






线性可分支持向量机:
举一个简单的例子:
我们需要将下面的圆圈和叉分开
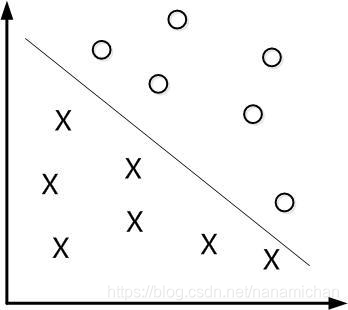
这里存在无数多条线可以将圆圈和叉分开,因此,我们要规定一个性能指标,对于每一条线,都有对应的一个性能指标。
我们将每一条可以分开圆圈和叉的线,平行的移动到可以叉到一个或几个圆圈和叉。两条线间的距离为d,同时,让这条线与两边的距离为d/2.
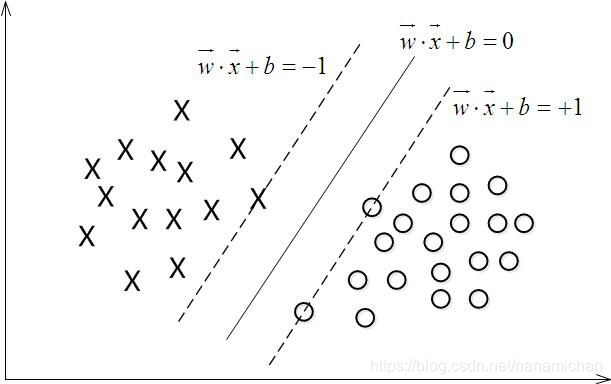
平行线插到的向量叫支持向量,这也是为什么支持向量机能用在小样本的训练上,因为这个方法最后做出来的线只跟支持向量有关,与其他点没有太大关系。在此可以引入定义了。
一.定义:
1. 训练数据及标签: T = {(X1,y1),(X2,y2)…,(Xn,yn)} (此处的Xi为向量,yi = +1或-1)
2. 线性模型:我们需要找到一个超平面 (W,b)
W
T
⋅
X
+
b
=
0
\begin{aligned}W^{T }\cdot X+ b\end{aligned} = 0
WT⋅X+b=0
此处的w也是一个向量,和X同维度,b为一个常数
通过上面这个函数来确定这是一个超平面模型,再通过训练样本和一些算法算出w和b的取值,学习完成。
3. 一个训练集可分是指:
{(Xi,yi)} i = 1~N
存在(W,b),使:
对任意 i = 1~N 有:
a.若yi = 1,则
W
T
⋅
X
+
b
≥
0
\begin{aligned}W^{T }\cdot X+ b\end{aligned} \geq 0
WT⋅X+b≥0
b.若yi = -1,则
W
T
⋅
X
+
b
≤
0
\begin{aligned}W^{T }\cdot X+ b\end{aligned} \leq 0
WT⋅X+b≤0
若yi只取+1 or -1,则可简化为
y
i
⋅
(
W
T
⋅
X
+
b
)
≥
0
yi\cdot(\begin{aligned}W^{T }\cdot X+ b\end{aligned} )\geq 0
yi⋅(WT⋅X+b)≥0
二.优化问题(凸优化问题:二次规划问题):
最小化: (||W||^2)/2 (此处除以2只是为了后面求导的方便)
限制条件: y i ⋅ ( W T ⋅ X + b ) ≥ 1 yi\cdot(\begin{aligned}W^{T }\cdot X+ b\end{aligned} )\geq 1 yi⋅(WT⋅X+b)≥1 (i = 1~N)
为证明上面所述,我们先要了解几个事实:
事实1.
W
T
⋅
X
+
b
=
0
\begin{aligned}W^{T }\cdot X+ b\end{aligned} = 0
WT⋅X+b=0 与
a
W
T
⋅
X
+
a
b
=
0
\begin{aligned}aW^{T }\cdot X+ ab\end{aligned} = 0
aWT⋅X+ab=0 是同一个平面 (a为实数)
事实2. 向量
X
0
X_{0}
X0到超平面
W
T
⋅
X
+
b
=
0
\begin{aligned}W^{T }\cdot X+ b\end{aligned} = 0
WT⋅X+b=0的距离为:
d =
W
T
⋅
X
0
+
b
∣
∣
W
∣
∣
\dfrac {\begin{aligned}W^{T }\cdot X_{0}+ b\end{aligned}}{||W||}
∣∣W∣∣WT⋅X0+b
结合上面事实,我们可以用a去缩放,使得:(W,b)-> (aW,ab)
最终在所有的支持向量
X
0
X_{0}
X0上有:
∣
W
T
⋅
X
0
+
b
∣
=
1
|\begin{aligned}W^{T }\cdot X_{0}+ b\end{aligned} | = 1
∣WT⋅X0+b∣=1
此时,支持向量与d的距离为:
1
∥
W
∥
\dfrac {1}{\left\| W\right\| }
∥W∥1
而其他点算出来的距离大于支持向量算出来的距离,这也是为什么要加入这个限制条件,上面限制条件中的数字1可以改成容易的整数,求出来代表的是同一个平面。
二次规划:
1.目标函数为二次项
2.限制条件为一次项
在上述条件下,要么无解,要么只有一个极值 ,而优化的方法基本上都离不开挨个搜寻,梯度下降。找到局部极值。(模拟退火算法能更好的寻找全局最优解,这里不做展开了)
支持向量机将整个问题化成一个凸优化问题,在凸优化问题下,将有一个最优解。
关于原问题与对偶问题的转化将在后面处理非线性中讲到,是类似的。
SVM处理非线性:
1.最小化: 1 2 ∥ W ∥ 2 + C ∑ i = 1 N ξ i \dfrac {1}{2}\left\| W\right\| ^{2}+C\sum ^{N}_{i=1}\xi _{i} 21∥W∥2+C∑i=1Nξi ( ξ i \xi _{i} ξi为松弛变量)
2.限制条件:
a. y i ⋅ ( W T ⋅ X i + b ) ≥ 1 − ξ i yi\cdot(\begin{aligned}W^{T }\cdot X _{i}+ b\end{aligned} )\geq 1-\xi _{i} yi⋅(WT⋅Xi+b)≥1−ξi
b. ξ i ≥ 0 \xi _{i}\geq 0 ξi≥0 (i = 1 ~ K)
当.
