







 本文是PyTorch教程的一部分,主要探讨了Optimizer优化器的作用和不同优化器的效果对比。通过创建和训练不同的神经网络,使用SGD、Adam、RMSprop和Adagrad等常见优化器,并通过训练损失图表展示它们的表现。实验结果显示,优化器的选择对模型性能有显著影响,建议根据具体任务选择合适的优化器。
本文是PyTorch教程的一部分,主要探讨了Optimizer优化器的作用和不同优化器的效果对比。通过创建和训练不同的神经网络,使用SGD、Adam、RMSprop和Adagrad等常见优化器,并通过训练损失图表展示它们的表现。实验结果显示,优化器的选择对模型性能有显著影响,建议根据具体任务选择合适的优化器。
Pytorch教程目录
Torch and Numpy
变量 (Variable)
激励函数
关系拟合(回归)
区分类型 (分类)
快速搭建法
批训练
加速神经网络训练
Optimizer优化器
卷积神经网络 CNN
卷积神经网络(RNN、LSTM)
RNN 循环神经网络 (分类)
RNN 循环神经网络 (回归)
自编码 (Autoencoder)
DQN 强化学习
生成对抗网络 (GAN)
为什么 Torch 是动态的
GPU 加速运算
过拟合 (Overfitting)
批标准化 (Batch Normalization)
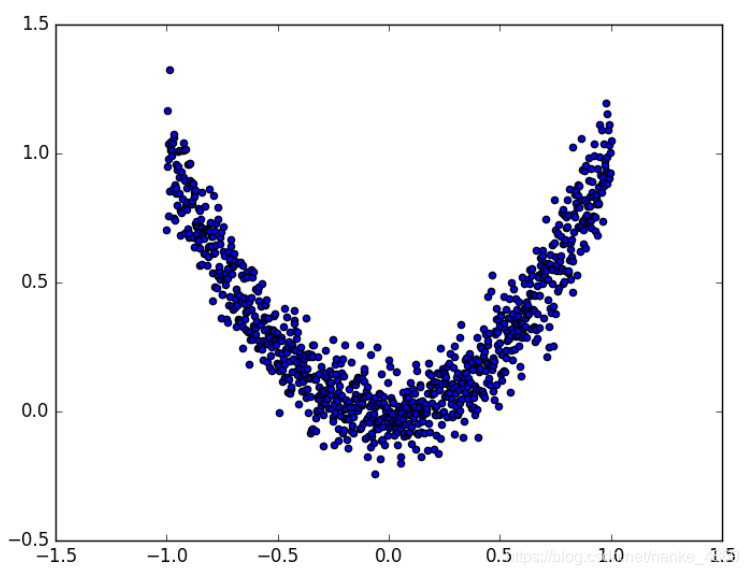
伪数据
为了对比各种优化器的效果, 我们需要有一些数据, 今天我们还是自己编一些伪数据, 这批数据是这样的:
import torch
import torch.utils.data as Data
import torch.nn.functional as F
import matplotlib.pyplot as plt
torch.manual_seed(1) # reproducible
LR = 0.01
BATCH_SIZE = 32
EPOCH = 12
# fake dataset
x = torch.unsqueeze(torch.linspace(-1, 1, 1000), dim=1)
y = x.pow(2) + 0.1*torch.normal(torch.zeros(*x.size()))
# plot dataset
plt.scatter(x.numpy(), y.numpy())
plt.show()
# 使用上节内容提到的 data loader
torch_dataset = Data.TensorDataset(x, y)
loader = Data.DataLoader(dataset=torch_dataset, batch_size=BATCH_SIZE, shuffle=True, num_workers=2,)
每个优化器优化一个神经网络
为了对比每一种优化器, 我们给他们各自创建一个神经网络, 但这个神经网络都来自同一个 Net 形式.
# 默认的 network 形式
class Net(torch.nn.Module):
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 711
711











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









