







原文标题: Semantically Consistent Visual Representation for Adversarial Robustness
原文代码: https://github.com/SkyKuang/SCARL
发布年度: 2023
发布期刊: TIFS
摘要
Deep neural networks have been widely used in various domains owing to the success of deep learning. However, recent studies have shown that these models are vulnerable to adversarial examples, leading to inaccurate predictions. In this paper, we focus on the issue of adversarial robustness by examining it through the lens of semantic information, which drives us to propose a new perspective, i.e., adversarial attacks destroy the correlation between visual representations and semantic word vectors, while adversarial training restores it. Additionally, we discover that the correlation among robust representations of different categories aligns with the correlation among the corresponding semantic word vectors. Based on these empirical observations, we incorporate the semantic information into the model training process and propose Semantic Constraint Adversarial Robust Learning (SCARL). Firstly, inspired by the information-theoretical perspective, we maximize mutual information to bridge the information gap between the visual representations and the corresponding semantic word vectors in the embedding space. We further provide a differentiable lower bound to optimize such mutual information efficiently. Secondly, we introduce a novel semantic structure constraint that maintains the structure of visual representations consistent with that of semantic word vectors. Finally, we integrate these techniques with adversarial training to learn robust visual representations. We conduct extensive experiments on several datasets (such as CIFAR and TinyImageNet) and evaluate the robustness against various adversarial attacks (such as PGD-attack and AutoAttack), demonstrating the benefits of incorporating semantic information for improving model robustness.
背景
以前的研究 表明,从对抗性训练训练的模型中获得的视觉表示对对抗性样本具有良好的鲁棒性。因此,这些初步结果自然而然地提出了一个问题:语义信息对视觉模型的对抗鲁棒性有什么影响?
为了回答这个问题,我们对自然模型和对抗性攻击下视觉表示和语义词向量之间的关系进行了实证分析。我们研究了视觉表示和语义词向量之间的关系在受到攻击时会发生什么变化。图 2 和图 3 中的结果表明,对抗性攻击破坏了视觉表征和语义词向量之间的相关性,但对抗性训练恢复了这种相关性。此外,随着模型变得更加稳健,视觉表示和语义词向量之间的相关性会变得更强。此外,我们还观察到,对抗模型提取的视觉表示可以以与语义词向量一致的方式反映类别之间的语义关联,而自然模型提取的视觉表示则不能。我们的分析表明,稳健的视觉表示和语义词向量密切相关。因此,一个自然的想法是:我们能否将语义信息纳入对抗性训练中,以进一步提高视觉模型的对抗鲁棒性?
然而,对抗性训练有几个关键限制:1) 在大规模图像文本数据集上耗时且计算成本高昂;2) 视觉图像和语义词/文本的表示空间不一致,图像文本数据集经常包含噪声数据;3) 目前没有可靠的方法来评估多模态模型的鲁棒性。
创新点
为了克服这些限制,我们在本文中专注于基本的图像分类任务,并提出了语义约束对抗鲁棒学习 (SCARL) 框架。
具体来说,我们首先制定语义互信息,以弥合视觉表示和语义词向量之间的信息差距,因为视觉图像和语义词之间的表示空间不一致。我们提供了一个互信息下界,可以有效地优化该下界,以使两者的分布信息更接近。其次,我们引入了语义结构约束损失,以使视觉表示的结构与词向量的结构保持一致。目的是使视觉表示能够反映不同类别之间的语义关联,例如语义词向量。最后,我们将上述两种技术与对抗性训练相结合,以学习一个稳健的模型。
定性分析和结果
我们通过分析不同的模型如何表示自然/对抗图像与相关性和关联的语义词之间的关系来开始我们的研究。我们主要考虑两种不同的模型,即自然模型和对抗模型。自然模型使用良性图像的正常训练进行训练,对抗模型使用标准对抗训练(即基于 PGD 的 AT)进行训练 。
- Analysis 1: Canonical Correlation Analysis
我们使用典型相关性分析 (CCA) 技术来分析视觉表示和语义词向量之间的分布相关性。具体来说,我们计算了不同训练模型下自然/对抗性视觉表示和语义词向量之间的相关系数。结果如图 2 所示。
首先,我们分析自然模型的相关性属性。图 2 (a) 显示了输入为自然图像时的结果。自然图像的表示与其相应的语义词向量具有高度相关性。然而,当输入是对抗性图像时,如图 2 (b) 所示,视觉表示和语义词向量之间的相关性显着下降。根据这些结果,我们推断对抗性示例实际上破坏了自然模型的语义信息,这与前面的观察结果相呼应。
其次,对抗模型的评估结果如图 2 (c) 和 (d) 所示。我们观察到,对抗模型可以在面对对抗图像时保持语义相关性。此外,基于 PGD 的对抗模型比基于 FGSM 的对抗模型具有更强的相关性。这意味着模型越稳健,2 相关性就越强。
