







这个问题早在去年9月就被发现了,但是现场保存得不好,只在简书上留了几张截图。并且笔者那时跑到11区浪去了,简书当时也被有司请去喝了一段时间的茶,因此细节没有保留太多,权当留个备忘吧。
故障现象:
- 机器硬盘告警,提示/tmp写满,在硬盘里有大量Cloudera Manager中Service Monitor服务的堆转储文件。
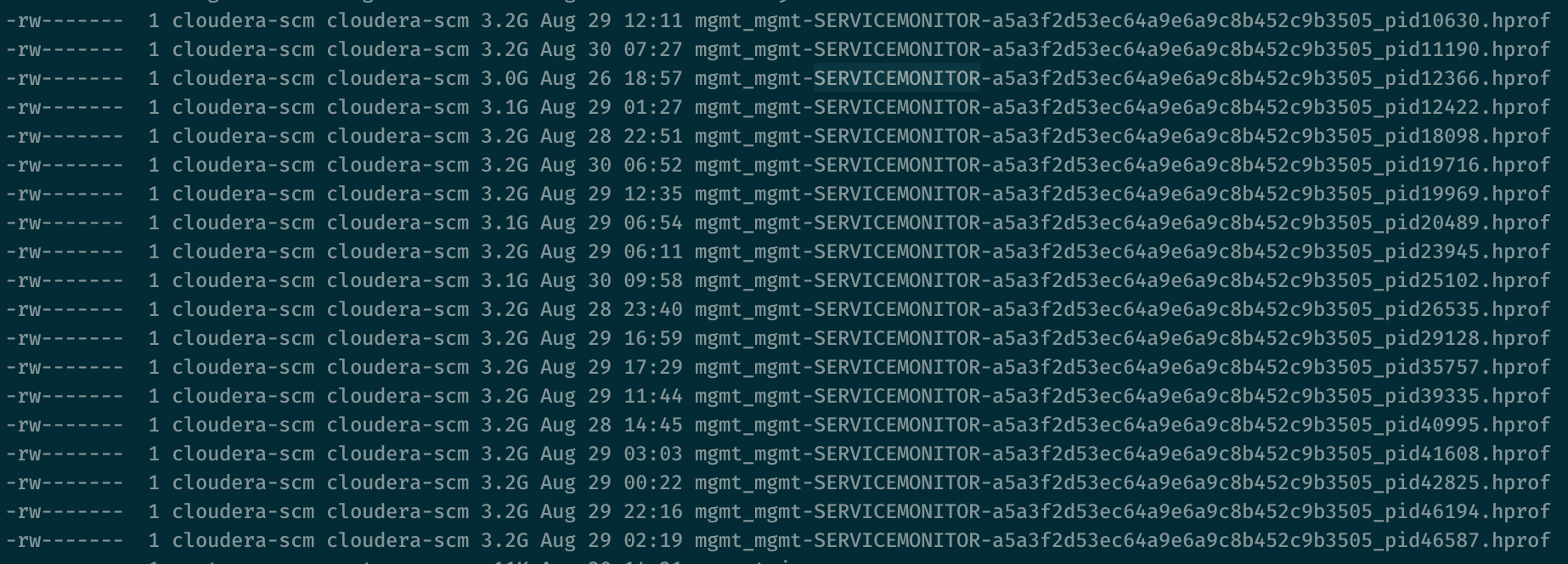
- Cloudera Manager的Web UI界面提示请求Service Monitor失败,所有组件状态未知,并且CM所在节点的CPU占用高。
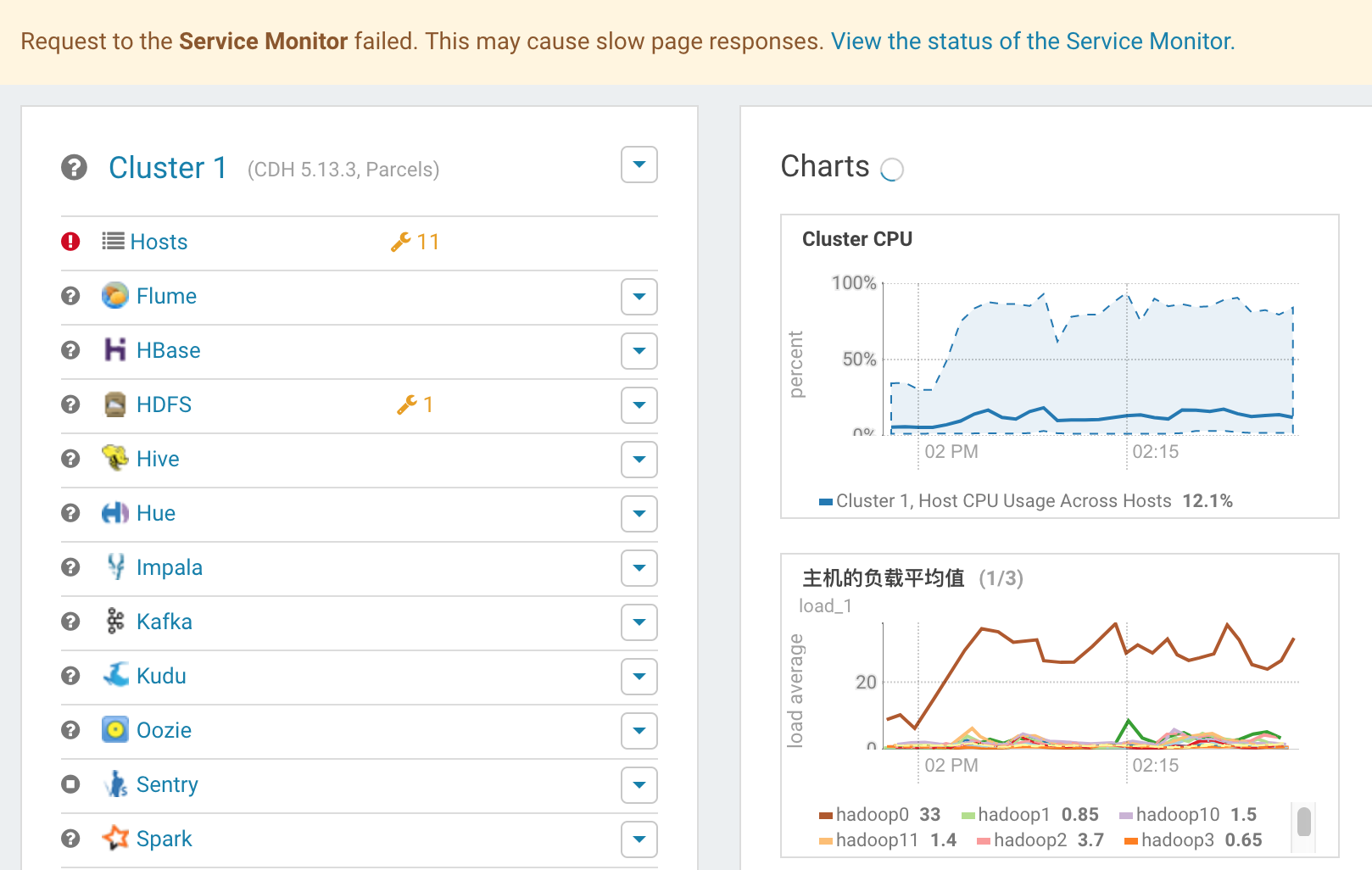
