







目录
前言
文章性质:学习笔记 📖
视频教程:使用 Pytorch 搭建 U-Net 网络并基于 DRIVE 数据集训练(语义分割)- 3 dice 损失计算
主要内容:根据 视频教程 中提供的 U-Net 源代码(PyTorch),对 tain_and_val.py、dice_coefficient_loss.py、distributed_utils.py 文件进行大致讲解,简单介绍了如何计算 dice 损失值。
Preparation
├── src: 搭建U-Net模型代码
├── train_utils: 训练、验证以及多GPU训练相关模块
├── my_dataset.py: 自定义dataset用于读取DRIVE数据集(视网膜血管分割)
├── train.py: 以单GPU为例进行训练
├── train_multi_GPU.py: 针对使用多GPU的用户使用
├── predict.py: 简易的预测脚本,使用训练好的权重进行预测测试
└── compute_mean_std.py: 统计数据集各通道的均值和标准差
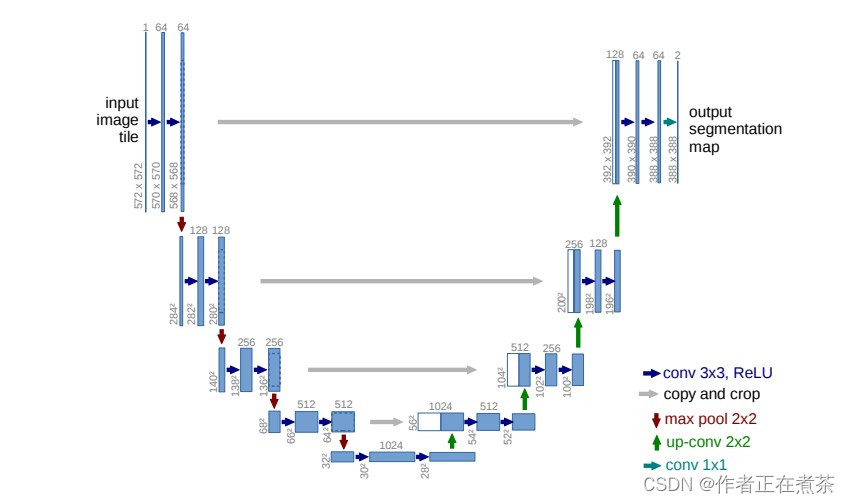
一、U-Net 网络结构图
原论文提供的 U-Net 网络结构图如下所示:
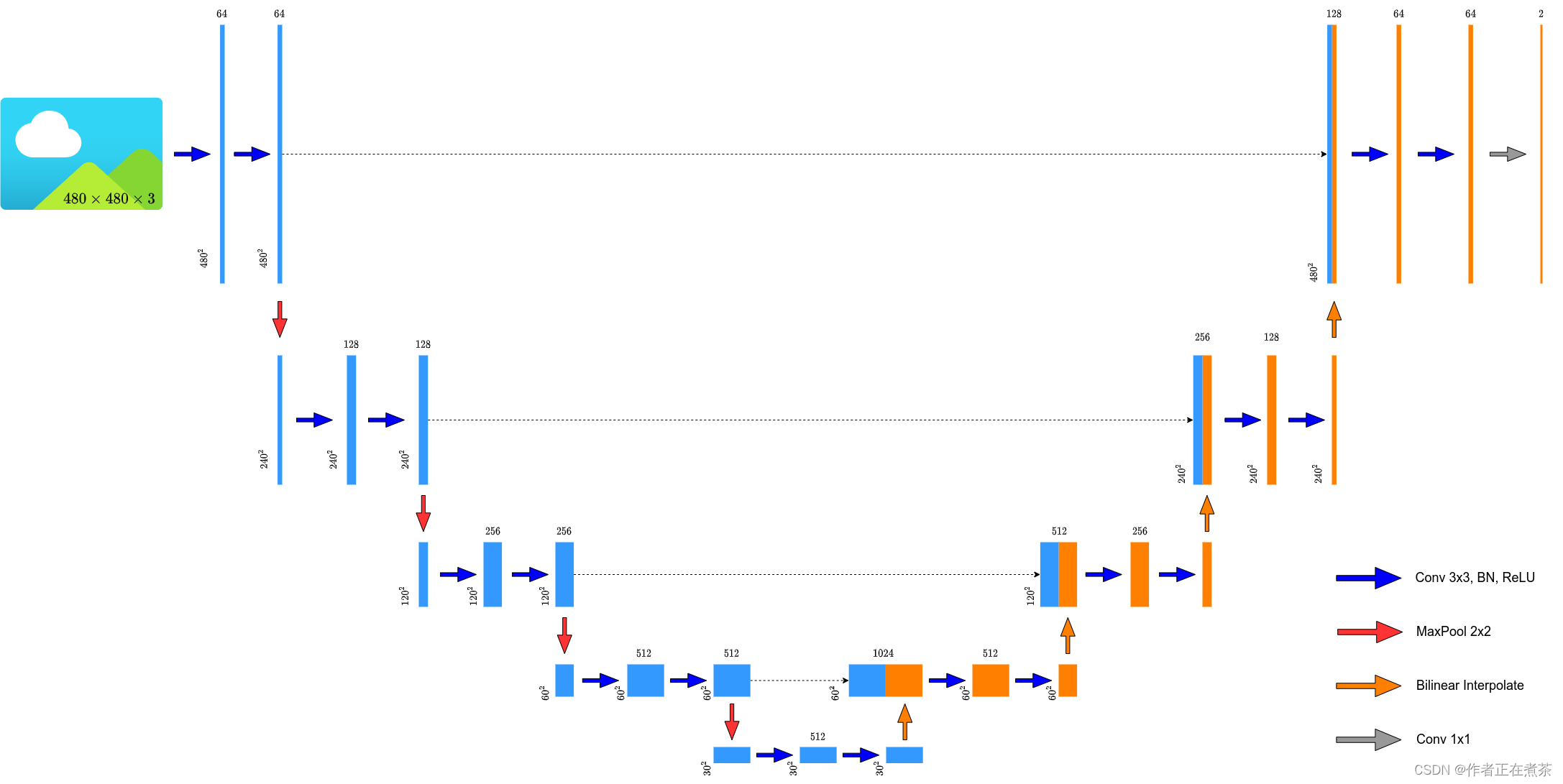
原论文中提供的 U-Net 网络结构所使用的卷积层会改变特征层的高和宽,而现在比较主流的方式是 不去改变输入特征层的高和宽 ,将转置卷积替换成简单的双线性插值进行上采样,所以霹雳吧啦重绘的 U-Net 网络结构图也是按照 双线性插值 进行绘制的,如下图所示:
二、Dice similarity coefficient
Dice similarity coefficient 用于度量两个集合的相似性,Dice 和 Dice Loss 的计算公式如下所示:
【说明】在语义分割任务中,X 和 Y 的范围都是在 [ 0 , 1 ] 之间的。

【说明】Dice 的分子就只看 前景 GT 标签中为 1 的位置,将 X 中对应位置的数值加起来乘以二。针对矩阵 Y 中为 1 的值,若其在矩阵 X 中对应位置的预测值越大, 越接近于 1 ,说明 预测的越准,Dice 系数就越大,损失就越小 ;若对应位置的预测值越小, 越接近于 0 ,说明 预测的不准,Dice 系数就越小,损失就越大 。通过误差反向传播之后,更倾向于预测值变得更大。
【注意】这里的 Dice 公式是针对训练过程中的,在验证过程中通常不是这样计算的,比如最终去预测的时候,我们针对每个像素一般都是直接去取它对应类别概率最大的那个类别,所以预测时的 X 并不是概率分数,应该只有零或者一两种情况,以上面这张图中的矩阵为例:
- 介于 0 和 0.5 之间的元素值比较小,属于背景的概率比前景大,因此取值为 0
- 介于 0.5 和 1 之间的元素值比较大,属于前景的概率比背景大,因此取值为 1
然后,我们再用和上面相同的方式计算 Dice 系数。
三、U-Net 网络源代码