基于上述观察,我们得出结论,视觉表示和语义词向量之间的相关性被对抗性攻击破坏,但被对抗性训练恢复。
- Analysis 2: Semantic Association Relationships
通常,一个训练有素的词嵌入模型可以看作是一个知识图谱[42],[49],其中词之间的关联关系可以用学习到的语义向量来表示[50],[51]。作为对这个想法的回应,我们将各种表示的相似性矩阵可视化,以检查语义类比关系。
首先,我们在图 3 (a) 中展示了 CIFAR-10 上词向量的相似性矩阵,其中词向量是从预先训练的手套模型中提取的 [14]。在这个图中,我们发现第 3 类(即猫)和第 5 类(即狗)之间的相关性比第 3 类和第 9 类(即卡车)之间的相关性更强。关联关系与我们人脑的认知一致,即猫和狗在外表和属性上相对相似,而猫和汽车没有关系。
其次,我们绘制了不同类别的视觉表示之间的相似性。图 3 (c) 中的结果表明,对抗模型提取的视觉表示也可以反映不同类别之间的关联关系。它类似于语义词向量所反映的关系。然而,与图 3 (c) 相比,自然模型提取的视觉表示无法反映关联关系(如图 3 (b) 所示)。
此外,CLIP 模型 [1] 使用大规模的图像文本对来学习强大的语义表示。因此,我们将 CLIP 提取的视觉特征的相似性矩阵可视化,如图 3 (d) 所示。结果表明,CLIP 模型呈现的关联关系也令人困惑,这与自然模型相似。也就是说,与 Glove 特征相比,当前的视觉模型(在标准训练或对抗训练下)无法准确反映关联关系。
根据我们的两项分析,我们得出结论,稳健的视觉表示应该 (i) 更接近它们相应的相似语义词向量;(ii) 能够反映接近语言模型的语义关联关系。
模型
作为对上述分析的回应,目标是对齐视觉表示和词向量的特征分布。具体来说,提出了两种新技术:1) 最大化语义互信息和 2) 保留语义结构。最后,将这两种技术与对抗性训练相结合,以学习一种称为语义约束对抗性鲁棒学习 (SCARL) 的稳健模型。
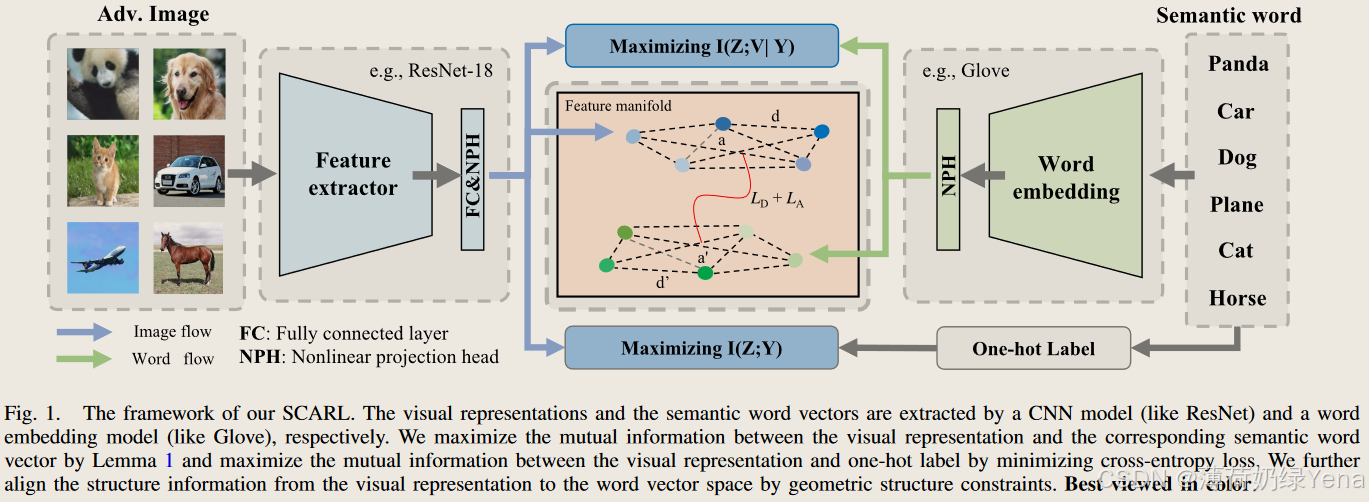
- Maximizing Semantic Mutual Information
在标准分类任务中,目标是训练分类器 y = Fθ (x) = c ⊙ h(x),使其能够根据表示 Z 预测 Y。从信息论的角度来看,可以看作是 Z 和 Y 之间的互信息最大化:
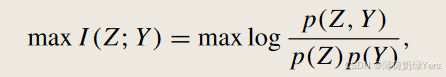
为了融入语义信息,提出了语义互信息来弥合视觉表示和语义词向量之间的信息鸿沟,其表述如下:max I(Z; Y, V).
请注意,目标是增强视觉表示 Z 中的语义信息,它来自单词向量 V。然而,直接优化方程 (6) 是困难的,因为分布 V 是未知的。为了解决这个问题,将方程 (6) 分解为两个项,如下所示:
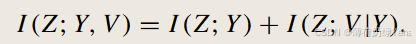
第一项 I (Z ;Y ) 可以很容易地表示为交叉熵损失。为了优化第二项 I (Z ;V |Y ),受对比学习的启发,推导出了一个可优化的下界 −Lin f o,如以下引理所示:
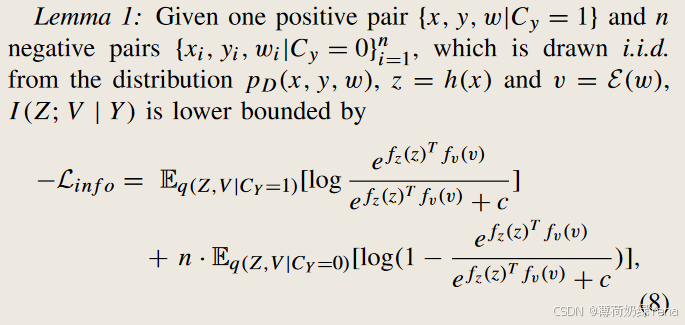
根据引理 1,最终可以使用一批样本(包括正负对)来计算 Lin f o,然后将其最小化以最大化 I (Z ;V |Y )。请注意,在引理 1 中的结果包含两部分。第一部分最大化图像和相应的语义词之间的信息。第二个选项将图像与不匹配的语义词之间的信息降至最低。直观地说,引理 1 的公式类似于度量学习的基本目标:在某个度量空间中,将正对之间的表示拉近,并推开负对之间的表示。与典型的度量学习不同,本文的方法是从信息论的角度衍生而来的,可以看作是通过优化互信息进行的特殊度量学习。
