







NLP教程
TF_IDF
词向量
句向量
Seq2Seq 语言生成模型
CNN的语言模型
语言模型的注意力
Transformer 将注意力发挥到极致
ELMo 一词多义
GPT 单向语言模型
BERT 双向语言模型
NLP模型的多种应用
怎么了
不管是图片识别还是自然语言处理,模型都朝着越来越臃肿,越来越大的方向发展。 每训练一个大的模型,都会消耗掉数小时甚至数天的时间。我们并不希望浪费太多的时间在训练上,所以拿到一个预训练模型就十分重要了。 基于预训练模型,我们能够用较少的模型,较快的速度得到一个适合于我们自己数据的新模型,而且这个模型效果也不会很差。
所以预训练的核心价值就是:
- 手头只有小数据集,也能得到一个好模型;
- 训练速度大大提升,不用从零开始训练。
词向量有问题
传统使用skip gram 或者 CBOW 训练出来的词向量, 在ELMo看起来,是有问题的。ELMo的全称是 Embeddings from Language Models,他的主要目标是:找出词语放在句子中的意思。
具体展开,ELMo还是想用一个向量来表达词语,不过这个词语的向量会包含上下文的信息。
想要让模型给出的词向量拥有上下文信息。我们就在词向量中加上从前后文来的信息就好了,这就是ELMo最核心的思想。 那么ELMo是怎样训练,为什么这样训练又可以拿到前后文信息呢?
如果学习过RNN的同学,其实你很容易理解下面的内容,ELMo对你来说,只是另一种双向RNN架构。ELMo里有两个RNN(LSTM), 一个从前往后看句子,一个从后往前看句子,每一个词的向量表达,就是下面这几个信息的累积:
- 从前往后的前文信息;
- 从后往前的后文信息;
- 当前词语的词向量信息。
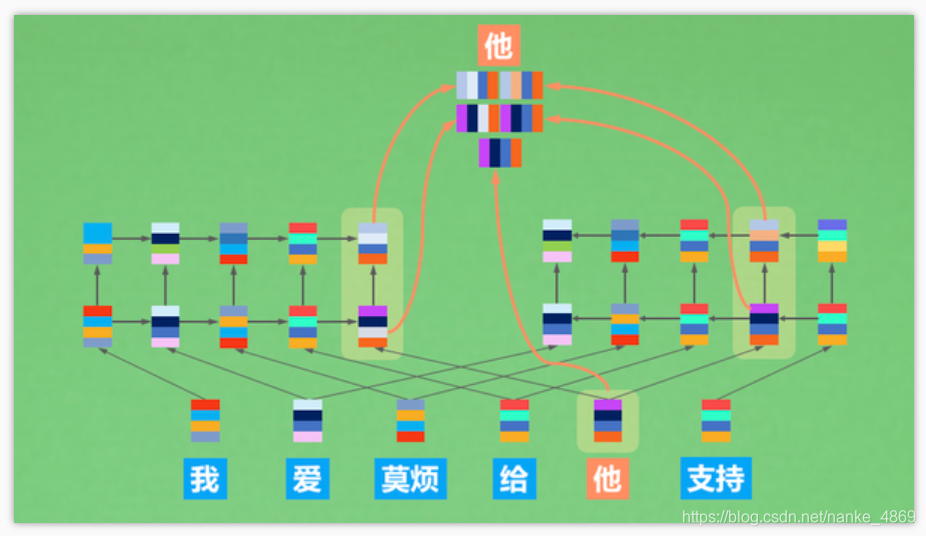
没错!就这么简单。在预训练模型中,EMLo应该是最简单的种类之一了。有了这些加入了前后文信息的词向量,模型就能提供这个词在句子中的意思了。
如何训练
一般来说,我们希望预训练模型都是在无监督的条件下被训练的。所谓NLP的无监督学习,实际上就是拿着网上一大堆论坛,wiki等文本, 用它们的前文预测后文,或者后文预测前文,或者两个一起混合预测。不管是 BERT还是GPT, 都是这样的方式,因为我们网上的无标签文本还是特别多的。 如果模型能理解人类在网上说话的方式,那么这个模型就学习到了人类语言的内涵。
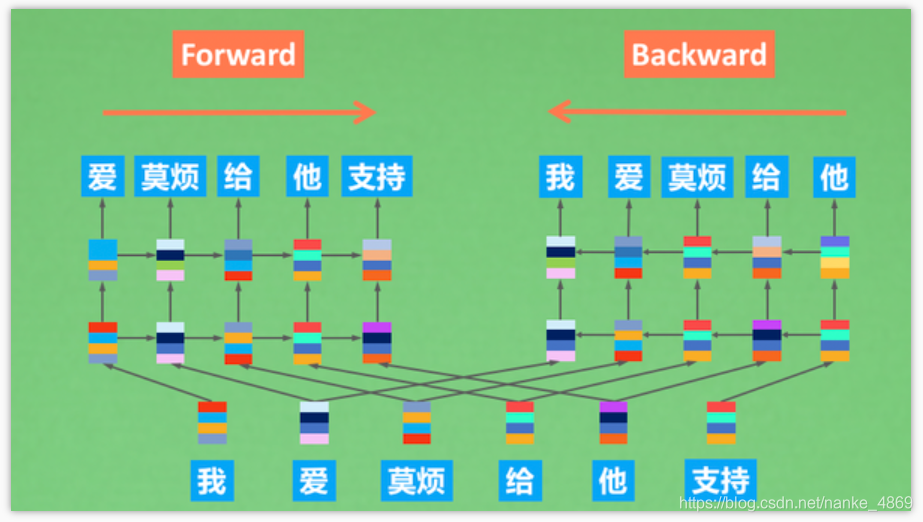
ELMo的训练,就是上面这种模式。它的前向LSTM预测后文的信息,后向LSTM预测前文的信息。训练一个顺序阅读者+一个逆序阅读者,在下游任务的时候, 分别让顺序阅读者和逆序阅读者,提供他们从不同角度看到的信息。这就是ELMo的训练和使用方法。
学习案例
这次的案例我们就上些真实点的数据,这样才好判断这种体量大点的预训练模型的优势在哪。 所以我挑选到了学术界上常用的 Microsoft Research Paraphrase Corpus (MRPC) 数据集来测试训练过程。 这个数据集的内容大概是用这种形式组织的。
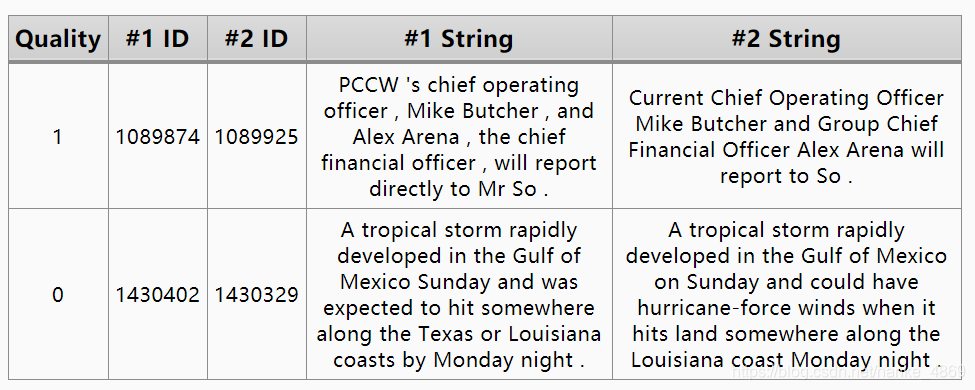
每行有两句话 #1 String 和 #2 String, 如果他们是语义相同的话,Quality 为1,反之为0。这份数据集可以做两件事:
- 两句合起来训练文本匹配;
- 两句拆开单独对待,理解人类语言,学一个语言模型。
这个教学中,我们在训练ELMo理解人类语言的时候,用的是无监督的方法训练第2种模式。让ELMo通读人类语言,然后在大数据中寻找人类说话的规律。 学完之后,模型就有对词语和句子有一定的理解能力了。
代码
这次我们主要需要构建一个正向的多层LSTM模型,一个反向的LSTM模型,在构建正向LSTM的时候,我相信大家应该都没什么问题,但是在做反向的时候,有一些小技巧可以说明一下。 另外,让模型做预测的时候也要稍微注意下,每次用上文预测的是紧接着的下一个词。
代码的训练模式和我们之前写的那些都非常接近,为了让你将重点放在学习模型上,我在utils.py 将数据处理相关的代码封装进了utils.MRPCSingle()这里,现在我们只需要直接调用就能自动下载数据并处理数据了。
def train(model, data, step):
