更好的优化SQL语句,让SQL更高效的执行。那么这篇文章就结合最权威的官方文档手册详细介绍一下《一条 SQL 语句的执行流程》。
特别说明💥:本篇文章部分知识点均来源于 Oracle 公开可查的官方文档手册,并结合了我个人的理解和案例演示。如有冲突,请联系,会立即处理。转载请标明出处😄
官方文档对于SQL语句执行流程和优化器的介绍(Oracle 12c):

目录
步骤四:行源生成器阶段(对SQL语句进行解析(prase),利用内部算法对SQL进行解析,生成解析树(parse tree)及执行计划(execution plan)
步骤五:执行阶段(执行SQL语句,返回结果execute and return)
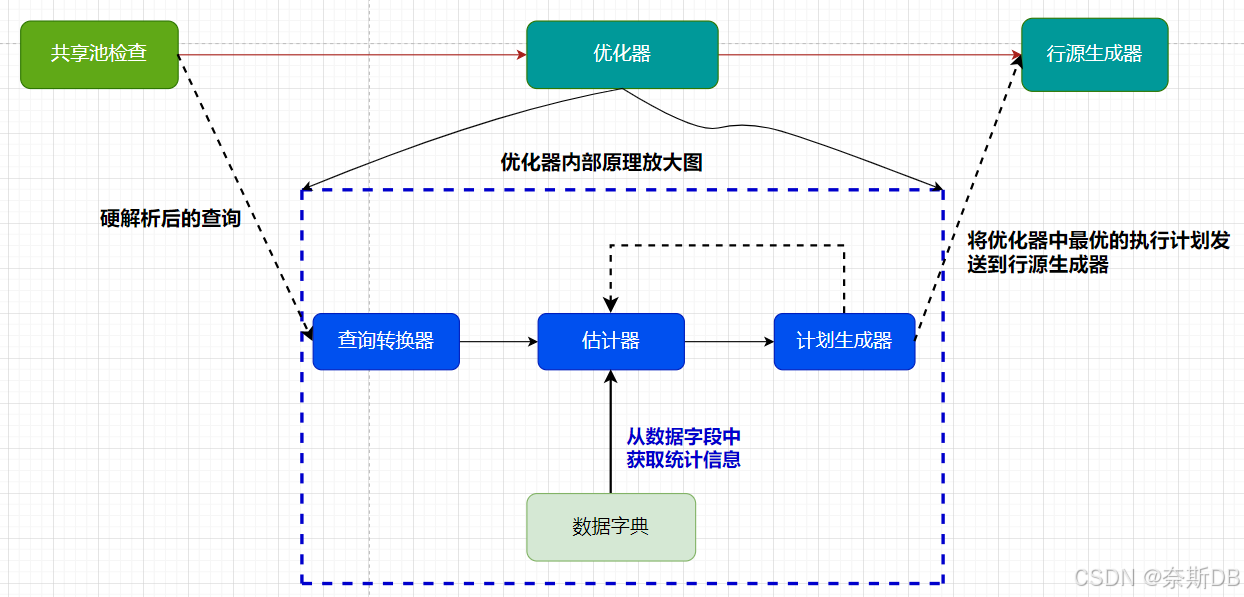
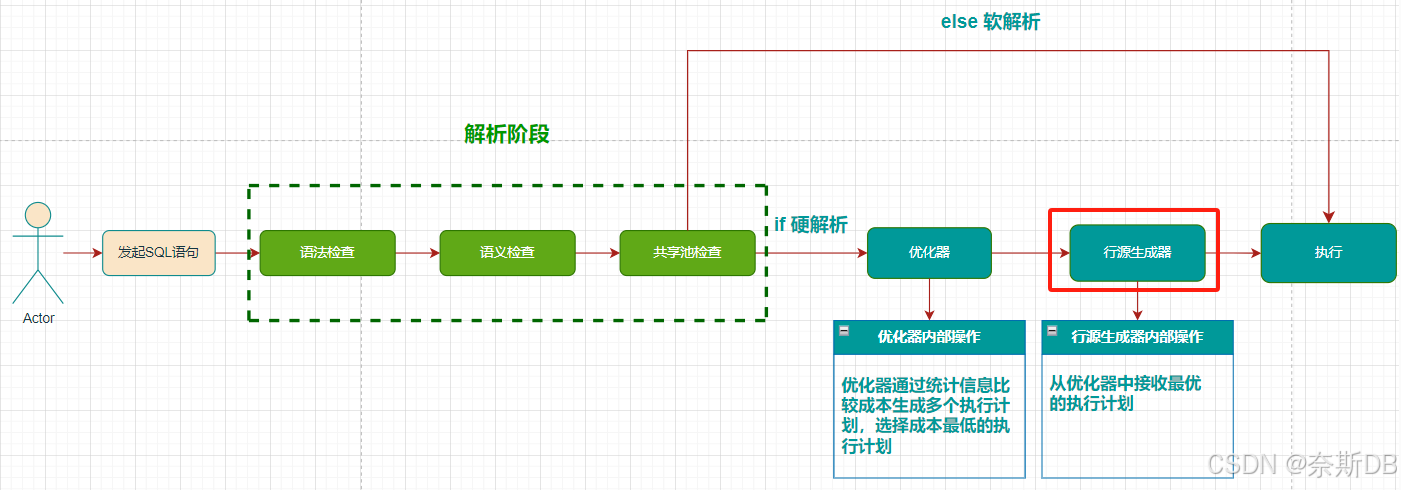
在Oracle数据库中执行一条SQL是有一套执行标准的,先干什么后干什么都被安排的明明白白,下图是博主手绘了一张《一条 SQL 语句的执行流程》的流程图。
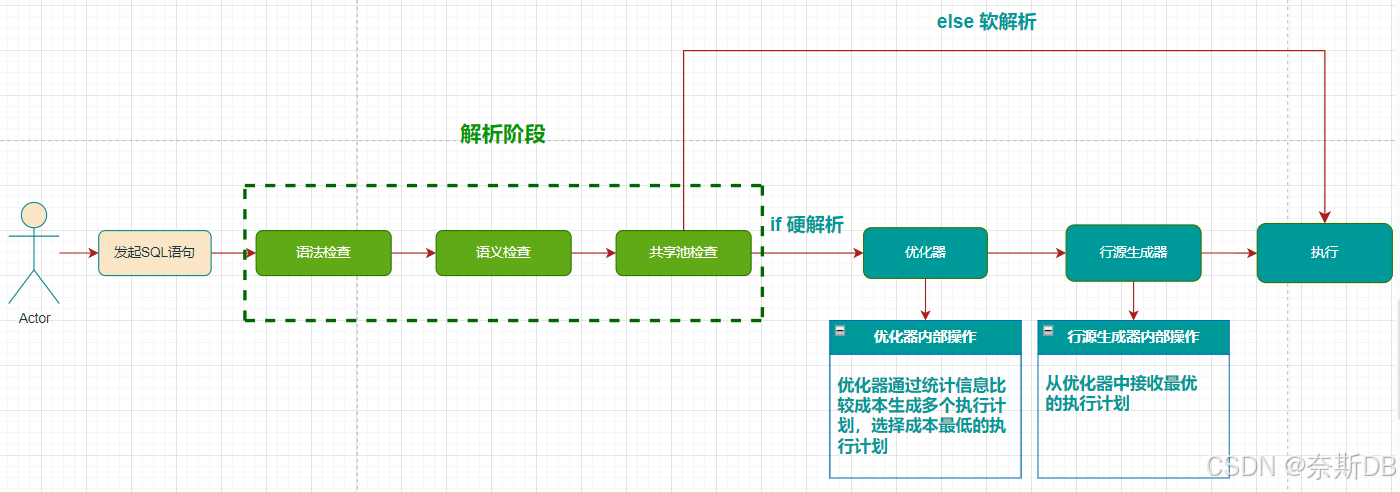
流程图显示了SQL处理的各个阶段,总共可以分成5个阶段:发起SQL语句阶段,解析阶段,优化器阶段、行源生成器阶段,以及最后的执行阶段。
- SQL语句阶段:客户端发起SQL语句。
- 解析阶段:包含了语法检查,语义检查,共享池检查三种检查。
- 优化器阶段:优化器通过统计信息比较成本生成多个执行计划,选择成本最低的执行计划。
- 行源生成器阶段:从优化器中接收最优的执行计划。
- 执行阶段:根据SQL返回结果。
步骤一:SQL语句阶段
这个阶段很好理解,一句话总结就是客户端或者程序端发起需要执行SQL语句。
步骤二:解析阶段
解析阶段涉及将 SQL 语句的各个部分分离成一个数据结构,以便其他程序可以处理。当应用程序指示时,数据库会解析一个语句,这意味着只有应用程序,而不是数据库本身,才能减少解析次数。
当应用程序发出 SQL 语句时,它会向数据库发起解析调用,以准备执行该语句。解析调用会打开或创建一个游标,游标是指向会话特定的私有 SQL 区域的句柄,该区域保存已解析的 SQL 语句和其他处理信息。游标和私有 SQL 区域位于程序全局区(PGA)中。
在解析调用期间,数据库会执行检查,以识别在语句执行之前可以发现的错误。有些错误无法通过解析捕捉到。例如,数据库可能在语句执行过程中遇到死锁或数据转换错误。
解析阶段之第一步:语法检查
检查每个 SQL 语句的语法有效性。任何违反 SQL 语法规则的语句都会失败。就比如说以下语句会失败,因为关键字 FROM 拼写成了 FORM:
SQL> select * form liu_oracleoltp_ywcs_table1; select * form liu_oracleoltp_ywcs_table1 * ERROR at line 1: ORA-00923: FROM keyword not found where expected
解析阶段之第二步:语义检查
语句的语义是指其含义。语义检查用于确定语句是否有意义,例如,检查语句中的对象和列是否存在。语法正确的语句可能会在语义检查中失败,例如,下面的查询尝试 查询一个不存在的表 :
SQL> select * from liu_oracleoltp_ywcs_table1; select * from liu_oracleoltp_ywcs_table1 * ERROR at line 1: ORA-00942: table or view does not exist
解析阶段之第三步:共享池检查(只针对DML语句。对于DDL永远都是硬解析)
在解析过程中,数据库执行共享池检查,以确定是否可以跳过语句处理的资源密集型步骤。为此,数据库使用哈希算法为每个SQL语句生成一个哈希值。语句哈希值是SQL ID显示在V$SQL.SQL_ID。此哈希值在Oracle数据库版本中是确定的,因此单个实例或不同实例中的同一语句具有相同的SQL ID。
当用户提交SQL语句时,数据库会搜索共享SQL区域,查看现有的解析语句是否具有相同的哈希值。SQL语句的哈希值不同于以下值:
- 语句的内存地址:Oracle数据库使用SQL ID在查找表中执行键控读取。通过这种方式,数据库获得语句的可能内存地址。
