







 题目目录基础概念1. 载入R中自带的数据集 iris,指出其每列是定性还是定量数据2. 对数据集 iris的所有定量数据列计算集中趋势指标:众数、分位数和平均数3. 对数据集 iris的所有定性数据列计算水平及频次4. 对数据集 iris的所有定量数据列计算离散趋势指标:方差和标准差等5. 计算数据集 iris的前两列变量的相关性,提示cor函数可以选择3种methods6. 对数据集 iris的所有定量数据列内部z-score标准化,并计算标准化后每列的平均值和标准差7. 计算列内部zcore标准化后 i
题目目录基础概念1. 载入R中自带的数据集 iris,指出其每列是定性还是定量数据2. 对数据集 iris的所有定量数据列计算集中趋势指标:众数、分位数和平均数3. 对数据集 iris的所有定性数据列计算水平及频次4. 对数据集 iris的所有定量数据列计算离散趋势指标:方差和标准差等5. 计算数据集 iris的前两列变量的相关性,提示cor函数可以选择3种methods6. 对数据集 iris的所有定量数据列内部z-score标准化,并计算标准化后每列的平均值和标准差7. 计算列内部zcore标准化后 i
题目目录
- 基础概念
-
- 1. 载入R中自带的数据集 iris,指出其每列是定性还是定量数据
- 2. 对数据集 iris的所有定量数据列计算集中趋势指标:众数、分位数和平均数
- 3. 对数据集 iris的所有定性数据列计算水平及频次
- 4. 对数据集 iris的所有定量数据列计算离散趋势指标:方差和标准差等
- 5. 计算数据集 iris的前两列变量的相关性,提示cor函数可以选择3种methods
- 6. 对数据集 iris的所有定量数据列内部z-score标准化,并计算标准化后每列的平均值和标准差
- 7. 计算列内部zcore标准化后 iris的前两列变量的相关性
- 8. 根据数据集 iris的第五列拆分数据集后重复上面的Q2到Q7问题
- 9. 载入R中自带的数据集 mtcars,重复上面的Q1到Q7个问题
- 10. 载入r包airway并且通过assay函数拿到其表达矩阵后计算每列之间的相关性
- 表达矩阵相关
-
- 1. 把RNAseq_expr第一列全部加1后取log2后计算平均值和标准差
- 2. 根据上一步得到平均值和标准差生成同样个数的随机的正态分布数值
- 3. 删除RNAseq_expr第一列低于5的数据后,重复Q1和Q2
- 4. 基于Q3对RNAseq_expr的第一列和第二列进行T检验
- 5. 取RNAseq_expr行之和最大的那一行根据分组矩阵进行T检验
- 6. 取RNAseq_expr的MAD(绝对中位差)最大的那一行根据分组矩阵进行T检验
- 7. 对RNAseq_expr全部加1后取log2后重复Q5和Q6
- 8. 取RNAseq_expr矩阵的MAD最高的100行,对列和行分别进行层次聚类
- 9. 取RNAseq_expr矩阵的SD最高的100行,对列和行分别进行层次聚类
- 10. 对Q8矩阵按照行和列分别归一化并且热图可视化
- 统计检验相关
写在前面——本文是介绍了一些统计学的基础知识,以及如何用R语言实现。旨在熟练使用编程语言解决实际问题。统计学是一门复杂的学科,还需更加系统的学习。下方 生统基础是大佬写的StartQuest的读书笔记,能够帮助快速理解生物统计学。
题目原文:http://www.bio-info-trainee.com/4385.html
参考答案:https://www.jianshu.com/p/1c0cbf1bfb75
参考答案:https://hc1023.github.io/2019/09/27/R-statistic/
生统基础:http://rvdsd.top/categories/%E7%94%9F%E7%BB%9F%E4%B9%8BStatQuest/
基础概念
1. 载入R中自带的数据集 iris,指出其每列是定性还是定量数据
colnames(iris)
head(iris)

