







原文标题: GuardT2I: Defending Text-to-Image Models from Adversarial Prompts
原文代码: https://github.com/cure-lab/GuardT2I
发布年度: NeurIPS
发布期刊: 2024
摘要
Recent advancements in Text-to-Image models have raised significant safety concerns about their potential misuse for generating inappropriate or Not-Safe-ForWork contents, despite existing countermeasures such as NSFW classifiers or model fine-tuning for inappropriate concept removal. Addressing this challenge, our study unveils GUARDT2I, a novel moderation framework that adopts a generative approach to enhance Text-to-Image models’ robustness against adversarial prompts. Instead of making a binary classification, GUARDT2I utilizes a large language model to conditionally transform text guidance embeddings within the Text-to-Image models into natural language for effective adversarial prompt detection, without compromising the models’ inherent performance. Our extensive experiments reveal that GUARDT2I outperforms leading commercial solutions like OpenAI-Moderation and Microsoft Azure Moderator by a significant margin across diverse adversarial scenarios.
背景
对人类来说看似无害的复杂对抗性提示可以操纵这些模型来产生明确的不安全工作(NSFW)内容,例如色情、暴力和政治敏感性,从而显着提高安全挑战,如图1(b)所示。
现有的 T2I 模型防御方法大致可分为两类:training interference和post-hoc content moderation。training interference关注于在在训练过程中利用像数据集过滤或微调等策略删除不恰当的概念,以忘记NSFW的概念。虽然它可以有效抑制 NSFW 的产生,但在正常使用情况下通常会损害图像质量,并且仍然容易受到对抗性攻击。另一方面,post-hoc content moderation可以保持合成质量。这些方法依靠文本或图像分类器来识别和阻止恶意提示或生成的内容。然而,他们很难有效地防御对抗性提示
创新点
在本文中,我们介绍了一种名为 GUARDT2I 的新防御框架,专门用于保护 T2I 模型免受对抗性提示的影响。我们的主要观察结果是,虽然对抗性提示(如图 1 (b) 所示)与显式提示相比可能具有明显的视觉差异,但它们在 T2I 模型的潜在空间中仍然包含相同的底层语义信息。因此,我们将对抗性提示的防御视为一项生成任务,并利用大语言模型(LLM)的力量来有效处理隐式对抗性提示中嵌入的语义。具体来说,我们将LLM修改为条件LLM c·LLM,并对c·LLM进行微调,将提示的潜在表示“翻译”回纯文本,从而可以揭示用户的真实意图。对于合法的提示,如图1(c)所示,GUARDT2I尝试重建输入提示,如图1(c)的提示解释所示。对于对抗性提示,GUARDT2I 不会重构输入提示,而是尽可能生成符合对抗性提示的底层语义的提示解释,如图 1(d)所示。因此,通过估计输入和合成提示解释之间的相似性,我们可以识别对抗性提示。
模型
- overview
如图 2 (a) 所示,T2I 模型依靠文本编码器 τ (·) 将用户的提示 p 转换为嵌入 e 的指导,定义为 e = τ § ∈ R^d。这种嵌入有效地规定了扩散模型生成的图像的语义内容。我们观察到,表示为 p_adv 的对抗性提示(对人类来说可能是良性的或无意义的)可以在 T2I 模型的潜在空间中包含与显式提示相同的底层语义信息,从而导致扩散模型生成 NSFW 内容。
通过Prompt Interpretation,可以很容易地识别出对抗性提示(见图2(c))。具体来说,当给定一个正常提示的指导嵌入时,如图 1(c)所示,GUARDT2I 模型准确地重建了略有变化的输入提示。然而,当遇到对抗性提示的指导嵌入时,如图 2(b)所示,生成的提示解释将与原始输入显着不同,并且可能包含明确的 NSFW 单词,例如“sex”和“fuck”,很容易区分。此外,生成的提示解释增强了决策透明度,如图2(d)所示。
- Text Generation with c·LLM.
