







原文标题: Improving Fast Adversarial Training With Prior-Guided Knowledge
原文代码: https://github.com/jiaxiaojunQAQ/FGSM-PGK
发布年度: 2024
发布期刊: TPAMI
摘要
Fast adversarial training (FAT) is an efficient method to improve robustness in white-box attack scenarios. However, the original FAT suffers from catastrophic overfitting, which dramatically and suddenly reduces robustness after a few training epochs. Although various FAT variants have been proposed to prevent overfitting, they require high training time. In this paper, we investigate the relationship between adversarial example quality and catastrophic overfitting by comparing the training processes of standard adversarial training and FAT. We find that catastrophic overfitting occurs when the attack success rate of adversarial examples becomes worse. Based on this observation, we propose a positive prior-guided adversarial initialization to prevent overfitting by improving adversarial example quality without extra training time. This initialization is generated by using high-quality adversarial perturbations from the historical training process. We provide theoretical analysis for the proposed initialization and propose a prior-guided regularization method that boosts the smoothness of the loss function. Additionally, we design a prior-guided ensemble FAT method that averages the different model weights of historical models using different decay rates. Our proposed method, called FGSM-PGK, assembles the prior-guided knowledge, i.e., the prior-guided initialization and model weights, acquired during the historical training process. The proposed method can effectively improve the model’s adversarial robustness in white-box attack