基础概念讲解:https://mp.weixin.qq.com/s/OtB2h6f00U2SRZLzveJKfQ
前四个为定量变量,最后一个为定性变量
2. 对数据集 iris的所有定量数据列计算集中趋势指标:众数、分位数和平均数
# 求前四个变量的最大值、最小值、分位数和平均数
summary(iris[,1:4])
# R中无直接求众数的函数
# 法一
# tmp <- table(iris[,1])
# index <- which.max(tmp)
# tmp[index]
# 法二
getmode <- function(x){
return(as.numeric(names(table(x))[table(x) == max(table(x))]))
}
# table(iris[,1]) == max(table(iris[,1]))
# names(table(iris[,1]))
# names(table(iris[,1]))[table(iris[,1]) == max(table(iris[,1]))]
for(i in 1:4){
print(getmode(iris[,i]))
}
# 第三列有两个众数

3. 对数据集 iris的所有定性数据列计算水平及频次
summary(iris[,5])
#output#
setosa versicolor virginica
50 50 50
4. 对数据集 iris的所有定量数据列计算离散趋势指标:方差和标准差等
# 方差
apply(iris[,1:4], 2, var)
# 标准差
apply(iris[,1:4], 2, sd)
# 通过psych包中的describe()计算描述性统计量
# 输出结果依次为:非缺失值的数量、平均数、标准差、中位数、截尾均值、绝对中位差、最小值、最大值、值域、偏度、峰度和平均值的标准误
# install.packages("psych")
library(psych)
describe(iris[,1:4])

5. 计算数据集 iris的前两列变量的相关性,提示cor函数可以选择3种methods
cor(iris[,1:2], method = "pearson")
cor(iris[,1:2], method = "spearman")
cor(iris[,1:2], method = "kendall")
Pearson积差相关系数衡量了两个定量变量之间的线性相关程度(默认值)
Spearman等级相关系数则衡量分级定序变量之间的相关程度
Kendall’sTau相关系数也是一种非参数的等级相关度量

6. 对数据集 iris的所有定量数据列内部z-score标准化,并计算标准化后每列的平均值和标准差
newdata <- apply(iris[1:4],2,scale)
apply(newdata,2,mean)
apply(newdata,2,sd)
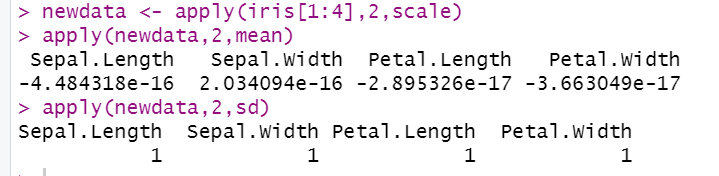

图源:https://blog.csdn.net/Orange_Spotty_Cat/article/details/80312154
scale(x, center = TRUE, scale = TRUE)
center和scale默认为真,center为真表示数据中心化,scale为真表示数据标准化
数据中心化是指:变量减去它的均值
数据标准化是指:数值减去均值,再除以标准差
所以不难理解,对数据的每列调用scale就完成了z-score标准化
标准化之后的数据均值为0,标准差为1(上面的均值结果近似于0,也算为0吗?)
参考:https://zhuanlan.zhihu.com/p/32482328
7. 计算列内部zcore标准化后 iris的前两列变量的相关性
cor(newdata[,1:2], method = "pearson")
cor(newdata[,1:2], method = "spearman")
cor(newdata[,1:2], method = "kendall")

与第5题结果相同,标准化后的数据相关性不变
8. 根据数据集 iris的第五列拆分数据集后重复上面的Q2到Q7问题
# 划分数据集
table(iris$Species)
setosa <- iris[iris$Species=="setosa",]
head(setosa)
versicolor <- iris[iris$Species=="versicolor",]
virginica <- iris[iris$Species=="virginica",]
# 写个无脑输出函数
getResult <- function(x){
print("### 2 ###")
print(apply(x[,1:4], 2, getmode))
print(summary(x[,1:4]))
print("### 3 ###")
print(summary(x[,5] 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 4789
4789











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