ξ
i
\xi _{i}
ξi特别大时,a式子很容易成立,但是优化问题会变得非常发散,因此,需要
C
∑
i
=
1
N
ξ
i
C\sum ^{N}_{i=1}\xi _{i}
C∑i=1Nξi中的系数C来让平衡两个任务
1.最小化
1
2
1
∥
W
∥
2
\dfrac {1}{2}\dfrac {1}{\left\| W\right\| }^{2}
21∥W∥12
2.限制
ξ
i
\xi _{i}
ξi的大小,让
ξ
i
\xi _{i}
ξi比较的小
其中yi,
X
i
X_{i}
Xi 为已知的,要求的未知量是W,
ξ
i
\xi _{i}
ξi,b
C
∑
i
=
1
N
ξ
i
C\sum ^{N}_{i=1}\xi _{i}
C∑i=1Nξi 叫做正则项
C是一个事先设定的参数,一般来说可以给一个数列来带进去不断地尝试,但就上面的处理是可能不够的。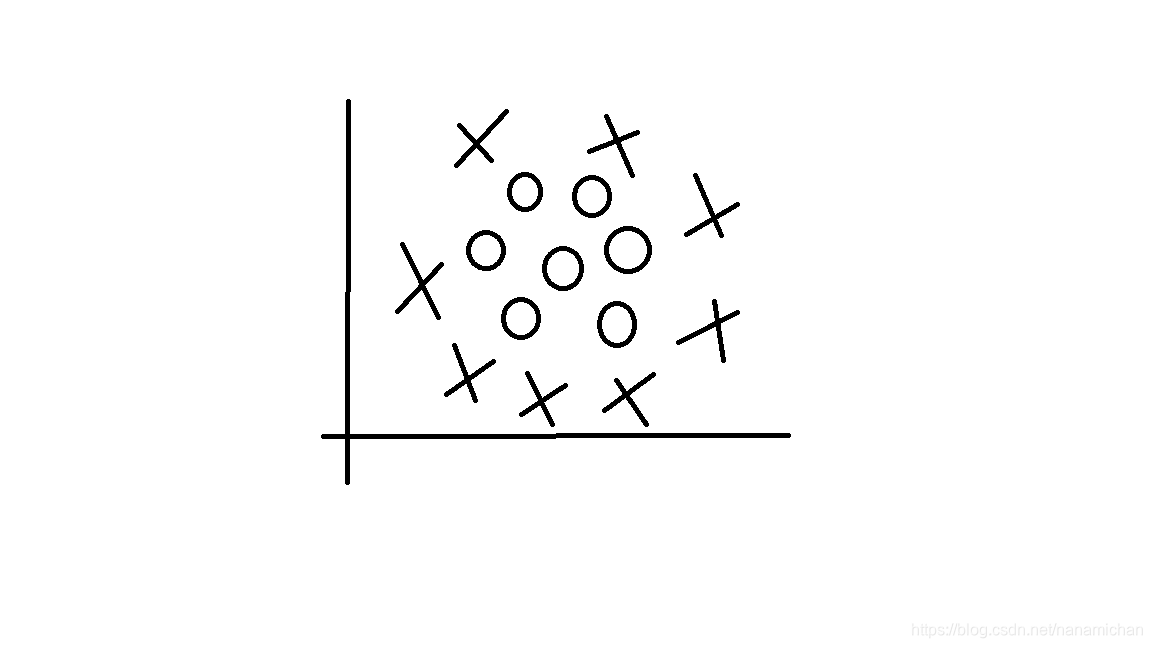
比如上面这个图片(我随手画的,好丑(ಥ_ಥ))虽然我们能一眼看出用一个怎么样是比较好的,但是用上面的方法做不了(找一条直线)。因此,我们可以将这些点映射到更高维
φ
(
x
)
\varphi \left( x\right)
φ(x)
X
φ
>
X\dfrac {\varphi}{} >
Xφ>
φ
(
x
)
\varphi \left( x\right)
φ(x)
换句话说,在低维空间线性不可分的一些数据集到高维的空间有更大的概率被分开。
在这里举一个例子:
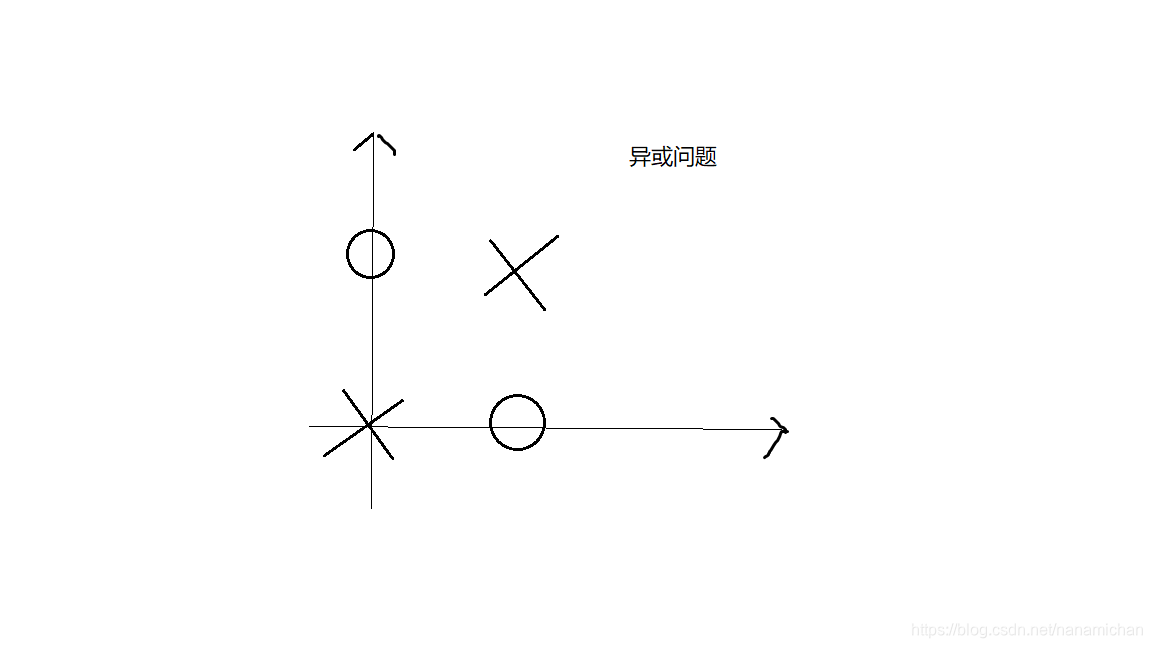
对于上面这个图,我们找不出一条直线,能将圆圈和叉分开。
假设:
X1 =
[
0
0
]
\begin{bmatrix} 0 \\ 0 \end{bmatrix}
[00],X2 =
[
1
1
]
\begin{bmatrix} 1 \\ 1\end{bmatrix}
[11],X3 =
[
1
0
]
\begin{bmatrix} 1 \\ 0 \end{bmatrix}
[10],X4 =
[
0
1
]
\begin{bmatrix} 0 \\ 1 \end{bmatrix}
[01]
其中X1,X2为叉,X3,X4为圆圈。这里可以通过这样的映射(多项式回归):
X =
[
a
b
]
\begin{bmatrix} a \\ b \end{bmatrix}
[ab]
φ
>
\dfrac {\varphi }{}>
φ>
φ
(
×
)
=
[
a
2
b
2
a
b
a
b
]
\varphi _{(\times )}=\begin{bmatrix} a^{2} \\ b^{2} \\ a \\b \\ab\end{bmatrix}
φ(×)=⎣⎢⎢⎢⎢⎡a2b2abab⎦⎥⎥⎥⎥⎤
带入得到:
φ ( × 1 ) = [ 0 0 0 0 0 ] \varphi _{(\times1 )}=\begin{bmatrix} 0 \\ 0 \\ 0 \\ 0 \\0 \end{bmatrix} φ(×1)=⎣⎢⎢⎢⎢⎡00000⎦⎥⎥⎥⎥⎤, φ ( × 2 ) = [ 1 1 1 1 1 ] \varphi _{(\times2 )}=\begin{bmatrix} 1 \\ 1 \\ 1\\1 \\1\end{bmatrix} φ(×2)=⎣⎢⎢⎢⎢⎡11111⎦⎥⎥⎥⎥⎤, φ ( × 3 ) = [ 1 0 1 0 0 ] \varphi _{(\times 3)}=\begin{bmatrix} 1 \\ 0 \\ 1 \\0 \\0\end{bmatrix} φ(×3)=⎣⎢⎢⎢⎢⎡10100⎦⎥⎥⎥⎥⎤ φ ( × 4 ) = [ 0 1 0 1 0 ] \varphi _{(\times4 )}=\begin{bmatrix} 0 \\ 1 \\ 0 \\ 1 \\0 \end{bmatrix} φ(×4)=⎣⎢⎢⎢⎢⎡01010⎦⎥⎥⎥⎥⎤
在此,因为维度已经改变,在
y
i
⋅
(
W
T
⋅
X
i
+
b
)
≥
1
−
ξ
i
yi\cdot(\begin{aligned}W^{T }\cdot X _{i}+ b\end{aligned} )\geq 1-\xi _{i}
yi⋅(WT⋅Xi+b)≥1−ξi中的W也应该改变为与
φ
(
x
)
\varphi \left( x\right)
φ(x)同维。同时将Xi换成
φ
(
x
i
)
\varphi \left( xi\right)
φ(xi)。在这里W是五维的,而b始终是个常数。
可以将上面的
φ
(
x
i
)
\varphi \left( xi\right)
φ(xi)回代,得到不止一组解。这里给出一组解:
W
=
[
−
1
−
1
−
1
−
1
6
]
W=\begin{bmatrix} -1 \\ -1 \\ -1 \\ -1 \\6 \end{bmatrix}
W=⎣⎢⎢⎢⎢⎡−1−1−1−16⎦⎥⎥⎥⎥⎤
有相关证明,在空间内取随机的点,标上圆圈或叉,维度越高时,
分开的概率越大,在无限维分开的概率为1
φ
(
×
)
\varphi _{(\times )}
φ(×)是无限维,但是直接将无限维带入是无法处理的。这里SVM有一个非常有趣的处理方法:
我们可以不知道无限维映射
φ
(
×
)
\varphi _{(\times )}
φ(×)的显式表达式,我们只需要知道一个核函数:
K(x1,x2) =
φ
(
x
1
)
T
φ
(
x
2
)
\varphi ^{T}_{\left( x_{1}\right) }\varphi _{\left( x_{2}\right) }
φ(x1)Tφ(x2)
则这个优化式仍然可解。
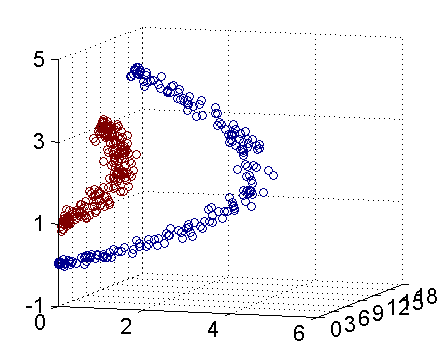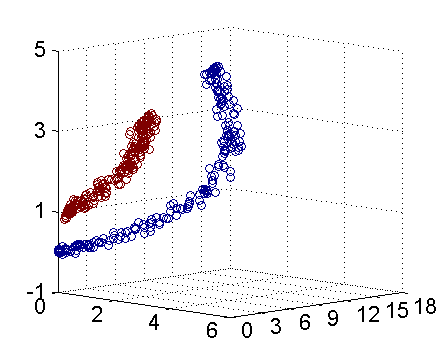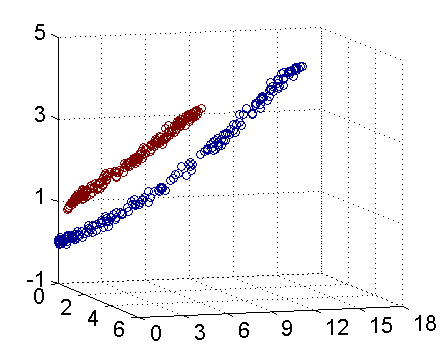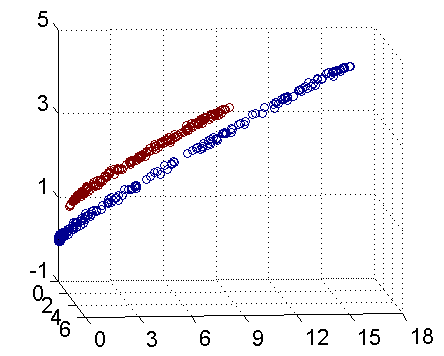