TPAMI_2024
背景
本文专注于提高白盒和非针对性攻击场景中的模型对抗鲁棒性。标准对抗性训练已被证明是增强对抗性示例鲁棒性的最有效方法之一。然而,它们大多数采用多步对抗性攻击来生成用于训练的对抗性示例。这种方法需要大量的训练时间,限制了标准对抗训练的实际应用。
为了减少训练时间,快速对抗训练被提出,可以将其表述为最小-最大优化问题,以提高白盒攻击场景中的对抗鲁棒性。但是在快速对抗训练中,经过几个训练周期后,模型突然失去了鲁棒性,被称为灾难性的过度拟合。为了解决这个问题,有人提出了样本初始化和正则化两种方法。它们不仅可以缓解灾难性的过度拟合,还可以实现尖端的模型鲁棒性性能。然而,它们还需要额外的训练时间来提高对抗样本的质量。
对抗样本的质量对于快速对抗训练至关重要。本文实验了快速对抗训练和标准对抗训练之间对抗样本质量的差异,以了解灾难性过度拟合的原因。如图2所示,经过一定时间的训练后,快速对抗训练方法(FGSM-AT和FGSM-RS)中使用的对抗样本的攻击成功率突然急剧下降,同时,模型的对抗鲁棒性也急剧下降。这一发现表明,灾难性过拟合与对抗样本的质量有关,即当对抗样本的质量恶化时,快速对抗训练会遇到灾难性过拟合。然而,PGD-2-AT(两步PGD-AT)可以被认为是具有对抗性样本初始化的FGSM-AT,不会遇到灾难性的过拟合。这一结果表明,更好的样本初始化可以帮助快速对抗训练,防止灾难性的过度拟合。
创新点
基于上述观察,本文提出了一个问题:是否有可能在不产生额外训练时间的情况下获得对抗性样本初始化。因此,本文提出采用先验引导的初始化,该初始化是利用历史训练过程中的高质量对抗性扰动生成的。具体来说,本文提出通过动量机制使用之前所有时期的缓冲梯度作为附加先验,此外,根据历史对抗样本的质量累积不同权重的缓冲梯度。
除此之外,还提出了一种简单而有效的正则化方法,用于防止学习模型在当前对抗性示例上的输出与先验引导初始化所初始化的样本上的输出偏差太大。在最小化的优化步骤中,对由先验引导的初始化和对抗性扰动生成的两类对抗性示例的模型预测之间的 L2 距离进行最小化。通过迫使模型在面对不同对抗样本时保持平滑的损失函数,从而增强模型对两种类型样本的鲁棒性。
有文献证明模型权重平均WA可以显着提高模型的鲁棒性,而且在标准对抗训练也有一定的效果。但本文实验发现直接使用 WA 导致对抗鲁棒性的提高有限。这是因为在快速对抗训练过程中也存在非鲁棒模型权重,这可能会对最终模型的鲁棒性产生负面影响。为了克服这一限制,本文提出了一种先验引导的集成快速对抗训练方法,该方法在训练过程中对具有不同衰减率的历史模型的模型权重进行平均。
通过结合所提出的先验指导知识,即先验指导初始化和模型权重,得出了本文的快速对抗训练方法,称为 FGSM-PGK。
相关工作
简单介绍一些之前用于解决快速对抗训练中灾难性过拟合的方法:
FGSM-GA:一种基于梯度对齐的正则化方法来提高对抗样本的质量
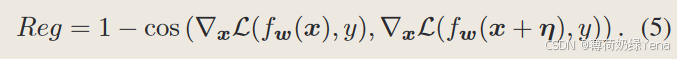
GAT:一种函数平滑引导正则化来提高对抗鲁棒性
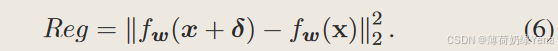
NuAT:一种基于 Nuclear-Norm 的正则化方法来增强函数平滑
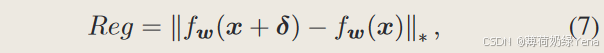
方法
A. Rethinking Catastrophic Overfitting
使用一步FGSM攻击可以找到对抗性的最优解扰动。否则,FGSM 攻击无法找到第一最佳对手,这可能会导致灾难性的过度拟合,但具有额外训练时间的多步 PGD 攻击可以找到第一最佳对手扰动。它表明灾难性的过度拟合与对抗样本的质量直接相关。我们可以从这个角度理解快速对抗训练变体的有效性。他们采用样本初始化和正则化方法来改进内部最大化解的解,即高质量的对抗样本。他们中的大多数需要额外的培训时间。在本文中,我们探索了样本初始化策略,并提出了具有不同权重的先验引导初始化,以提高对抗样本的质量,而无需额外的训练时间。
