










从 机器学习面试必知:SVM和LR的关系 一文中,我们可以看到SVM相比于LR的优势在于能产生稀疏解。现在把SVM应用到回归问题中,同时保持它的稀疏性。在简单的线性回归模型中,我们最小化一个正则化的误差函数
1
2
∑
n
=
1
N
(
y
n
−
t
n
)
2
+
λ
2
∣
∣
w
∣
∣
2
\frac{1}{2}\sum_{n=1}^{N}(y_{n}-t_{n})^{2}+\frac{\lambda}{2}||w||^{2}
21n=1∑N(yn−tn)2+2λ∣∣w∣∣2为了得到稀疏解,二次误差函数被替换成一个
ϵ
\epsilon
ϵ不敏感误差函数。如果预测
y
(
x
)
y(x)
y(x)与目标
t
t
t之间的差的绝对值小于
ϵ
\epsilon
ϵ,那么这个误差函数给出的误差为0。
E
ϵ
(
y
(
x
)
−
t
)
=
{
0
,
i
f
∣
y
(
x
)
−
t
∣
<
ϵ
∣
y
(
x
)
−
t
∣
−
ϵ
,
o
t
h
e
r
w
i
s
e
E_{\epsilon }(y(x)-t)= \left\{\begin{matrix} 0,\quad \quad if \ \ |y(x)-t|<\epsilon\\ |y(x)-t|-\epsilon,\ otherwise \end{matrix}\right.
Eϵ(y(x)−t)={0,if ∣y(x)−t∣<ϵ∣y(x)−t∣−ϵ, otherwise于是我们最小正则化的误差函数
C
∑
n
=
1
N
E
ϵ
(
y
(
x
n
)
−
t
n
)
+
1
2
∣
∣
w
∣
∣
2
C\sum_{n=1}^{N} E_{\epsilon }(y(x_{n})-t_{n})+\frac{1}{2}||w||^{2}
Cn=1∑NEϵ(y(xn)−tn)+21∣∣w∣∣2为了有更好的泛化能力,我们引入松弛变量
ξ
n
≥
0
\xi_{n}\geq0
ξn≥0和
ξ
n
~
≥
0
\widetilde{\xi_{n}}\geq0
ξn
≥0分别代表上界和下界。
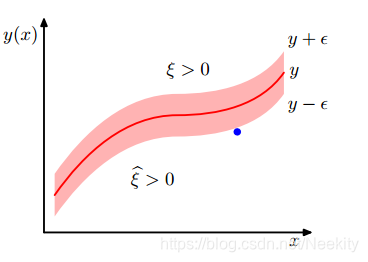
从图中可以看到,
ξ
n
>
0
\xi_{n}>0
ξn>0对应的是
t
n
>
y
(
x
n
)
+
ϵ
t_{n}>y(x_{n})+\epsilon
tn>y(xn)+ϵ数据点,
ξ
n
~
>
0
\widetilde{\xi_{n}}>0
ξn
>0对应的是
t
n
<
y
(
x
n
)
−
ϵ
t_{n}<y(x_{n})-\epsilon
tn<y(xn)−ϵ数据点,而位于管道内的点
y
n
−
ϵ
≤
t
n
≤
y
n
+
ϵ
y_{n}-\epsilon\leq t_{n}\leq y_{n}+\epsilon
yn−ϵ≤tn≤yn+ϵ所以
t
n
≤
y
(
x
n
)
+
ϵ
+
ξ
n
t_{n}\leq y(x_{n})+\epsilon+\xi_{n}
tn≤y(xn)+ϵ+ξn
t
n
≥
y
(
x
n
)
−
ϵ
−
ξ
n
~
t_{n}\geq y(x_{n})-\epsilon-\widetilde{\xi_{n}}
tn≥y(xn)−ϵ−ξn
相应地支持向量回归的误差函数可以写成
C
∑
n
=
1
N
(
ξ
n
+
ξ
n
~
)
+
1
2
∣
∣
w
∣
∣
2
C\sum_{n=1}^{N}(\xi_{n}+\widetilde{\xi_{n}})+\frac{1}{2}||w||^{2}
Cn=1∑N(ξn+ξn
)+21∣∣w∣∣2我们引入拉格朗日乘数
a
n
≥
0
a_{n}\geq0
an≥0,
a
n
~
≥
0
\widetilde{a_{n}}\geq0
an
≥0,
u
n
≥
0
u_{n}\geq0
un≥0和
u
n
~
≥