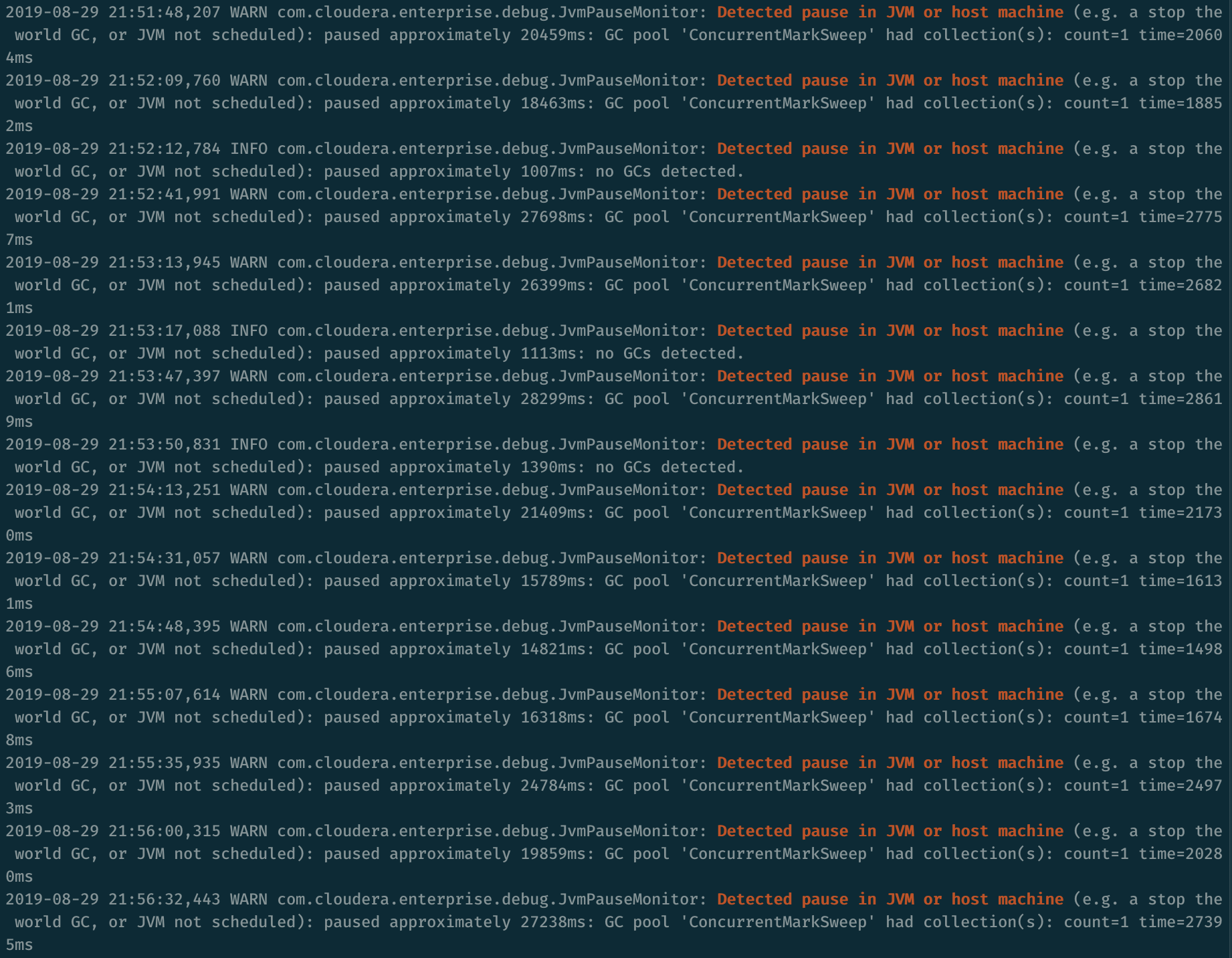
凭直觉确定是OOM了。去/var/log/cloudera-scm-firehose目录下查看Service Monitor的角色日志,果然有频繁的因JVM GC导致的stop-the-world。
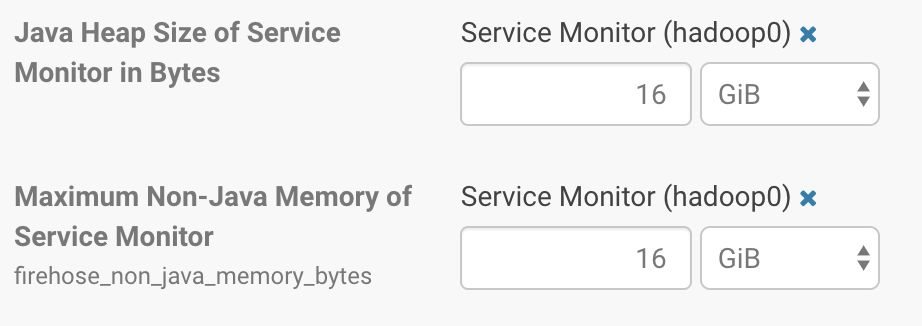
于是我们将Service Monitor的堆内内存和堆外内存都加大到16GB,重启之,发现完全没有好转。
接下来自然是采用top+ps+jstack大法,试图定位到出问题的线程,但令人窒息的是,吃CPU最狠的那个线程竟然没有线程ID。忘了截图,就这样吧。