- Preserving Semantic Structure
语言词中的关联关系仍然被忽略,它可以呈现词之间的类比和相关性。因此,进一步提出了一种语义结构约束损失,即保持视觉表示的结构与语义词向量的结构一致。主要目标是使视觉表示能够保持由相应的语义词向量构建的语义关联关系。
假设 pD(x, y, w) 具有 K 个类。将视觉表示中心定义为 Simage = {s1, . . . , sk},这是代表数据集 pD 的 K 个顶点的集合。每个顶点 si 都是质心向量,表示邻域内的一类特征向量。同样,定义单词向量中心 Tword = {t1, . . . , tk }。
要获取 Tword ,首先使用表示空间中的随机点初始化其值。然后,使用动量规则迭代更新 ti:
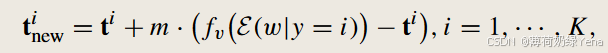
其中 Tinew 表示更新的顶点,超参数 m ∈ [0, 1) 是动量系数。E(w|y = i) 表示条件词嵌入(即对应于给定 one-hot 标签的语义词嵌入)。方程 (9) 确保顶点随着训练的进行而向中心稳定地迈进。
对于视觉表示中心,为每个训练时期中每个顶点的观测值构建一个新的中心si_{new}。si_{new}是通过小批量样本中同一类的平均表示来估计的:
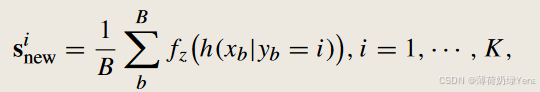
其中 B 表示批量大小,h(xb|yb = i) 是条件表示提取。然后,让 Tword 限制 Simage 以使其一致。为此,提出了两个几何关系对齐指标:距离对齐和角度对齐方案。它们都将视觉表示的结构与语义向量的结构对齐,如图 4 所示。
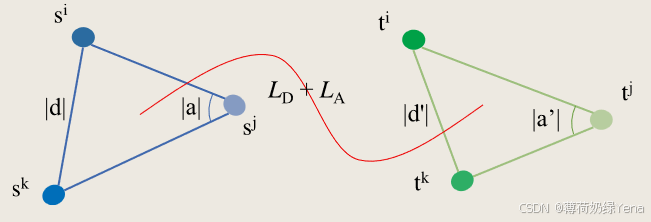
1) Distance-Wise Aligning:
给定一对视觉表征中心{si,sj}和一个距离函数φ D,计算了表征空间中两个中心之间的距离(例如,欧氏距离):
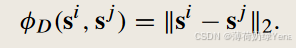
类似地,可以计算两个词向量中心之间的距离:φ D( ti , tj)。然后,将基于距离的对齐损失表示为:
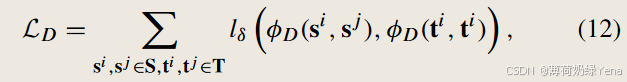
距离对齐损失通过惩罚它们的类中心之间的欧氏距离差异来保持视觉表示和词向量的结构。
2) Angle-Wise Aligning:
给定一个三元组训练中心{si,sj,sk},在表示空间中分别计算不同视觉中心的相对角度:
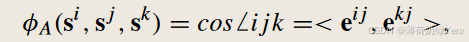
角度对齐损失公式为
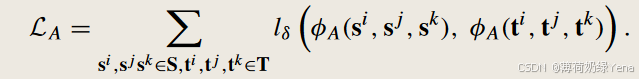
- Adversarial Training With Semantic Constraint
语义约束对抗性鲁棒学习(SCARL)包含以下三个组成部分:
1) Maximizing I (Zadv; Y ) on Adversarial Example Xadv:
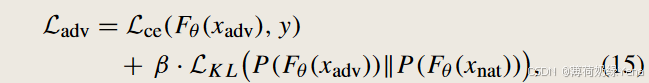
2) Maximizing I (Zadv; V |Y ) on Adversarial Example Xadv:
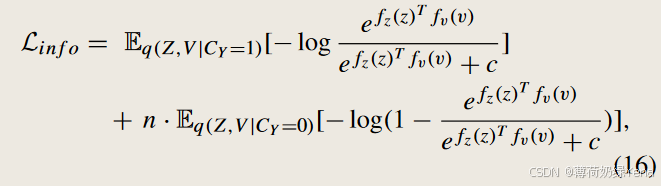
3) Restricting Simage with Tword
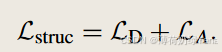
