




 本文提出了一种新的上下文依赖映射网络Context-I2W,用于零样本组合图像检索(ZS-CIR)。与现有方法不同,Context-I2W通过动态选择与描述相关的图像信息,生成适应性更强的伪词标记,提高了ZS-CIR的准确性。模型包含Intent View Selector和Visual Target Extractor两个模块,前者根据上下文信息旋转图像嵌入,后者则从不同方面聚合视觉信息。实验结果显示,Context-I2W在多种ZS-CIR任务上取得显著提升,达到新的state-of-the-art水平。
本文提出了一种新的上下文依赖映射网络Context-I2W,用于零样本组合图像检索(ZS-CIR)。与现有方法不同,Context-I2W通过动态选择与描述相关的图像信息,生成适应性更强的伪词标记,提高了ZS-CIR的准确性。模型包含Intent View Selector和Visual Target Extractor两个模块,前者根据上下文信息旋转图像嵌入,后者则从不同方面聚合视觉信息。实验结果显示,Context-I2W在多种ZS-CIR任务上取得显著提升,达到新的state-of-the-art水平。
原文标题: Context-I2W: Mapping Images to Context-dependent Words for Accurate Zero-Shot Composed Image Retrieval
原文代码: https://github.com/Pter61/context i2w.
发布年度: 2024
发布期刊: AAAI
摘要
Different from Composed Image Retrieval task that requires expensive labels for training task-specific models, Zero-Shot Composed Image Retrieval (ZS-CIR) involves diverse tasks with a broad range of visual content manipulation intent that could be related to domain, scene, object, and attribute. The key challenge for ZS-CIR tasks is to learn a more accurate image representation that has adaptive attention to the reference image for various manipulation descriptions. In this paper, we propose a novel context-dependent mapping network, named Context-I2W, for adaptively converting descriptionrelevant Image information into a pseudo-word token composed of the description for accurate ZS-CIR. Specifically, an Intent View Selector first dynamically learns a rotation rule to map the identical image to a task-specific manipulation view. Then a Visual Target Extractor further captures local information covering the main targets in ZS-CIR tasks under the guidance of multiple learnable queries. The two complementary modules work together to map an image to a context-dependent pseudo-word token without extra supervision. Our model shows strong generalization ability on four ZS-CIR tasks, including domain conversion, object composition, object manipulation, and attribute manipulation. It obtains consistent and significant performance boosts ranging from 1.88% to 3.60% over the best methods and achieves new state-of-the-art results on ZS-CIR.
背景
任务描述: 给定参考图像和文本描述,组合图像检索 (CIR)旨在检索视觉上与参考图像相似的图像,同时满足文本描述。CIR存在两个核心挑战:(1)根据描述准确定位参考图像中的视觉内容;(2)从不同模态组合相关的视觉和文本内容进行图像检索。