- 语句执行计划的哈希值:SQL语句在共享池中可以有多个计划。通常,每个计划都有不同的哈希值。如果同一个SQL ID有多个计划哈希值,则数据库知道此SQL ID存在多个计划。
根据提交的语句类型和哈希检查的结果,解析操作分为以下几类:
- 硬解析:若Oracle数据库不能重用现有代码,则必须构建应用程序代码的新可执行版本。此操作称为硬解析或库缓存未命中。在硬解析过程中,数据库多次访问库缓存和数据字典缓存以检查数据字典。当数据库访问这些区域时,它会在所需对象上使用一种称为锁的序列化设备,这样它们的定义就不会改变。锁存争用增加了语句执行时间并降低了并发性。 也就是说如果在共享池的库缓存中找不到对应的执行计划,Oracle 就需要重新解析 SQL 并生成执行计划,这个过程被称为硬解析。注意:对于DDL操作而言总是硬解析。
- 软解析:软解析是指任何非硬解析的解析。如果提交的语句与共享池中的可重用SQL语句相同,则Oracle数据库将重用现有代码。这种代码重用也称为库缓存命中。软解析的工作量可能会有所不同。例如,配置会话共享SQL区域有时可以减少软解析中的锁存量,使其“更软”。一般来说,软解析比硬解析更可取,因为数据库跳过优化和行源代码生成步骤,直接执行。换句话说,如果 SQL 语句的执行计划已经存在于共享池的库缓存中,Oracle 就不需要重新解析该 SQL,而是可以直接从库缓存中获取之前生成的执行计划,那么直接跳过优化器和行源生成器阶段,直接到就到了最后的执行阶段哈,那么这种过程被称为软解析。
那么总结一下硬解析和软解析的区别:
特征 硬解析 (Hard Parse) 软解析 (Soft Parse) 发生时机 首次执行 SQL 或者 SQL 执行计划不在缓存中 SQL 执行计划已被缓存,复用已有执行计划 过程 解析、优化、生成执行计划,并缓存执行计划 直接复用缓存中的执行计划,不需要重新解析 性能开销 较大,因为需要重新解析、优化和生成执行计划 较小,因为不需要重新解析和生成执行计划 资源消耗 较高,涉及更多的 CPU 和内存消耗 较低,节省了 CPU 和内存 下图是一条update语句的共享池检查的简化表示。
此图显示了共享池检查。顶部是三个相互叠放的框,每个框都比后面的框小。最小的框显示哈希值,并标记为Shared SQL Area(共享SQL区域)。第二个框标记为Shared Pool(共享池),最外层标记为SGA。此框下方是另一个标记为PGA的框。PGA框内是一个标记有Private SQL Area的框,其中包含一个哈希值。一个双头箭头连接上下框,并标记为“Comparison of hash values(哈希值的比较)”。PGA框右侧是一个标记为“用户进程”的人图标。图标由双面箭头连接。用户进程图标上方是“Update ....”语句。箭头从下面的用户进程指向,因此下面的服务器进程图标。
为了开始这个处理Oacle必须在Shared pool中寻找语句,Shared pool是SGA中的一部分用来缓存以前执行过的sql语句、PLSQL、数据字典内容的缓存以及其他许多信息,以供会话重用。为了高效完成此操作,查找Shared pool中是否有相同的语句。检查此SQL是否被当前用户使用过,如果是就是软解析soft parse,如果否那就是硬解析。DDL总是硬解析,语句从不重用。

案例:了解共享检查池,模拟硬解析和软解析
硬解析案例
一、假设我们第一次执行以下 SQL 语句:
SQL> select * from LIU_ORACLEOLTP_YWCS_EMPLOYEES where last_name='Smith';执行过程:
- 如果这条 SQL 是第一次执行,并且数据库中没有缓存该 SQL 的执行计划,Oracle 会进行硬解析。
- 解析过程包括语法检查、语义检查、生成执行计划(可能是全表扫描、索引扫描等),并将生成的执行计划缓存到共享池(shared pool)中。
- 由于这是首次执行,因此 Oracle 需要对 SQL 语句进行完全的解析和优化,过程比较消耗资源。
二、通过查询
