






"少年为学者,每一书皆作数次读之。当如入海百货皆有,人之精力不能并收尽取,但得其所欲求者耳。故愿学者每一次作一意求之,如欲求古今兴亡治乱圣贤作用,且只作此意求之,勿生余念;又别作一次求事迹文物之类,亦如之。他皆仿此。若学成,八面受敌,与慕涉猎者不可同日而语。"
本文首发微信公众号:码上观世界
Iceberg作为凌驾于HDFS和S3等存储系统之上的数据组织框架,提供了数据写入、读取、文件管理和元数据管理等基本功能,虽然Iceberg提供了丰富的API接口,但是面向API开发需要使用方比较了解其原理和实现细节,还是显得门槛过高。此外,在面向实时数据读写场景,需要有一个桥接框架来自动完成数据的读写,于是Iceberg和Flink成为天作之合,本文就来研究下Iceberg是如何跟Flink对接的。
Flink写入Iceberg总体流程介绍
Flink典型的数据处理链路是Source->Transform->Sink,对Iceberg来讲,也遵从这一模式,比如下图:
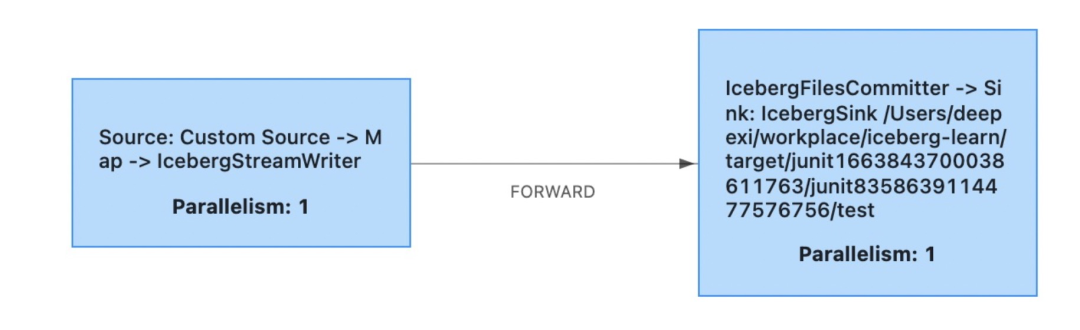
Custom Souce是自定义的数据源类型的Source,用于向下游发送数据,比如下面的数据来源于静态List集合:
DataStream<RowData> dataStream = env.fromCollection(list)
IcebergStreamWriter起着数据变换作用,跟Source 组成链式Operator,IcebergFilesCommiter作为Sink,将数据提交到本地文件test表。
Source端发送数据到IcebergStreamWriter,IcebergFilesCommiter将从IcebergStreamWriter获取的数据提交到元数据管理系统,比如Hive Metastore或者文件系统。当成功提交元数据之后,写入的数据才对外部可见。在这一个过程中,IcebergStreamWriter除了相当于上述链路模式中的Transform角色之外,还有一个重要原因:实现事务提交隔离。IcebergStreamWriter将数据暂时写入到一个缓冲文件,该文件暂时对外部是不可见的,然后IcebergFilesCommiter再将IcebergStreamWriter写入的文件的元信息,比如路径、文件大小,记录行数等写入到ManifestFile中,最后将ManifestFile文件元信息再写入到ManifestList(ManifestList即快照信息),ManifestList又被写入以版本号区分的metadata文件中(v%版本号%.metadata.json),下图展示了一个完整的数据包括元数据组织示例:
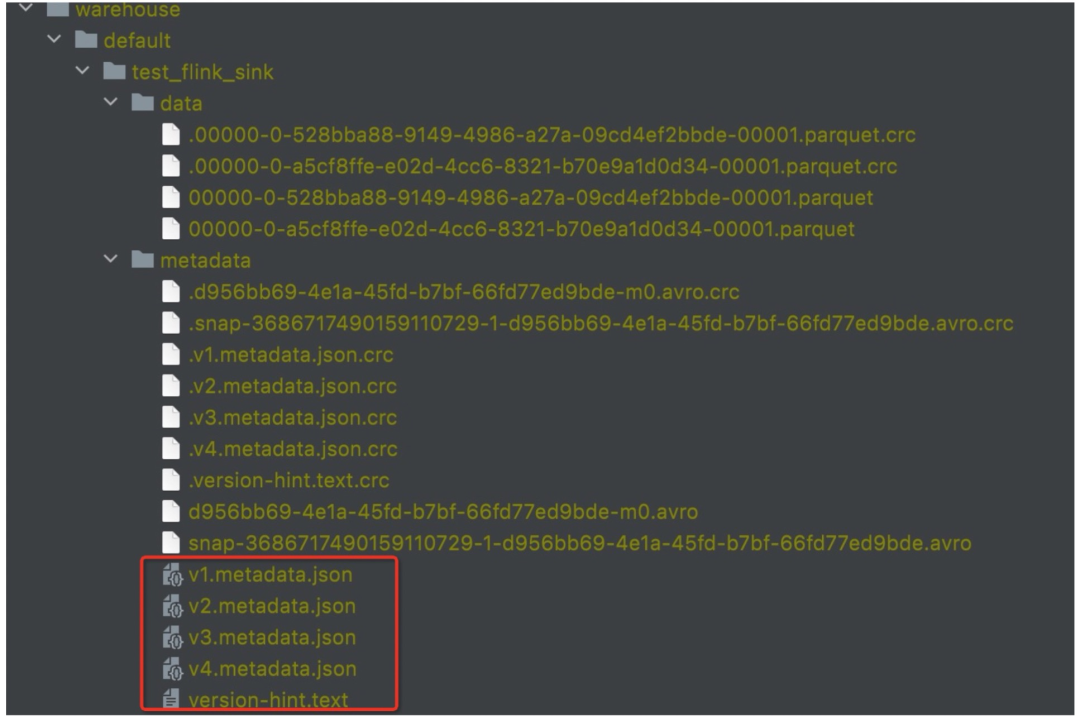
下面展开来讲下实现上述目标的细节内容:
首先Source端DataStream数据流经过IcebergStreamWriter变换,生成新的DataStream:SingleOutputStreamOperator<WriteResult> ,输出类型是WriteResult:
//DataStream<RowData> input
//IcebergStreamWriter streamWriter
SingleOutputStreamOperator<WriteResult> writerStream = input
.transform(operatorName(ICEBERG_STREAM_WRITER_NAME), TypeInformation.of(WriteResult.class), streamWriter)
.setParallelism(parallelism);其中WriteResult的定义如下:
public class WriteResult implements Serializable {
private DataFile[] dataFiles;
private DeleteFile[] deleteFiles;
private CharSequence[] referencedDataFiles;