因此,最终整体的损失:
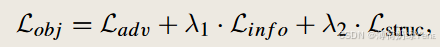
实验
- Benefits From Semantic Information
我们在表二中报告了不同模型的鲁棒性,其中鲁棒性越好,分类精度越高。我们发现,在大多数情况下,使用语义信息训练的模型比没有语义信息训练的模型更稳健,这表明语义信息有利于模型的稳健性。为了进一步验证语义信息对模型鲁棒性的影响,我们计算了用语义信息训练的AT的CCA。 CCA为0.84,这意味着模型通过使用词向量作为监督信息学习到的视觉表示比标准对抗训练[4](0.79)具有更多的语义信息。 CCA的可视化如图5所示。此外,我们还在CIFAR-10和CIFAR-100数据集上进行了单步对抗训练的实验[20]、[64]、[65]。我们选择 GAT [64] 作为我们的基线方法。我们在表三中报告了针对不同对抗性攻击的自然准确性和鲁棒准确性的结果。结果表明,我们提出的方法仍然可以与单步 AT 结合,并实现新的最先进的鲁棒性。我们进一步验证了我们的方法在自适应攻击下的鲁棒性[66],其中攻击者拥有对词嵌入模型的知识和白盒访问权限。我们使用基于 PGD 的自适应攻击来评估标准 AT、TRADES 及其使用 CIFAR-10 上预激活 ResNet-18 进行语义信息训练的相应模型。结果如表I所示。PGD-CE表示标准PGD攻击,其中损失函数是交叉熵损失。 PGD-KL 表示对抗样本是通过最大化 KL 散度生成的。 PGD-SI表示通过最大化语义信息约束损失来生成对抗样本(式(16)和式(17))。结果表明,用语义信息训练的模型仍然可以抵御自适应攻击,即使攻击者知道我们正在使用语义信息进行防御。
- Comparisons With Other Methods
为了验证所提出的方法可以有效提高模型的鲁棒性,我们将其与几种最先进的对抗训练模型进行比较并报告对抗鲁棒性。我们采用大容量网络(例如 WideResNet [59])来训练目标模型,因为许多工作已经证明大型模型通常更有利于更好的对抗鲁棒性 [4]、[37]、[67]。表 V 报告了 CIFAR-10 和 CIFAR-100 上针对不同攻击(即 PGD 攻击和 AutoAttack)的最佳测试鲁棒性。如表所示,与之前最先进的方法相比,我们的 SCALR 在 AutoAttack 下的 CIFAR-10 和 CIFAR-100 上的最佳鲁棒性分别提高了 1.37% 和 0.52%。此外,当与对抗性权重扰动(AWP)[31]相结合时,我们还可以在AutoAttack下实现最佳的鲁棒性,其中鲁棒性的轻微提升是显着的。因此,结果证明了所提出的 SCARL 的有效性。请注意,我们的实验没有使用额外的数据集。
此外,我们使用具有不同攻击预算和迭代次数的 PGD 攻击进行实验,并绘制对抗精度的结果。对于不同的攻击预算,攻击步长固定为10。对于不同的攻击迭代,攻击预算固定为8/255。结果如**图6(a)和(b)**所示。 SCARL 训练的模型在更大的预算下比标准 AT 和 TRADES 更好。此外,我们的 SCARL 对于大迭代攻击是稳定的,例如 500 步迭代的 PGD 攻击。因此,结果进一步证明了我们提出的方法的有效性。
- Semantic Robustness Analysis