这里可以两张图来方便理解
可以很明显的看到,在二维无法分开的点,映射到三维就能用一个超平面分开
(图片来自https://blog.csdn.net/v_july_v/article/details/7624837)

SVM中常见的核函数:
1. 线性核函数 LINEAR:
线性核,主要用于线性可分的情况。我们可以看到特征空间到输入空间的维度是一样的,其参数少|速度快。对于线性可分数据,其分类效果很理想,因此我们通常首先尝试用线性核函数来做分类,看看效果如何,如果不行再换别的。
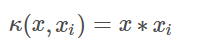
2.高斯径向基核函数 RBF:
高斯径向基函数是一种局部性强的核函数,其可以将一个样本映射到一个更高维的空间内,该核函数是应用最广的一个,无论大样本还是小样本都有比较好的性能,而且其相对于多项式核函数参数要少,因此大多数情况下在不知道用什么核函数的时候,优先使用高斯核函数。
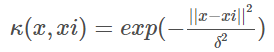
3.多项式核函数 POLY:
多项式核函数可以实现将低维的输入空间映射到高纬的特征空间,但是多项式核函数的参数多,当多项式的阶数比较高的时候,核矩阵的元素值将趋于无穷大或者无穷小,计算复杂度会大到无法计算。
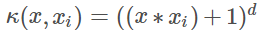
4.神经元的非线性作用核函数 Sigmoid:
采用sigmoid核函数,支持向量机实现的就是一种多层神经网络。因此,在选用核函数的时候,如果我们对我们的数据有一定的先验知识,就利用先验来选择符合数据分布的核函数;如果不知道的话,通常使用交叉验证1的方法,来试用不同的核函数,误差最小的即为效果最好的核函数,或者也可以将多个核函数结合起来,形成混合核函数。在吴恩达的课上,也曾经给出过一系列的选择核函数的方法:
如果特征的数量大到和样本数量差不多,则选用LR或者线性核的SVM; 如果特征的数量小,样本的数量正常,则选用SVM+高斯核函数;
如果特征的数量小,而样本的数量很大,则需要手工添加一些特征从而变成第一种情况。
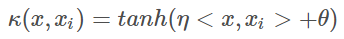
其中核函数能被拆开的充要条件:(详细证明可以去看泛函分析里的Mercer’s Theorem)
1.K(X1,X2) = K(X2,X1) (交换性)
2.任意一个Ci(常数),Xi(向量) (i = 1~N),有: (半正定性)
∑
i
=
1
N
∑
j
=
1
N
C
i
C
j
≥
0
\sum ^{N}_{i=1}\ \sum ^{N}_{j=1}C _{i} C _{j}\geq 0
∑i=1N ∑j=1NCiCj≥0
在已知了核函数的情况下,接下来要做的是去解上面的优化问题。
原问题与对偶问题:
首先提提优化理论的知识:
原问题:
最小化:f(w)
限制条件:
.
