






论文SpeechGPT
背景
1、大语言模型为什么难以同语音相结合
- 目前部分LLM能够理解但是难以生成多模态内容
- 音频信号是连续的,而LLM接受的输入需要离散的,二者存在gap
2、主流的两种语音语言模型(speech-language model)范式
- cascading paradigm:直接在LLM接入TTS和ASR模型,LLM作为一个控制中枢来处理语音任务;LLM只作为内容生成器,并不参与语音维度的生成,无法构建像情绪、韵律这样的附加信息
- spoken language models:将语音信号编码成离散的表征并通过LLM建模;目前的方法难以理解音频语义特征,更无法理解音频文本跨模态关系
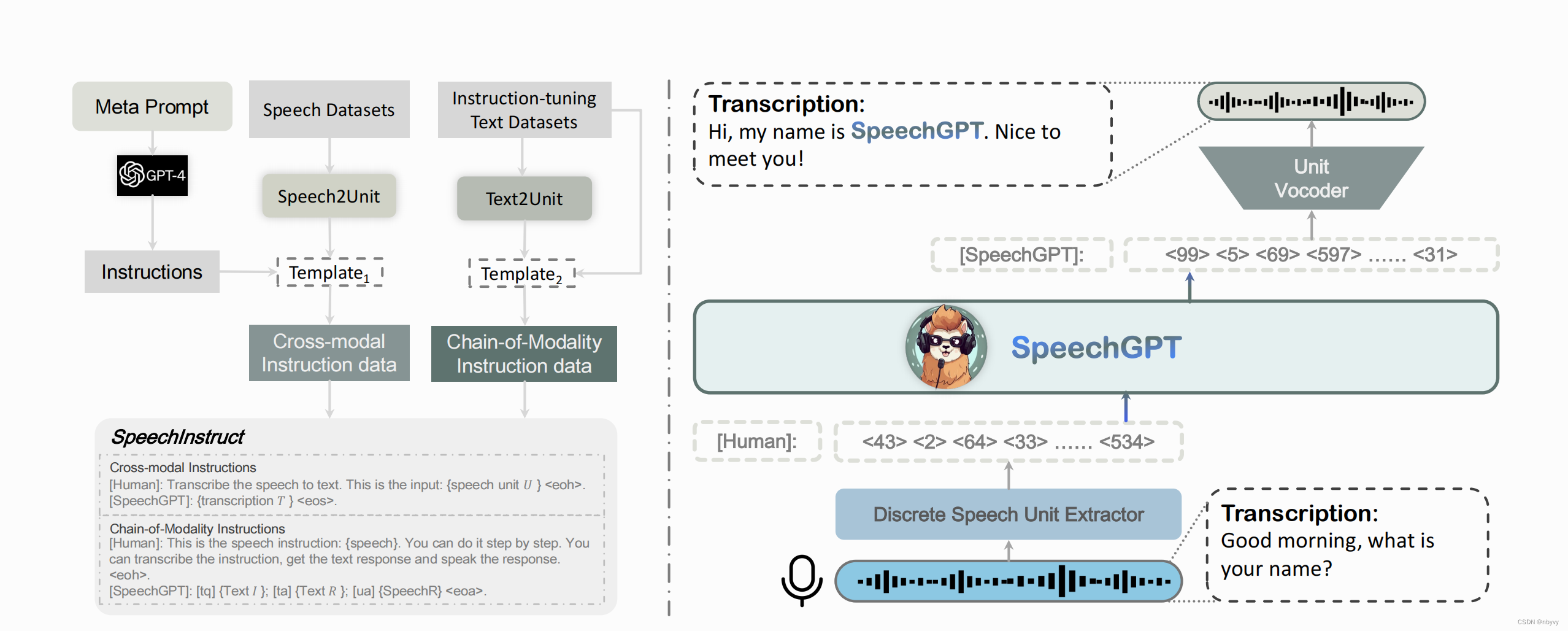
为解决上述方法的缺陷,SpeechGPT构建跨模态指令数据集SpeechInstruct和模态链路指令数据集,并且设计三阶段训练任务。
模型设计
纵观目前主要的大模型落的设计过程,无非为两个过程:预训练和指令集精调
- 预训练:如果基座模型的训练语料同垂域模型的任务所需预料相差特别大时,需要考虑预训练任务,扩充词表,使得模型能够理解垂域专有词的表征。预训练往往需要大量无标注的领域知识,消耗大量资源
- 指令集精调:指令集的精调通常为向模型输入(指令(问题),回答),建模自回归过程,数据的质量极大程度影响了模型的生成能力(https://arxiv.org/pdf/2306.11644.pdf)
如果基座模型和垂域模型任务相差巨大的话,还需要设计更多阶段的训练任务来减少二者的gap,SpeechGPT也是遵从了大模型落地的流程,设计了三阶段训练任务帮助模型更好理解文本语音的语义特征,处理跨模态任务
因此可以这样理解:预训练帮助模型学习单词,指令集精调帮助模型更好遣词造句
跨模态数据集构造
- 数据收集:结合几个大型英语ASR数据集:Gigaspeech,Common Voice,LibriSpeech得到文本-音频对
- 离散化:使用Hidden-unit BERT (HuBERT)将语音信号编码成离散语音特征转存失败重新上传取消,最终得到9million条文本-unit对
- 任务描述生成:通过GPT4,对于TTS和ASR任务分别生成100条描述
- 指令集构造:随机组合任务描述,用户输入,和模型输出得到指令数据集(D,U,T)
对于TTS任务,指令可以是