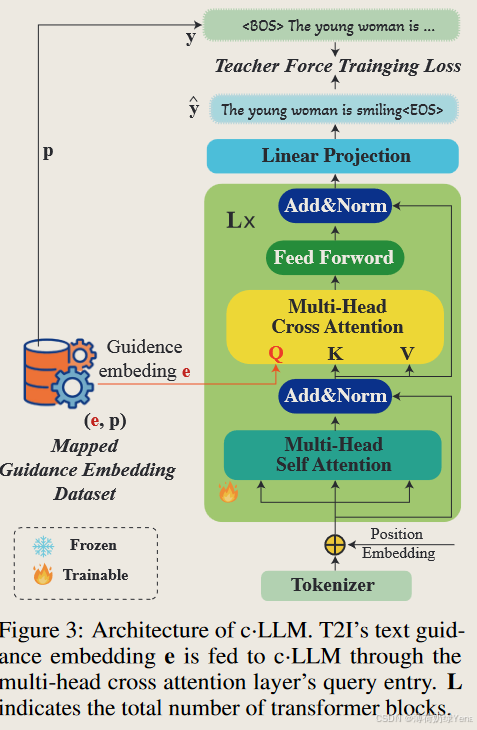
由于潜在向量的隐含性,将潜在表示 e 翻译回纯文本提出了重大挑战。为了解决这个问题,将其视为条件生成问题,并将交叉注意模块合并到预训练的 LLM 中,从而产生条件 LLM (c·LLM) 来完成此条件生成任务。具体来说,我们采用仅解码器架构,由 L 个堆叠的 Transformer 层组成,如图 3 所示,并在每个 Transformer 块中插入交叉注意层。这些交叉注意力层接收嵌入 e 的指导作为查询,并利用缩放点积注意力机制来计算注意力分数,如下所示:
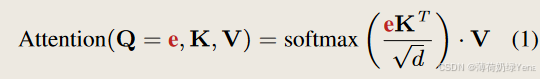
最后,c·LLM 最后一层的输出通过线性投影层投影到标记空间并转换为文本。
为了微调 c·LLM,本文还整理了一个源自 LAION-COCO 数据集的子数据集,作为训练集,表示为 D。值得注意的是,源数据集 D 应该是未过滤的,这意味着它自然包含安全工作 (SFW) 和 NSFW 提示。我们将数据集 D 中的每个提示(p)输入到 T2I 模型的文本编码器中,得到对应的指导嵌入(guidance embedding),用公式表示为:e=τ§∈Rd。这个过程生成的数据集由一对对的指导嵌入 和对应的提示组成(即 e,p)。这个新生成的数据集被称为 映射指导嵌入数据集(Mapped Guidance Embedding Dataset),简称 De,它将用于训练我们的 c·LLM 模型。
对于从数据集 De 中给定的一个训练样本 ( e i , p i ) (e_i, p_i) (ei,pi),任务是让 c·LLM 生成一个解释后的提示令牌序列 y ^ = ( y ^ 1 , y ^ 2 , . . . , y ^ n ) \hat{y} = (\hat{y}_1, \hat{y}_2, ..., \hat{y}_n) y^=(y^1,y^2,...,y^n),这个序列是根据 T2I 模型的指导嵌入 e 来生成的。
在这个过程中,遇到了一些挑战包括:信息丢失:当将指导嵌入 e 压缩成一个向量时,可能会丢失一些信息。任务不匹配:c·LLM 模型通常在预训练时做的任务与当前这个“条件生成”任务不完全相同,这可能会影响模型的生成效果。
这些挑战可能会导致解码器在只依赖于e来重建目标提示 p 时表现不佳,就像图 3 所示那样。为了解决这个问题,我们采用teacher forcing训练技术。在这种技术下,c·LLM 在训练时不仅使用指导嵌入 e,还会同时使用真实的目标提示 p。这样,模型可以更好地学习如何从 e中生成正确的提示。
通过参数化 c·LLM(用θ表示)来进行训练,并且优化的目标是最小化每个提示令牌位置 t上的 交叉熵损失(cross-entropy loss),该损失函数是基于e来计算的。因此,假设提示 p 的令牌序列为 y=(y1,y2,…,yn),那么损失函数可以表示为:
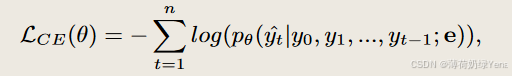
上述目标公式(2)的基本概念旨在调整 c·LLM,最小化预测的令牌序列和目标令牌序列之间的差异。教师强制技术确保模型在生成的每一步都能接触到gth的 p,从而使模型能够更准确地预测序列中的下一个令牌。
- A Double-folded Generation Parse Detects Adversarial Prompts.
