







1 概述
大语言模型训练语料数量、上下文的限制、生成速度都用Token表示:
-
通义千问-7B使用超过2.4万亿tokens的数据进行预训练,这是用token来描述训练语料的规模。
-
模型后面带着8k、32k,就是指在生成响应或进行预测时最大文本长度。
-
评估大模型生成速度的TPS,指的是每秒输出token数。
可见,token在大模型领域是一个对文本数据的计量单位。
2 一个token能表示中文、英文的多少?
token是描述文本规模的一个中间层。
Token是指语言模型中用来表示中文汉字、英文单词、或中英文短语的符号。
2.1 Token的编码形式
每个Token在模型中会被转换成一个数字ID,这些ID对应于模型的词汇表中的条目。模型通过这些ID来识别文本数据,因为有一个全局的字典。
- 原句:“I have a dream.”
- Token化:[“I”, “have”, “a”, “dream.”]
- 数字ID化:[40, 617, 264, 8063, 13]
2.2 各个大模型的token计算器
一个具体的模型,使用了不同的编码方式,导致一个token能表示的文本词汇长短也有差异。
OpenAI官方文档中介绍:“1000个token通常代表750个英文单词或500个汉字。1 个token大约为 4 个字符或 0.75 个单词。”
OpenAI官方的token计算工具:
https://platform.openai.com/tokenizer
百度文心一言也提供了token计算器:
https://console.bce.baidu.com/support/#/tokenizer
阿里通义千问token计算器:
https://dashscope.console.aliyun.com/tokenizer
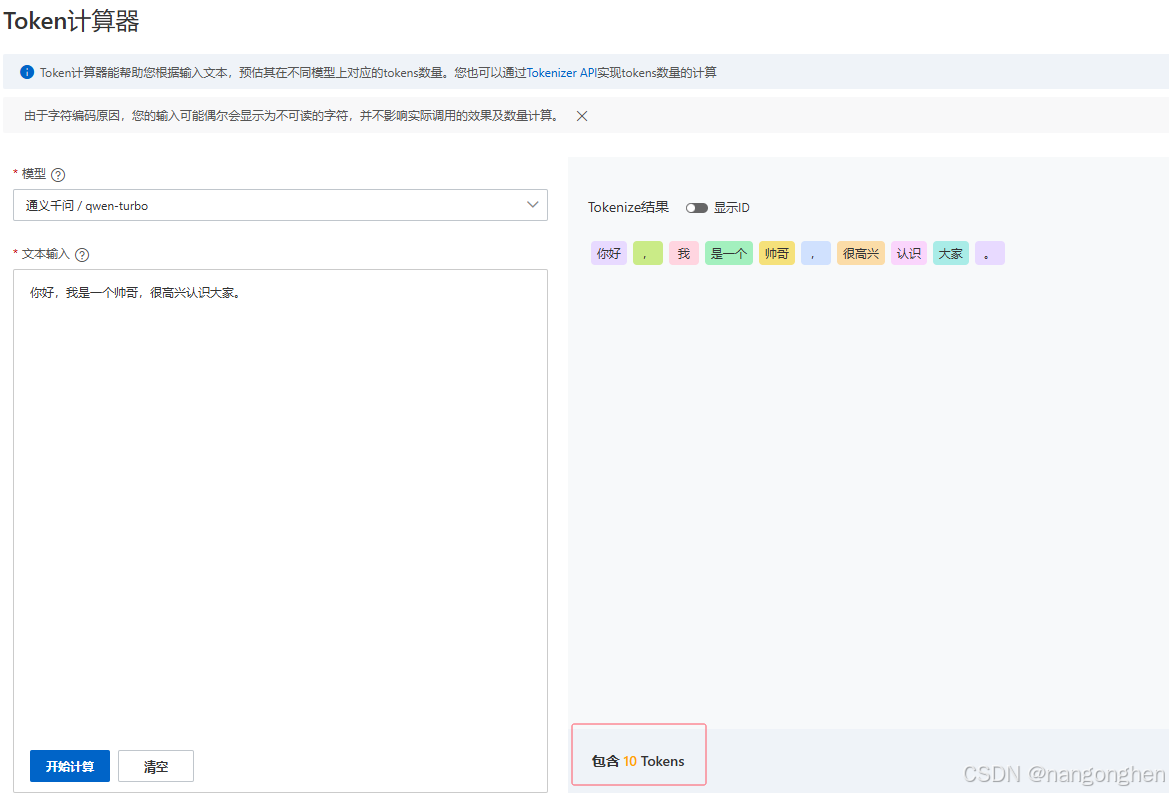
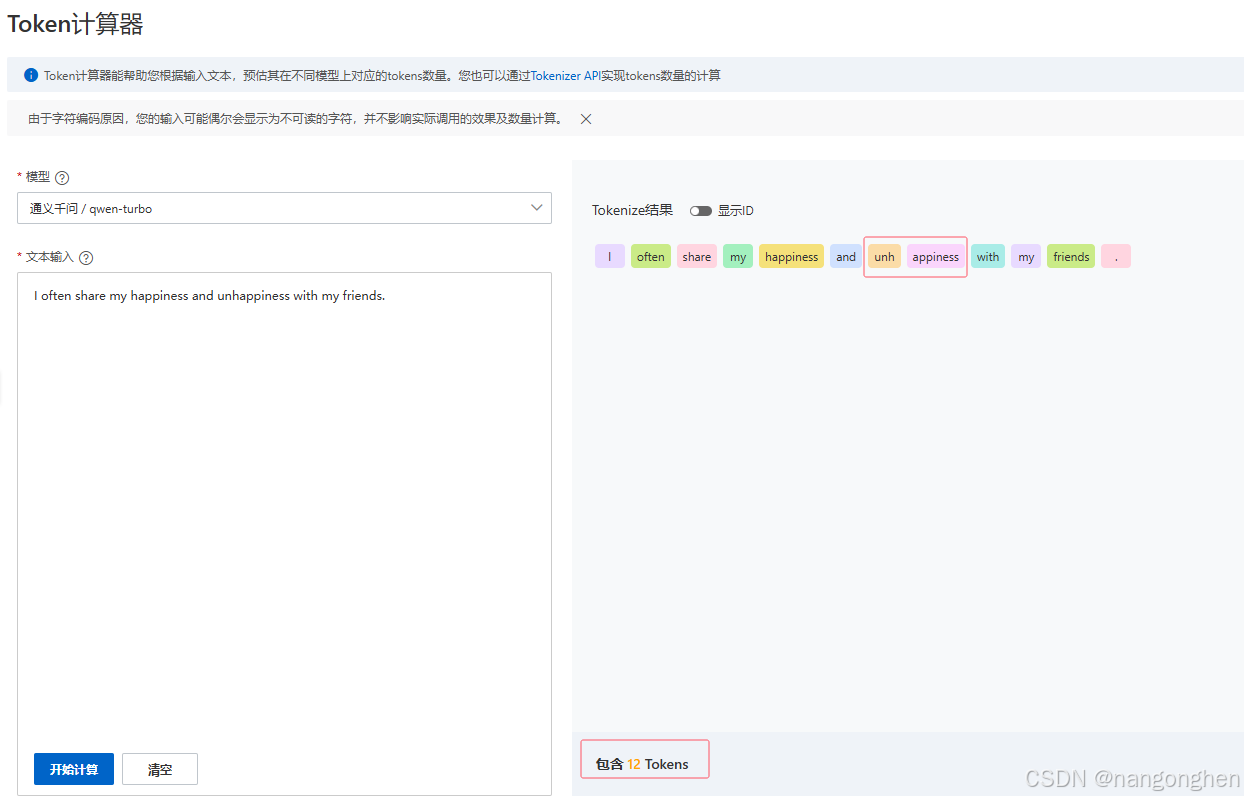 参考通义千问大模型,一个token的表示能力:
参考通义千问大模型,一个token的表示能力:
- 一个中文汉字(“我”)
- 一个小词组(“是一个”、“很高兴”、“帅哥”、“你好”)
- 一个英文单词(“friends”、 “share”)
- 一个英文sub单词(“unh”)
3 小结
token在大模型领域是一个对文本数据的计量单位,是描述文本规模的一个中间层。

















 987
987

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