B. Sample Initialization Strategies
这里考虑使用历史训练过程中生成的对抗性扰动来初始化基于 FGSM 的对抗性示例进行训练。这种样本的先验知识只是占用存储空间,不会增加梯度计算的训练时间。具体研究了利用先验引导的对抗性扰动的三种样本初始化策略,即采用来自前一个训练批次、前一个训练时期和所有训练时期的动量中的对抗性扰动的样本初始化。
1.Prior-Guided Initialization From Previous Batch
来自前一批次训练的对抗性扰动被存储并用于初始化当前批次中基于 FGSM 的对抗性示例,称为 FGSM-BP。在每次迭代中,我们通过从训练数据集中随机采样来获得训练批次。因此,前一批中的对抗性扰动与当前批次中的样本没有对应关系。具体来说,对于当前的良性图像x,我们对通过在x上添加前一批中的扰动而生成的扰动示例执行FGSM。对抗性扰动可以计算为:
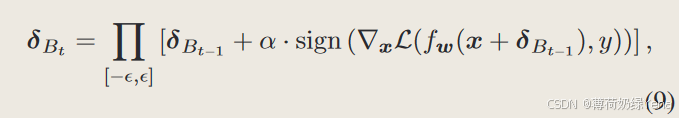
其中 δBt 表示第 t 次迭代时批次中的扰动
2.Prior-Guided Initialization From Previous Epoch
前一个时期的所有对抗性扰动都会被存储并用于初始化当前时期中基于 FGSM 的对抗性示例。与FGSM-BP不同的是,前一个时期的对抗性扰动与当前时期的样本直接相关。具体来说,对于当前的良性图像x,我们采用前一时期的相应扰动δEt−1来初始化x,从而执行FGSM来生成用于训练的对抗样本。对抗性扰动可以计算为:
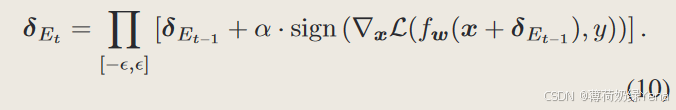
3.Prior-Guided Initialization From the Momentum of all Previous Epochs
为了充分利用先验引导的对抗性扰动,我们建议累积一个样本在所有先前历元的梯度动量信息,以生成当前历元的样本初始化,用于基于 FGSM 的对抗性示例生成,称为 FGSMMEP。具体来说,对于当前的良性图像 x,我们首先累积 x 上所有先前历元的梯度动量,然后使用它来生成基于 FGSM 的对抗性扰动的对抗性初始化。对抗性扰动可以计算为:
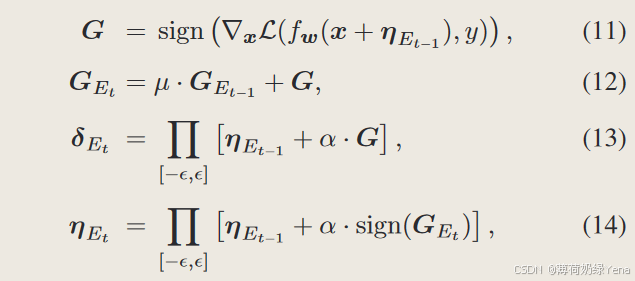
其中G表示训练模型在输入图像x上的梯度,GEt表示之前t个时期的累积梯度G之和,δEt表示第t个时期生成的对抗性扰动,ηEt表示第t个时期中的样本对抗性初始化第 t 个纪元。与之前的样本初始化策略相比,所提出的FGSM-MEP更充分地利用了先验引导信息,即训练过程中样本的历史梯度。
C. The Proposed Initialization Strategy
尽管提出的FGSM-MEP可以防止灾难性的过度拟合,但它积累了负的先验引导梯度信息,导致模型鲁棒性的提高有限。为了克服这一缺点,我们提出根据梯度动量质量为一个样本的不同梯度动量信息分配不同的权重进行累积。具体来说,我们提出了一种基于攻击率的简单有效的度量方法来评估梯度动量的质量。所提出的评估指标可以定义为:
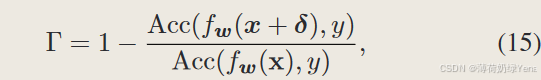
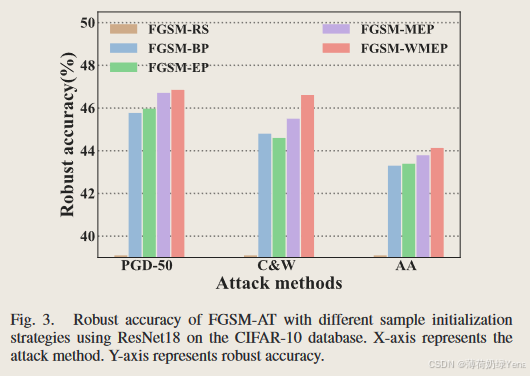
Γ越高,当前梯度生成的对抗样本的攻击成功率越高,即当前梯度的质量越好。称为 FGSM-WMEP,公式上体现在:

由图3实验看出,FGSM-WMEP在所有攻击场景下都实现了最佳的对抗鲁棒性性能。
D. The Proposed Regularization Method
具体来说,对于给定的输入图像x,产生先验引导初始化的对抗图像x + δpgi和FGSM生成的对抗图像x + δadv。为了使得鲁棒模型对两种样本都能产生较好的结果,提出了一个正则化项来指导模型,提高了样本周围损失函数的平滑度。
