






卡尔曼滤波
卡尔曼滤波利用目标的动态信息,设法去掉噪声的影响,得到一个关于目标位置的估计。可以是当前目标位置的估计(滤波),将来位置的估计(预测),过去位置的估计(插值或平滑)。
卡尔曼滤波通过递归估计的方法,在获知上一时刻的估计值及当前时刻的观测值,计算当前时刻的估计值。
预测真实状态计算估计值
(1)
x
k
=
F
k
x
k
−
1
+
B
k
u
k
+
w
k
x_k=F_kx_{k-1}+B_ku_k+w_k\tag{1}
xk=Fkxk−1+Bkuk+wk(1)
F
k
F_k
Fk:作用于
x
k
−
1
x_{k-1}
xk−1的状态变换模型(矢量/矩阵)
B
k
B_k
Bk:作用于控制器向量
u
k
u_k
uk上的输入控制模型(矢量/矩阵)
w
k
w_k
wk:过程噪声,符合
w
k
w_k
wk
∼
\sim
∼N(0,
Q
k
Q_k
Qk)
对真实状态的观测
(2)
Z
k
=
H
k
x
k
+
v
k
Z_k=H_kx_k+v_k\tag{2}
Zk=Hkxk+vk(2)
H
k
H_k
Hk:观测模型,真实状态空间与观测空间映射
v
k
v_k
vk:观测噪声,符合
v
k
v_k
vk
∼
\sim
∼N(0,
R
k
R_k
Rk)
{
x
0
,
w
1
,
.
.
.
,
w
k
,
v
1
,
.
.
.
,
v
k
x_0,w_1,...,w_k,v_1,...,v_k
x0,w1,...,wk,v1,...,vk}相互独立
在获知上一时刻的估计值及当前时刻的观测值后,计算当前时刻估计值包括预测和更新两步,在预测过程中,获知上一时刻的估计值
x
k
−
1
x_{k-1}
xk−1,利用公式(1)计算当前时刻估计
x
k
x_{k}
xk;更新过程则是利用公式(2)计算所得当前时刻观测值
Z
k
Z_k
Zk优化预测结果
x
k
x_k
xk。具体步骤如下所示。
预测:
(3)
x
^
k
∣
k
−
1
=
F
K
x
^
k
−
1
∣
k
−
1
+
B
k
u
k
\hat{x}_{k|k-1}=F_K\hat{x}_{k-1|k-1}+B_ku_k\tag{3}
x^k∣k−1=FKx^k−1∣k−1+Bkuk(3)
(4)
P
k
∣
k
−
1
=
F
k
P
k
−
1
∣
k
−
1
F
k
T
+
Q
k
P_{k|k-1}=F_kP_{k-1|k-1}F_k^T+Q_k\tag{4}
Pk∣k−1=FkPk−1∣k−1FkT+Qk(4)
x
^
k
∣
k
\hat{x}_{k|k}
x^k∣k:在k时刻状态的估计
P
k
∣
k
P_{k|k}
Pk∣k:误差相关矩阵,度量估计值的精确程度
更新:
(5)
y
~
k
=
Z
k
−
H
k
x
^
k
∣
k
−
1
\tilde{y}_k=Z_k-H_k\hat{x}_{k|k-1}\tag{5}
y~k=Zk−Hkx^k∣k−1(5)
(6)
S
k
=
H
K
P
k
∣
k
−
1
H
k
T
+
R
k
S_k=H_KP_{k|k-1}H_k^T+R_k\tag{6}
Sk=HKPk∣k−1HkT+Rk(6)
(7)
K
k
=
P
k
∣
k
−
1
H
k
T
S
k
−
1
K_k=P_{k|k-1}H_k^TS_k^{-1}\tag{7}
Kk=Pk∣k−1HkTSk−1(7)
(8)
x
^
k
∣
k
=
x
^
k
∣
k
−
1
+
K
k
y
~
k
\hat{x}_{k|k}=\hat{x}_{k|k-1}+K_k\tilde{y}_k\tag{8}