阅前必读:本章节对 U-Net 网络源代码的讲解是以 criterion 函数和 evaluate 函数为主线展开的,整体上按照逻辑顺序进行讲述,二级标题名称只是为了提醒大家该去哪个文件中查看对应的函数与方法。
1、train_and_eval.py
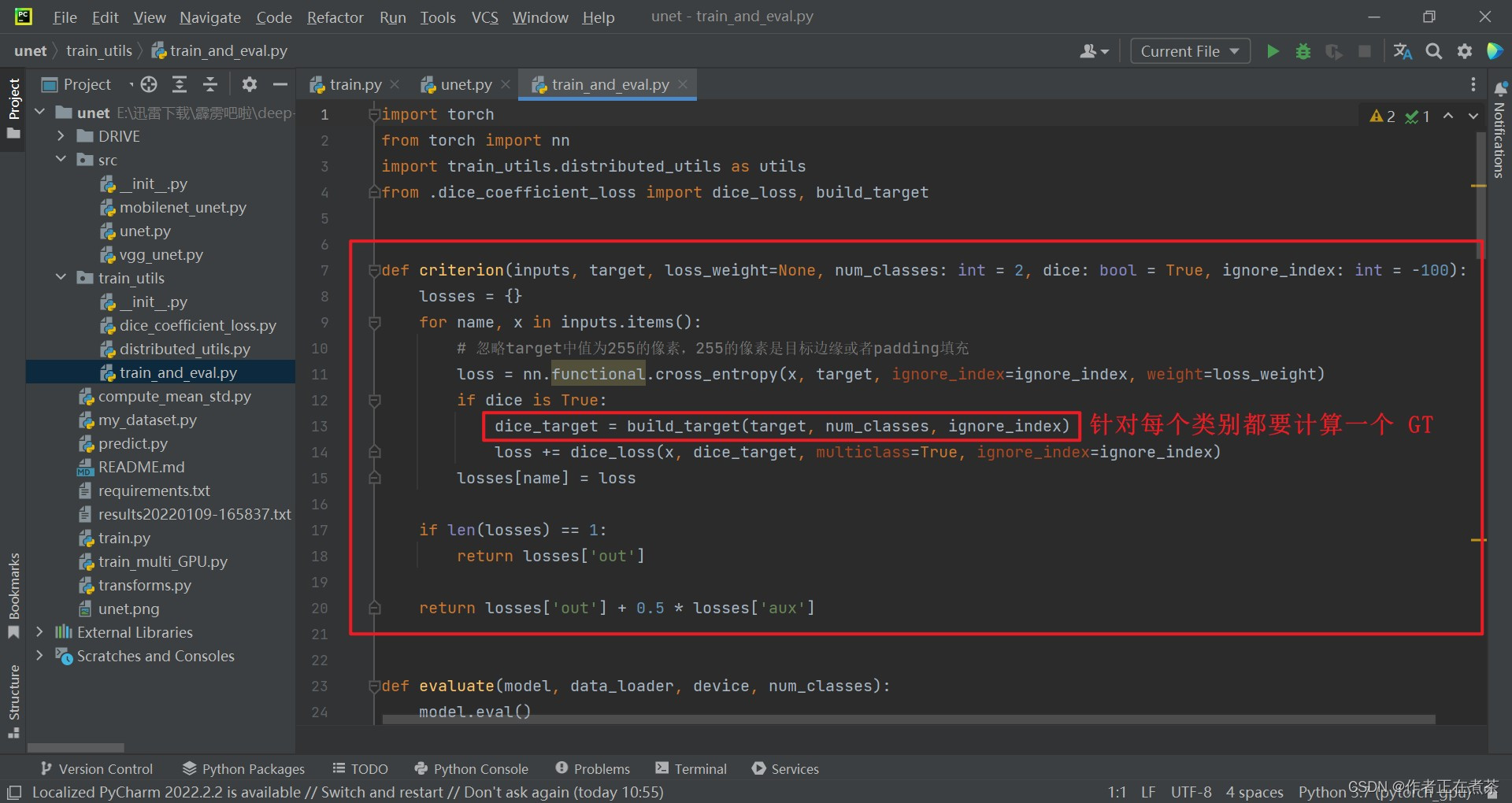
(1)criterion 函数
在 criterion 函数中,使用 nn.functional.cross_entropy 方法计算交叉熵损失,该方法传入的参数包括:
- x 是网络输出
- target 是目标标签
- ignore_index 指定需要忽略的像素值,默认为 -100
- weight 表示损失权重
接着判断 dice 的值是否为 True ,如果是的话,就调用 build_target 方法生成 Dice Loss 的目标标签 dice_target ,该方法传入的参数包括:
- target 是目标标签
- num_classes 是包含了背景的类别个数,默认为 2(背景+前景)
- ignore_index 指定需要忽略的像素值,默认为 -100
然后使用 dice_loss 方法计算 Dice Loss ,该方法传入的参数包括:
- x 是网络输出
- dice_target 是 Dice Loss 的目标标签
- multiclass 表示是否多类别
- ignore_index 指定需要忽略的像素值,默认为 -100
在 for 循环的最后,将每个网络输出的损失值保存到 losses 字典中。