...
}从类定义可知,IcebergStreamWriter的输出结果其实只是该过程产生的数据文件,主要包括DataFile和DeleteFile,referencedDataFiles暂时先不关注。
然后,IcebergFilesCommiter对上游的Operator 做变换,生成新的DataStream:SingleOutputStreamOperator<Void>,这个过程只是提交元数据,本身不会再往下游发送数据,所以返回数据类型为Void:
//SingleOutputStreamOperator<WriteResult> writerStream
SingleOutputStreamOperator<Void> committerStream = writerStream
.transform(operatorName(ICEBERG_FILES_COMMITTER_NAME), Types.VOID, filesCommitter)
.setParallelism(1)
.setMaxParallelism(1);IcebergStreamWriter和IcebergFilesCommiter实现详细分析
从上面介绍可知,IcebergStreamWriter和IcebergFilesCommiter是最主要的两个数据处理过程,下面对其详细介绍。IcebergStreamWriter和IcebergFilesCommiter都是AbstractStreamOperator的子类,本身除了要实现对单个元素的处理逻辑,还有对快照处理的相关逻辑,先说说对单个元素的处理逻辑:
class IcebergStreamWriter<T> extends AbstractStreamOperator<WriteResult>
implements OneInputStreamOperator<T, WriteResult>, BoundedOneInput {
private transient TaskWriter<T> writer;
@Override
public void processElement(StreamRecord<T> element) throws Exception {
writer.write(element.getValue());
}
@Override
public void endInput() throws IOException {
// For bounded stream, it may don't enable the checkpoint mechanism so we'd better to emit the remaining
// completed files to downstream before closing the writer so that we won't miss any of them.
emit(writer.complete());
}
}IcebergStreamWriter的processElement逻辑看起来比较简单,实际都封装到TaskWriter中去了。endInput方法起着兜底作用,在关闭writer之前,将剩余未发送的数据发到下游,由前文可知,发给下游的数据类型为WriteResult。这里一个明显问题是writer是无止境地往文件中写吗?实际不是的,Writer会根据写入的文件大小自动切换新的Writer。
再来看IcebergFilesCommitter:
class IcebergFilesCommitter extends AbstractStreamOperator<Void>
implements OneInputStreamOperator<WriteResult, Void>, BoundedOneInput {
// The completed files cache for current checkpoint. Once the snapshot barrier received, it will be flushed to the 'dataFilesPerCheckpoint'.