g
i
(
w
)
≤
0
g_{i}(w)\leq0
gi(w)≤0 (i = 1~K)
.
h
i
(
w
)
=
0
h_{i}(w)=0
hi(w)=0 (i = 1~M)
对偶问题:
1.定义:
L(w,
α
\alpha
α,
β
\beta
β) =
f
(
w
)
f(w)
f(w)+
∑
i
=
1
K
α
i
g
i
(
w
)
+
∑
i
=
1
M
β
i
h
i
(
w
)
\sum ^{K}_{i=1}\alpha_{i} g_{i}(w)+ \sum ^{M}_{i=1}\beta_{i}h_{i}(w)
∑i=1Kαigi(w)+∑i=1Mβihi(w)
也可以写成向量形式 = f(w) +
∑
i
=
1
K
α
i
T
g
i
(
w
)
+
∑
i
=
1
M
β
i
T
h
i
(
w
)
\sum ^{K}_{i=1}\alpha_{i}^T g_{i}(w)+ \sum ^{M}_{i=1}\beta_{i}^Th_{i}(w)
∑i=1KαiTgi(w)+∑i=1MβiThi(w)
2.对偶问题的定义:
最大化:
θ
(
α
,
β
)
=
i
n
f
{
L
(
w
,
α
,
β
)
}
\theta(\alpha,\beta) = inf\left\{ L(w,\alpha,\beta)\right\}
θ(α,β)=inf{L(w,α,β)}
在限定
α
\alpha
α,
β
\beta
β取值的情况下,去遍历所有的w,来求最小值。相当于对所有的w求最小值,再在外面针对所有的
α
\alpha
α,
β
\beta
β求最大值
限制条件
α
i
≥
0
\alpha_{i}\geq0
αi≥0 ( i= 1~K)
原问题与对偶问题的关系:
定理:如果
w
∗
w^*
w∗ 是原问题的解,而
α
∗
\alpha^*
α∗,
β
∗
\beta^*
β∗是对偶问题的解,
则有:
f
(
w
∗
)
≥
θ
(
α
∗
,
β
∗
)
f(w^*) \geq \theta(\alpha^*,\beta^*)
f(w∗)≥θ(α∗,β∗)
证明:
θ
(
α
∗
,
β
∗
)
=
i
n
f
{
L
(
w
,
α
∗
,
β
∗
)
}
≤
L
(
w
∗
,
α
∗
,
β
∗
)
\theta(\alpha^*,\beta^*) = inf\left\{ L(w,\alpha^*,\beta^*)\right\}\leq L(w^*,\alpha^*,\beta^*)
θ(α∗,β∗)=inf{L(w,α∗,β∗)}≤L(w∗,α∗,β∗)
前面一项是最小值,必定小于等于某一个特定的w所带入得到的值。
而
L
(
w
∗
,
α
∗
,
β
∗
)
=
f
(
w
)
+
∑
i
=
1
K
α
i
g
i
(
w
)
+
∑
i
=
1
M
β
i
h
i
(
w
)
L(w^*,\alpha^*,\beta^*) = f(w) + \sum ^{K}_{i=1}\alpha_{i} g_{i}(w)+ \sum ^{M}_{i=1}\beta_{i}h_{i}(w)
L(w∗,α∗,β∗)=f(w)+∑i=1Kαigi(w)+∑i=1Mβihi(w)
又因为已经是原问题的解了,即满足原问题中的限制条件:
.
g
i
(
w
)
≤
0
g_{i}(w)\leq0
gi(w)≤0 (i = 1~K)
.
h
i
(
w
)
=
0
h_{i}(w)=0
hi(w)=0 (i = 1~M)
将限制条件带入上式即可得到:
f
(
w
∗
)
≥
θ
(
α
∗
,
β
∗
)
f(w^*) \geq \theta(\alpha^*,\beta^*)
f(w∗)≥θ(α∗,β∗)
原问题与对偶问题的间距:
定义:G =
f
(
w
∗
)
−
θ
(
α
∗
,
β
∗
)
≥
0
f(w^*) - \theta(\alpha^*,\beta^*) \geq 0
f(w∗)−θ(α∗,β∗)≥0
G叫做原问题与对偶问题的间距
(对于某些特定优化问题,可以证明:G = 0)
强对偶定理:
若
f
(
w
)
f(w)
f(w)为凸函数,且
g
(
w
)
=
A
w
+
b
g(w) = Aw +b
g(w)=Aw+b,
h
(
w
)
=
C
W
+
d
h(w) = CW+d
h(w)=CW+d,则此优化问题的原问题与对偶问题间距为0,即:
f
(
w
∗
)
=
θ
(
α
∗
,
β
∗
)
f(w^*) = \theta(\alpha^*,\beta^*)
f(w∗)=θ(α∗,β∗)
KKT条件:
再回头看
f
(
w
∗
)
≥
θ
(
α
∗
,
β
∗
)
f(w^*) \geq \theta(\alpha^*,\beta^*)
f(w∗)≥θ(α∗,β∗)的证明过程,可以很容易的推出:
对于任意的 i = 1~K,(KKT条件)
α
i
∗
\alpha^*_{i}
αi∗ = 0
或者
g
i
∗
g^*_{i}
gi∗ = 0 (这两个为0时可以正好满足强对偶关系)
原问题化为对偶问题:
原问题:
首先,将之前处理非线性问题得到的列在这里:
最小化:
1
2
∥
W
∥
2
+
C
∑
i
=
1
N
ξ
i
\dfrac {1}{2}\left\| W\right\| ^{2}+C\sum ^{N}_{i=1}\xi _{i}
21∥W∥2+C∑i=1Nξi
限制条件:
a.