在循环遍历结束后,判断 losses 字典长度为 1 ,是则返回 losses [ 'out' ] 值,否则返回 losses [ 'out' ] + 0.5 * losses [ 'aux' ] 值。
2、dice_coefficient_loss.py
(1)build_target 函数

【说明】计算 dice 系数时,是要针对各个类别分别计算其 dice 系数,然后求平均值,例如在上面这张图中,分别计算了背景 background 和前景 foreground 的 dice 系数,所以我们要分别针对每个类别去构建它的一个 GT ,关于如何构建,可以去看代码中的 build_target 方法。
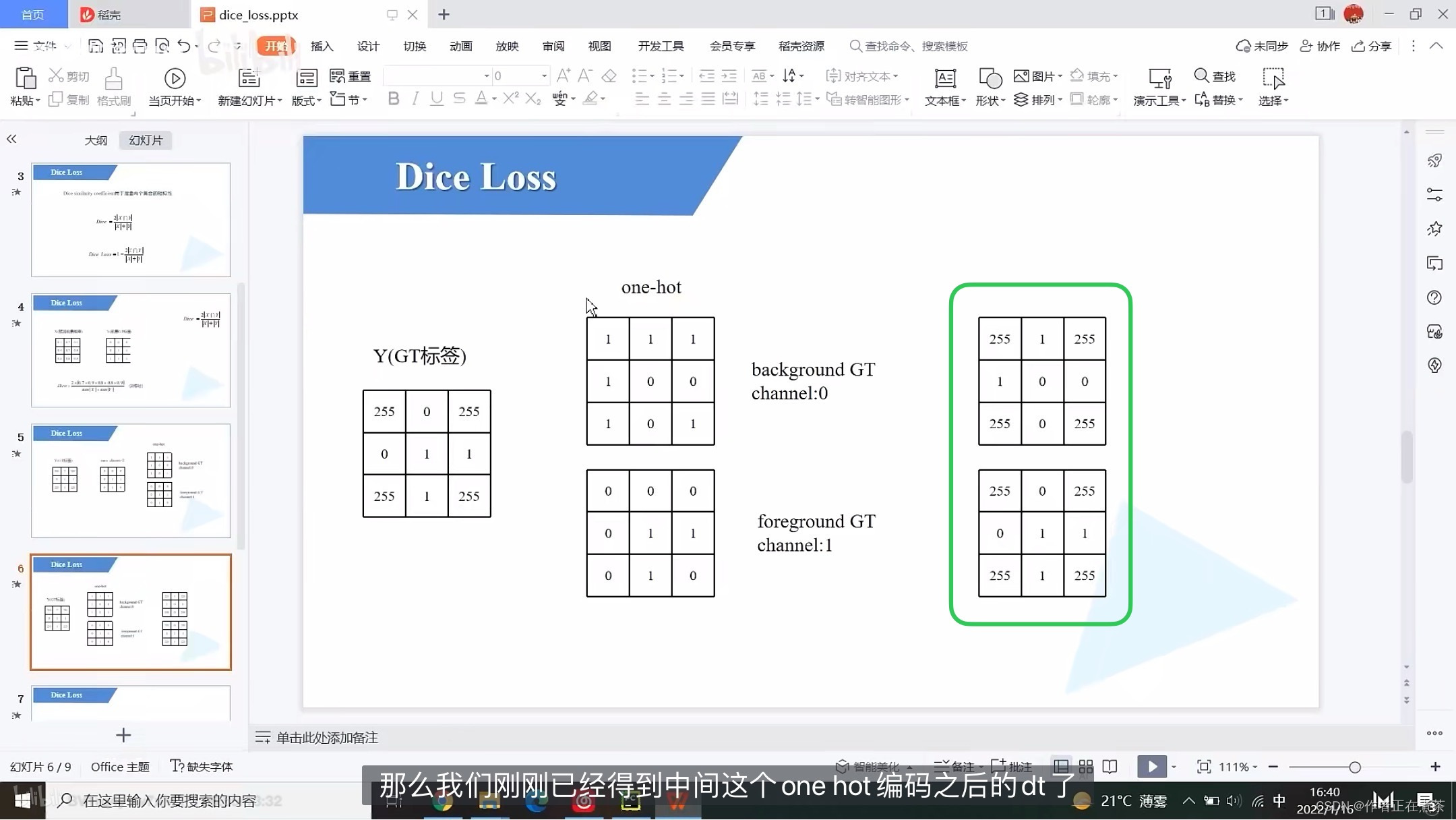
【说明】在上面这张图的示例中,因为 num_classes 为 2 ,所以只有背景和前景两个类别:
- 背景区域(0)对应的 one_hot 编码应该是 10 ,也就是说在 channel 0 上的像素值全都是 1 ,在 channel 1 上的像素值全都是 0 。
- 前景区域(1)对应的 one_hot 编码应该是 01 ,也就是说在 channel 0 上的像素值全都是 0 ,在 channel 1 上的像素值全都是 1 。
用 绿 框标出的两个矩阵对应的是两个通道,通过如上操作,我们就能将传入的最原始的 GT 转化成 针对每一个类别的 GT 。
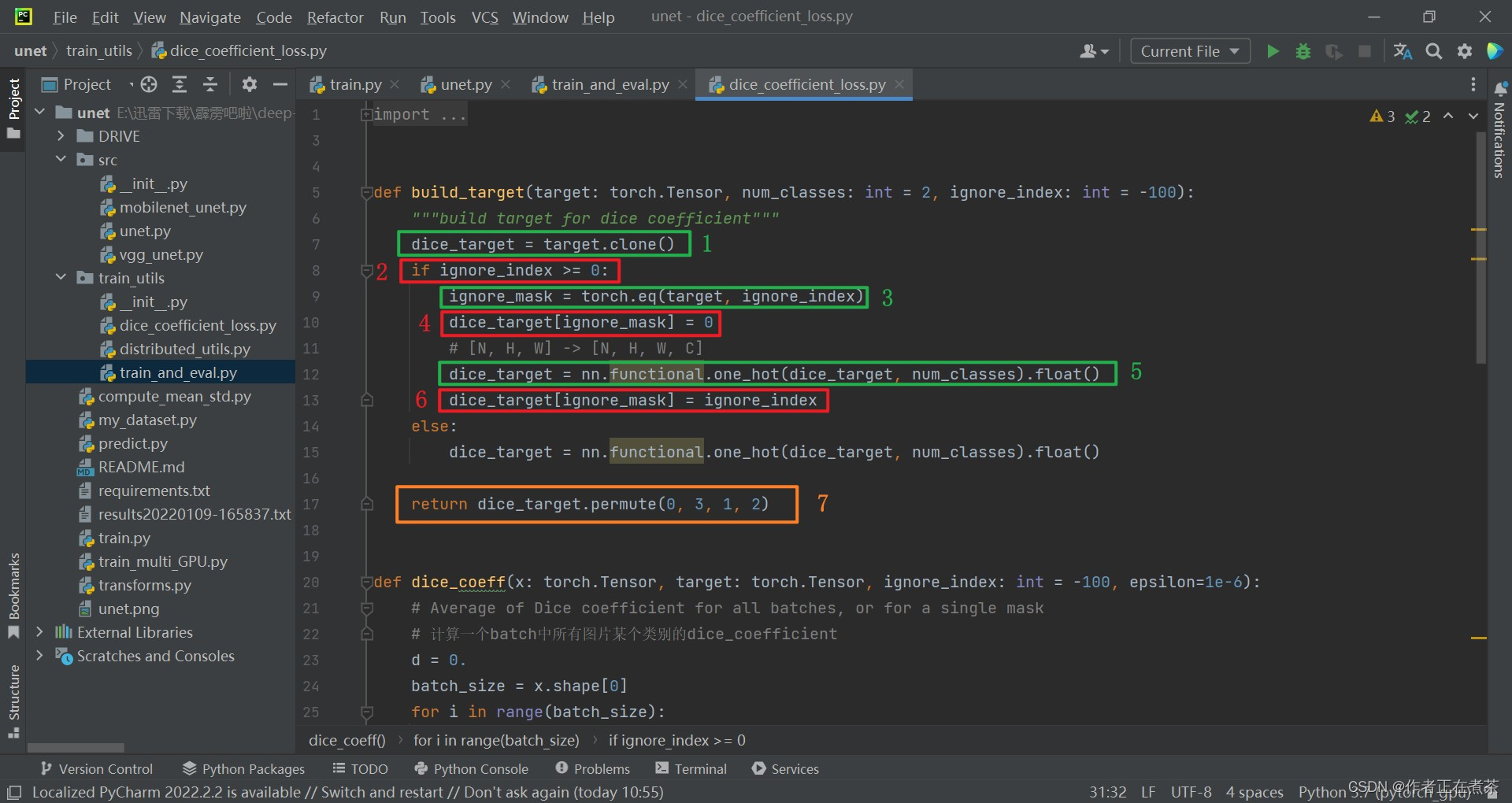
【代码解析】 针对 build_target 函数代码进行具体解析(结合上图):
