







JavaScript爬取网页并分析
任务分析
- 爬取三个网站下的新闻数据,这里选择网易新闻网(https://news.163.com/);
- 提取每条新闻的如下字段:标题,内容,发表日期,网址,关键词,作者,来源,评论等;
- 将爬取的数据写入数据库;
- 搭建前后端,实现对爬取数据的查询搜索分析等功能;
!!注:这篇博客只会对关键代码进行解析,完整代码在GitHub 中
代码链接:https://github.com/zgl-ai/a-crawler-about-javascript
爬虫部分
首先是爬取网易新闻网(https://news.163.com/)
引入一些必须的包
var fs = require('fs');
var myRequest = require('request')
var myCheerio = require('cheerio')
var myIconv = require('iconv-lite')
require('date-utils');
fs负责文件读写,request负责获得服务端发来的html响应,cheerio负责解析html文件,incov-lite负责html文件的编码格式的转换;
爬取网页的基本信息
var source_name = "网易新闻";
var myEncoding = "gbk";
var seedURL = 'https://news.163.com/';
要注意的是这个网页的编码格式为GBK,之前我使用的是“utf-8”发现出现了乱码。
还有一些字段格式的声明在之后解释。
爬虫的步骤一般如下:
- 向目标服务端发送一个种子页面请求;
- 服务端返回这个页面的html文件;
- 转码,解析文件,获得所需要的tag中信息;
- 如果还需要获取种子页面下一些超链接的信息,那么就需要重复以上几步;
本次的实验也是按照以上的步骤进行的。
首先是构造相应的种子页面请求
//防止网站屏蔽我们的爬虫
var headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.65 Safari/537.36'
}
//request模块异步fetch url
function request(url, callback) {
var options = {
url: url,
encoding: null,
//proxy: 'http://x.x.x.x:8080',
headers: headers,
timeout: 10000 //
}
myRequest(options, callback)
}
这是基于http协议构造的请求信息,包括了头部信息,网址,时间限制等信息。
得到种子页面的html文件后,解码并且解析
var html = myIconv.decode(body, myEncoding);
//console.log(html);
//准备用cheerio解析html
var $ = myCheerio.load(html, { decodeEntities: true });
我们的目的是通过网易新闻网的主页面,访问主页面中的新闻链接来获得新闻的信息。因此接下来我们要做的是,分析网易新闻网主页面中的新闻超链接,判断它是不是一个新闻的超链接(这里只提取文本类新闻)。
通过对比发现,网易所有文本类新闻的URL都有一个共同点:
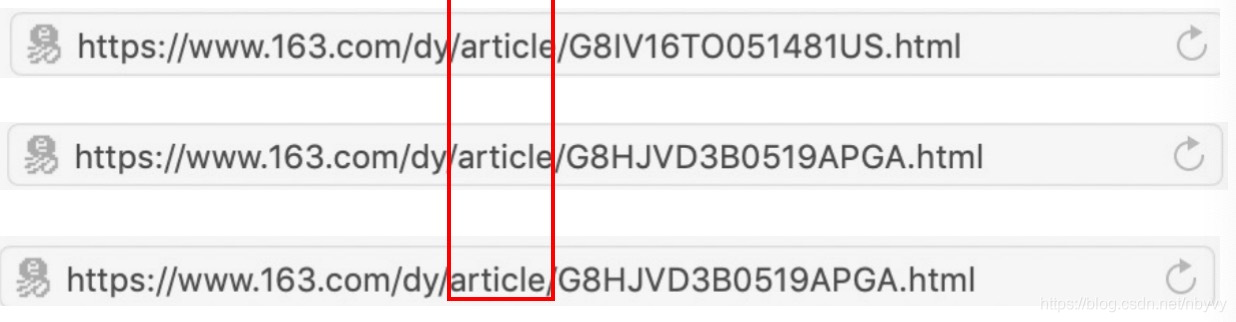
那就是其中都有一个“article”字段。基于此来判断是不是一个有效的新闻链接
首先需要规范一下url的格式:
url不能是“undefined”,意思就是不能为空,
if (typeof(href) == "undefined") { // 有些网页地址undefined
return true;
}
url必须是以大写或者小写的“http://”或者“https://”开头,否则就在前面加上“http:”
路径名规范为https://news.163.com/……
if (href.toLowerCase().indexOf('http://') >= 0 || href.toLowerCase().indexOf('https://') >= 0) {
myURL = href; //http://开头的或者https://开头
//console.log(href);
}
else if (href.startsWith('//')) myURL = 'http:' + href; 开头的
else {
myURL = seedURL.substr(0, seedURL.lastIndexOf('/') + 1) + href; //其他
//console.log(href);
}
规范格式后就需要通过正则表达式的匹配来看有没有article字段:
var url_reg =/article/
if (!url_reg.test(myURL)){
//console.log(myURL);
return; //检验是否符合新闻url的正则表达式
}
接下来就是提取新闻的信息(标题,内容,发表日期,网址,关键词,作者,来源,评论等);
需要分析一下网页的源文件
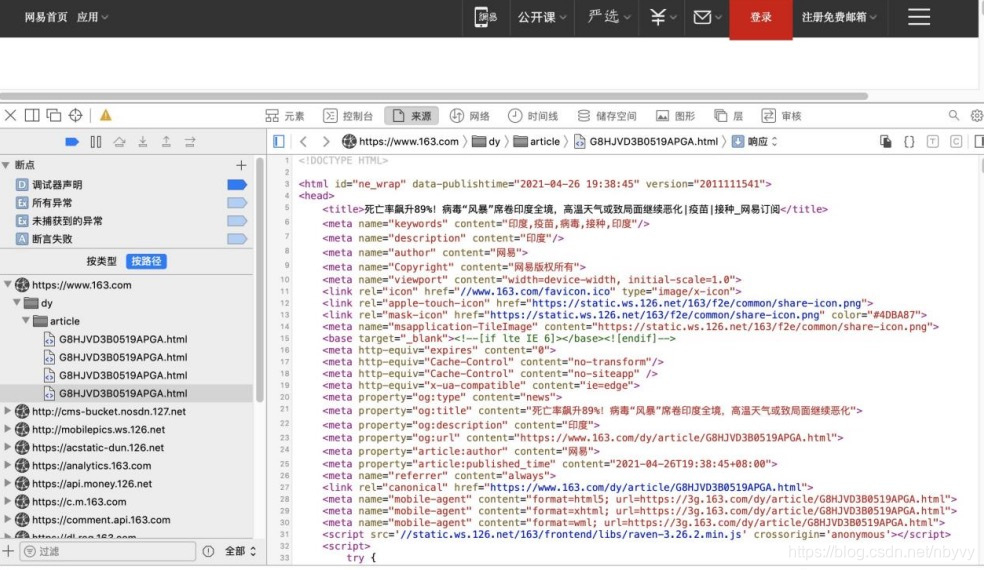
发现标题存放位置,在title标签中
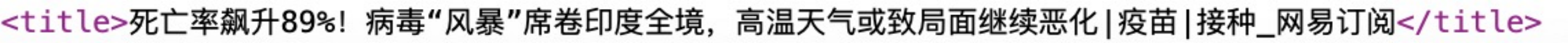
var title_format = "$('title').text()";
关键词存储格式,在标签中的keywords-content键值对中