在我们的实验数据集中,某些类别对应于相似的语义词向量,例如“猫”和“狗”。值得注意的是,这种相似性是相对的,例如,“猫”和“狗”的相似性比“猫”和“卡车”的相似性更强。事实上,不同的词向量之间存在一定的距离,经过训练的分类器可以很好地区分(分类准确率可以达到100%)。因此相似性不会干扰训练模型在自然样本上的识别。然而,我们的方法中仍然存在模型[6]、[68]、[69]的自然准确性和对抗鲁棒性之间的权衡。我们在图7中展示了不同模型对于每个类别的自然准确率和鲁棒准确率。通过比较不同类别的自然准确率和鲁棒准确率的变化,我们可以观察到一个趋势:随着类别的鲁棒准确率增加,其自然准确率下降趋于减少。因此,当我们的方法实现更好的鲁棒性时,自然的精度下降是存在的。尽管如此,我们的自然准确度在 CIFAR10 上仍然超过 82.0%,在 CIFAR-100 上仍然超过 58.0%。与原始自然准确率(即TRADES)相比,准确率总体仅下降了不到1.0%,这是可以接受的。此外,为了验证添加语义信息带来的相似性是否使构建对抗性示例变得更加容易,我们进行了两个实验。首先,我们计算不同模型在非针对性 PGD 攻击下每个类别的鲁棒准确性。结果如图7右侧所示。我们可以观察到模型对不同类别的鲁棒性是不同的,并且不同类别之间的鲁棒性差异很大。这意味着不同的类别在构造对抗性例子时有不同的难度。此外,对于带有语义信息的SCARL模型,大多数类别的鲁棒性都得到了提高,只有少数类别(例如“卡车”)有所下降。数据集的整体稳健性得到提高。其次,我们使用目标PGD攻击,使“猫”和“狗”类别相互攻击,并统计不同模型下的攻击成功率(ASR),结果如表六所示。我们可以看到,带有语义信息的SCALR模型的ASR明显小于TRADES,这表明添加语义信息并不容易构造对抗性示例。此外,我们还对语义信息和视觉表示差异较大的类别进行目标攻击,例如“狗”和“卡车”。我们可以看到语义信息也降低了 ASR。
- 消融
对于消融研究,所有比较实验均在 CIFAR-10 上进行,除所使用的对比变量外,所有其他超参数均保持完全相同。 1)消融不同技术:我们验证了SCARL中提出的两种技术,其结果在表VII中给出。从表七中,我们可以观察到每种技术的显着性能提升。这证实了我们提出的技术的优点。 2)与InfoNCE比较:所提出的Lin f o 与InfoNCE[53]类似。 InfoNCE还使用噪声对比估计[81]来估计变量之间的互信息。不同之处在于,InfoNCE 仅从一组数据对中选择单个正样本。相比之下,我们不仅计算正样本,还优化负样本的度量。当使用相同数量的底片时,我们将 InfoNCE 与 Lin f o 进行比较。表 VII 显示我们的 Lin f o 优于 InfoNCE。这证实了所提议的 Lin f o 的优点。 3)语义嵌入的效果:我们使用不同的词嵌入来验证语义信息有利于鲁棒性。我们设计了五种嵌入方案:a)随机:随机向量作为语义词向量; b) NN:词向量由可学习的神经网络嵌入层生成; c) CLIP:词向量由经过训练的CLIP模型生成; (d) BERT:词向量由经过训练的 BERT [82]模型生成; e) Glove:词向量由经过训练的 Glove 模型生成。结果示于表VIII中。实验结果清楚地表明,**使用 Glove 可以获得最佳结果。可能的原因是 Glove 是根据语料库聚合的全局词与词共现统计数据进行训练,**而 BERT 和 CLIP 则是根据句子结构进行训练。 4)批量大小的影响:理论上,所提出的Lin f o 和InfoNCE 可以受益于大批量大小。为了评估批量大小的影响,我们测试了批量大小的六个值,结果如图 6© 所示。随着小批量大小变大,标准对抗训练的性能急剧下降。这证明在我们的实验设置中,对抗性训练不适合大批量。 Lin f o 无法从大批量中受益的另一个原因是,在给定的数据集下,计算 Lin f o 时数据类别的语义词是有限的。即使使用大批量,语义词仍然限制 Lin f o 中负样本的数量。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