- 先将 target 克隆给 dice_target ,这里的 target 就是之前图中的矩阵 Y ,也就是 GT
- 判断 ignore_index 是否大于等于 0 ,这里的 ignore_index 传入时默认为 -100 ,经 target 克隆后,有些区域的 ignore_index 设置为 255
- 通过 torch.eq 方法寻找 target 中所有等于 255 的像素的位置,记作 ignore_mask
- 再将 dice_target 中对应 255 区域的数据全部设置为 0
- 通过 torch 提供的 one_hot 方法将 dice_target 转化成 one_hot 编码的形式
- 将刚刚寻找到的对应 255 的区域的数值 填充回 255 ,这样我们在计算每一个类别的 dice coefficient 时同样去计算那些非 255 的区域
- 使用 permute 方法将 dice_target 的维度从 [ N, H, W, C ] 调整为 [ N, C, H, W ] ,并返回构建好的 dice_target
【注意】经过 one_hot 后由 [ batch,高度,宽度 ] 变成了 [ batch,高度,宽度,channel ] 。在 torch 当中,默认将 channel 放在索引为 1 的位置上,所以需要使用 permute 方法将 channel 维度的数据 3 移到索引为 1 的位置上来。最后 return 返回我们构建好的 target 。
3、train_and_eval.py