x^k∣k=x^k∣k−1+Kky~k(8)
(9)
P
k
∣
k
=
(
I
−
K
k
H
k
)
P
k
∣
k
−
1
P_{k|k}=(I-K_kH_k)P_{k|k-1}\tag{9}
Pk∣k=(I−KkHk)Pk∣k−1(9)
y
~
k
\tilde{y}_k
y~k:观测余量
S
k
S_k
Sk:观测余量协方差
K
k
K_k
Kk:最优卡尔曼增益
I
I
I:单位矩阵
当模型准确,且
x
^
0
∣
0
\hat{x}_{0|0}
x^0∣0与
P
0
∣
0
P_{0|0}
P0∣0的值准确反映最初的状态分布,则以下变量将保持不变,且估计的误差均值为零。
(10)
E
[
x
k
−
x
^
k
∣
k
]
=
E
[
x
k
−
x
^
k
∣
k
−
1
]
=
0
E[x_k-\hat{x}_{k|k}]=E[x_k-\hat{x}_{k|k-1}]=0\tag{10}
E[xk−x^k∣k]=E[xk−x^k∣k−1]=0(10)
(11)
E
[
y
~
k
]
=
0
E[\tilde{y}_k]=0\tag{11}
E[y~k]=0(11)
(12)
P
k
∣
k
=
c
o
v
(
x
k
−
x
^
k
∣
k
)
P_{k|k}=cov(x_k-\hat{x}_{k|k})\tag{12}
Pk∣k=cov(xk−x^k∣k)(12)
(13)
P
k
∣
k
−
1
=
c
o
v
(
x
k
−
x
^
k
∣
k
−
1
)
P_{k|k-1}=cov(x_k-\hat{x}_{k|k-1})\tag{13}
Pk∣k−1=cov(xk−x^k∣k−1)(13)
(14)
S
k
=
c
o
v
(
y
~
k
)
S_k=cov(\tilde{y}_k)\tag{14}
Sk=cov(y~k)(14)
推导:
已知卡尔曼滤波器是一种最小均方误差估计器,即后验状态误估计是
x
k
−
x
^
k
∣
k
x_k-\hat{x}_{k|k}
xk−x^k∣k,那么最小化矢量
x
k
−
x
^
k
∣
k
x_k-\hat{x}_{k|k}
xk−x^k∣k幅度平方的期望,即
E
[
(
x
k
−
x
^
k
∣
k
)
2
]
E[(x_k-\hat{x}_{k|k})^2]
E[(xk−x^k∣k)2],等同于最小化后验估计协方差矩阵
P
k
∣
k
P_{k|k}
Pk∣k的迹。
后验协方差矩阵
P
k
∣
k
=
c
o
v
(
x
k
−
x
^
k
∣
k
)
P_{k|k}=cov(x_k-\hat{x}_{k|k})
Pk∣k=cov(xk−x^k∣k)
先后代入公式(8),(5),(2)
P
k
∣
k
=
c
o
v
(
x
k
−
(
x
^
k
∣
k
−
1
+
K
k
(
H
k
x
k
+
v
k
−
H
k
x
^
k
∣
k
−
1
)
)
)
P_{k|k}=cov(x_k-(\hat{x}_{k|k-1}+K_k(H_kx_k+v_k-H_k\hat{x}_{k|k-1})))
Pk∣k=cov(xk−(x^k∣k−1+Kk(Hkxk+vk−Hkx^k∣k−1)))
P
k
∣
k
=
c
o
v
(
(
I
−
K
k
H
k
)
(
x
k
−
x
^
k
∣
k
−
1
)
−
K
k
v
k
)
P_{k|k}=cov((I-K_kH_k)(x_k-\hat{x}_{k|k-1})-K_kv_k)
Pk∣k=cov((I−KkHk)(xk−x^k∣k−1)−Kkvk)
v_k与其他项不相关
P
k
∣
k
=
c
o
v
(
(
I
−
K
k
H
k
)
(