0
\widetilde{u_{n}}\geq0
un
≥0,然后最优化拉格朗日函数
L
=
C
∑
n
=
1
N
(
ξ
n
+
ξ
n
~
)
+
1
2
∣
∣
w
∣
∣
2
−
∑
n
=
1
N
u
n
ξ
n
−
∑
n
=
1
N
u
n
~
ξ
n
~
−
∑
n
=
1
N
a
n
(
y
(
x
n
)
+
ϵ
+
ξ
n
−
t
n
)
−
∑
n
=
1
N
a
n
~
(
−
y
(
x
n
)
+
ϵ
+
ξ
n
~
+
t
n
)
L=C\sum_{n=1}^{N}(\xi_{n}+\widetilde{\xi_{n}})+\frac{1}{2}||w||^{2}-\sum_{n=1}^{N}u_{n}\xi_{n}-\sum_{n=1}^{N}\widetilde{u_{n}}\widetilde{\xi_{n}}-\sum_{n=1}^{N}a_{n}(y(x_{n})+\epsilon+\xi_{n}-t_{n})-\sum_{n=1}^{N}\widetilde{a_{n}}(-y(x_{n})+\epsilon+\widetilde{\xi_{n}}+t_{n})
L=Cn=1∑N(ξn+ξn
)+21∣∣w∣∣2−n=1∑Nunξn−n=1∑Nun
ξn
−n=1∑Nan(y(xn)+ϵ+ξn−tn)−n=1∑Nan
(−y(xn)+ϵ+ξn
+tn)
∂
L
∂
w
=
0
⇒
w
=
∑
n
=
1
N
(
a
n
−
a
n
~
)
ϕ
(
x
n
)
\frac{\partial L}{\partial w}=0\Rightarrow w=\sum_{n=1}^{N}(a_{n}-\widetilde{a_{n}})\phi(x_{n})
∂w∂L=0⇒w=n=1∑N(an−an
)ϕ(xn)
∂
L
∂
b
=
0
⇒
0
=
∑
n
=
1
N
(
a
n
−
a
n
~
)
\frac{\partial L}{\partial b}=0\Rightarrow 0=\sum_{n=1}^{N}(a_{n}-\widetilde{a_{n}})
∂b∂L=0⇒0=n=1∑N(an−an
)
∂
L
∂
ξ
n
=
0
⇒
a
n
+
u
n
=
C
\frac{\partial L}{\partial \xi_{n}}=0\Rightarrow a_{n}+u_{n}=C
∂ξn∂L=0⇒an+un=C
∂
L
∂
ξ
n
~
=
0
⇒
a
n
~
+
u
n
~
=
C
\frac{\partial L}{\partial \widetilde{\xi_{n}}}=0\Rightarrow \widetilde{a_{n}}+\widetilde{u_{n}}=C
∂ξn
∂L=0⇒an
+un
=C把这些结果代入到L中得到
L
~
(
a
,
a
~
)
=
−
1
2
∑
n
=
1
N
∑
m
=
1
N
(
a
n
−
a
n
~
)
(
a
m
−
a
m
~
)
K
(
x
n
,
x
m
)
−
ϵ
∑
n
=
1
N
(
a
n
+
a
n
~
)
+
∑
n
=
1
N
(
a
n
−
a
n
~
)
t
n
\widetilde{L}(a,\widetilde{a})=-\frac{1}{2}\sum_{n=1}^{N}\sum_{m=1}^{N}(a_{n}-\widetilde{a_{n}})(a_{m}-\widetilde{a_{m}})K(x_{n},x_{m})-\epsilon\sum_{n=1}^{N}(a_{n}+\widetilde{a_{n}})+\sum_{n=1}^{N}(a_{n}-\widetilde{a_{n}})t_{n}
L
(a,a
)=−21n=1∑Nm=1∑N(an−an
)(am−am
)K(xn,xm)−ϵn=1∑N(an+an
)+n=1∑N(an−an