var keywords_format = " $('meta[name=\"keywords\"]').eq(0).attr(\"content\")";
正文内容是在,“post_body”这一个类别中

var content_format = "$('.post_body').text()";
同理其他的所有的读取格式都通过对比网页源码来获得
var keywords_format = " $('meta[name=\"keywords\"]').eq(0).attr(\"content\")";
var title_format = "$('title').text()";
//<meta property="article:published_time" content="2021-04-26T14:47:04+08:00">
var date_format =" $('meta[property=\"article:published_time\"]').eq(0).attr(\"content\")";
//<meta name="author" content="网易">
var author_format = " $('meta[name=\"author\"]').eq(0).attr(\"content\")";
var content_format = "$('.post_body').text()";
var desc_format = " $('meta[name=\"description\"]').eq(0).attr(\"content\")";
var source_format = "$('.post_info').text()";
将目标信息通过evel读取并且存入fetch结构体中
var fetch = {};
fetch.title = "";
fetch.content = "";
fetch.publish_date = (new Date()).toFormat("YYYY-MM-DD");
//fetch.html = myhtml;
fetch.url = myURL;
fetch.source_name = source_name;
fetch.source_encoding = myEncoding; //编码
fetch.crawltime = new Date();
发表日期的写入的时候要注意
因为有的文章没有发表日期,所以需要填上“未知”,再将所有的日期转换为“YYYY-MM-DD”的格式
if (date_format != "") {
fetch.publish_date = eval(date_format); //刊登日期
if (!fetch.publish_date){
fetch.publish_date = "未知";
}else{
//fetch.publish_date = regExp.exec(fetch.publish_date)[0];
fetch.publish_date = fetch.publish_date.replace('年', '-')
fetch.publish_date = fetch.publish_date.replace('月', '-')
fetch.publish_date = fetch.publish_date.replace('日', '')
fetch.publish_date = new Date(fetch.publish_date).toFormat("YYYY-MM-DD");
}
}
来源部分也需要通过正则表达式来提取
if (source_format == "") fetch.source = fetch.source_name;
else {
fetch.source = eval(source_format).replace("\r\n", ""); //来源
var matchReg = /(?<=来源: ).*?(?=.\n)/gi;
fetch.source=(fetch.source.match(matchReg));
if(fetch.source==null){
fetch.source=source_name;
}
}
完成上面所有的步骤,就可以提取新闻的信息了,一下选取一篇新闻提取的信息来展示