V$SQL视图来查看 SQL 的解析次数。以下 SQL 语句可以帮助你查看 SQL 的硬解析和软解析情况:SQL> SELECT sql_id, executions, parse_calls,sql_text FROM v$sql WHERE sql_text like 'select * from LIU_ORACLEOLTP_YWCS_EMPLOYEES where last_name%';parse_calls:表示 SQL 被解析的次数。
executions:表示 SQL 执行的次数。
如果 parse_calls 大于 executions,则说明存在硬解析。如果 parse_calls 等于 executions,则说明是软解析。
软解析案例
软解析是指 Oracle 在执行 SQL 时,如果该 SQL 已经有执行计划被缓存,Oracle 会直接复用已有的执行计划,而不需要重新解析和生成新的执行计划。软解析能够提高性能,因为它避免了重复的解析工作。
软解析的前提是 SQL 语句的文本与之前执行的 SQL 完全一致,并且执行计划被缓存。
一、第二次执行相关SQL语句:
SQL> select * from LIU_ORACLEOLTP_YWCS_EMPLOYEES where last_name='Smith';执行过程:
- 如果这条 SQL 语句已经执行过,且其执行计划已经被缓存,下一次执行相同的 SQL 时,Oracle 会跳过硬解析,直接从共享池(shared pool)中获取已缓存的执行计划并执行。这种方式就叫做软解析。
- 软解析意味着不需要重新生成执行计划,节省了 CPU 和内存资源,因此执行速度更快。
二、通过查询
V$SQL视图来查看 SQL 的解析次数。以下 SQL 语句可以帮助你查看 SQL 的硬解析和软解析情况:SQL> SELECT sql_id, executions, parse_calls,sql_text FROM v$sql WHERE sql_text like 'select * from LIU_ORACLEOLTP_YWCS_EMPLOYEES where last_name%';parse_calls:表示 SQL 被解析的次数。
executions:表示 SQL 执行的次数。
如果 parse_calls 大于 executions,则说明存在硬解析。如果 parse_calls 等于 executions,则说明是软解析。


步骤三:优化器阶段
那么下一步就到了优化器部分。在Oracle 数据库中必须对每个唯一的 DML 语句至少执行一次硬解析,并在此解析过程中执行优化。
需要注意哈,数据库不会对 DDL 进行优化。唯一的例外是当 DDL 包含需要优化的 DML 组件,例如子查询时。
优化器介绍:
在Oracle中,优化器(optimizer)是数据库中可谓最核心的部分,主要是因为 优化器用来负责解析SQL语句,因此优化器的性能直接决定SQL语句的执行效率 。想要做好SQL优化,就需要了解优化器,这是基础。optimizer优化器根据统计信息对每个sql语句执行最优的执行计划(执行计划受统计信息影响)。
优化器是内置的数据库软件,它确定SQL语句访问请求数据的最有效方法。优化器试图为SQL语句生成最佳的执行计划,并且在所有考虑的候选计划中选择成本最低的执行计划。优化器使用可用的统计信息来计算成本,对于给定环境中的特定查询,成本计算考虑了查询执行的因素,如I/O、CPU和通信。
例如,查询一张员工信息表时,可能会请求查询有关担任经理的员工的信息。如果优化器的统计数据表明80%的员工是经理,那么优化器可能会决定全表扫描是最有效的。然而,如果统计数据表明很少有员工是经理,那么读取索引并按rowid访问表可能比全表扫描更有效。
由于数据库有许多内部统计数据和工具可供使用,优化器通常比用户更能确定语句执行的最佳方法。因此,所有SQL语句都使用优化器。
优化器的主要任务是根据一定的判断原则,选择最优的执行路径(Access Path)来执行目标 SQL 查询。它的目标是生成高效的执行计划,以确保 SQL 查询在当前环境下的最佳性能 。优化器决定了 Oracle 如何访问数据,包括选择是进行全表扫描(Full Table Scans)、索引范围扫描(Index Range Scans),还是索引快速全扫描(Index Fast Full Scans)、索引跳跃扫描(Index Skip Scans)等访问路径。