for t in range(step):
seqs = data.sample(BATCH_SIZE) # 拿数据
loss, (fo, bo) = model.step(seqs) # 练数据,这里我让它返回了loss和前后向预测的logits
开启训练后,你就能看到类似这样的结果。
step: 0 | time: 1.52 | loss: 9.463
| tgt: <GO> hovan , a resident of trumbull , conn . , had worked as a bus driver since <NUM> and had no prior criminal record . <SEP>
| f_prd: atsb knew knew competition competition competition competition markup floors festivals merit merit merit korkuc korkuc korkuc fingerprinting grade grade car car nicky roush thoughts roush gain gain
| b_prd: stockwell stockwell stockwell mta mta mta mta mta mta mta tornadoes tornadoes tornadoes router router halliburton halliburton talked engaged ona db2 life rashid rashid ursel ursel
step: 80 | time: 8.37 | loss: 7.975
| tgt: <GO> the winner of the williams-mauresmo match will play the winner of justine henin-hardenne vs. chanda rubin . <SEP>
| f_prd: the , , , , , , , , , , , , , , , , , ,
| b_prd: , , , , , , , , , , , , , , , , , . <SEP> <SEP> <SEP> <SEP> <SEP> <SEP> <SEP> <SEP> <SEP> <SEP> <SEP> <SEP> <SEP> <SEP> <SEP> <SEP> <SEP> <SEP> <SEP>
...
step: 9840 | time: 8.35 | loss: 0.570
| tgt: <GO> montgomery was one of the first places to enact such a law , but many places , including new york city , now ban smoking in bars . <SEP>
| f_prd: the was being of the american places , enact such a law , but he places , including the york city , where ban smoking in bars . <SEP>
| b_prd: while montgomery <GO> one at the <NUM> places to enact such a <NUM> , but <NUM> places , including new york <NUM> , air bans smoking in <NUM> .
step: 9920 | time: 8.36 | loss: 0.543
| tgt: <GO> of personal vehicles , <NUM> percent are cars or station wagons , <NUM> percent vans or suvs , <NUM> percent light trucks . <SEP>
| f_prd: the the vehicle 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