翻看CDH官方文档,找到了其监控服务中的数据存储相关细节,传送门https://www.cloudera.com/documentation/enterprise/latest/topics/cm_ig_storage.html。简单概括如下。
- Service Monitor用于监控各服务(HDFS、HBase、Kafka、Kudu,etc.),Host Monitor用于监控各主机。
- Service Monitor的监控数据由三部分组成:时序的监控指标数据(用LevelDB存储)、Impala查询的元数据、YARN App的元数据。这些数据存储的位置由参数
firehose.storage.base.directory来指定。 - 随着时间的推移,时序数据会被不断地汇总,以方便查询不同时间粒度的监控状态,如1小时级、6小时级、天级或周级。默认是10分钟汇总一次,CDH将这个行为叫做“卷起”(rollup)。
下图示出Cloudera Manager提供的监控图表展开后的数据粒度选项。
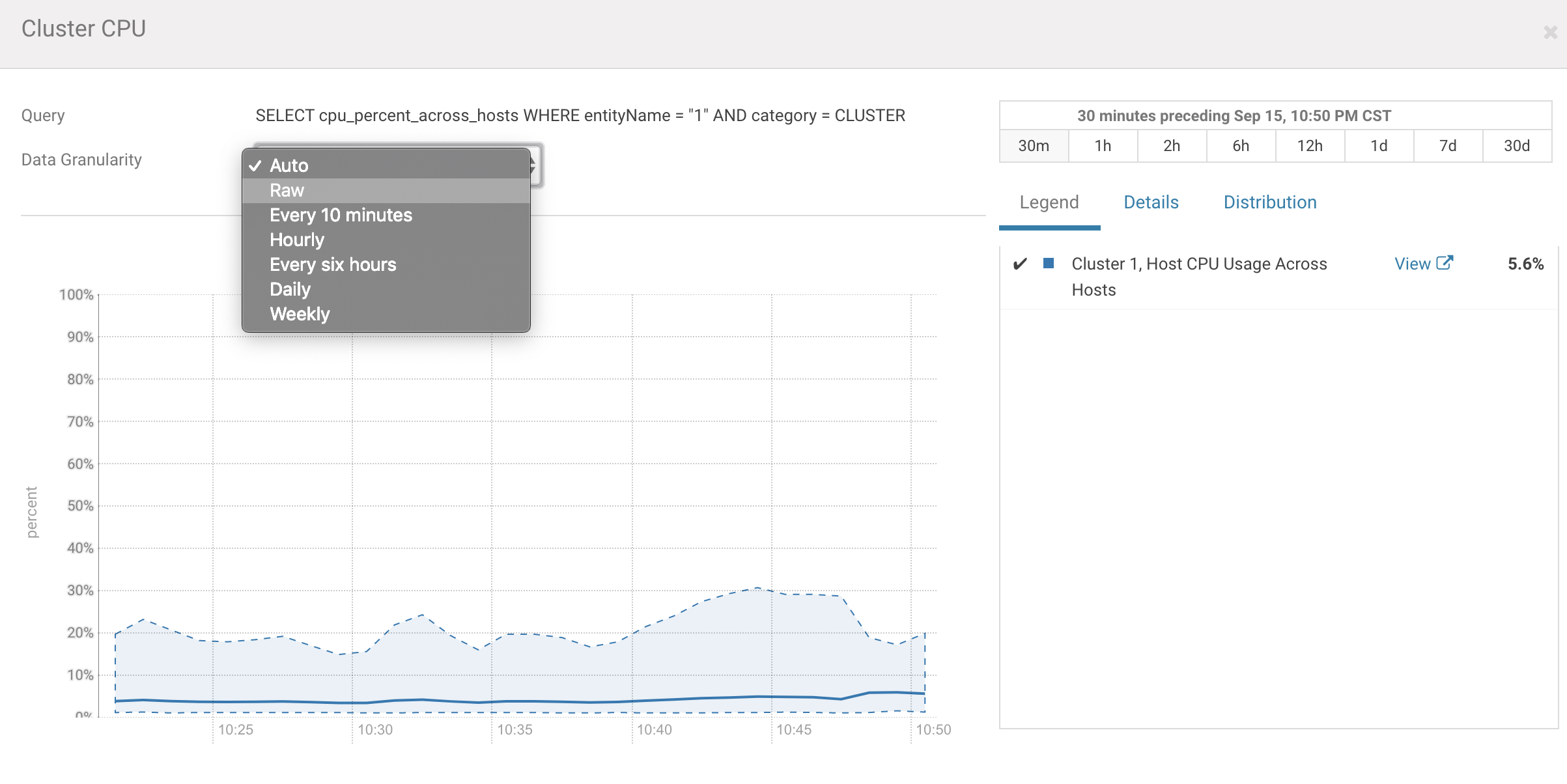
由于时序数据肯定会占绝大部分(最小都要有10GB大),联想到rollup可能容易出现问题。从日志看,rollup的延迟已经达到了一天之多,说明进入到LevelDB的监控数据过多,处理不过来了。这是造成内存爆掉的真正原因。
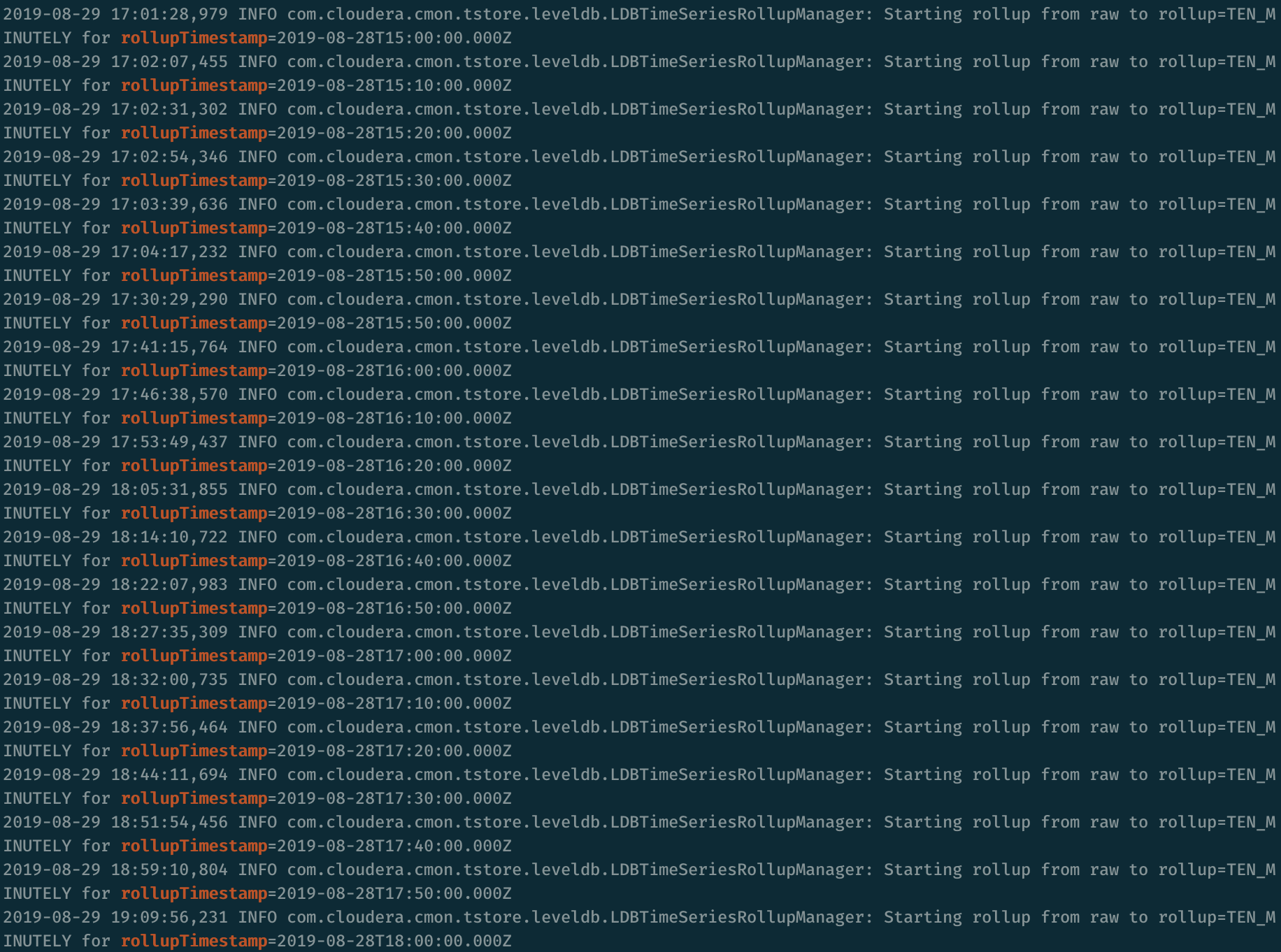
在CDH 6.x版本中,可以通过将firehose.timeseries.rollup.disabled配置项设为false来禁用指标rollup,但是同时会造成汇总粒度只剩下raw,查看起来不是很方便。更合适的方法是禁用掉一些产生大量指标但平时又不太关心的服务的监控,即在对应服务的配置中取消勾选“Enable Metric Allocation”一项。

通过观察每个服务的Charts Library,发现Kudu的监控指标和实体都很多(每张表都会产生监控数据)。我们关闭对Kudu的监控,并手动清理了firehose.storage.base.directory目录内的监控数据后,再重启Service Monitor,一切正常。
民那晚安,祝身体健康,百毒不侵。














 4324
4324











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