private final List<WriteResult> writeResultsOfCurrentCkpt = Lists.newArrayList();
@Override
public void processElement(StreamRecord<WriteResult> element) {
this.writeResultsOfCurrentCkpt.add(element.getValue());
}
@Override
public void endInput() throws IOException {
// Flush the buffered data files into 'dataFilesPerCheckpoint' firstly.
long currentCheckpointId = Long.MAX_VALUE;
dataFilesPerCheckpoint.put(currentCheckpointId, writeToManifest(currentCheckpointId));
writeResultsOfCurrentCkpt.clear();
commitUpToCheckpoint(dataFilesPerCheckpoint, flinkJobId, currentCheckpointId);
}
}IcebergFilesCommitter的processElement将接收到的元素(WriteResult)放到内存List<WriteResult>中,在endInput中提交。这里有一个明显的问题:如果数据无界,List<WriteResult> writeResultsOfCurrentCkpt是否可能被撑爆?因为WriteResult只是记录文件的元信息,比如位置等,实际数据已经落盘了,尽管如此,这种实现也是适用于有界数据。如果实时无界数据流,就需要靠Checkpoint机制了。先来看IcebergStreamWriter如何实现Checkpoint快照逻辑:
class IcebergStreamWriter<T> extends AbstractStreamOperator<WriteResult>
implements OneInputStreamOperator<T, WriteResult>, BoundedOneInput {
...
@Override
public void prepareSnapshotPreBarrier(long checkpointId) throws Exception {
// close all open files and emit files to downstream committer operator
emit(writer.complete());
this.writer = taskWriterFactory.create();
}
...
}IcebergStreamWriter的Checkpoint 基于默认实现,只重写了prepareSnapshotPreBarrier预发送逻辑:结束当前Writer,创建WriteResult,发送到下游,同时切换writer实例,仅此而已。Checkpoint逻辑的重头戏在IcebergFilesCommitter中,因为IcebergStreamWriter支持并发创建Checkpoint,它只负责将写入结果发送到下游,而下游的IcebergFilesCommitter逻辑涉及到多Checkpoint的排序、ManifestFlie和ManifestList的创建、snapshot 状态的保存与维护等,为保证Checkpoint的事务性,IcebergFilesCommitter采用串行化提交。
class IcebergFilesCommitter extends AbstractStreamOperator<Void>
implements OneInputStreamOperator<WriteResult, Void>, BoundedOneInput {
// The completed files cache for current checkpoint. Once the snapshot barrier received, it will be flushed to the 'dataFilesPerCheckpoint'.
private final List<WriteResult> writeResultsOfCurrentCkpt = Lists.newArrayList();
@Override
public void initializeState(StateInitializationContext context) throws Exception {
...
this.maxCommittedCheckpointId = getMaxCommittedCheckpointId(table, restoredFlinkJobId);
NavigableMap<Long, byte[]> uncommittedDataFiles = Maps
.newTreeMap(checkpointsState.get().iterator().next())
.tailMap(maxCommittedCheckpointId, false);
if (!uncommittedDataFiles.isEmpty()) {
// Committed all uncommitted data files from the old flink job to iceberg table.
long maxUncommittedCheckpointId = uncommittedDataFiles.lastKey();
commitUpToCheckpoint(uncommittedDataFiles, restoredFlinkJobId, maxUncommittedCheckpointId);
}
...
}
@Override
public void snapshotState(StateSnapshotContext context) throws Exception {
...
// Update the checkpoint state.
dataFilesPerCheckpoint.put(checkpointId, writeToManifest(checkpointId));
// Reset the snapshot state to the latest state.
checkpointsState.clear();
checkpointsState.add(dataFilesPerCheckpoint);
...
}
@Override
public void notifyCheckpointComplete(long checkpointId) throws Exception {
super.notifyCheckpointComplete(checkpointId);
// It's possible that we have the following events:
// 1. snapshotState(ckpId);
// 2. snapshotState(ckpId+1);
// 3. notifyCheckpointComplete(ckpId+1);
// 4. notifyCheckpointComplete(ckpId);
// For step#4, we don't need to commit iceberg table again because in step#3 we've committed all the files,
// Besides, we need to maintain the max-committed-checkpoint-id to be increasing.
