







import numpy as np
from sklearn.datasets import fetch_openml
from sklearn.linear_model import SGDClassifier
from sklearn.model_selection import cross_val_predict
from sklearn.metrics import confusion_matrix
from sklearn.metrics import precision_score, recall_score, f1_score
mnist = fetch_openml('mnist_784', version=1, parser='auto')
X, y = mnist['data'], mnist['target']
X = np.array(X)
y = np.array(y)
X_train, X_test, y_train, y_test = X[:60000], X[60000:], y[:60000], y[60000:]
shuffle_index = np.random.permutation(60000)
X_train, y_train = X_train[shuffle_index], y_train[shuffle_index]
y_train_5 = (y_train=='5')
y_test_5 = (y_test=='5')
clf = SGDClassifier(random_state=42)
clf.fit(X_train,y_train_5)
pred_y_train_5 = cross_val_predict(clf, X_train, y_train_5)
con_mat_5 = confusion_matrix(y_train_5, pred_y_train_5)
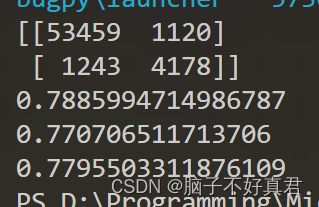
print(con_mat_5)
prec_y_train_5 = precision_score(y_train_5, pred_y_train_5)
print(prec_y_train_5)
rec_y_train_5 = recall_score(y_train_5, pred_y_train_5)
print(rec_y_train_5)
f1_y_train_5 = f1_score(y_train_5, pred_y_train_5)
print(f1_y_train_5)
1. 初始化和训练一个随机梯度下降(SGD)分类器,用于识别手写数字是否为数 '5'
clf = SGDClassifier(random_state=42)
clf.fit(X_train,y_train_5)
SDGClassifier 是sklearn.linear_model 模块中的一个类,它利用随机梯度下降方法来拟合线性模型。fit 方法接受输入特征 X_train 和对应的目标标签 y_train_5 作为参数。在这个例子中, X_train包含60000个手写数字图像的特征向量,而 y_train_5 是一个布尔数组,表示每个图像是否代表数字"5"(True表示是"5",False表示不是"5")。
2. 使用交叉验证来生成每个输入样本的预测值
pred_y_train_5 = cross_val_predict(clf, X_train, y_train_5)
调用 cross_val_predict 方法的目的是获得一个更加公正和无偏的模型性能评估。由于每个样本的预测是在它未参与模型训练的情况下生成的,因此这些预测可以用来计算模型的性能指标(如混淆矩阵、精确率、召回率等),而这些指标更接近于模型在未见过的新数据上的表现。
默认情况下 cv=5 ,也就是5折交叉验证,均分 X_train 为5份,每份 12000 个数据,一份为测试集,其余四份为数据集,直至遍历5份,每份测试集都会得到一组含 12000 个预测结果预测值,而
pred_y_train_5就存储了这些预测值。
3. confusion_matrix混淆矩阵
- 真正类 (True Positives, TP): 模型正确预测为正类的数量。
- 假负类 (False Negatives, FN): 模型错误地将正类预测为负类的数量。
- 假正类 (False Positives, FP): 模型错误地将负类预测为正类的数量。
- 真负类 (True Negatives, TN): 模型正确预测为负类的数量。
con_mat_5 = confusion_matrix(y_train_5, pred_y_train_5)
print(con_mat_5)
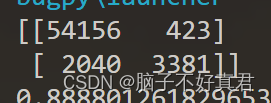

54156+3381+423+2040 = 60000。混淆矩阵用于评估分类模型的性能。它展示了实际类别与模型预测类别之间的关系。按上图所述,我们的希望是让主对角线之和越大越好。
4. 精确率(Precision)、召回率(Recall)、F1分数
精准率Precision =TP/(TP+FP),精确率是预测为正类(此例中为数字"5")的样本中,实际为正类的比例。也就是预测结果和实际情况为5 和 预测结果和实际情况为5 + 预测结果为5实际情况不是5之和 的比例。
召回率recall=TP/(TP+FN),召回率是实际为正类的样本中,被正确预测为正类的比例。也就是预测结果是 5 实际情况也是 5,和预测结果是 5 实际情况也是 5 + 预测结果不是5 实际情况也不是5 的比例。
 ,F1分数同时考虑精确率和召回率。
,F1分数同时考虑精确率和召回率。
5. 运行结果
















 492
492











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