对于多表关联查询,优化器还负责决定表与表之间采用何种连接方式。这些连接方式可能是哈希连接(Hash Join)、嵌套循环连接(Nested Loops),或者合并连接(Merge Join)。这些选择会直接影响 SQL 查询的执行效率。因此,优化器在 SQL 执行过程中扮演着至关重要的角色,它所生成的执行计划质量直接决定了 SQL 执行的性能。
① 优化器三大组件介绍:
优化器包含三个组件:查询转换器、估计器和计划生成器。手绘图如下:
此图描绘了一个解析后的查询进入到“查询转换器”。
然后将转换后的查询发送到“估计器”。从字典中检索统计数据,然后将查询和估计值发送到“计划生成器”。
“计划生成器”要么将计划返回给“估计器”,要么将执行计划发送给“行源生成器”。
组件
描述
Query Transformer
(查询转换器)
优化器确定更改查询的形式是否有帮助,以便优化器可以生成更好的执行计划。
Estimator
(估计器)
优化器根据数据字典中的统计数据估计每个计划的成本。
Plan Generator
(计划生成器)
优化器比较计划的成本,并选择成本最低的计划(称为执行计划)传递给行源生成器。
组件一:查询转换器
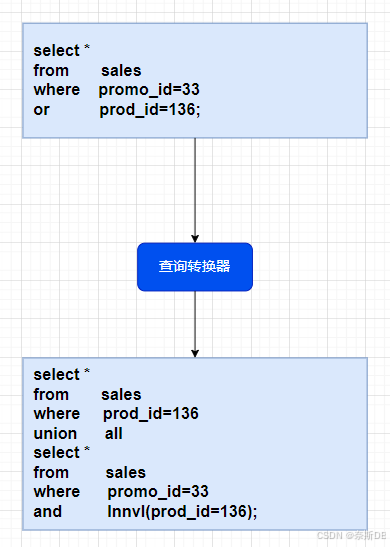
对于某些语句,查询转换器会确定将原始SQL语句重写为语义上等效的SQL语句是否有利,并且成本更低。
当存在可行的替代方案时,数据库会分别计算替代方案的成本,并选择成本最低的替代方案。下图显示了查询转换器将使用OR的输入查询重写为使用UNION ALL的输出查询。也就是说查询转换器觉得UNION ALL写法成本更低。
组件二:估计器
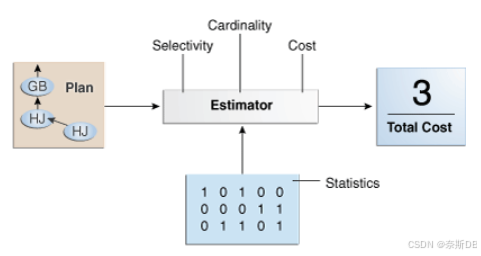
估计器是优化器的组成部分,它决定了给定执行计划的总成本。估算师使用三种不同的衡量标准来确定成本:
- 选择性(Selectivity):查询选择的行集中的行百分比,0表示没有行,1表示所有行。选择性与查询谓词相关联,例如WHERE last_name LIKE“a%”或谓词的组合。当选择性值接近0时,谓词变得更有选择性,当值接近1时,谓词的选择性降低(或更无选择性)。注意:选择性是一种内部计算,在执行计划中不可见。
- 基数(Cardinality):基数是执行计划中每个操作返回的行数。这种输入对于获得最优计划至关重要,是所有成本函数的共同点。估计器可以从DBMS_STATS收集的表统计信息中推导出基数,或者在考虑谓词(过滤、连接等)、DISTINCT或GROUP by操作等的影响后推导出基数。执行计划中的Rows列显示了估计的基数。
- 成本(Cost):此度量表示所使用的工作或资源单位。查询优化器使用磁盘I/O、CPU使用率和内存使用率作为工作单位。
如下图所示,如果统计信息可用,则估计器使用它们来计算度量值。统计信息提高了测量的准确性。该图中左侧的框标有Plan,箭头指向标有Estimator的框,有三个特点:选择性(Selectivity)、基数(Cardinality)和成本(Cost)。箭头指向右侧的一个框,内容为“Total Cost=3(总成本=3)”。Estimator框下方的框标有“Statistics(统计信息)”。该框填充有1和0。
组件三:计划生成器
计划生成器通过尝试不同的访问路径、连接方法和连接顺序来探索查询块的各种计划。许多计划都是可能的,因为数据库可以使用各种组合来产生相同的结果。优化器选择成本最低的计划。
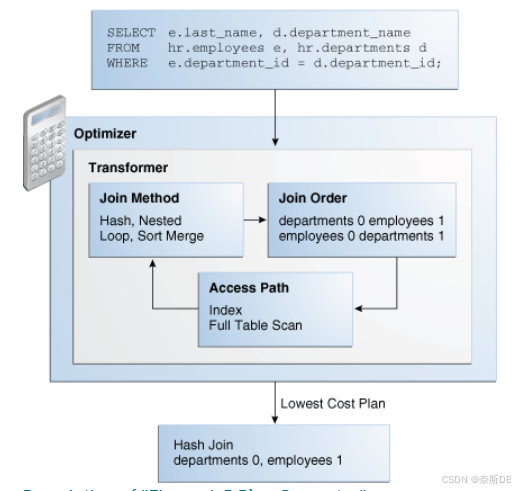
下图显示了优化器测试输入查询的不同计划。此框指向一个标记为“Optimizer(优化器)”的框。此框内有一个标有“Transformer(转换器)”的框,此框包含三个框:Join Method、Join Order、Access Path(连接方法、连接顺序、访问路径)。
- Join Method(连接方法)框包含“Hash、Nested Loop、Sort Merge(哈希、嵌套循环、排序合并)”。
- Join Order(连接顺序)框包含“departments 0 employees 1”和“employees 0 departments 1”。
- Access Path(访问路径)框包含“Index(索引)”和“Full Table Scan(全表扫描)”。