将爬取到的所有信息存储到mysql数据库中
这需要已经提前下载好的mysql数据库,并且创建好crawl库
create database crawl;
use crawl;
创建表fetches
CREATE TABLE `fetches` (
`id_fetches` int(11) NOT NULL AUTO_INCREMENT,
`url` varchar(200) DEFAULT NULL,
`source_name` varchar(200) DEFAULT NULL,
`source_encoding` varchar(45) DEFAULT NULL,
`title` varchar(200) DEFAULT NULL,
`keywords` varchar(200) DEFAULT NULL,
`author` varchar(200) DEFAULT NULL,
`publish_date` date DEFAULT NULL,
`crawltime` datetime DEFAULT NULL,
`content` longtext,
`createtime` datetime DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (`id_fetches`),
UNIQUE KEY `id_fetches_UNIQUE` (`id_fetches`),
UNIQUE KEY `url_UNIQUE` (`url`)
) ENGINE=InnoDB DEFAULT CHARSET=gbk;
JavaScript连接数据库需要相应的包
var mysql = require('./mysql.js');
插入数据库的语句,和插入的变量
var fetchAddSql = 'INSERT INTO fetches(url,source_name,source_encoding,title,' +
'keywords,author,publish_date,crawltime,content) VALUES(?,?,?,?,?,?,?,?,?)';
var fetchAddSql_Params = [fetch.url, fetch.source_name, fetch.source_encoding,
fetch.title, fetch.keywords, fetch.author, fetch.publish_date,
fetch.crawltime.toFormat("YYYY-MM-DD HH24:MI:SS"), fetch.content
];
执行插入语句
//执行sql,数据库中fetch表里的url属性是unique的,不会把重复的url内容写入数据库
mysql.query(fetchAddSql, fetchAddSql_Params, function(qerr, vals, fields) {
if (qerr) {
console.log(qerr);
}
}); //mysql写入
至此,从网易新闻官网爬取数据,并且存入数据库的任务已经完成,数据库里的数据展示如下
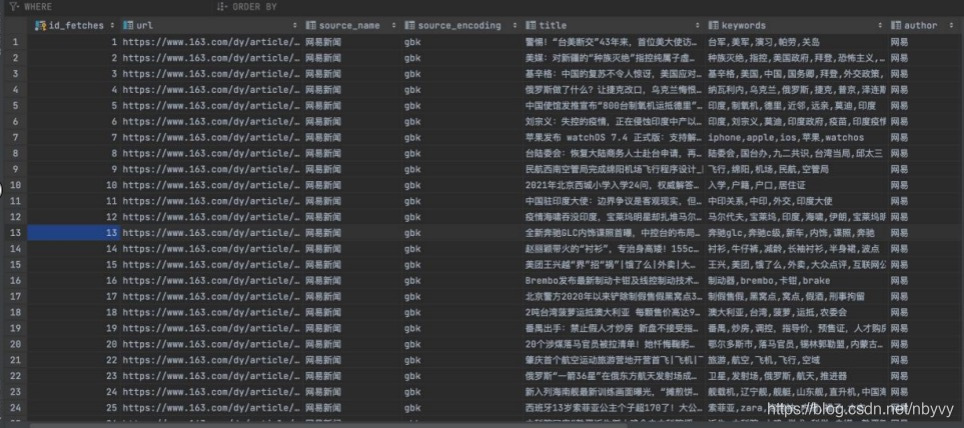
同理还爬取了搜狐(https://www.sohu.com)、腾讯新闻(https://www.qq.com)的新闻。总共的数据有三百多条。工作量不大,就是需要向上文那样,产源码的结构,找出目标字段所在的标签,然后提取出来存入数据库。
因此写了三个爬虫文件分别爬取这三个代码
搜索和分析
这里需要一个前后端交互的功能,用到了express脚手架,具体的搭建方法这里就不详述了。最后可以创建一个路由架构。
主要的工作量是search.html文件,time.html文件和index.js文件。
search.html文件:实验按标题搜索关键词的前端网页。
首先是需要一个表单,来接受用户输入的关键词并传输给后端
<body>
<form>
<br> 标题:<input type="text" name="title_text">
<input class="form-submit" type="button" value="查询">
</form>