x
k
−
x
^
k
∣
k
−
1
)
)
+
c
o
v
(
K
k
v
k
)
P_{k|k}=cov((I-K_kH_k)(x_k-\hat{x}_{k|k-1}))+cov(K_kv_k)
Pk∣k=cov((I−KkHk)(xk−x^k∣k−1))+cov(Kkvk)
P
k
∣
k
=
(
I
−
K
k
H
k
)
c
o
v
(
x
k
−
x
^
k
∣
k
−
1
)
(
I
−
K
k
H
k
)
T
+
K
k
c
o
v
(
v
k
)
K
k
T
P_{k|k}=(I-K_kH_k)cov(x_k-\hat{x}_{k|k-1})(I-K_kH_k)^T+K_kcov(v_k)K_k^T
Pk∣k=(I−KkHk)cov(xk−x^k∣k−1)(I−KkHk)T+Kkcov(vk)KkT
代入公式(13)及R_k
P
k
∣
k
=
(
I
−
K
k
H
k
)
P
k
∣
k
−
1
(
I
−
K
k
H
k
)
T
+
K
k
R
k
K
k
T
P_{k|k}=(I-K_kH_k)P_{k|k-1}(I-K_kH_k)^T+K_kR_kK_k^T
Pk∣k=(I−KkHk)Pk∣k−1(I−KkHk)T+KkRkKkT
以上公式对任意卡尔曼增益K都成立,若K为最优卡尔曼增益,则可继续化简
最优卡尔曼增益
将上式展开,并代入公式(6)
(15)
P
k
∣
k
=
P
k
∣
k
−
1
−
P
k
∣
k
−
1
K
k
T
H
k
T
−
K
k
H
k
P
k
∣
k
−
1
+
K
k
S
k
K
k
T
P_{k|k}=P_{k|k-1}-P_{k|k-1}K_k^TH_k^T-K_kH_kP_{k|k-1}+K_kS_kK_k^T\tag{15}
Pk∣k=Pk∣k−1−Pk∣k−1KkTHkT−KkHkPk∣k−1+KkSkKkT(15)当矩阵的导数为0时,得到P的迹的最小值
d
t
r
(
P
k
∣
k
)
d
(
K
k
)
=
−
2
(
H
k
P
k
∣
k
−
1
)
T
+
2
K
k
S
k
=
0
\frac{{\rm d}tr(P_{k|k})}{{\rm d}(K_k)}=-2(H_kP_{k|k-1})^T+2K_kS_k=0
d(Kk)dtr(Pk∣k)=−2(HkPk∣k−1)T+2KkSk=0 根据矩阵求导公式可以算得
K
k
=
P
k
∣
k
−
1
H
k
T
S
k
−
1
K_k=P_{k|k-1}H_k^TS_k^{-1}
Kk=Pk∣k−1HkTSk−1时,上式成立,此时,
K
k
K_k
Kk为最优卡尔曼增益,左右两边同乘
S
k
K
k
T
S_kK_k^T
SkKkT,代入公式(15)
P
k
∣
k
=
P
k
∣
k
−
1
−
P
k
∣
k
−
1
K
k
T
H
k
T
+
P
k
∣
k
−
1
K
k
T
H
k
T
−
K
k
H
k
P
k
∣
k
−
1
P_{k|k}=P_{k|k-1}-P_{k|k-1}K_k^TH_k^T+P_{k|k-1}K_k^TH_k^T-K_kH_kP_{k|k-1}
Pk∣k=Pk∣k−1−Pk∣k−1KkTHkT+Pk∣k−1KkTHkT−KkHkPk∣k−1
化简后即为公式(9)。
卡尔曼与递归贝叶斯估计的关系
假设真正的状态是无法观察的马尔可夫过程,测量结果是从隐性马尔可夫模型观察到的状态。
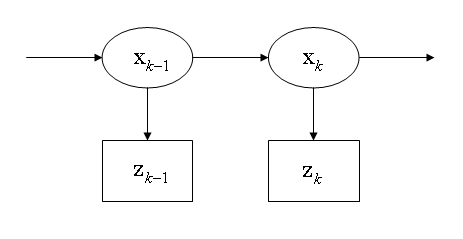
根据马尔可夫假设,真正的状态仅受最近一个状态影响而与其它以前状态无关。
p
(
x
k
∣
x
0
,
.