if (checkpointId > maxCommittedCheckpointId) {
commitUpToCheckpoint(dataFilesPerCheckpoint, flinkJobId, checkpointId);
this.maxCommittedCheckpointId = checkpointId;
}
}这就是IcebergFilesCommitter整个的Checkpoint的提交逻辑,不论是无Checkpoint还是有Checkpoint,最终都落脚到commitUpToCheckpoint方法中进行元数据的提交,接下来单独看它的实现方式。
Checkpoint元数据提交详解
Iceberg把每次Checkpoint的变更操作用一个接口类SnapshotUpdate来定义,其中一个主要方法就是commit,它的子类实现比较多,比如下面的:
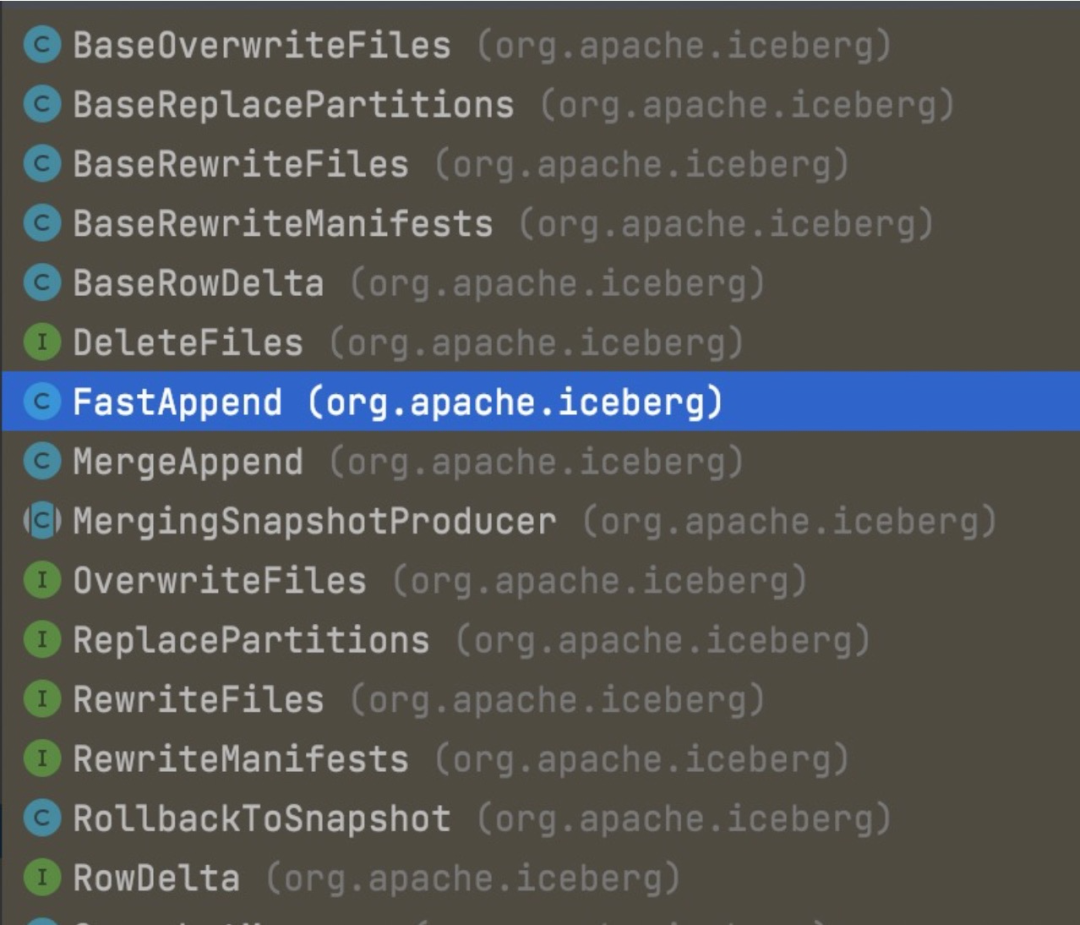
这些操作涉及到重写文件、添加文件、删除文件、重写Manifest文件、替换分区、快照回滚等,同时在Table中也向用户暴露了一些操作接口,比如:

举两个例子,newAppend用于向table中追加数据文件,newRowDelta向表中同时追加数据文件和删除文件:
table.newAppend()
.appendFile(dataFile)
.commit();
table.newRowDelta()
.addRows(dataFile)
.addDeletes(deleteFile)
.commit();而在SnapshotUpdate实现类的commit方法中,又通过接口TableOperations的commit来实现:
TableOperations operations = ((BaseTable) table).operations();
TableMetadata metadata = operations.current();
operations.commit(metadata, metadata.upgradeToFormatVersion(2));TableOperations是干啥的呢?类注释是这么写的:
SPI interface to abstract table metadata access and updates.