)tn同样地我们得到了限制条件
0
≤
a
n
≤
C
0\leq a_{n}\leq C
0≤an≤C
0
≤
a
n
~
≤
C
0\leq \widetilde{a_{n}}\leq C
0≤an
≤C对应的KKT条件等于零的情况如下
a
n
(
y
(
x
n
)
+
ϵ
+
ξ
n
−
t
n
)
=
0
a_{n}(y(x_{n})+\epsilon+\xi_{n}-t_{n})=0
an(y(xn)+ϵ+ξn−tn)=0
a
n
~
(
−
y
(
x
n
)
+
ϵ
+
ξ
n
~
+
t
n
)
=
0
\widetilde{a_{n}}(-y(x_{n})+\epsilon+\widetilde{\xi_{n}}+t_{n})=0
an
(−y(xn)+ϵ+ξn
+tn)=0
(
C
−
a
n
)
ξ
n
=
0
(C-a_{n})\xi_{n}=0
(C−an)ξn=0
(
C
−
a
n
~
)
ξ
n
~
=
0
(C-\widetilde{a_{n}})\widetilde{\xi_{n}}=0
(C−an
)ξn
=0分析上述的等式我们可以得到些有用的结果。如果
y
(
x
n
)
+
ϵ
+
ξ
n
−
t
n
=
0
y(x_{n})+\epsilon+\xi_{n}-t_{n}=0
y(xn)+ϵ+ξn−tn=0,那么
a
n
≠
0
a_{n}\neq0
an̸=0,进一步的,如果
a
n
=
C
a_{n}=C
an=C也就是
ξ
n
>
0
\xi_{n}>0
ξn>0此时数据点位于上边界的上方,如果
ξ
n
=
0
\xi_{n}=0
ξn=0那么数据点位于管道的上边界上。同理可以分析
−
y
(
x
n
)
+
ϵ
+
ξ
n
~
+
t
n
=
0
-y(x_{n})+\epsilon+\widetilde{\xi_{n}}+t_{n}=0
−y(xn)+ϵ+ξn
+tn=0。
我们已经得到了
y
(
x
)
=
∑
n
=
1
N
(
a
n
−
a
n
~
)
K
(
x
n
,
x
)
+
b
y(x)=\sum_{n=1}^{N}(a_{n}-\widetilde{a_{n}})K(x_{n},x)+b
y(x)=n=1∑N(an−an
)K(xn,x)+b现在寻找支持向量也就是有贡献的数据点即
a
n
≠
0
a_{n}\neq0
an̸=0或者
a
n
~
≠
0
\widetilde{a_{n}}\neq0
an
̸=0的点。这些数据点位于管道边界上或者管道外部,管道内部的点有
a
n
=
a
n
~
=
0
a_{n}=\widetilde{a_{n}}=0
an=an
=0。更一般地,我们使用前文的分析用满足
0
<
a
n
<
C
0<a_{n}<C
0<an<C,此时
ξ
n
=
0
\xi_{n}=0
ξn=0,
y
(
x
n
)
+
b
+
ϵ
+
ξ
n
−
t
n
=
0
y(x_{n})+b+\epsilon+\xi_{n}-t_{n}=0
y(xn)+b+ϵ+ξn−tn=0,那么
b
=
−
w
T
ϕ
(
x
n
)
−
ϵ
+
t
n
b=-w^{T}\phi(x_{n})-\epsilon+t_{n}
b=−wTϕ(xn)−ϵ+tn或者用
0
<
a
n
~
<
C
0<\widetilde{a_{n}}<C
0<an
<C的数据点去求解b。当然更好的方法对所有符合条件的情况取平均。














04-12
12-12
03-12
 6031
6031
6031
“相关推荐”对你有帮助么?
-

 非常没帮助
非常没帮助 -

 没帮助
没帮助 -

 一般
一般 -

 有帮助
有帮助 -

 非常有帮助
非常有帮助
提交

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