.
.
,
x
k
−
1
)
=
p
(
x
k
∣
x
k
−
1
)
p(x_k|x_0,...,x_{k-1})=p(x_k|x_{k-1})
p(xk∣x0,...,xk−1)=p(xk∣xk−1)
与此类似,在时刻k测量只与当前状态有关而与其它状态无关。
p
(
z
k
∣
x
0
,
.
.
.
,
x
k
)
=
p
(
z
k
∣
x
k
)
p(z_k|x_0,...,x_k)=p(z_k|x_k)
p(zk∣x0,...,xk)=p(zk∣xk)
根据这些假设,隐性马尔可夫模型所有状态的概率分布可以简化为:
p
(
x
0
,
.
.
.
,
x
k
,
z
1
,
.
.
.
,
z
k
)
=
p
(
x
0
)
∏
i
=
1
k
p
(
z
i
∣
x
i
)
p
(
x
i
∣
x
i
−
1
)
p(x_0,...,x_k,z_1,...,z_k)=p(x_0)\prod_{i=1}^kp(z_i|x_i)p(x_i|x_{i-1})
p(x0,...,xk,z1,...,zk)=p(x0)∏i=1kp(zi∣xi)p(xi∣xi−1)
然而,当卡尔曼滤波器用来估计状态x时,感兴趣的机率分布,是基于目前为止所有个测量值来得到的当前状态之机率分布,这是通过边缘化先前的状态并除以测量集的概率来实现的。这导致概率地写入的卡尔曼滤波器的预测和更新步骤。与预测状态相关联的概率分布是与从第(k-1)时刻到第k个时刻的转变相关联的概率分布的乘积与前一状态相关的概率分布的和(积分),在所有可能的
Z
k
−
1
Z_{k-1}
Zk−1。
(16)
p
(
x
k
∣
Z
k
−
1
)
=
∫
p
(
x
k
∣
x
k
−
1
)
p
(
x
k
−
1
∣
Z
k
−
1
)
d
x
k
−
1
p(x_k|Z_{k-1})=\int p(x_k|x_{k-1})p(x_{k-1}|Z_{k-1}){\rm d}x_{k-1}\tag{16}
p(xk∣Zk−1)=∫p(xk∣xk−1)p(xk−1∣Zk−1)dxk−1(16) 设置在时间t的观测值为
Z
t
=
{
z
1
,
.
.
.