优化器框指向一个包含“Hash Join”和“departments 0 employees 1”的框。箭头标记为“Lowest Cost Plan(最低成本计划)”。
优化器跟踪文件中的以下代码片段显示了优化器执行的一些计算:
GENERAL PLANS *************************************** Considering cardinality-based initial join order. Permutations for Starting Table :0 Join order[1]: DEPARTMENTS[D]#0 EMPLOYEES[E]#1 *************** Now joining: EMPLOYEES[E]#1 *************** NL Join Outer table: Card: 27.00 Cost: 2.01 Resp: 2.01 Degree: 1 Bytes: 16 Access path analysis for EMPLOYEES . . . Best NL cost: 13.17 . . . SM Join SM cost: 6.08 resc: 6.08 resc_io: 4.00 resc_cpu: 2501688 resp: 6.08 resp_io: 4.00 resp_cpu: 2501688 . . . SM Join (with index on outer) Access Path: index (FullScan) . . . HA Join HA cost: 4.57 resc: 4.57 resc_io: 4.00 resc_cpu: 678154 resp: 4.57 resp_io: 4.00 resp_cpu: 678154 Best:: JoinMethod: Hash Cost: 4.57 Degree: 1 Resp: 4.57 Card: 106.00 Bytes: 27 . . . *********************** Join order[2]: EMPLOYEES[E]#1 DEPARTMENTS[D]#0 . . . *************** Now joining: DEPARTMENTS[D]#0 *************** . . . HA Join HA cost: 4.58 resc: 4.58 resc_io: 4.00 resc_cpu: 690054 resp: 4.58 resp_io: 4.00 resp_cpu: 690054 Join order aborted: cost > best plan cost ***********************跟踪文件显示优化器首先尝试将departments表作为联接中的外部表。优化器计算三种不同连接方法的成本:嵌套循环连接(NL)、排序合并(SM)和哈希连接(HA)。优化器选择哈希连接作为最有效的方法:
Best:: JoinMethod: Hash Cost: 4.57 Degree: 1 Resp: 4.57 Card: 106.00 Bytes: 27然后,优化器使用employees作为外部表,尝试不同的连接顺序。此连接顺序的成本高于前一个连接顺序,因此被放弃。
优化器在找到成本最低的计划时使用内部截止值来减少它尝试的计划数量。截止日期基于当前最佳计划的成本。如果当前的最佳成本较大,则优化器会探索其他计划以找到成本较低的计划。如果当前的最佳成本很小,那么优化器会迅速结束搜索,因为进一步的成本改进并不显著。
② 优化器的分类:
rbo(rule-based optimization):基于规则的优化器(9i)
Oracle 的规则优化器(RBO,Rule-Based Optimizer)是早期版本中用于生成 SQL 查询执行计划的一种优化器。 在 RBO 中,查询的优化和执行计划的生成依赖于一套预定义的规则和优先级,而非基于成本模型。这意味着,RBO 的决策完全由规则驱动。具体而言,RBO 根据一系列固定的规则来决定查询的执行路径,这些规则包括表的访问顺序、联接方式等 。例如,RBO 可能会选择使用索引扫描而非全表扫描,或者选择某种特定的联接类型。在某些情况下,如果