对于ASR任务,指令可以是

模态链路指令数据集
- 使用跨模态数据集训练文本 to unit生成器
- 选取37,969条moss-002-sft-data集中的问答文本数据
- 使用生成器对于37,969条生成对应的Unit,最终得到四元组 (SpeechI, TextI, TextR, SpeechR)
- 构造指令数据集

训练阶段一:模态适应预训练Modality-Adaptation Pre-training
目的:将语音的离散表征嵌入LLM-13B
数据集:LibriLight which contains 60K hours of unlabelled English audiobook speech,语音离散表征
基座模型:LLama
流程
- 扩充词表和embedding:将LLM原有的词表V结合离散语音特征V'得到新词表V‘’,将原有的embedding矩阵随机初始化增广以适合新词表
- next-token预测:同其他大模型的语言任务,但时这使用训练语料为音频离散编码u
资源:96 A100,900steps,768 batchsize
训练阶段二:跨模态指令微调
目的:学习不同模态文本之间的语义对齐
数据集:跨模态数据集融合 moss-002-sft
流程: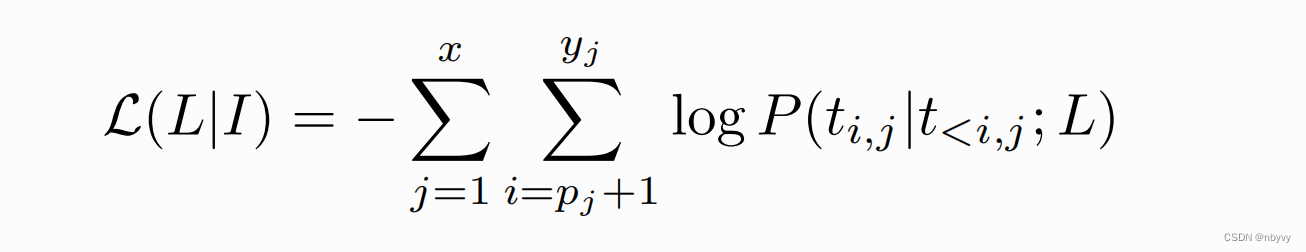
资源:96 A100,2100steps,1536 batchsize
训练阶段三:模态链路指令微调Chain-of-Modality Instruction Fine-Tuning
目的:受启发于思维链COT,强化不同模态之间的语义对齐能力以及LLM本来就有的文本问答能力,训练模型的对话能力
数据集:模态链路指令数据集
资源:8 A100,4200steps,128 batchsize
结果
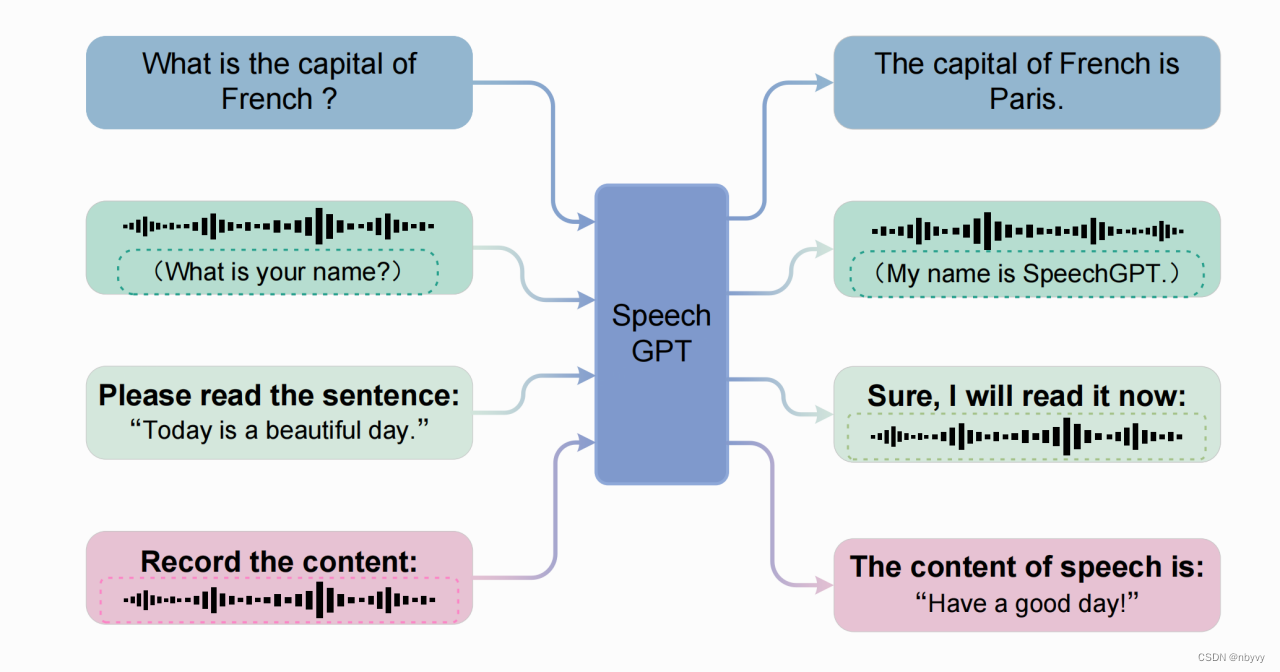
模型最终能够处理以下图示四种任务:TTS,ASR,语音对话,文本对话


















 7070
7070

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