,
z
t
}
Z_t=\{z_1,...,z_t\}
Zt={z1,...,zt},更新的概率分布与观测的可能性和预测状态的乘积成比例。
p
(
x
k
∣
Z
k
)
=
p
(
z
k
∣
x
k
)
p
(
x
k
∣
Z
k
−
1
)
p
(
z
k
∣
Z
k
−
1
)
p(x_k|Z_k)=\frac{p(z_k|x_k)p(x_k|Z_{k-1})}{p(z_k|Z_{k-1})}
p(xk∣Zk)=p(zk∣Zk−1)p(zk∣xk)p(xk∣Zk−1)
分母
p
(
z
k
∣
Z
k
−
1
)
=
∫
p
(
z
k
∣
x
k
)
p
(
x
k
∣
Z
k
−
1
)
d
x
k
p(z_k|Z_{k-1})=\int p(z_k|x_{k})p(x_{k}|Z_{k-1}){\rm d}x_{k}
p(zk∣Zk−1)=∫p(zk∣xk)p(xk∣Zk−1)dxk是一个标准化术语。剩余的概率密度函数是
p
(
x
k
∣
x
k
−
1
)
=
N
(
F
k
x
k
−
1
,
Q
k
)
p(x_k|x_{k-1})=N(F_kx_{k-1},Q_k)
p(xk∣xk−1)=N(Fkxk−1,Qk)
p
(
z
k
∣
x
k
)
=
N
(
H
k
x
k
,
R
k
)
p(z_k|x_k)=N(H_kx_k,R_k)
p(zk∣xk)=N(Hkxk,Rk)
p
(
x
k
−
1
∣
Z
k
−
1
)
=
N
(
x
^
k
−
1
,
P
k
−
1
)
p(x_{k-1}|Z_{k-1})=N(\hat{x}_{k-1},P_{k-1})
p(xk−1∣Zk−1)=N(x^k−1,Pk−1)
扩展卡尔曼滤波器
基本卡尔曼滤波器(The basic Kalman filter)限于线性假设。然而,更复杂的系统可以是非线性的。非线性可以与过程模型(process model)或观测模型(observation model)相关联,也可以与两者相关联。
在扩展卡尔曼滤波器(Extended Kalman Filter,简称EKF)中状态转换和观测模型不需要是状态的线性函数,可替换为(可微的)函数。
x
k
=
f
(
x
k
−
1
,
u
k
,
w
k
)
x_k=f(x_{k-1},u_k,w_k)
xk=f(xk−1,uk,wk)
z
k
=
h
(
x
k
,
v
k
)
z_k=h(x_k,v_k)
zk=h(xk,vk)
函数
f
f
f可以用来从过去的估计值中计算预测的状态,相似的,函数
h
h
h可以用来以预测的状态计算预测的测量值。然而
f
f
f和
h
h
h不能直接的应用在协方差中,取而代之的是计算偏导矩阵(雅可比矩阵)。
在每一步中使用当前的估计状态计算雅可比矩阵,这几个矩阵可以用在卡尔曼滤波器的方程中。这个过程,实质上将非线性的函数在当前估计值处线性化了。
这样一来,卡尔曼滤波器的等式为:
预测:
(17)
x
^
k
∣
k
−
1
=
f
(
x
k
−
1
,
u
k
,
0
)
\hat{x}_{k|k-1}=f(x_{k-1},u_k,0)\tag{17}
x^k∣k−1=f(xk−1,uk,0)(17)
(18)
P
k
∣
k
−
1
=
F
k
P
k
−
1
∣
k
−
1
F
k
T
+
Q
k
P_{k|k-1}=F_kP_{k-1|k-1}F_k^T+Q_k\tag{18}
Pk∣k−1=FkPk−1∣k−1FkT+Qk(18) 使用雅克比矩阵更新模型:
(19)
F
k
=
∂
f
∂
x
∣
x
^
k
−
1
∣
k
−
1
,
u
k
F_k=\left. \frac{\partial f}{\partial x}\right| _{\hat{x}_{k-1|k-1},u_k}\tag{19}
Fk=∂x∂f∣∣∣∣x^k−1∣k−1,uk(19)
(20)
H
k
=
∂
h
∂
x
∣
x
^
k
∣
k
−
1
H_k= \left. \frac{\partial h}{\partial x} \right| _{\hat{x}_{k|k-1}}\tag{20}