具体就是最小化两种类型的对抗样本的模型预测之间的L2 距离的平方值,公式为:
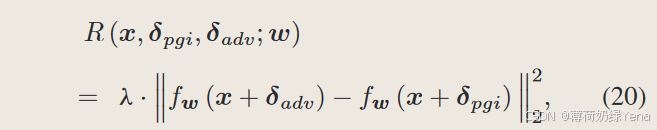
结合初始化和正则化,本文的快速对抗训练框架可以表述为:
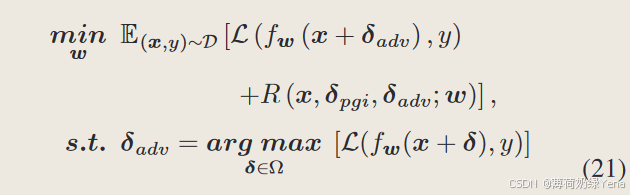
E. The Proposed Ensemble Weight
详细来说,在每次训练迭代中,可以通过计算训练模型权重 w的指数加权移动平均(EMA),结合衰减率κ,得到一个加权平均模型权重w。 WA模型权重的计算如下:
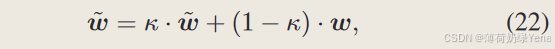
其中 κ 设置为 0.999,WA 模型 ̃ w 通常能够对未见过的测试数据获得更好的泛化能力。
由于直接将权重平均应用于快速对抗训练也会遭受灾难性的过度拟合,并且对抗鲁棒性的提高有限。具体来说,如表I所示,可以观察到FGSM-RS与原始权重平均(FGSM-RS-EMA)相结合有限地提高了对抗鲁棒性,并且在最后epoach上展示出了灾难性的过拟合。
为了克服上述缺点,我们根据模型的稳健程度提出了一种简单而有效的权重平均方法动态衰减率机制。具体来说,在权重平均更新轨迹期间,我们为具有不同鲁棒性的模型分配不同的衰减率,即,更鲁棒的模型参数被分配较小的衰减率。这样可以减少鲁棒性较差的模型参数对最终模型的影响。正如我们在第 III-A 节中讨论的,在快速对抗训练中,生成的对抗示例的质量与模型的鲁棒性直接相关。为了不增加额外的训练时间,我们采用生成的用于训练的对抗样本质量来间接衡量当前训练模型参数的鲁棒性。我们采用生成的对抗样本的准确率与干净样本的准确率之比来评估对抗样本的质量。它可以表述为:
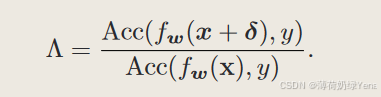
然后我们采用Λ来获得模型权重平均值的动态衰减率。可以计算为

其中ν是阈值超参数,用于生成动态衰减率̃κ。我们将固定衰减率 κ 替换为指数加权移动平均线的动态衰减率 ̃ κ ,称为 D-EMA。 Λ 代表对抗样本质量。当Λ很大时,生成的对抗样本质量较差,并且更新的模型权重不太稳健,甚至可能遇到灾难性的过拟合。使用所提出的方法可以减少它们对权重平均更新轨迹的影响。如表1所示,可以看出,与原始的FGSM-RS-EMA相比,所提出的FGSM-RS-D-EMA不仅可以防止灾难性的过拟合,而且可以在所有攻击场景下实现更好的对抗鲁棒性性能。
为了进一步探讨该方法的有效性,我们计算了 FGSM-RS 模型、FGSMRS-WA 模型和 FGSM-RS-WWA 模型在训练过程中的鲁棒演化。结果如图4所示。可以看出,FGSM-RS-WA可以延缓灾难性过拟合的发生,但不能阻止它。所提出的 WWA 方法可以防止灾难性的过度拟合。这是因为,如果比率 Λ ≥ ν,我们的 WWA 会以较小的衰减率更新模型,因为该比率 ≥ ν 的模型可能是非鲁棒的。为了验证这一点,我们计算了 FGSM-RS 训练阶段的比率。结果如图5所示。分析如下。我们发现,75%的模型在早期(0-4个epoch)超过ν,15%在中期(4-70个epoch),100%在后期(70-110个epoch)。非鲁棒模型主要集中在早期和后期。这是合理的,因为早期和后期的模型都是非鲁棒的。早期模型识别性能较低 Acc(fw(x + δ),y) 和 Acc(fw(x),y) 接近且精度较低。整合它们是没有意义的。在后期,Acc(fw(x + δ),y) 和 Acc(fw(x),y) 接近并且精度很高,但会发生灾难性的过拟合。整合它们将遭受灾难性的过度拟合。因此,使用所提出的方法可以有效防止灾难性的过度拟合并提高模型的对抗鲁棒性。
伪代码:
F.理论分析
实验
- 干净和鲁棒准确性效果
1)CIFAR-10 上的结果:
-