WHERE子句中的某列有索引,RBO 会优先选择索引扫描,而不是全表扫描;而当没有合适的索引时,RBO 可能会选择全表扫描。在 RBO 中,执行计划的生成是通过应用这些规则,并根据预定义的优先级来排序规则的执行顺序。这些优先级决定了哪些规则被优先应用。与之后引入的成本优化器(CBO,Cost-Based Optimizer)不同,RBO 不会考虑执行计划的成本或性能,只是简单地按照规则来选择执行路径。
从 Oracle 10g 版本开始,Oracle 数据库逐渐转向主要使用成本优化器(CBO),而 RBO 在现代版本中已被完全淘汰。虽然 RBO 在早期版本中被广泛使用,但 CBO 因其更灵活、更能够提供优化的执行计划,成为了当前的主流优化方法。
PS小提示:从 Oracle 10g 开始,RBO 已经被弃用,但仍然可以通过使用 Hint 强制查询使用规则优化器。需要注意的是,走索引不一定总是最优的。例如,如果一个表只有两行数据,那么一次 I/O 操作就能完成全表的检索。而如果使用索引,则可能需要两次 I/O 操作。此时,全表扫描(Full Table Scan)反而是更高效的选择。
cbo(cost-based optimization):基于成本的优化器(10g之后)
Oracle 的成本优化器(CBO,Cost-Based Optimizer)是一种基于成本模型的查询优化器,它通过评估不同执行计划的成本,来选择最优的执行路径。CBO 主要依据表的统计信息来计算每个执行计划的成本,然后选择成本最低的计划。具体来说,CBO 评估的成本因素包括 I/O 操作、CPU 消耗、内存使用和网络传输等。
在做出决策时,优化器主要参考表、索引、列以及数据分布的统计信息。这些统计信息包括表的大小、行数、每行的长度等内容。刚开始时,数据库中是没有这些统计信息的,可以通过
ANALYZE或DBMS_STATS包来更新。统计信息越准确,CBO 选择的执行计划通常就越高效。CBO 会评估多种执行路径,包括不同的联接方法(如嵌套循环、哈希联接等)、访问路径(如全表扫描、索引扫描等)以及排序方式。根据数据的分布和查询模式的变化,CBO 会自适应地调整执行计划。因此,定期更新统计信息非常重要,因为过期的统计信息可能导致优化器生成不合理的执行计划。
此外,Oracle 允许通过设置参数(如
OPTIMIZER_MODE)来选择不同的优化策略,这使得 CBO 可以在不同的兼容模式下运行,包括返回与 RBO 相似的行为。
③ 优化器的优化模式:
SQL> show parameter optimizer_mode ###Oracle使用optimizer_mode参数为实例选择优化方法的默认行为。 first_rows_n --CBO first_rows --CBO all_rows --CBO rule --RBO Choose --RBO SQL> alter session set optimizer_mode=rule | choose | first_rows | all_rows | FIRST_ROWS_[1 | 10 | 100 | 1000];PS小提示:10g之后默认为all_rows。并且10g之后中不再支持RBO(rule、Choose),需要注意10g之后官方文档关于optimizer_mode参数的只有first_rows_n、first_rows和all_rows。
值
描述
FIRST_ROWS_N
优化器使用基于成本的方法,目标是优化最佳响应时间,以返回前 n 行(其中 n = 1、10、100、1000)。
FIRST_ROWS
优化器使用成本和启发式方法的结合,找到一个最佳计划,以快速返回前几行。FIRST_ROWS 主要用于向后兼容性和执行计划稳定性;建议使用 FIRST_ROWS_n 代替。
ALL_ROWS
优化器对会话中的所有 SQL 语句使用基于成本的方法,并以最佳吞吐量为目标进行优化(即最小资源消耗以完成整个语句)。
RULE
RULE 参数与 ALL_ROWS 参数恰好相反,不论是否有统计信息,都会采用基于规则(RBO)的优化方法。基于规则的优化器(RBO)是早期 Oracle 版本使用的一种优化模式。然而,由于 RBO 不支持自 1994 年以来 Oracle 版本引入的新特性,如位图索引、分区表、基于函数的索引等,因此在后续的 Oracle 版本中,RBO 不再得到更新,并且不推荐用户继续使用这种优化模式。