Hk=∂x∂h∣∣∣∣x^k∣k−1(20) 更新:
(21)
y
~
k
=
z
k
−
h
(
x
^
k
∣
k
−
1
,
0
)
\tilde{y}_k=z_k-h(\hat{x}_{k|k-1},0)\tag{21}
y~k=zk−h(x^k∣k−1,0)(21)
(22)
S
k
=
H
k
P
k
∣
k
−
1
H
k
T
+
R
k
S_k=H_kP_{k|k-1}H_k^T+R_k\tag{22}
Sk=HkPk∣k−1HkT+Rk(22)
(23)
K
k
=
P
k
∣
k
−
1
H
k
T
S
k
−
1
K_k=P_{k|k-1}H_k^TS_k^{-1}\tag{23}
Kk=Pk∣k−1HkTSk−1(23)
(24)
x
^
k
∣
k
=
x
^
k
∣
k
−
1
+
K
k
y
~
k
\hat{x}_{k|k}=\hat{x}_{k|k-1}+K_k\tilde{y}_k\tag{24}
x^k∣k=x^k∣k−1+Kky~k(24)
(25)
P
k
∣
k
=
(
I
−
K
k
H
k
)
P
k
∣
k
−
1
P_{k|k}=(I-K_kH_k)P_{k|k-1}\tag{25}
Pk∣k=(I−KkHk)Pk∣k−1(25)
Unscented卡尔曼滤波器
当状态转换和观察模型-即预测和更新功能
f
f
f和
h
h
h高度非线性,扩展卡尔曼滤波器的性能非常差。这是因为协方差通过底层的非线性模型的线性化传递。
无迹卡尔曼滤波器(
U
F
K
UFK
UFK)使用无损变换(UT)的确定性采样技术来选择围绕均值的最小样本点集(称为
S
i
g
m
a
Sigma
Sigma点)。然后通过非线性函数传播
S
i
g
m
a
Sigma
Sigma点,然后从中形成新的均值和协方差估计,对非线性函数的概率密度分布近似,而不是近似非线性函数。
得到的
U
K
F
UKF
UKF滤波器取决于如何计算
U
T
UT
UT的转换统计数据以及使用哪组
S
i
g
m
a
Sigma
Sigma点-应该注意始终以一致的方式构造新的
U
K
F
UKF
UKF。对于某些系统,得到的
U
K
F
UKF
UKF滤波器可以更准确地估计真实均值和协方差。这可以通过蒙特卡罗抽样或后验统计的泰勒级数展开来验证。此外,这种技术消除了明确计算雅可比行列式的要求,对于复杂函数本身来说计算雅可比行列式是一项艰巨的任务。
预测:
与EKF一样,
U
K
F
UKF
UKF预测可以独立于
U
K
F
UKF
UKF更新使用,结合线性(或
E
K
F
EKF
EKF)更新,反之亦然。
估计的状态和协方差用过程噪声
w
k
w_k
wk的均值和协方差来增强。
x
k
−
1
∣
k
−
1
a
=
[
x
^
k
−
1
∣
k
−
1
T
E
[
w
k
T
]
]
T
x_{k-1|k-1}^a=\left[\begin{matrix}\hat{x}_{k-1|k-1}^T&E[w_k^T]\end{matrix}\right]^T
xk−1∣k−1a=[x^k−1∣k−1TE[wkT]]T
P
k
−
1
∣
k
−
1
a
=
[
P
k
−
1
∣
k
−
1
0
0
Q
k
]
P_{k-1|k-1}^a=\left[\begin{matrix}P_{k-1|k-1}&0\\\\0&Q_k\end{matrix}\right]
Pk−1∣k−1a=⎣⎡Pk−1∣k−100Qk⎦⎤
从增强均值和协方差导出一组
2
L
+
1
2L+1
2L+1个
S
i
g
m
a
Sigma
Sigma点,其中
L
L
L是增强均值的维度。
(26)
χ
k
−
1
∣
k
−
1
i
=
{
x
k
−
1
∣
k
−
1
a
,
if i=0
x
k
−
1
∣
k
−
1
a
+
(
(
L
+
λ
)
P
k
−
1
∣
k
−
1
a
)
i
,
if i=1,...,L
x
k
−
1
∣
k
−
1
a
−
(
(
L
+
λ
)
P
k
−
1
∣
k
−
1
a
)
i
,
if i=L+1,...,2L
