




 本文深入解析了DOM(文档对象模型)及其在W3C标准下的三个组成部分:核心DOM、XMLDOM和HTMLDOM,并通过实例展示了如何使用XPath进行HTML和XML文档的节点查询,包括路径、属性、逻辑运算等高级用法。
本文深入解析了DOM(文档对象模型)及其在W3C标准下的三个组成部分:核心DOM、XMLDOM和HTMLDOM,并通过实例展示了如何使用XPath进行HTML和XML文档的节点查询,包括路径、属性、逻辑运算等高级用法。
1.DOM
DOM 是 W3C(万维网联盟)的标准,DOM 定义了访问 HTML 和 XML 文档的标准,DOM 是 Document Object Model(文档对象模型)的缩写。
W3C DOM 标准被分为 3 个不同的部分:
| 核心 DOM | XML DOM | HTML DOM |
|---|---|---|
| 针对任何结构化文档的标准模型 | 针对 XML 文档的标准模型 | 针对 HTML 文档的标准模型 |
HTML DOM树
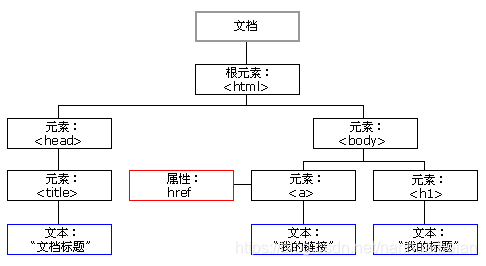
2.XPath
在介绍XPath之前,要先确保lxml已经安装成功,若出现问题,可参考
lxml安装详细记录
XPath,全称XML Path Language,即路径语言,它是一门XML文档中查找信息的语言。做爬虫时,完全可以用XPath来做相应的信息抽取。
- 常用规则
| 表达式 | 描述 |
|---|---|
nodename | 选取此节点的所有子节点 |
/ | 从根节点选取,选择直接子节点,不包含更小的后代(例如孙、从孙) |
// | 从当前路径选择文档中的节点,而不考虑它们的位置,包含所有后代 |
. | 选取当前节点 |
. . | 选取当前节点的父节点 |
@ | 选取属性 |
nodename:指定节点的节点名称。
# 测试代码test.html
<html>
<head>
<meta charset="UTF-8">
</head>
<body>
<div class='main-content'>
<h1 id="title">This is a test!</h1>
<p class="main-content ref">This is paragraph1</p>
<div>
<p>测试语句1</p>
</div>
</div>
<div>
<p>This is paragraph2</p>
<div>
<p class="ref">测试语句2</p>
</div>
</div>
</body>
</html>
#实例
from lxml import etree #首先导入lxml库的etree模块
import re
with open('test.html','r') as f:
c = f.read()
s =re.sub('\n','',c) #将所有的空格替换掉
tree = etree.HTML(s)
#测试‘/’的用法
test1 = tree.xpath('/html/body/div/p')
print(len(test1))
#测试‘//’的用法
test2 = tree.xpath('/html/body/div//p')
print(len(test2))
print(test1[1].text)
print(test2[3].text)
此时若只想得到第一个div下的p
from lxml import etree #首先导入lxml库的etree模块
import re
with open('test.html','r') as f:
c = f.read()
s =re.sub('\n','',c) #将所有的空格替换掉
tree = etree.HTML(s)
#在XPath里数组下标从1开始,切记!!!
test1 = tree.xpath('/html/body/div[1]/p')
#如果想得到第一个div下的所有节点
test2 = tree.xpath('/html/body/div[1]//*')
print(len(test1)) #返回结果: 1
print(test1[0].text) #返回结果:This is paragraph1
调用div节点下节点的另一种表达方法
from lxml import etree #首先导入lxml库的etree模块
import re
with open('test.html','r') as f:
c = f.read()
s =re.sub('\n','',c) #将所有的空格替换掉
tree = etree.HTML(s)
#得到第一个div下的p节点
test1 = tree.xpath('/html/body/div')[0].xpath('p')
print(len(test1)) #结果返回值:1
#此种形式下,不能通过以下方式调用重孙节点,返回值错误,返回的是所有节点P
#test1 = tree.xpath('/html/body/div')[0].xpath('//p')
在DOM树,以路径的方式查询节点,通过@符号来选取属性
from lxml import etree
import re
with open('test.html','r',encoding='UTF-8') as f:
c = f.read()
s =re.sub('\n','',c)
tree = etree.HTML(s)
#通过加入[@id="title"]限制节点id为'title'
test = tree.xpath('//*[@id="title"]') #返回结果是一个列表
test1 = tree.xpath('//*[@id="title"]')[0]
print(test) #返回结果:[<Element h1 at 0x25d0558>]
print(test1.attrib['id']) #返回结果:title
print(test1.text) #返回结果:This is a test!
=符号要求属性完全匹配,可以用contains方法来部分匹配
from lxml import etree
import re
with open('test.html','r',encoding='UTF-8') as f:
c = f.read()
s =re.sub('\n','',c)
tree = etree.HTML(s)
# "="符号表示完全匹配
test1 = tree.xpath('//p[@class="ref"]') #返回结果:[<Element p at 0x2360530>]
#contains方法可以实现部分匹配,只要class属性"ref"就会被匹配
test = tree.xpath('//p[contains(@class,"ref")]') #返回结果:[<Element p at 0x2360558>, <Element p at 0x2360530>]
print(test[0].attrib) #{'class': 'main-content ref'}
print(test[1].attrib) #{'class': 'ref'}
print(test[0].text) #This is paragraph1
print(test[1].text) #测试语句2
- 属性选择之逻辑运算
from lxml import etree
import re
with open('test.html','r',encoding='UTF-8') as f:
c = f.read()
s =re.sub('\n','',c)
tree = etree.HTML(s)
# 在所有标签中选取所有的p标签或h1标签的元素
test = tree.xpath('//p | //h1')
#与上式含义相同:test = tree.xpath('//*[self::p or self::h1]')
print(len(test)) #返回结果:5
print(test)
#返回结果:[<Element h1 at 0x820580>, <Element p at 0x820558>, <Element p at 0x820530>, <Element p at 0x8200f8>, <Element p at 0x81edf0>]
# 结果一定是按顺序输出的
for i in test:
print(i.text)


















 416
416

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