y
i
⋅
(
W
T
⋅
φ
(
x
i
)
+
b
)
≥
1
−
ξ
i
yi\cdot(\begin{aligned}W^{T }\cdot \varphi \left( x_{i}\right)+ b\end{aligned} )\geq 1-\xi _{i}
yi⋅(WT⋅φ(xi)+b)≥1−ξi
b.
ξ
i
≥
0
\xi _{i}\geq 0
ξi≥0 (i = 1~K)
最小化:f(w)
限制条件:
.
g
i
(
w
)
≤
0
g_{i}(w)\leq0
gi(w)≤0 (i = 1~K)
.
h
i
(
w
)
=
0
h_{i}(w)=0
hi(w)=0 (i = 1~M)
前面的非线性的对应着
f
(
w
)
f(w)
f(w),在这里可以证明该函数为凸函数,再对比限制条件,我们发现两边不太一样,因此需要稍微修改一下:
限制条件:
改变使
ξ
i
≤
0
\xi _{i}\leq 0
ξi≤0
因此这里也要变号
1
2
∥
W
∥
2
−
C
∑
i
=
1
N
ξ
i
\dfrac {1}{2}\left\| W\right\| ^{2}-C\sum ^{N}_{i=1}\xi _{i}
21∥W∥2−C∑i=1Nξi
再将非线性中的限制条件a修改一下:
0
≥
1
+
ξ
i
−
y
i
⋅
(
W
T
⋅
φ
(
x
i
)
+
b
)
0\geq 1+\xi _{i}-yi\cdot(\begin{aligned}W^{T }\cdot \varphi \left( x_{i}\right)+ b\end{aligned} )
0≥1+ξi−yi⋅(WT⋅φ(xi)+b)
和原问题就行对比,发现前面的 g i ( w ) ≤ 0 gi(w)\leq0 gi(w)≤0 分成了两个问题,对应着另外两个的两个限制条件,没有h(w)
对偶问题:
将上面式子带入L(w,
α
\alpha
α,
β
\beta
β) 得:
最大化:
θ
(
α
,
β
)
=
i
n
f
{
1
2
∥
W
∥
2
−
C
∑
i
=
1
N
ξ
i
+
∑
i
=
1
N
α
i
[
1
+
ξ
i
−
y
i
⋅
(
W
T
⋅
φ
(
x
i
)
+
b
)
]
+
∑
i
=
1
N
β
i
ξ
i
}
\theta(\alpha,\beta) = inf\left\{ \dfrac {1}{2}\left\| W\right\| ^{2}-C\sum ^{N}_{i=1}\xi _{i}+ \sum ^{N}_{i=1}\alpha_{i}[1+\xi _{i}-yi\cdot(\begin{aligned}W^{T }\cdot \varphi \left( x_{i}\right)+ b\end{aligned} )] + \sum ^{N}_{i=1}\beta_{i}\xi _{i}\right\}
θ(α,β)=inf{21∥W∥2−C∑i=1Nξi+∑i=1Nαi[1+ξi−yi⋅(WT⋅φ(xi)+b)]+∑i=1Nβiξi}
(遍历所有的
w
,
ξ
i
,
b
w,\xi_{i},b
w,ξi,b,L(w,
α
\alpha
α,
β
\beta
β) 中的
α
\alpha
α对应这里面的
α
\alpha
α,
β
\beta
β,因为所有
α
\alpha
α在L中对应着不等式部分,L中的
β
\beta
β对应着等式部分,在这个式子中没有)
限制条件为:
α
i
≥
0
\alpha_{i} \geq 0
αi≥0
β
i
≥
0
\beta_{i}\geq0
βi≥0 (i = 1~N )
根据拉格朗日乘子法,对原方程求偏导,让三个偏导为0
对向量求导定义:
∂
f
∂
W
=
[
∂
f
∂
W
i
]
\dfrac {\partial f}{\partial W} =\left[ \dfrac {\partial f}{\partial W_{i} }\right]
∂W∂f=[∂Wi∂f] (i = 1~N) (应该是竖着N个,但我这里不方便写)
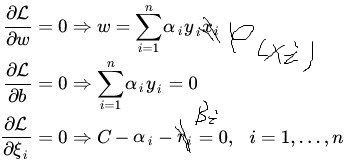
(上图中的xi应该改为
φ
(
X
i
)
\varphi \left( X_{i}\right)
φ(Xi),ri应该为
β
i
\beta_{i}
βi)
当上面条件满足时,达到最小。因此,将上式带入即可:
可以化简得到:
θ
(
α
,
β
)
=
∑
i
=
1
N
α
i
+
1
2
∥
W
∥
2
−
∑
i
=
1
N
α
i
y
i
W
T
φ
(
X
i
)
\theta(\alpha,\beta) = \sum ^{N}_{i=1}\alpha_{i} + \dfrac {1}{2}\left\| W\right\| ^{2} -\sum ^{N}_{i=1}\alpha_{i}y_iW^T\varphi_{(Xi)}
θ(α,β)=∑i=1Nαi+21∥W∥2−∑i=1NαiyiWTφ(Xi)
其中:
1
2
∥
W
∥
2
\dfrac {1}{2}\left\| W\right\| ^{2}
21∥W∥2 =
1
2
W
T
W
=
1
2
∑
i
=
1
N
∑
j
=
1
N
α
i
α
j
y
i
y
j
φ
(
X
i
)
T
φ
(
X
j
)
\dfrac {1}{2} W^T W=\dfrac {1}{2}\sum ^{N}_{i=1}\sum ^{N}_{j=1}\alpha_{i}\alpha_{j}y_{i}y{j}\varphi_{(Xi)}^T\varphi_{(Xj)}
