







1.集合框架概述
集合都是在 java.util包中
Java Collection Framework=Java集合框架 JCF
集合:用来存放很多元素的一种类型 也可以称为集合容器
框架:是一种结构体系 有很多类去组成的
提到集合我们自然就想到数组 那么这两个有什么关系呢?
我们定义一个数组的时候 是必须得定长 并且只能存同一种类型
比如 String[] a=new String[5]; //必须这样去定义
那么用ArrayList的时候就用限制长度
对于集合框架的知识 我们可以用、Java API(Application Programing Interface=应用程序接口)去获得
这个是事先已经编好的 我们只需要拿来用就可以了
那么我们就开始集合框架的学习了
首先让我们看一个集合框架图
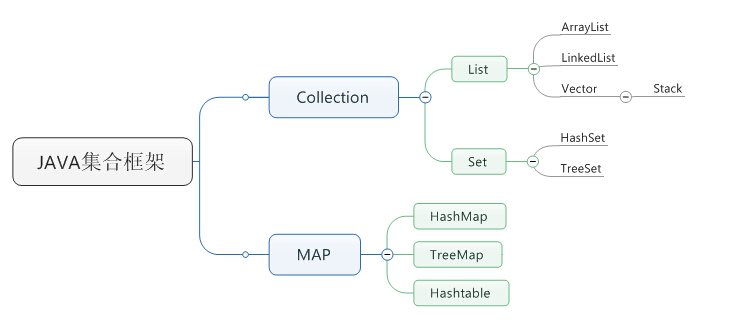
上方这个图是集合框架图 集合框架中 不只是有Collection 和 Map接口 还有其它的接口 只是这两个是结合中用的最多的
那我们先学习Collection 然后在学Map
2.Collection接口
在这个Collection接口中 有两个子接口 List和 Set ,而 List 和 Set后面就是他们的实现类。
那么这两个子接口究竟有什么区别呢?
| List | Set |
| 有索引 | 无索引 |
| 数据可以重复 | 数据不可以重复 |
2.1 List
2.1.1 ArrayList
ArrayList:动态数组,表示数组长度可变
public class Text {
public static void main(String[] args) {
ArrayList<String> al=new ArrayList<String>();
al.add("Beijing");
al.add("Tianjin");
al.add("Shanghai");
al.add(0,"Chongqing");
for(int i=0; i<al.size(); i++)
{
System.out.println(al.get(i));
}
}
}2.1.2 LinkedList
LinkedList::用法和ArrayList是完全一样的
2.1.3 ArrayList和LinkedList区别
数据存储方式不一样,称为不同的数据结构
ArrayList:基于数组实现(优点:连续存放,查找速度比较快,缺点:增加元素或者删除元素比较慢),
LinkedList基于链表实现(缺点:不连续存放,查找速度比较慢,优点:增加元素或删除元素比较快)。
2.1.4 Vector
Vector 向量:基于数组实现的,但是已经过时,现在都用ArrayList。
2.2 Set
2.2.1 HashSet
HashSet:是以哈希表为存储结构 是无序的
public class Text {
public static void main(String[] args) {
HashSet<String> al=new HashSet<String>();
al.add("Beijing");
al.add("Tianjin");
al.add("Shanghai");
al.add("Chongqing");
Iterator<String> it=al.iterator();
while(it.hasNext())
{
System.out.println(it.next());
}
}
}Beijing
Shanghai
Chongqing
Tianjin iterator: 迭代器(遍历器)
迭代器用于遍历集合中的元素
详细请看:http://blog.csdn.net/ncut_ljd/article/details/51075931
2.2.2 TreeSet
TreeSet:是以二叉树为存储结构 是有序的
public class Text {
public static void main(String[] args) {
TreeSet<String> al=new TreeSet<String>();
al.add("Beijing");
al.add("Tianjin");
al.add("Shanghai");
al.add("Chongqing");
Iterator<String> it=al.iterator();
while(it.hasNext())
{
System.out.println(it.next());
}
}
}Beijing
Chongqing
Shanghai
Tianjin但是如果我们存自定义对象的时候 TreeSet就无法进行排序 从而报错
package javastudy;
import java.util.*;
public class Text {
public static void main(String[] args) {
TreeSet<Person> al=new TreeSet<Person>();
al.add(new Person("小明", 15));
al.add(new Person("王芳", 19));
al.add(new Person("张红", 12));
Iterator<Person> it=al.iterator();
while(it.hasNext())
{
System.out.println(it.next());
}
}
}
Person类
package javastudy;
public class Person {
String name;
int age;
public Person(String name,int age) {
this.name=name;
this.age=age;
}
@Override
public String toString() {
return "name=" + name + ", age=" + age;
}
}
异常信息