已经提出了几种监督方法来解决 CIR 问题,这需要大量带注释的三元组,包括参考图像、描述和检索到的图像。针对特定任务训练的监督方法也很难泛化。因此在最近的工作中引入了zero-short的CIR任务。
ZS-CIR任务的当前工作中,还是将其视为传统的基于文本的图像检索问题。基本框架可以分为三个步骤。首先,学习映射网络Mapping Network,将参考图像嵌入转换为伪词标记,该标记与描述连接以形成组合文本查询。然后,利用预训练的 CLIP 对查询和候选图像进行编码,以便在零样本模式下进行文本到图像检索。然而,现有模型将图像的整个视觉信息转换为用于不同描述的相同伪词。这限制了模型自适应选择和映射视觉信息的灵活性。事实上,只有部分视觉内容与操作意图相关。
创新点
在这项工作中,将描述视为参考图像的上下文,并提出了一个上下文相关的映射网络,以自适应地将与描述相关的图像信息转换为伪词(Context-I2W),以实现准确的ZS-CIR。
为了适用于多样的组合图像检索(CIR)任务,Context-I2W 模块以分层方式自适应地从图像中选择与描述相关的信息,如图1(b)所示:Intent View Selector 模块首先学习各种映射规则,以一种上下文相关的方式动态地将视觉嵌入映射到不同的视图。因此,每个视图都捕捉了与任务特定操作意图(例如,领域、场景和属性)相关的视觉信息,即使输入相同。接着,Visual Target Extractor 模块在多个可学习查询的引导下,进一步从不同方面(例如前景、背景、物体和细节)收集局部信息。这两个模块共同作用,将图像映射到一个上下文相关的伪单词令牌。独立于昂贵的描述区域标签,Context-I2W 使用检索到的图像与伪单词增强的组合查询之间的对比损失进行训练。
模型
为了有效地在不同模态之间组合 I 和 T 进行零样本图像检索,构建了一个以句子 P[ “a photo of S∗ that T ”]形式的组合查询,并使用 CLIP 的冻结文本编码器进行嵌入。给定组合查询嵌入,通过 CLIP 的冻结图像编码器对每个候选图像 Ic 进行嵌入,并将 ZS-CIR 视为传统的文本到图像检索任务,通过衡量 P 和 Ic 之间的相似性来进行评估。
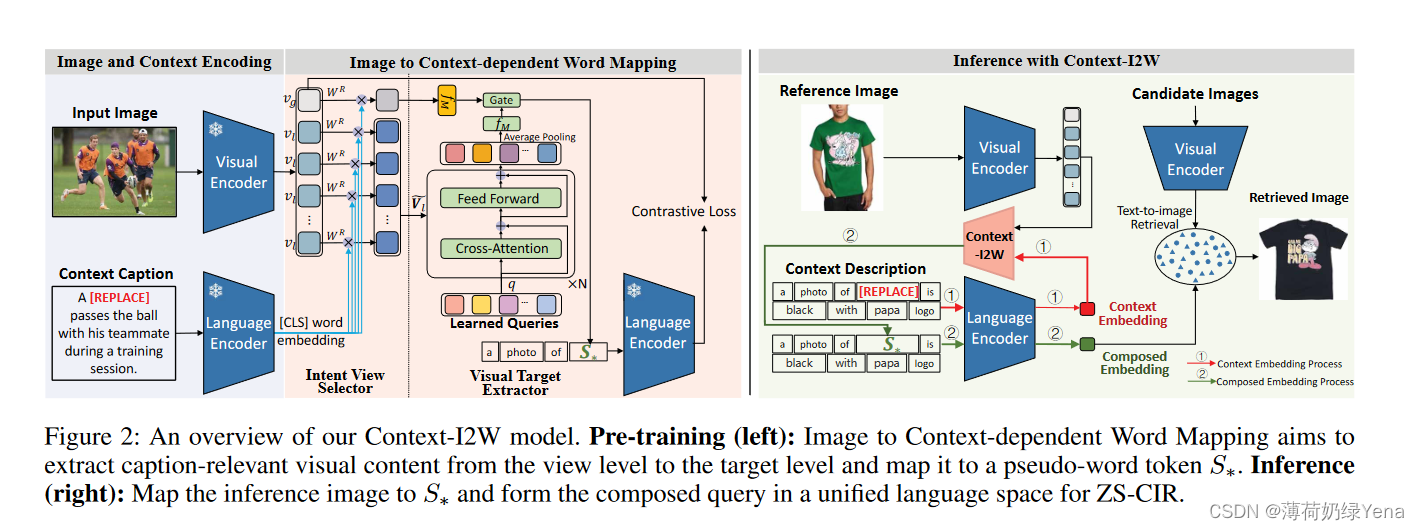
- 图像和上下文编码Image and Context Encoding
首先利用预训练模型 CLIP 对上下文和图像进行编码,以进行精细的图像到单词映射。
应用 CLIP 的冻结视觉编码器来表示参考图像 I,得到一组视觉特征向量 V = { v i } i = 1 m V =\{v_i\}^m_{i=1} V={
vi}i=1m,其中 v1 表示全局图像特征 vg,而其他的表示局部patch特征 V l = { v i } i = 2 m V_l =\{v_i\}^m_{i=2} Vl={
vi}i=2m。
在这项工作中,使用一个image-caption对的数据集用于学习 Context-I2W 网络,并有一组image-description对用于ZS-CIR,将caption和description都标识为相应图像的上下文。由于上下文通常通过描述其相关信息(例如,环境或属性)引入一个视觉目标,通过目标相关信息表示上下文。
首先,需要确保上下文捕捉到对视觉内容的所述意图视图。换句话说,将上下文特征充当映射规则,将相同的图像表示转换为文本特定的视图。其次,需要确保这样的上下文特征能够以一种互补的方式与视觉目标特征集成,以进行准确的伪标记映射。为此,通过 spacy的词性标注器提取上下文中的第一个主语,并用一个可学习的标记 [REPLACE] 替换它。并将重写的句子馈送给冻结的 CLIP 的视觉编码器,并获得 [CLS] 标记嵌入 t t t作为视觉特征提取的引导。
- 图像到上下文相关的单词映射Image to Context-dependent Word Mapping
涉及两个模块从互补的方面约束视觉表示:意图视图选择器(简称IVS)通过上下文引导特征旋转,从相同的图像特征中保留上下文所需的视觉特征视图。视觉目标提取器(简称VTE)进一步从所需的视图特征中聚合上下文特定目标的视觉特征。通过跨模态对比学习,目标及其相关信息被自适应地组合并映射到词标记空间中。
- 意向视图选择器Intent View Selector.
基于编码图像和上下文嵌入,该模块旨在从上下文中描述的意图的角度来表示视觉内容,而不干扰视觉内容。从数学角度来看,上下文通过根据上下文约束旋转图像嵌入空间来服务,从而在不改变其内容的情况下选择V的视图表示。
具体来说,将每个视觉嵌入 vi 馈送到具有可学习权重矩阵 W R = { w k R } k = 1 d W_R = \{w^R_k \}^d_{k=1} WR=
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1304
1304

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