(1)criterion 函数
再回到 criterion 函数,将我们构建好的 target 以及网络预测的 x 传入到我们的 dice_lost 方法中去计算 dice_loss 损失。
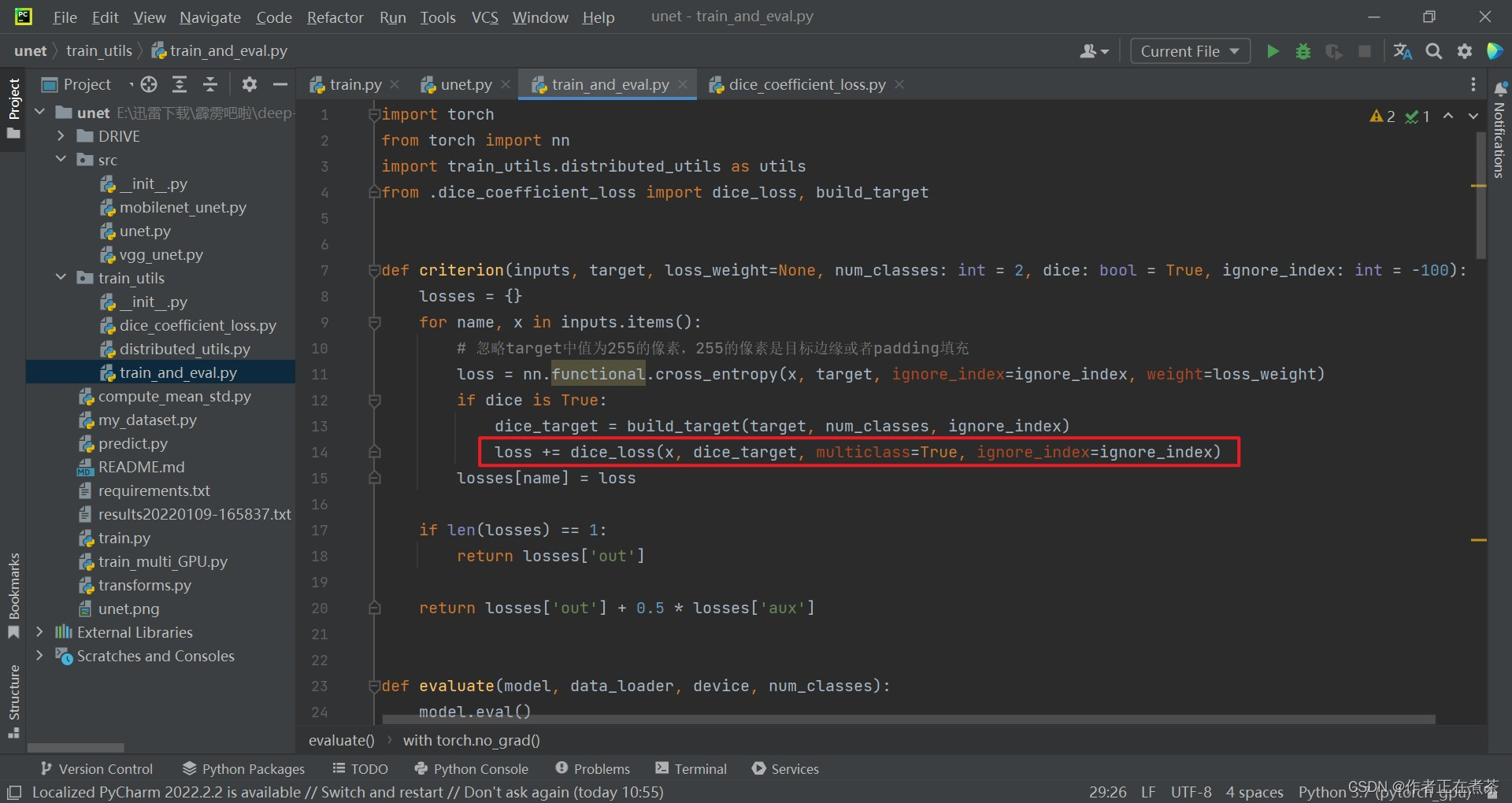
【说明】我们在 criterion 函数中调用 dice_loss 时传入的 multiclass=True ,意味着我们将分别去计算每个类别的 dice loss 。
4、dice_coefficient_loss.py
(1)dice_loss 函数
在 dice_loss 函数中先对预测值 x 在 channel 方向做一个 softmax 处理,就能得到每个像素针对每个类别的概率。如果传入的 multiclass 为 True 的话,就去采用 multiclass_dice_coeff 方法,否则采用 dice_coeff 方法。
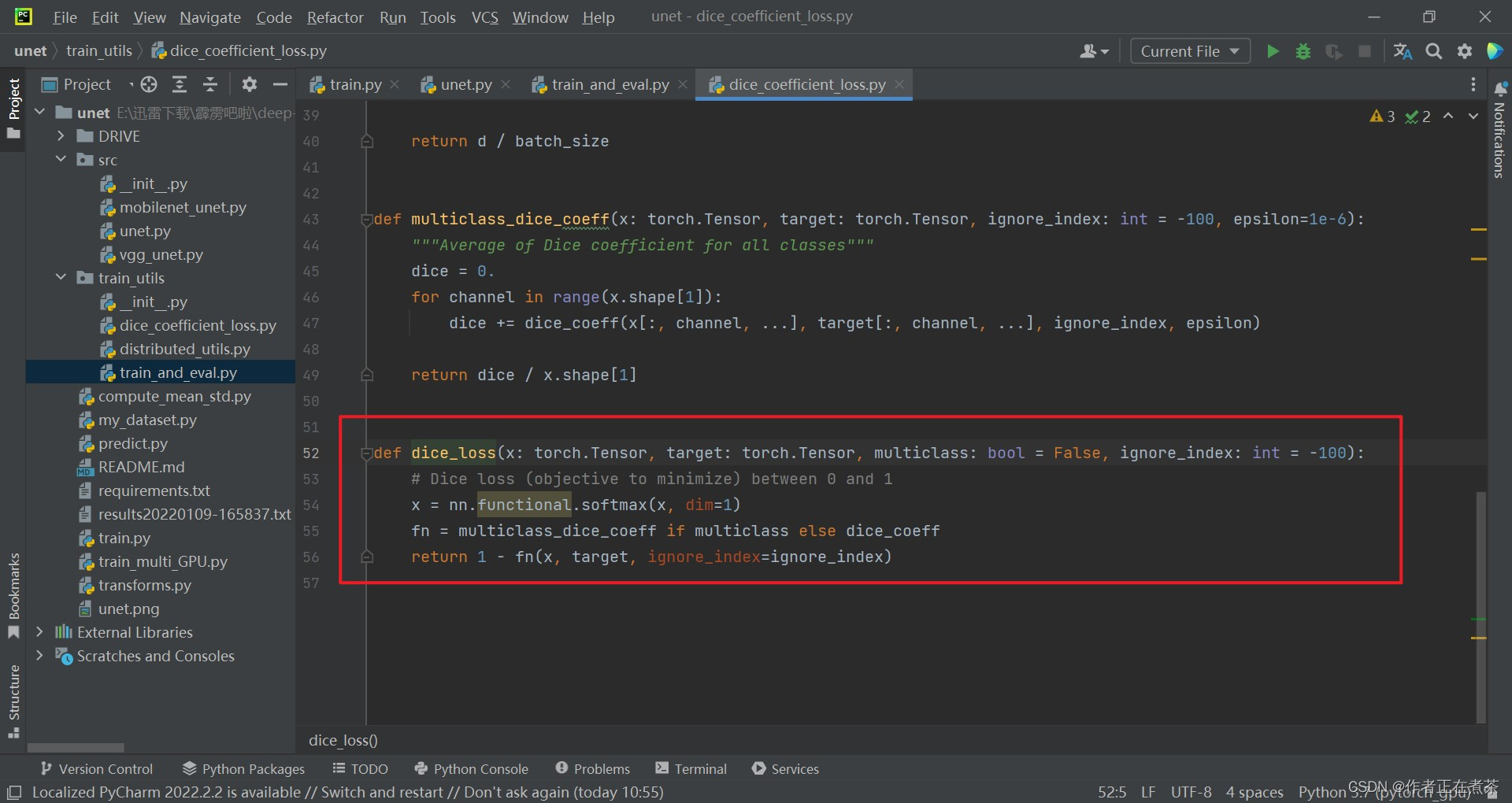
(2)multiclass_dice_coeff 函数
在 multiclass_dice_coeff 函数中,遍历 channel,也就是遍历每个类别的预测值和 target ,计算每个类别的 dice coefficient ,得到累加值 dice ,然后除以通道数,也就是类别个数 x.shape[1] ,得到所有类别的 dice coefficient 的均值。
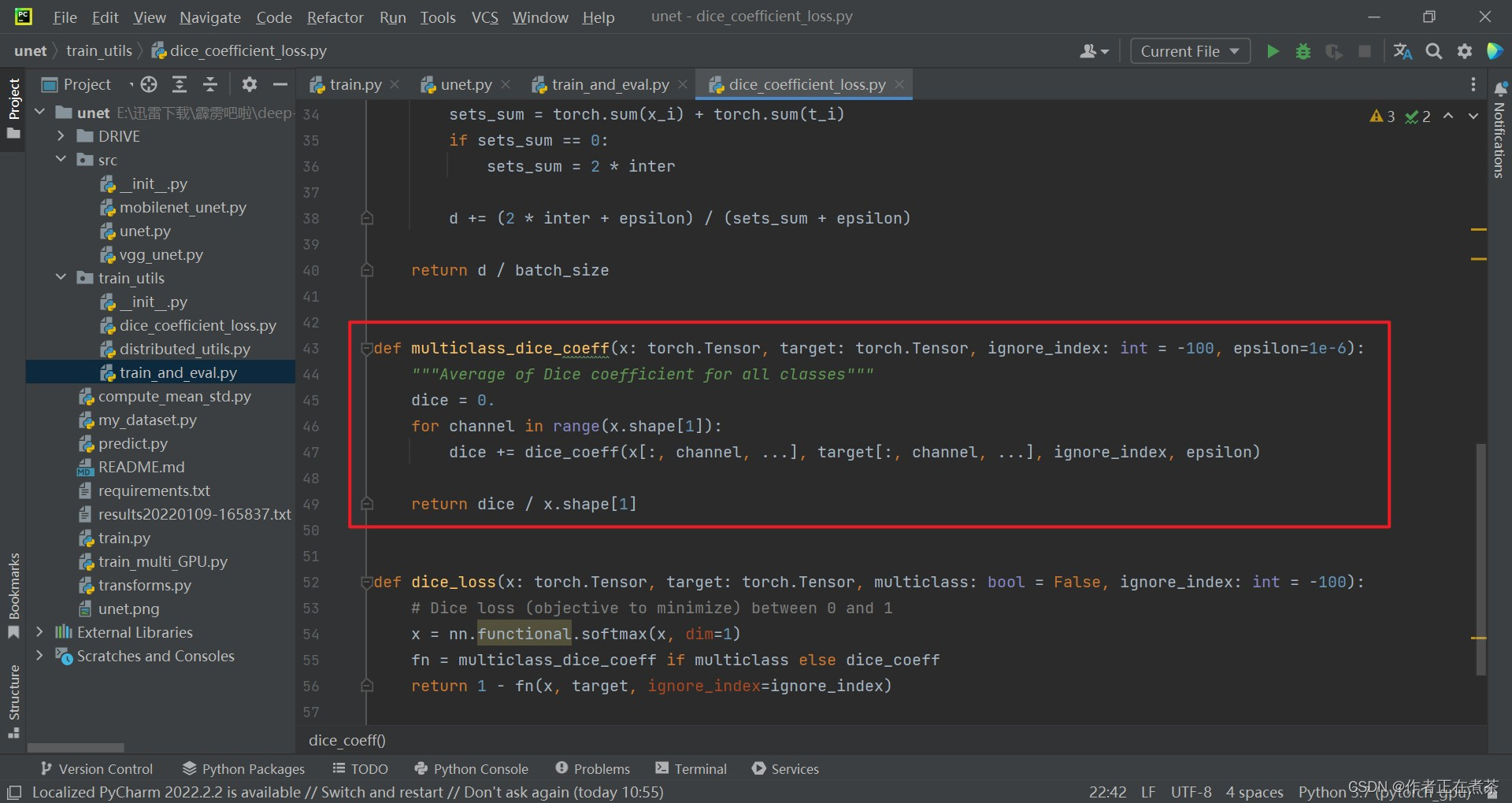