CHOOSE
当使用 CHOOSE 参数时,Oracle 会根据当前 SQL 查询中被访问的表是否具有统计信息,决定是使用基于规则(RBO)还是基于成本(CBO)的优化方法。如果查询中有一个或多个表具有统计信息,Oracle 会对没有统计信息的表进行采样统计,而不是对全部数据进行统计。统计完成后,Oracle 会选择基于成本的优化方法(CBO)。如果所有被访问的表都没有统计信息,Oracle 则会采用基于规则的优化方法(RBO)。
步骤四:行源生成器阶段(对SQL语句进行解析(prase),利用内部算法对SQL进行解析,生成解析树(parse tree)及执行计划(execution plan)
行源生成器是从优化器接收最优执行计划 并生成可供数据库其余部分使用的迭代执行计划的软件。
迭代计划是一个二进制程序,当由SQL引擎执行时,会产生结果集。该计划采取了一系列步骤的组合形式。每一步返回一个行集。下一步使用此集中的行,或者最后一步将行返回给发出SQL语句的应用程序。
行源是由执行计划中的步骤返回的行集,以及可以迭代处理行的控制结构。行源可以是表、视图或联接或分组操作的结果。
行源生成器生成一个行源树,它是行源的集合。行源树显示以下信息:
- 语句引用的表的排序
- 语句中提到的每个表的访问方法
- 语句中受联接操作影响的表的联接方法
- 数据操作,如筛选、排序或聚合
行源生成器阶段之执行计划
SQL的执行计划实际代表了目标SQL在数据库内部的具体执行步骤。执行计划贯穿于Oracle调优的全过程,只有了解了优化器选择的执行计划是否是当前情形下最优的,才能确定下一步的调优方向。了解执行计划的真实执行过程对于SQL优化至关重要。
查看执行计划的方法:
SQLPLUS AUTOTRACE ###自动跟踪某条SQL最简单的方法,但计划执行不真实 Explain Plan For SQL(VSSQL和VSSQL_PLAN) ###对于很长时间不能返回结果的sql使用这种方法,但计划执行不真实使用 DBMS_XPLAN包 ###查看某条SQL多条执行计划,计划执行真实 PL/SQLDev,Toad ###调用的就是Explain Plan For SQL AWR执行计划报告 ###查看某条SQL多条执行计划
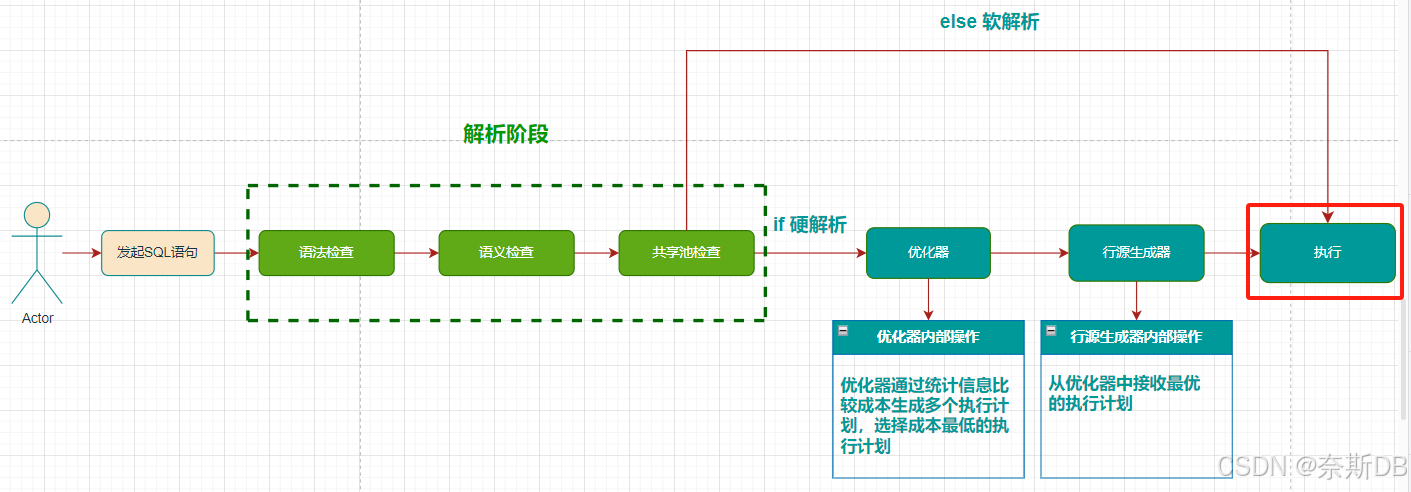
步骤五:执行阶段(执行SQL语句,返回结果execute and return)
在讲解之前我们先看一个SQL语句的执行计划。如下示例中列出了SELECT语句的执行计划。该语句为姓氏以字母A开头的所有员工选择姓氏、职务和部门名称。此语句的执行计划是行源生成器的输出。
SELECT e.last_name, j.job_title, d.department_name FROM hr.employees e, hr.departments d, hr.jobs j WHERE e.department_id = d.department_id AND e.job_id = j.job_id AND e.last_name LIKE 'A%'; Execution Plan ---------------------------------------------------------- Plan hash value: 975837011 --------------------------------------------------------------------------- | Id| Operation | Name |Rows|Bytes|Cost(%CPU)|Time| --------------------------------------------------------------------------- | 0| SELECT STATEMENT | | 3 |189 |7(15)|00:00:01 | |*1| HASH JOIN | | 3 |189 |7(15)|00:00:01 | |*2| HASH JOIN | | 3 |141 |5(20)|00:00:01 | | 3| TABLE ACCESS BY INDEX ROWID| EMPLOYEES | 3 | 60 |2 (0)|00:00:01 | |*4| INDEX