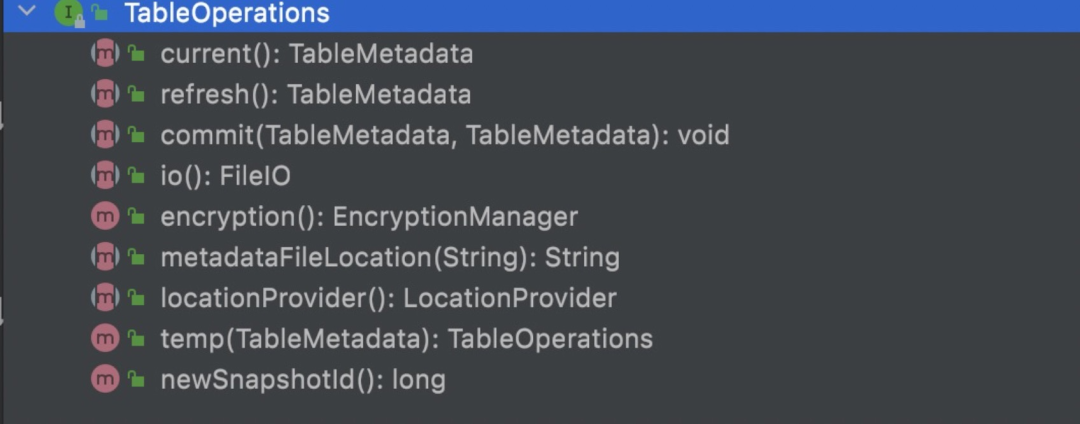
从接口定义来看,它是关于metadata的访问和更新操作的,其有三个主要实现类:HadoopTableOperations、HiveTableOperations和JdbcTableOperations。为什么会有这么多不同的实现类呢?回顾文章开头部分的Iceberg的元数据组织结构和Checkpoint过程可知,Iceberg支持并发Checkpoint,但是在提交元数据阶段又要保证事务性,因此在提交元数据过程如何保证原子性地让metadata文件按照提交顺序递增是一大挑战。
先来看HadoopTableOperations是如何实现的?HadoopTable是将元数据存储在HDFS文件上,没有依赖HMS,因此在生成v%版本号%.metadata.json文件时,需要有一个地方记录上次最大的版本序号,Iceberg的做法是在metadata目录创建一个version-hint.txt文件,里面记录上次的版本序号,每次提交新的metadata.json文件时就更新这个值,而如何保证提交新的metadata.json不会导致冲突,Iceberg是先生成一个随机序号的临时metadata.json文件,然后再通过rename到当前版本号+1的metadata.json文件,如果rename成功,则表示没有冲突,否则丢弃当前交。
再看HiveTableOperations是如何保证metadata.json的原子顺序提交的?HiveTable跟HadoopTable的区别是,HiveTable依赖HMS,HiveTableOperations通过一个进程级别的全局锁来控制每个表一把锁,进而控制对表元数据修改的并发提交。
而JdbcTableOperations是将表的元数据信息存储在支持JDBC协议的数据库中的固定表iceberg_tables中,所有对表元信息的更新通过数据库本身的乐观锁实现。
总结
Flink实时写入Iceberg的过程不论是否基于Checkpoint,都是通过两阶段完成,并且做到事务隔离,即IcebergStreamWriter负责数据的写入落盘,然后写入结果WriteResult发送到下游,IcebergFilesCommitter从IcebergStreamWriter发送的多个WriteResult中回放数据文件,按照数据类型的不同(DAtaFile、DeleteFile)创建对应类型的ManifestFile,并创建ManifestList作为快照保存在序号递增的metadata.json文件中,为保证metadata.json序号的递增,Iceberg采用了多种方式来实现并发更新操作来满足不同场景的需要,比如HadoopTable基于HDFS,不依赖HMS,通过文件的rename操作进行并发控制,HiveTable依赖HMS,通过进程级的表锁来控制并发,而JdbcTable依赖支持JDBC协议的数据库本身的乐观锁机制来实现并发控制。
Iceberg作为数据湖的代表性框架,能够解决离线数仓的很多痛点,潜力很大,但是因为比较”年轻“,还存在很多问题,比如不支持跨分区的、跨快照的数据去重,小文件合并在大数据集场景下的性能问题、Schema不支持动态变更、索引能力较弱等,这些问题不解决,将会严重阻塞其推广使用,本文在后续将陆续介绍这些问题的解决方法。















 2758
2758











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