21WTW=21∑i=1N∑j=1Nαiαjyiyjφ(Xi)Tφ(Xj)
φ
(
X
i
)
T
φ
(
X
j
)
\varphi_{(Xi)}^T\varphi_{(Xj)}
φ(Xi)Tφ(Xj) 恰好是K(Xi,Xj),核函数,消掉了
φ
\varphi
φ
另一项:
∑
i
=
1
N
α
i
y
i
W
T
φ
(
X
i
)
=
∑
i
=
1
N
∑
j
=
1
N
α
i
α
j
y
i
y
j
φ
(
X
i
)
T
φ
(
X
j
)
\sum ^{N}_{i=1}\alpha_{i}y_iW^T\varphi_{(Xi)} = \sum ^{N}_{i=1}\sum ^{N}_{j=1}\alpha_{i}\alpha_{j}y_iy_j\varphi_{(Xi)}^T\varphi_{(Xj)}
∑i=1NαiyiWTφ(Xi)=∑i=1N∑j=1Nαiαjyiyjφ(Xi)Tφ(Xj)
这里又恰好有核函数,可以将
φ
(
X
i
)
T
φ
(
X
j
)
\varphi_{(Xi)}^T\varphi_{(Xj)}
φ(Xi)Tφ(Xj)换成K(XI,Xj)
带入
θ
\theta
θ得:
最大化:
θ
(
α
,
β
)
=
∑
i
=
1
N
α
i
−
1
2
∑
i
=
1
N
∑
j
=
1
N
α
i
α
j
y
i
y
j
K
(
X
i
,
X
j
)
\theta(\alpha,\beta) = \sum ^{N}_{i=1}\alpha_{i} -\dfrac {1}{2}\sum ^{N}_{i=1}\sum ^{N}_{j=1}\alpha_{i}\alpha_{j}y_iy_jK(Xi,Xj)
θ(α,β)=∑i=1Nαi−21∑i=1N∑j=1NαiαjyiyjK(Xi,Xj)
限制条件:
- 0 ≤ α ≤ C 0\leq\alpha\leq C 0≤α≤C
- ∑ i = 1 N α i y i = 0 \sum^{N}_{i = 1}\alpha_iy_i =0 ∑i=1Nαiyi=0
由之前的限制条件 α i ≥ 0 \alpha_{i} \geq 0 αi≥0 , β i ≥ 0 \beta_{i}\geq0 βi≥0 加上上面求偏导时得到的 α i + β i = C \alpha_i+\beta_i = C αi+βi=C可以推出限制条件1,第二个限制条件和之前的相同
这个算法还有一点非常巧妙,在最后我们甚至可以不需要知道 W W W
回到问题的最开始:
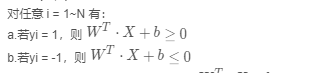
将X换成
φ
(
X
)
\varphi(X)
φ(X)
W
T
⋅
φ
(
X
)
=
∑
i
=
1
N
[
α
i
y
i
φ
(
X
i
)
]
T
φ
(
X
)
=
∑
i
=
1
N
α
i
y
i
K
(
X
i
,
X
)
W^{T }\cdot \varphi (X_{})= \sum^{N}_{i = 1}[\alpha_iyi\varphi{(Xi)}]^T\varphi_{(X)} =\sum^{N}_{i = 1}\alpha_iyiK(Xi,X)
WT⋅φ(X)=∑i=1N[αiyiφ(Xi)]Tφ(X)=∑i=1NαiyiK(Xi,X)
这里就成功的将W转换为其他参数了
而常数b则需要用的KKT条件了:
KKT:
对于任意的 i = 1~K,(KKT条件)
α
i
∗
\alpha^*_{i}
αi∗ = 0
或者
g
i
∗
g^*_{i}
gi∗ = 0
这里将最开始带入L时得到的关系式子再复制过来:
θ
(
α
,
β
)
=
i
n
f
{
1
2
∥
W
∥
2
−
C
∑
i
=
1
N
ξ
i
+
∑
i
=
1
N
α
i
[
1
+
ξ
i
−
y
i
⋅
(
W
T
⋅
φ
(
x
i
)
+
b
)
]
+
∑
i
=
1
N
β
i
ξ
i
}
\theta(\alpha,\beta) = inf\left\{ \dfrac {1}{2}\left\| W\right\| ^{2}-C\sum ^{N}_{i=1}\xi _{i}+ \sum ^{N}_{i=1}\alpha_{i}[1+\xi _{i}-yi\cdot(\begin{aligned}W^{T }\cdot \varphi \left( x_{i}\right)+ b\end{aligned} )] + \sum ^{N}_{i=1}\beta_{i}\xi _{i}\right\}
θ(α,β)=inf{21∥W∥2−C∑i=1Nξi+∑i=1Nαi[1+ξi−yi⋅(WT⋅φ(xi)+b)]+∑i=1Nβiξi}
(遍历所有的
w
,
ξ
i
,
b
w,\xi_{i},b
w,ξi,b,L(w,
α
\alpha
α,
β
\beta
β) 中的
α
\alpha
α对应这里面的
α
\alpha
α
与KKT相对照,我们可以得到:
1.要么
β
i
=
0
\beta_i = 0
βi=0 ,要么
ξ
i
=
0
\xi_{i} = 0
ξi=0
2.要么
α
i
=
0
\alpha_i = 0
αi=0 ,要么
1
+
ξ
i
−
y
i
⋅
(
W
T
⋅
φ
(
x
i
)
+
b
)
=
0