cannot be cast to java.lang.Comparable
Comparable:可比较的
那现在该怎么办呢?
有两种方法解决
方法一:传入的对象所属的类,必须实现Comparable
给Person实现Comparable接口
package javastudy;
public class Person implements Comparable<Person> {
String name;
int age;
public Person(String name,int age) {
this.name=name;
this.age=age;
}
@Override
public String toString() {
return "name=" + name + ", age=" + age;
}
@Override
public int compareTo(Person o) {
if(this.age>o.age){
return 1;
}
else if(this.age<o.age){
return -1;
}
else{
return 0;
}
}
}
name=张红, age=12
name=小明, age=15
name=王芳, age=19方法二:初始化TreeSet时,传入一个比较器(比较器是一个实现了Comparator的类的对象)作为一个构造参数。
package javastudy;
import java.util.Comparator;
public class MyCom implements Comparator<Person> {
@Override
public int compare(Person o1, Person o2) {
// TODO Auto-generated method stub
return o1.name.compareTo(o2.name);
}
}
TreeSet<Person> al=new TreeSet<Person>(new MyCom());结果:
name=wangfang, age=19
name=xiaoming, age=15
name=zhanghong, age=12如果方法一和方法二同时使用的时候 方法二优先执行
3.Map接口
他和Collection这个接口是有区别的
Collection 是单列集合,Map是双列集合
在Map接口中有Key-Value 键值对这个概念
键值对的键是不可以重复的 获取的时候用Set 而值是可以重复的 所以用Collection
而且Map在用的时候 有点像Set
3.1 HashMap
HashMap: 底层是哈希表,键值都可以是null。
读取方式以HashMap举例 TreeMap也是这么做的
3.1.1 获得所有键的结合keyset
public class Text {
public static void main(String[] args) {
HashMap<String, String> hm=new HashMap<String,String>();
hm.put("010", "Beijing");
hm.put("020", "Shanghai");
hm.put("021", "Chongqing");
hm.put("023", "Tianjin");
Set<String> s=hm.keySet();
Iterator<String> it=s.iterator();
while(it.hasNext())
{
System.out.println(it.next());
}
}
}023
020
010
0213.1.2 获得所有值得结合values
public class Text {
public static void main(String[] args) {
HashMap<String, String> hm=new HashMap<String,String>();
hm.put("010", "Beijing");
hm.put("020", "Shanghai");
hm.put("021", "Chongqing");
hm.put("023", "Tianjin");
Collection<String> cl=hm.values();
Iterator<String> it=cl.iterator();
while(it.hasNext())
{
System.out.println(it.next());
}
}
}Tianjin
Shanghai
Beijing
Chongqing
3.1.3获得所有条目entryset
entry=一行,一个条目(包含键和值)
package javastudy;
import java.util.*;
import java.util.Map.Entry;
public class Text {
public static void main(String[] args) {
HashMap<String, String> hm=new HashMap<String,String>();
hm.put("010", "Beijing");
hm.put("020", "Shanghai");
hm.put("021", "Chongqing");
hm.put("023", "Tianjin");
Set<Entry<String, String>> en=hm.entrySet();
Iterator<Entry<String, String>> it=en.iterator();
while(it.hasNext())
{
System.out.println(it.next());
}
}
}
//023=Tianjin
//020=Shanghai
//010=Beijing
//021=Chongqing
3.2 TreeMap
TreeMap: 底层是二叉树,支持键排序。有序的(键是有序的)
package javastudy;
import java.util.*;
import java.util.Map.Entry;
public class Text {
public static void main(String[] args) {
TreeMap<String, String> hm=new TreeMap<String,String>();
hm.put("023", "Beijing");
hm.put("021", "Shanghai");
hm.put("020", "Chongqing");
hm.put("030", "Tianjin");
Set<Entry<String, String>> en=hm.entrySet();
Iterator<Entry<String, String>> it=en.iterator();
while(it.hasNext())
{
System.out.println(it.next());
}
}
}
//020=Chongqing
//021=Shanghai
//023=Beijing
//030=Tianjin
如果键是自定义对象的话 那么我们也需要用到TreeSet中的方法 方法都是一样的 不做演示
3.3 HashTable
HashTable:底层存储结构是哈希表,键和值都不可以是null。已过时。















 3468
3468

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