在用纯文本揭示输入提示的真实意图后,引入了包括Verbalizer和句子相似度检查器的双层解析机制来检测恶意提示。
首先,Verbalizer,V(·,S)作为一种简单直接的调节方法,用于检查提示解释是否包含任何明确的单词,例如“ “fuck”。这里,S表示开发者定义的NSFW单词列表。值得注意的是,S 具有很强的适应性,允许实时更新以包含新兴的 NSFW 词汇,同时保持系统针对不断变化的威胁的有效性。
此外,利用句子相似性检查器来检查文本空间中的相似性。对于良性提示,其提示解释应与其自身相同,表明推理过程中具有较高的相似性。相比之下,对抗性提示揭示了攻击者的模糊意图,导致与原始提示存在显着差异。我们使用已建立的句子相似性模型来衡量这种差异,将低相似性标记为潜在恶意。
实验
- settings
- Baseline
OpenAI 审核将 NSFW 主题分为五种类型,包括性内容、仇恨内容、暴力、自残和骚扰。如果这些类别中的任何一个被标记,则提示将被拒绝。 Microsoft Azure 内容审核器作为基于分类器的 API 审核器,专注于露骨和攻击性的 NSFW 主题。 AWS Comprehend将 NSFW 提示检测视为二元分类任务。如果模型将提示分类为有毒,则会被拒绝。 NSFW-text-classifier是一个开源的二进制 NSFW 分类器。 Detoxity能够检测四种类型的不当提示,包括色情内容、威胁、侮辱和基于身份的仇恨。SLD[38]和ESD[11]是概念擦除方法,旨在降低NSFW生成的概率。
- 评估指标
拒绝对抗性提示是一个检测任务,我们采用标准指标,包括 AUROC、AUPRC 和 FPR@TPR95。AUROC 和 AUPRC 的较高值表示性能优越,而较低的 FPR@TPR95 值更为理想。
2. Main result
- result
GUARDT2I 在关键性能指标方面始终优于现有方法。GUARDT2I 实现了最高平均 AUROC 98.36% 和最高平均 AUPRC 98.51%。此外,GUARDT2I 在最大限度地减少误报和攻击成功率方面表现出卓越的有效性,平均 FPR@TPR95 为 19.26%,平均 ASR 为 8.75%,两者均显着低于比较基线。
- GUARDT2I 对正常用例影响很小
表2 的 FPR@TPR95 结果证实了 GUARDT2I 对正常提示无害,显示 FPR 显着降低 18.39%,比表现最佳的基线平均值低 89.23%。在高 FPR 会影响用户体验的实际场景中,该指标至关重要。
此外,我们还使用了 FID 和 CLIP-Score 指标来评估 GUARDT2I 的表现,这两个指标用来衡量生成图像的质量和文本与图像之间的对齐程度,结果见表格 3。
- 针对各种对抗性提示的普遍性
GUARDT2I 在不同阈值下表现出强大且一致的结果,如图 5 中的黑色 ROC 曲线所示。可以看到OpenAI Moderation在SneakyPrompt 上表现异常出色,但是在 MMA-Diffusion上效果下降较多。相比之下,GUARDT2I 进行生成式操作,分析每个提示的相似性或 NSFW 单词,从而对不同的对抗性提示提供更准确、适应性更强的响应。
- 针对不同 NSFW 概念的通用性
如图 6 所示,GUARDT2I 在 I2P 的五个 NSFW 主题中始终获得超过 90% 的 AUROC 分数,表明始终如一的高性能。相比之下,当面对不同的 NSFW 主题时,基线表现出显着的性能波动。这种不一致主要源于这些模型是在有限的 NSFW 数据集上进行训练的,这阻碍了它们泛化到未见过的 NSFW 主题的能力。另一方面,我们提出的 GUARDT2I 模型利用了 c·LLM,受益于大规模语言数据集的无监督训练。这种方法使其能够对不同概念有广泛的理解,从而增强其跨不同 NSFW 主题的泛化能力。
- 可解释性