\chi_{k-1|k-1}^i=\begin{cases}x_{k-1|k-1}^a,& \text{if i=0}\\x_{k-1|k-1}^a+(\sqrt{(L+\lambda)P_{k-1|k-1}^a})_i,& \text{if i=1,...,L}\\x_{k-1|k-1}^a-(\sqrt{(L+\lambda)P_{k-1|k-1}^a})_i,& \text{if i=L+1,...,2L}\end{cases}\tag{26}
χk−1∣k−1i=⎩⎪⎪⎨⎪⎪⎧xk−1∣k−1a,xk−1∣k−1a+((L+λ)Pk−1∣k−1a)i,xk−1∣k−1a−((L+λ)Pk−1∣k−1a)i,if i=0if i=1,...,Lif i=L+1,...,2L(26)
(
(
L
+
λ
)
P
k
−
1
∣
k
−
1
a
)
i
(\sqrt{(L+\lambda)P_{k-1|k-1}^a})_i
((L+λ)Pk−1∣k−1a)i:矩阵
(
L
+
λ
)
P
k
−
1
∣
k
−
1
a
(L+\lambda)P_{k-1|k-1}^a
(L+λ)Pk−1∣k−1a平方根的的
i
i
i列。
S
i
g
m
a
Sigma
Sigma点通过函数
f
f
f传递。KaTeX parse error: Expected '}', got 'EOF' at end of input: …k-1}^i), \text{iKaTeX parse error: Expected 'EOF', got '}' at position 10: =0,...,2L}̲;
f
f
f是非线性映射
R
L
⟶
R
∣
x
∣
R^L\longrightarrow R^{|x|}
RL⟶R∣x∣
加权
S
i
g
m
a
Sigma
Sigma点重新组合以产生预测均值与协方差。
(27)
x
^
k
∣
k
−
1
=
∑
i
=
0
2
L
W
s
i
χ
k
∣
k
−
1
i
\hat{x}_{k|k-1}=\sum_{i=0}^{2L}{W_s^i\chi_{k|k-1}^i}\tag{27}
x^k∣k−1=i=0∑2LWsiχk∣k−1i(27)
(28)
P
k
∣
k
−
1
=
∑
i
=
0
2
L
W
c
i
[
χ
k
∣
k
−
1
i
−
x
^
k
∣
k
−
1
]
[
χ
k
∣
k
−
1
i
−
x
^
k
∣
k
−
1
]
T
P{k|k-1}=\sum_{i=0}^{2L}W_c^i[\chi_{k|k-1}^i-\hat{x}_{k|k-1}][\chi_{k|k-1}^i-\hat{x}_{k|k-1}]^T\tag{28}
Pk∣k−1=i=0∑2LWci[χk∣k−1i−x^k∣k−1][χk∣k−1i−x^k∣k−1]T(28) 其中,均值和协方差的权值由下式给出:
W
s
i
=
λ
L
+
λ
W_s^i=\frac{\lambda}{L+\lambda}
Wsi=L+λλ
W
c
i
=
λ
L
+
λ
+
(
1
+
α
2
+
β
)
W_c^i=\frac{\lambda}{L+\lambda}+(1+\alpha^2+\beta)
Wci=L+λλ+(1+α2+β)
W
s
i
=
W
c
i
=
1
2
(
L
+
λ
)
W_s^i=W_c^i=\frac{1}{2(L+\lambda)}
Wsi=Wci=2(L+λ)1
λ
=
α
2
(
L
+
κ
)
−
L
\lambda=\alpha^2(L+\kappa)-L
λ=α2(L+κ)−L
W
s
i
W_s^i
Wsi均值权值,
W
c
i
W_c^i
Wci协方差权值,
α
\alpha
α用于调节
S
i
g
m
a
Sigma
Sigma点和均值的距离,
κ
\kappa
κ包含
S
i
g
m
a
Sigma
Sigma点分布信息的加权系数,
β
\beta
β与
x
x
x的分布有关。参数的取值不唯一,根据实际情况选择,通常
κ
≥
0
\kappa\geq0
κ≥0,
α
∈
(
0
,
1