用一个表来展示数据库传来的数据
<div class="cardLayout" style="margin: 10px 0px">
<table width="100%" id="record2"></table>
</div>
接下来需要通过javascript语言来与后端交互数据
与后段交互数据:
构造路由与出入数据
$va='/process_get?title=' + $("input:text").val();
传入数据后需要接受后端传来的数据,在data这个变量中
$.get($va, function(data) {
解析data数据存入表record2中
$("#record2").empty();
$("#record2").append('<tr class="cardLayout"><td>url</td><td>source_name</td>' +
'<td>title</td><td>author</td><td>publish_date</td></tr>');
for (let list of data) {
let table = '<tr class="cardLayout"><td>';
$i=0;
Object.values(list).forEach(element => {
if($i==0){
table += ('<a href='+element+'>'+element+'</a>'+ '</td><td>');
}else{
table += (element+'</td><td>');
}
$i++;
});
$("#record2").append(table + '</td></tr>');
这里是一列一列的读取data,然后对每列再一个一个元素的读取。存入的时候需要了解html文件中表格的格式
除此之外,我还把url变成超链接的形式。url位于每一列的第一个元素中。上图的红框所示。
引入一个超链接指向time.html
<a href='time.html'>点击进行时间热度分析</a>
index.js:负责后端的,与数据库交互,与前端交互
首先是search.html路由到的函数
router.get('/process_get', function(request, response) {
//sql字符串和参数
var fetchSql = "select url,source_name,title,author,publish_date " +
"from fetches where title like '%" + request.query.title + "%'";
mysql.query(fetchSql, function(err, result, fields) {
response.writeHead(200, {
"Content-Type": "application/json"
});
response.write(JSON.stringify(result));
response.end();
});
});
收到前端传来的title数据之后,向数据库发送查询命令
Select url,source_name,title,author,publish_date
From fetches
Where title like ‘%……%’
(这个是查询包含关键词$title的语法)
查询之后,结果写到了result变量中,然后以json格式传到前端的data中。
这两个part运行的结果如下:
工作目录下运行node bin/www
浏览器输入:localhost:3000/search.html

time.html文件:实现按照时间热度搜索关键词的前端页面。逻辑和search.html差不多
inde.js中负责处理time.html文件的函数
router.get('/time_get', function(request, response) {
//sql字符串和参数
var fetchSql = "select publish_date,COUNT(keywords) " +
"from fetches where keywords like'%" + request.query.title + "%' GROUP BY publish_date ORDER BY COUNT(keywords) DESC";
mysql.query(fetchSql, function(err, result, fields) {
response.writeHead(200, {
"Content-Type": "application/json"
});
console.log(result);
response.write(JSON.stringify(result));
response.end();
});
});
它在接受到title之后,向数据库发送查询指令
Select publish_date,count(keywords)
From fetches
Where keywords like ‘%……%’
Group by publish_date
Order by count(keywords) desc;
这样可以做到使搜索结果按照发表日期做好统计。
点击这个之后就可以看到运行结果

发现目前统计的新闻数据中,4月27发表的新闻最多。
搜索“裙子”关键词

总结
这次项目的几个难点
- 为了找到新闻url,需要查看很多新闻的url,找到相似处,由于每个企业对网页的格式定义不同,我们也需要相应的改写相关的正则表达式;
- 读取相关字段,如标题,日期作者等等。在选取本次实验的三个种子网页(腾讯,网易,搜狐)之前,我还尝试爬取过虎扑,东方财经等其他新闻网页。但是在爬取过程中总是碰到一些奇怪的问题。比如有的字段藏在了很复杂的标签块中,在爬虫代码中不好以统一的格式定义,因此在代码运行的过程中总是出现爬取到空字段的情况。还有就是每个网站的编码格式不一样,有的是utf-8有的又是gbk,所以在爬取的时候需要都试一试。
虽然如此,这些网页还是会采用一些通用的标准来编写,比如“标题,关键字,摘要”等信息。 - 统一每个网页爬取到的信息。在爬取“时间”这一个字段是,有的网页是“2021-4-29”,有的又是“4/29/2021”,有的又是“2021年4月29号”,虽然统一起来不是很难吧,但也很麻烦。
- 前后端路由。由于对Javascript语法不是很熟悉,所以在编写代码中也遇到很多问题,就比如前后端路由的时候。具体一点,就是前端怎么向后端传数据,后端接受数据后怎么读取出来。后端怎么向前端传数据,前端接收到之后,怎么将json格式的数据读取出来。在搞清语法上花了很多时间。
- 本来之前还想做很多任务的,比如对展示结果进行分页,用css做一个好看一点的前端,在交互上做的好一点。但是自己的这方面知识确实太贫瘠了,作业提交时间也快到了。因此也就完成了这些基本功能。
好在之前有数据库,python flask,php等相关基础,因此还是完成了这次实验。


















 1753
1753

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