(3)dice_coeff 函数
在 dice_coeff 函数中,传入参数包括:
- x 是针对某一个类别的预测概率的矩阵
- target 就是针对某一个类别的 Ground Truth
- ignore_index 用于指定需要忽略的像素区域
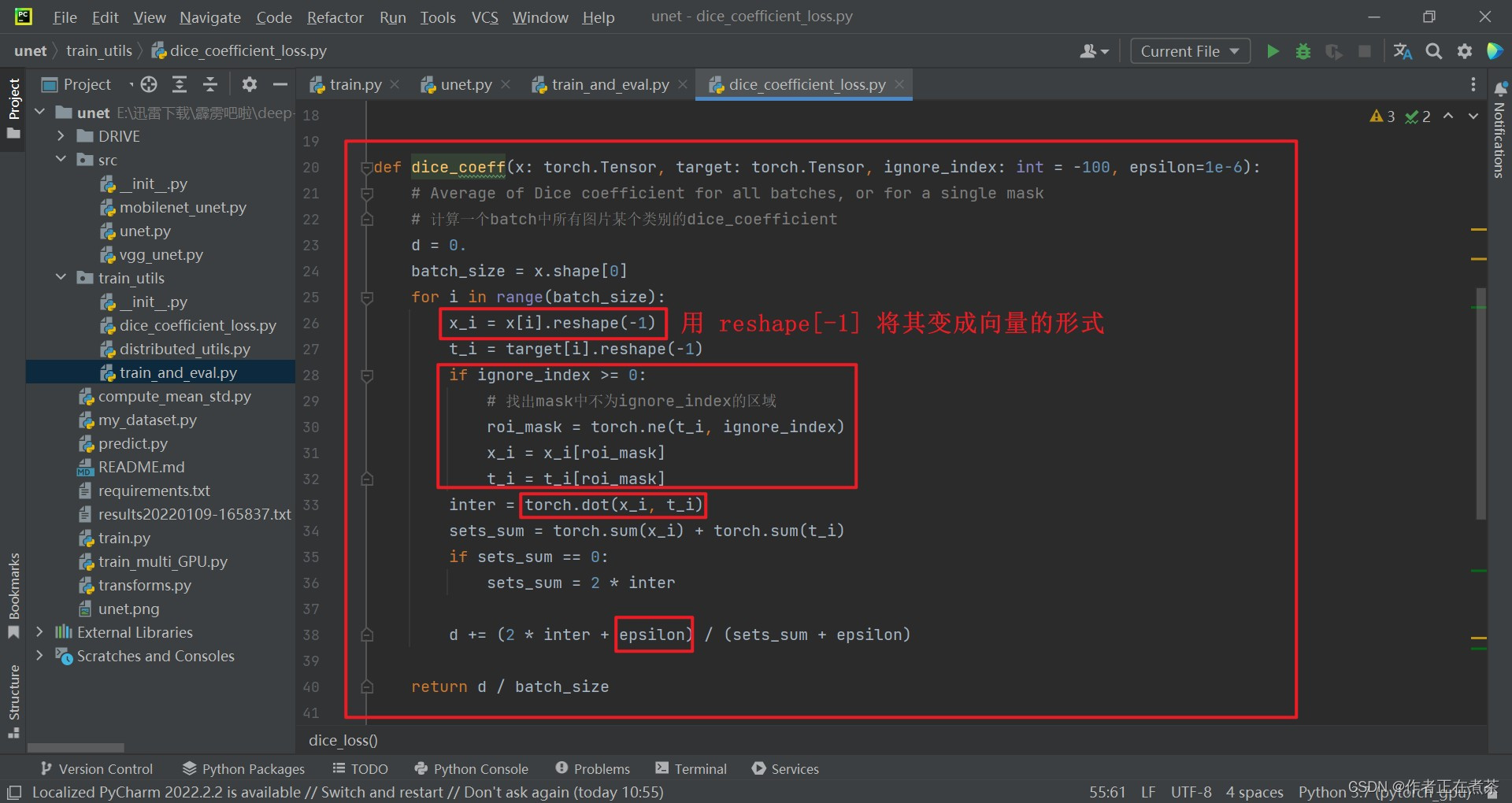
【说明】通过 x_i 能够取出当前 batch 中的第 i 张图片对应某一类别的预测概率矩阵。
- 当 ignore_index 大于等于 0 时,这里的 roi_mask 是指感兴趣的区域,将 x 和 target 当中感兴趣的区域数据提取出来,依旧是向量形式
- 通过 torch.dot 的方法将 x_i 和 t_i 的相应元素相乘,然后求和得到 inter ,也就是之前所说的 Dice 公式中关于分子计算的过程
- 这里的 sets_sum 是分母计算的过程
- 当 sets_sum 为 0 时,所有 x_i 和 t_i 都是 0 ,说明预测都是对的,此时 dice coefficient 等于 1 ,故将 sets_sum 设置为 2 倍的 inter
- 这里的 d 是 batch 当中针对某个类别的所有 coefficient 数值之和
- 这里的 epsilon 是一个很小的值,为了防止分母出现 0 的情况。
- 返回时除以 batch_size 就得到针对每张图片的对应某个类别的 dice coefficient 的均值
5、train_and_eval.py
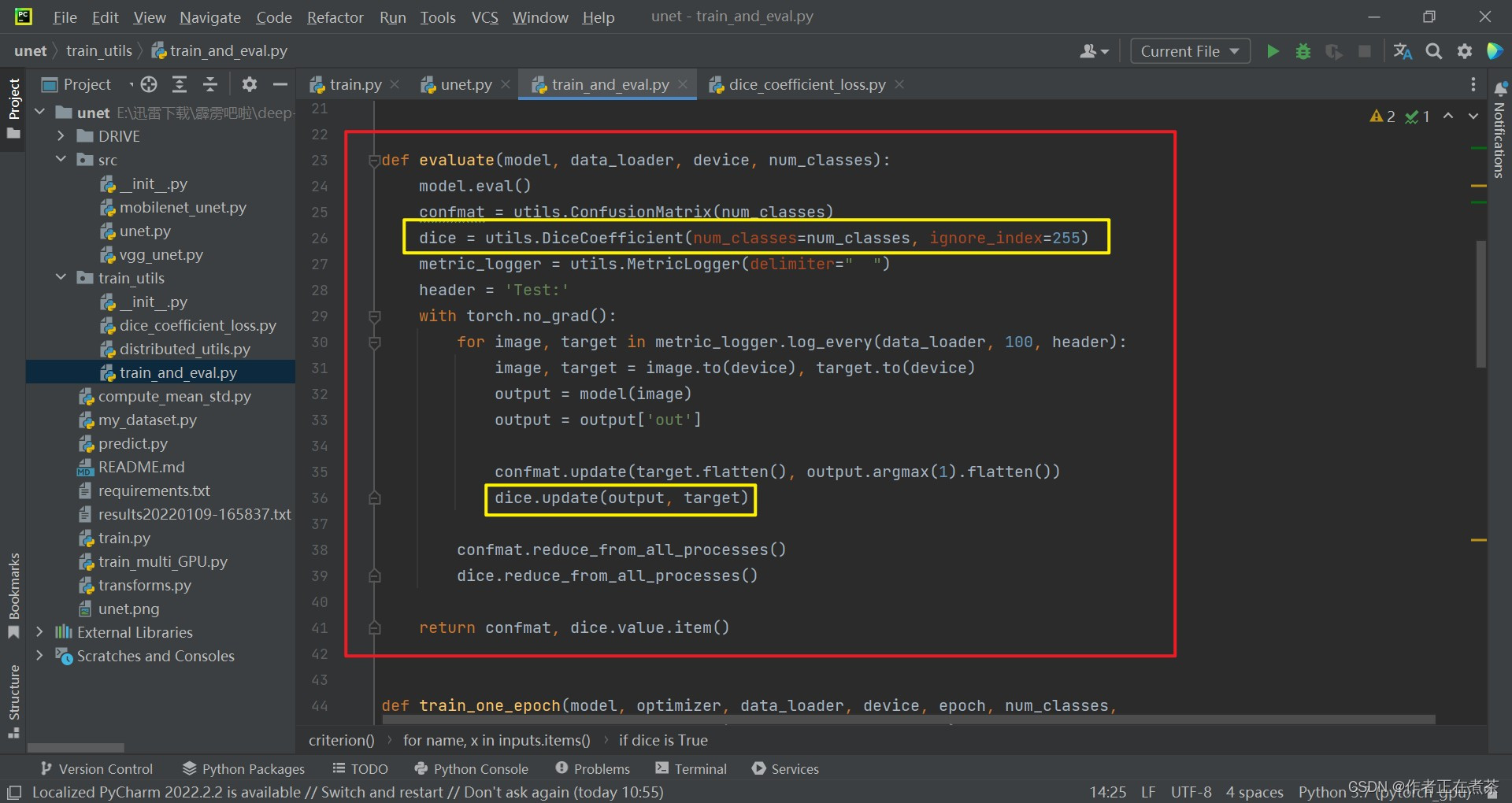