GUARDT2I 生成的提示解释如表4所示。如表所示。如图 4 的上半部分所示,当呈现正常提示时,我们的 GUARDT2I 模型展示了其基于相关 T2I 的潜在指导嵌入重建原始提示的能力。在对抗性提示的背景下,提示解释的重要性变得更加明显。如表所示。在图 4 的下半部分,GUARDT2I 将对抗性提示的相应文本指导解释为嵌入到可读句子中。这些句子作为即时解释,可以揭示攻击者的真实意图。如图 7 所示,原始对抗性提示的突出单词似乎对工作来说是安全的,而在我们的 GUARDT2I 解析后,我们可以得到它们的实际意图。提供可解释性的能力是 GUARDT2I 的一个显着特征,将其与通常缺乏这种透明度的基于分类器的方法区分开来。此功能不仅使 GUARDT2I 脱颖而出,而且还通过阐明决策过程增加了重要价值,为 T2I 开发人员提供了更深入的了解。
3. 自适应攻击
考虑到攻击者对 T2I 和 GUARDT2I 都有完整的了解,修改了最新的 MMA-Diffusion 加上对GUARDT2I的攻击。
结果表明,由于优化方向相互冲突,对整个系统的自适应攻击具有挑战性。具体来说,LT2I 的目标是根据 T2I 的嵌入找到出现不同且恶意语义的提示。另一方面,根据 T2I 模型的嵌入,GUARDT2I 要求任何被绕过的提示保持接近其语义。因此,“GUARDT2I 绕过率”的增加会导致“T2I NSFW 生成率”的降低,反之亦然。因此,即使对于自适应攻击者来说,躲避 GUARDT2I 也变得很困难,总体“攻击成功率”不高于 16%。在双倍攻击迭代的健全性检查中(1000,每个高级提示约 30 分钟),观察到的最高“自适应攻击成功率”为 24%。相比之下,据[45]报道,Safety Checker 的准确率高于 85.48%。此外,定性结果表明,成功的对抗会导致合成质量下降,如图 8 所示,从而削弱了自适应攻击带来的威胁。为了增强GUARDT2I的稳健性,开发人员可以设置更严格的阈值。如果一些用户仍然担心从替代版主转移到 GUARDT2I,那么他们可以并行使用两者。
4. 消融
表6 探讨了 GUARDT2I 中两个关键组件的作用:Verbalizer 和句子相似性检查器。 Verbalizer 在不同的对抗性提示中显示出不同的有效性,表明其独立处理复杂案例的能力有限。作为补充,句子相似度检查器始终获得高于 91% 的高 AUROC 分数,证明了其有效辨别提示之间细微差异的能力。结合这两种成分可实现最高性能,突出协同效应。 Verbalizer 分析语言结构,而句子相似性检查器评估语义连贯性,共同提供针对对抗性提示的全面防御。
5. 讨论
失败案例分析。我们分析了两种类型的失败案例,涉及假阴性和假阳性。如图9(a)所示,当对抗性提示[38]导致生成有关特朗普的未经授权的T2I内容并被错误地归类为正常内容时,就会出现漏报。为了防止此类错误,我们可以通过包含“Donald Trump”等特定关键字来丰富 Verbalizer。此外,我们还观察到,由于某些术语很少出现,GUARDT2I 偶尔会出现误报。然而,如图9(b)所示,罕见的术语要么很难被T2I模型描述,从而使得误报的危害较小。
计算成本。表 7 比较了 GUARDT2I 和基于图像分类器的事后 SafetyChecker [1] 的计算成本。G UARDT2I 与 T2I 并行运行,允许在检测到有害消息时立即停止生成过程。只要 GuardT2I 的推理速度快于 T2I 模型的图像生成速度,从用户的角度来看,它就不会引入额外的延迟。相比之下,SafetyChecker 需要 50 次迭代的完整扩散过程来对 NSFW 内容进行分类,这使得其效率显着降低。特别是在出现对抗性提示的情况下,GUARDT2I 的响应速度比 SafetyChecker 快大约 300 倍。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