]
\alpha\in(0,1]
α∈(0,1],
β
=
2
\beta=2
β=2。如果
x
x
x的分布符合高斯分布,
β
=
2
\beta=2
β=2是最佳的;
x
x
x为单变量,
β
=
0
\beta=0
β=0是最佳的。
更新:
如果使用了
U
K
F
UKF
UKF预测,则可线性增加
S
i
g
m
a
Sigma
Sigma点本身
χ
k
∣
k
−
1
:
=
[
χ
k
∣
k
−
1
T
E
[
v
k
T
]
]
T
±
(
L
+
λ
)
R
k
a
\chi_{k|k-1}:=\left[\begin{matrix}\chi_{k|k-1}^T&E[v_k^T]\end{matrix}\right]^T\pm\sqrt{(L+\lambda)R_k^a}
χk∣k−1:=[χk∣k−1TE[vkT]]T±(L+λ)Rka;
R
k
a
=
[
0
0
0
R
k
]
R_k^a=\left[\begin{matrix}0&0\\0&R_k\end{matrix}\right]
Rka=[000Rk]
通过观测函数
h
h
h映射
S
i
g
m
a
Sigma
Sigma点
(29)
γ
k
i
=
h
(
χ
k
∣
k
−
1
i
)
,
i
=0,...,2L
\gamma_k^i=h(\chi_{k|k-1}^i),\text{$i$=0,...,2L}\tag{29}
γki=h(χk∣k−1i),i=0,...,2L(29) 重新加权
S
i
g
m
a
Sigma
Sigma点,计算观测值和观测协方差
(30)
z
^
k
=
∑
i
=
0
2
L
W
s
i
γ
k
i
\hat{z}_k=\sum_{i=0}^{2L}W_s^i\gamma_k^i\tag{30}
z^k=i=0∑2LWsiγki(30)
(31)
P
z
k
z
k
=
∑
i
=
0
2
L
W
c
i
[
γ
k
i
−
z
^
k
]
[
γ
k
i
−
z
^
k
]
T
P{z_kz_k}=\sum_{i=0}^{2L}W_c^i[\gamma_{k}^i-\hat{z}_{k}][\gamma_{k}^i-\hat{z}_{k}]^T\tag{31}
Pzkzk=i=0∑2LWci[γki−z^k][γki−z^k]T(31) 均值观测的互协方差矩阵
(32)
P
x
k
z
k
=
∑
i
=
0
2
L
W
c
i
[
χ
k
∣
k
−
1
i
−
x
^
k
∣
k
−
1
]
[
γ
k
i
−
z
^
k
]
T
P{x_kz_k}=\sum_{i=0}^{2L}W_c^i[\chi_{k|k-1}^i-\hat{x}_{k|k-1}][\gamma_{k}^i-\hat{z}_{k}]^T\tag{32}
Pxkzk=i=0∑2LWci[χk∣k−1i−x^k∣k−1][γki−z^k]T(32) 用于计算
U
K
F
UKF
UKF卡尔曼增益
(33)
K
k
=
P
x
k
z
k
P
z
k
z
k
−
1
K_k=P{x_kz_k}P{z_kz_k}^{-1}\tag{33}
Kk=PxkzkPzkzk−1(33) 与卡尔曼滤波器一样,更新状态及协方差矩阵
(34)
x
^
k
∣
k
=
x
^
k
∣
k
−
1
+
K
k
(
z
k
−
z
^
k
)
\hat{x}_{k|k}=\hat{x}_{k|k-1}+K_k(z_k-\hat{z}_k)\tag{34}
x^k∣k=x^k∣k−1+Kk(zk−z^k)(34)
(35)
P
k
∣
k
=
P
k
∣
k
−
1
−
K
k
P
z
k
z
k
K
k
T
P_{k|k}=P_{k|k-1}-K_kP_{z_kz_k}K_k^T\tag{35}
Pk∣k=Pk∣k−1−KkPzkzkKkT(35)
作者:TensionRidden
2018年11月6日















 40万+
40万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