(1)evaluate 函数
在验证过程中,创建了一个 DiceCoefficient 类,这个类会去计算验证过程中所对应的 dice coefficient 。
6、distributed_utils.py
(1)DiceCoefficient 类
我们先来看看 DiceCoefficient 类的 update 函数:

【说明】针对第 141 行中 pred 值的计算,先使用 argmax 方法针对每一个像素,找到 它所属概率最大的那个类别对它的一个预测数值 ,然后将它转化成 one_hot 编码的形式。同样进行 permute 处理,将 channel 维度转移到索引 1 这个位置上。这个计算过程就是上面讲过的,将矩阵 x 的分数数值换为 0 或者 1 的过程。除此之外,由第 143 行的 pred [ : , 1: ] 可知 multiclass_dice_coeff 的计算忽略了背景,这里的 channel 是从 1 开始取的,而 channel = 0 对应的是背景,因此从 1 开始就是把背景忽略了。
我们再来看看 DiceCoefficient 类的 value 函数:
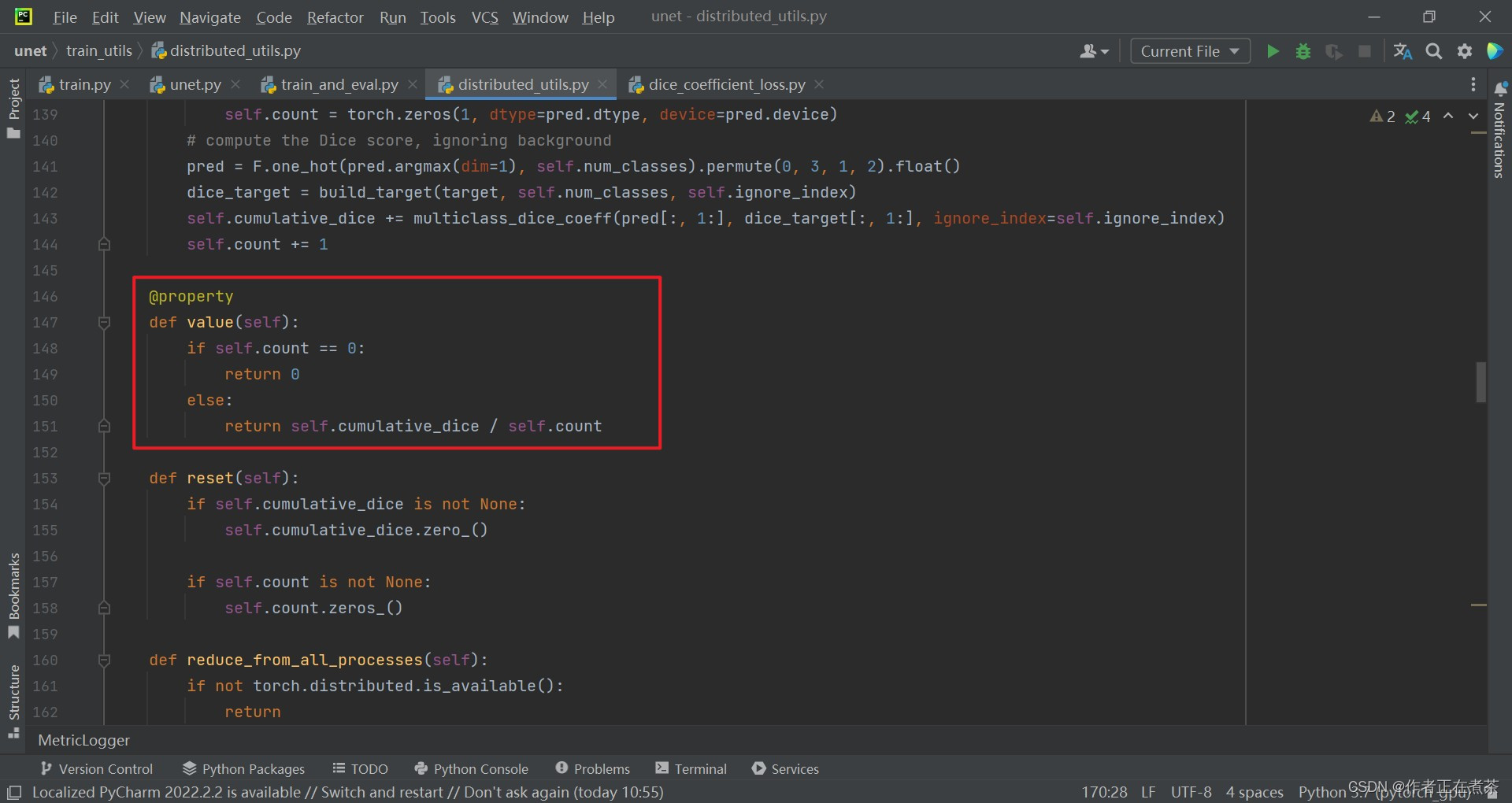
【说明】第 151 行的返回值,我们直接用累积的 dice coefficient 值除以累计的样本个数。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