在ResNet18上,所提出的FGSM-PGK可以在所有攻击场景下以更少的训练时间获得更好的对抗鲁棒性。
-
在WideResNet34-10上,FGSM-PGK 在所有攻击场景下都实现了最佳的对抗鲁棒性,而且花费时间明显较少。
-
使用带有循环学习率策略。FGSM-PGK 方法表现出与使用多步学习率策略训练的模型相似的特征。
2) 在CIFAR-100上的结果
对于 CIFAR-100,我们使用 ResNet18 作为主干。比大部分方法快,实现了最好的鲁棒性方法。
3)在Tiny ImageNet上的结果
Tiny ImageNet数据库比CIFAR-10和CIFAR-100覆盖了更多的图像和类别,这需要更多的训练时间来执行对抗性训练。具体来说,多步骤 PGD-AT 需要大约 30.1 小时才能实现对抗鲁棒性。但所提出的 FGSM-PGK 仅需要约 8.6 小时,比 PGD-AT 快 3.6 倍,并且在所有攻击场景下都比 PGD-AT 获得更好的对抗鲁棒性。
4)ImageNet上的结果:结果列于表VII中。我们提出的 FGSM-PGK 方法比 PGD-AT 具有更高的清洁度和鲁棒精度。
5)结果与额外数据相结合:在本文中,我们系统地探讨了使用额外数据对快速对抗训练的影响。。训练期间鲁棒性的演变如图8所示。很明显,使用额外生成的数据可以延迟灾难性过拟合的发生,但不能防止灾难性过拟合。具体来说,FGSM-RS 在 epoch 70 遇到灾难性过拟合,但 FGSM-RSDDPM 在 epoch 200 遇到灾难性过拟合。所提出的 FGSM-PGK 与额外生成的数据相结合,不仅可以防止灾难性过拟合,还进一步提高了模型的对抗鲁棒性。结果示于表VIII中。显然,使用额外生成的训练数据可以在所有攻击场景下获得更好的清洁精度和对抗鲁棒性精度。
-
消融
-
先验引导初始化:仅使用先验引导的初始化可以有效防止灾难性的过拟合,并带来一定的对抗鲁棒性提升。
-
先验引导初始化 + 正则化器:当结合正则化器时,对抗鲁棒性在所有攻击场景下都有显著提高,但训练时间也相应增加。
-
先验引导初始化 + 权重:结合先验引导的权重与初始化相比,训练时间相同,但对抗鲁棒性提升更显著。
-
全部结合:当三者全部结合时,在几乎不增加训练时间的情况下,实现了最佳的对抗鲁棒性性能。研究表明,先验指导知识具有兼容性,结合使用能够带来最优的对抗鲁棒性。
-
参数
-
超参数 μ(衰减因子):
CIFAR-10:最佳衰减因子为 0.3,此时对抗鲁棒性最佳。CIFAR-100:最佳衰减因子为 0.4.TinyImageNet:最佳衰减因子为 0.2。
-
超参数 λ(lambda):
CIFAR-10:λ 值设为 8.0 时实现了最佳对抗鲁棒性。CIFAR-100 和 TinyImageNet:λ 值设为 10.0 时,模型在所有攻击场景下的鲁棒性最佳。
-
超参数 ν(阈值):
CIFAR-10 和 CIFAR-100:阈值 ν 最优设置为 0.82,在所有攻击场景中都能实现最佳性能。TinyImageNet:阈值设为 0.9 时取得最佳效果
所有三个超参数在不同数据集上的最佳值略有不同,但该方法整体对超参数的变化并不敏感。
- Performance Analysis
平坦对抗性损失曲线:
-
之前的研究指出,平坦的对抗性损失曲线表明模型在应对对抗攻击时更为鲁棒(即模型对扰动的敏感度较低)。
-
在本实验中,研究者通过生成损失景观来分析不同方法下的对抗损失。损失景观是在由随机方向(v方向)和对抗方向(u方向)定义的线性空间内改变输入来生成的。
-
结果显示,与之前的方法相比,FGSM-PGK 方法在对抗方向上的交叉熵损失更具线性,即损失曲线在局部区域更平滑。
-
这表明,使用先验指导知识能够更好地保持目标模型的局部线性,使模型在应对对抗样本时表现出更高的稳定性和鲁棒性。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