RANGE SCAN | EMP_NAME_IX | 3 | |1 (0)|00:00:01 | | 5| TABLE ACCESS FULL | JOBS |19 |513 |2 (0)|00:00:01 | | 6| TABLE ACCESS FULL | DEPARTMENTS |27 |432 |2 (0)|00:00:01 | --------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 1 - access("E"."DEPARTMENT_ID"="D"."DEPARTMENT_ID") 2 - access("E"."JOB_ID"="J"."JOB_ID") 4 - access("E"."LAST_NAME" LIKE 'A%') filter("E"."LAST_NAME" LIKE 'A%')在执行过程中,SQL引擎执行行源生成器生成的树中的每个行源。此步骤是DML处理中唯一必需的步骤。
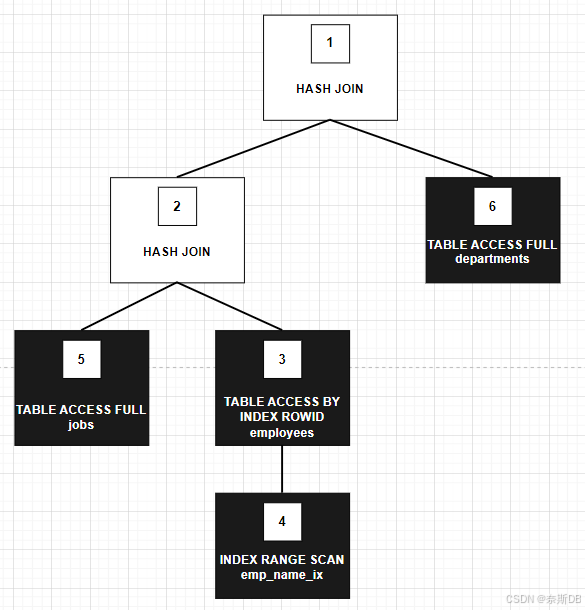
那么我们将上面SQL语句的执行计划画成下面的执行树,也称为解析树,执行树显示了SQL语句的执行计划从一个步骤到另一个步骤的流程。一般来说,执行步骤的顺序与计划中的顺序相反,因此需要从下往上阅读计划。
执行计划中的每个步骤都有一个ID号。下图中的数字对应于上面SQL语句执行计划中的Id列。SQL语句执行计划中的“Operation(操作)”列,前面的空格表示层次关系。例如,如果一个operation(操作)的名称前面有两个空格,那么这个operation(操作)就是前面有一个空格的操作的子操作。前面有一个空格的操作是SELECT语句本身的子项。
在上图中,树的每个节点都充当行源,这意味着SQL语句执行计划的每个步骤要么从数据库中检索行,要么接受来自一个或多个行源的行作为输入。SQL引擎按如下方式执行每个行源:
黑框指示的步骤从数据库中的对象中物理检索数据。这些步骤是从数据库检索数据的访问路径或技术:
- 步骤6:使用全表扫描从departments表中检索所有行。
- 步骤5:使用全表扫描从jobs表中检索所有行。
- 步骤4:按顺序扫描emp_name_ix索引,查找以字母A开头的每个键并检索相应的行ID。例如,与Atkinson对应的rowid是AAAPzRAAFAAAABSAAe。
- 步骤3:从employees表中检索其rowid由步骤4返回的行。例如,数据库使用rowid AAAPzRAAFAAAABSAAe检索Atkinson的行。
白框指示的步骤对行源进行操作:
- 步骤2:执行hash join(哈希连接),接受步骤3和5中的行源,在步骤3中将步骤5行源中的每一行连接到其对应的行,并将结果行返回到步骤1。例如,员工Atkinson的行与职位名称“Stock Clerk”相关联。
- 步骤1:执行另一个hash join(哈希连接),接受步骤2和6中的行源,在步骤2中将步骤6源中的每一行连接到其对应的行,并将结果返回给客户端。例如,员工Atkinson的行与名为“Shipping”的部门相关联。
在某些执行计划中,步骤是迭代的,而在其他执行计划中则是顺序的。在SQL执行计划中显示的哈希连接是顺序的。数据库根据连接顺序完整地完成这些步骤。数据库从emp_name_ix的索引范围扫描开始。使用从索引中检索的行ID,数据库读取employees表中的匹配行,然后扫描jobs表。从jobs表检索行后,数据库执行哈希连接。
在执行过程中,如果数据不在内存中,数据库会将数据从磁盘读取到内存中。数据库还会取出确保数据完整性所需的任何锁和闩锁,并记录SQL执行过程中所做的任何更改。处理SQL语句的最后阶段是关闭游标。

《一条 SQL 语句的执行流程》和《优化器》的介绍到这里就算全部结束啦,对于这两个部分,网上的资源非常有限,并且文章也良莠参半,整理起来非常不容易,可能有些重要的知识点也没有再文章中体现,如果有想深入了解的同学可以去参考官方文档哦,也希望各位小伙伴提出建议,查缺补漏,让这篇文章更加完善。



















 5593
5593

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