1+\xi _{i}-yi\cdot(\begin{aligned}W^{T }\cdot \varphi \left( x_{i}\right)+ b\end{aligned} ) =0
1+ξi−yi⋅(WT⋅φ(xi)+b)=0
取一个
0
<
α
i
<
C
0<\alpha_i<C
0<αi<C,即
β
i
>
0
\beta_i >0
βi>0(当然,也可以取所有,再求b平均值,得到的b值更准确)
此时
ξ
i
=
0
\xi_{i} = 0
ξi=0,
1
+
ξ
i
−
y
i
⋅
(
W
T
⋅
φ
(
x
i
)
+
b
)
=
0
1+\xi _{i}-yi\cdot(\begin{aligned}W^{T }\cdot \varphi \left( x_{i}\right)+ b\end{aligned} ) =0
1+ξi−yi⋅(WT⋅φ(xi)+b)=0
而之前又推出了
W
T
⋅
φ
(
X
)
=
∑
i
=
1
N
[
α
i
y
i
φ
(
X
i
)
]
T
φ
(
X
)
=
∑
i
=
1
N
α
i
y
i
K
(
X
i
,
X
)
W^{T }\cdot \varphi (X_{})= \sum^{N}_{i = 1}[\alpha_iyi\varphi{(Xi)}]^T\varphi_{(X)} =\sum^{N}_{i = 1}\alpha_iyiK(Xi,X)
WT⋅φ(X)=∑i=1N[αiyiφ(Xi)]Tφ(X)=∑i=1NαiyiK(Xi,X)
因此只需带入解出来即可。
b
=
1
−
y
i
∑
i
=
1
N
α
i
y
i
K
(
X
i
,
X
)
y
i
b = \dfrac {1-y_i\sum^{N}_{i = 1}\alpha_iyiK(Xi,X)}{y_i}
b=yi1−yi∑i=1NαiyiK(Xi,X)
至此,结束。
sklearn.svm.SVC的简介:
sklearn.svm.SVC
(C=1.0, kernel=‘rbf’, degree=3, gamma=‘auto’, coef0=0.0, shrinking=True, probability=False,tol=0.001, cache_size=200, class_weight=None, verbose=False, max_iter=-1, decision_function_shape=None,random_state=None)
参数:
C:C-SVC的惩罚参数C?默认值是1.0
C越大,相当于惩罚松弛变量,希望松弛变量接近0,即对误分类的惩罚增大,趋向于对训练集全分对的情况,这样对训练集测试时准确率很高,但泛化能力弱。C值小,对误分类的惩罚减小,允许容错,将他们当成噪声点,泛化能力较强。
kernel :核函数,默认是rbf,可以是‘linear’, ‘poly’, ‘rbf’, ‘sigmoid’, ‘precomputed’
– 线性:u’v
– 多项式:(gammau’v + coef0)^degree
– RBF函数:exp(-gamma|u-v|^2)
– sigmoid:tanh(gammau’v + coef0)
degree :多项式poly函数的维度,默认是3,选择其他核函数时会被忽略。
gamma : ‘rbf’,‘poly’ 和‘sigmoid’的核函数参数。默认是’auto’,则会选择1/n_features
coef0 :核函数的常数项。对于‘poly’和 ‘sigmoid’有用。
probability :是否采用概率估计?.默认为False
shrinking :是否采用shrinking heuristic方法,默认为true
tol :停止训练的误差值大小,默认为1e-3
cache_size :核函数cache缓存大小,默认为200
class_weight :类别的权重,字典形式传递。设置第几类的参数C为weight*C(C-SVC中的C)
verbose :允许冗余输出?
max_iter :最大迭代次数。-1为无限制。
decision_function_shape :‘ovo’, ‘ovr’ or None, default=None3
random_state :数据洗牌时的种子值,int值
主要调节的参数有:C、kernel、degree、gamma、coef0。
参考书籍和博客以及一些书籍博客的推荐
《统计学习方法》第二版,李航;
《凸优化 》 Boyd
《数学分析 》 刘玉琏
《Machine Learning - A Probabilistic Perspective》 Kevin P. Murphy
《高等代数第四版》 北京大学数学系前代数小组 编
《PRML_Translation》 马春鹏编译
《支持向量机通俗导论(理解SVM的三层境界)》 https://blog.csdn.net/v_july_v/article/details/7624837
《深入理解拉格朗日乘子法(Lagrange Multiplier) 和KKT条件》 https://blog.csdn.net/lijil168/article/details/69395023
参考代码:https://github.com/wzyonggege/statistical-learning-method














 3361
3361











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









