









数据结构
C++
串
几个概念
子串和主串:字符串s1中任意个连续的字符组成的子序列s2被称为是s1的子串,而称s1是s2的主串
子串的位置:子串在主串中第一次出现的第一个字符的位置
相等:两个串的长度相等,并且对应位置上的字符都相等
顺序串定义
数组形式
字符数组表示法
事先定义字符串的最大长度
以一个特殊的字符(’\0’)作为字符串的结束标志
方法1
#define MAXNUM /* 串允许的最大字符个数 */
typedef struct
{
char c[MAXNUM];
int n; /* 串的长度,nMAXNUM */
} SeqString;
方法2
typedef struct
{
char *str;
int length;
} STRING;
链式串定义
typedef struct StrNode
{
char c;
struct StrNode *next;
} Lstring, *LinkedString; /* 链串的类型 */

单链表法主要缺点是存储效率比较低
改进的方法:将其与顺序表示的思想结合起来,每个链表的结点顺序存放多个字符。
这样既提高了存储效率,又保留了链表的灵活性;
缺点:增加了一点管理方面的复杂度
改进版定义
#define CHUNKSIZE 80 //可由用户定义的块大小
typedef struct StrNode
{
char c;
struct StrNode *next;
} Lstring, *LinkedString; /* 链串的类型 */
typedef struct Chunk
{//结点结构
char ch[CHUNKSIZE];
struct Chunk *next;
} Chunk;
typedef struct
{//串的链表结构
Chunk *head, *tail;//串的头和尾指针
int curlen;//串的当前长度
}LString;
由于串中的字符个数不一定是每个结点存放字符个数的整倍数,所以,需要在最后一个结点的空缺位置上填充特殊的字符。
这种存储形式优点是存储密度高于结点大小为1 的存储形式;
缺点是做插入、删除字符的操作时,可能会引起结点之间字符的移动,算法实现起来比较复杂。
创建空顺序串
定义方式见上文
STRING STRINGInit()
{
STRING *s;
s->str = new char[1];
s->str[0] ='\0';
s->length = 0;
return s;
}
顺序串赋值
int StringAssign(STRING *s, *t)
{
if (s->str) delete (s->str);
int len = t->length;
s->length = len;
if (len == 0)
{
s->str = new char[1];
s->str[0] ='\0';
}
else
{
s->str = new char[len + 1];
if (s->str == NULL)
return ERROR;
for (int i = 0; i <= len; i++)
s->str[i] = t->str[i];
}
return OK;
}
顺序串连接
int StringConcat(STRING *s, *t)
{
STRING temp;
StringAssign(&temp, s);
int len = s->length + t->length;
s->length = len;
delete (s->str);
s->str = new char[len + 1];
if (!s->str) return ERROR;
else{
for (int i = 0; i < temp.length; i++)
s->str[i] = temp.str[i];
for (int j = 0; j <= t->length; j++, i++)
s->str[i] = t->str[j];
free(temp.str);
return OK;
}
}
子串定位(重点)
int Index(STRING *s, *t)
{
int i, j;
i = j = 0;
while (i < s->length && j < t->length)
{
if (s->str[i] == t->str[j])
{
i++;j++;
}
else
{
i = i - j + 1;//i往后挪
j = 0;//子串从头开始
}
}
if (j == t->length)//符合子串长度
return i - t->length + 1;
//返回子串在主串的开始位置
else
return 0;
}
算法-模式匹配
子串在主串中的定位操作
从目标s中查找与模式p完全相同子串的过程
常见算法:
1 朴素的模式匹配
2 首尾模式匹配算法
3 KMP算法(无回溯的模式匹配)
朴素的模式匹配
思想
- 用p中的字符依次与s中的字符比较:如果s0 = p0,s1 = p1,…,sm-1 = pm-1,则匹配成功,调用求子串的操作subStr(s,1,m)即是找到的子串。
- 否则必有某个i(0≤i≤m-1),使得si ≠pi,这时可将p右移一个字符,用p中字符从头开始与s中字符依次比较;
- 如此反复执行,直到下面两种情况之一:
1.匹配成功:到达某步时,si = p0,si+1 = p1,…,si+m-1 = pm-1,,subStr(s,i+1,m)即是找到的(第一个)与模式p相同的子串
2.匹配失败:一直将p移到无法与s继续比较为止
优点:简单,易理解
缺点:效率不高,怕回溯
时间:O(m*n),在最坏的情况下,每趟比较都在最后出现不等,最多比较n-m+1趟,总比较次数为m*(n-m+1),由于在一般情况下m<<n
首尾模式匹配
先比较模式串的第一个字符,再比较模式串的最后一个字符,最后比较模式串的从第2个到第n-1个字符
(重点)无回溯的模式匹配(KMP算法)
由D.E.Knuth与J.H.Morris和V.R.Pratt同时发现的。
简称KMP算法
时间复杂度 O(n)
用空间换时间
该算法的重点就是求k值


K值只依赖于子串(k是下标 )
怎么找K值?
找已匹配的字符串的子串
也就是找子串的最大相同子串,从下标0开始
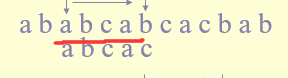
如图,abca就是一个已匹配的子串,从前往后 和 从后往前 找相同的子串,不包括本身
这里只有 a 符合,所以 k = 1

Next数组,记录K值

已知Next数组的情况下,快速运用KMP算法
int index(STRING *s, *p, int *next)
{//Next数组已知,也就是K值是知道的
int i, j;
i = 0;j = 0; /*初始化*/
while (i < s->length && j < p->length)
{
if (j = = -1 || s->str[i] == p->str[j])
{
i++;
j++;
}
else
j = next[j];//和朴素模式匹配不同之处
//i不改变,而是直接移动子串
}
if (j >= p->length)
return (i - p->length + 1); /*匹配成功*/
else
return (0); /*匹配失败*/
}
如何求Next数组,是KMP算法的核心
在数据结构课程中,一般采用手动计算
这里拓展代码方式
Next的数组是从小到大求的
void Getnext(int next[],String t)
{//求next数组,也就是K值
int j=0,k=-1;
next[0]=-1;
while(j<t.length-1)
{
if(k == -1 || t[j] == t[k])
{
j++;k++;
next[j] = k;
}
else
k = next[k];//往前找
}
}
如果Pk和Pj相等的情况
进一步拓展
求nextval数组
这是完全体,解决了Pk和Pj相等
void Getnext(int next[],String t)
{//求next数组,也就是K值
int j, k;
k = -1;
j = 0;
next[0] = -1; /* 初始化 */
while (j < p.length()) /* 计算next[j+1] */
{
while (k >= 0 && (p[j] != p[k]))
k = next[k];
j++;
k++;
if (p[j] == p[k])
next[j] = next[k];
else
next[j] = k;
}
}
配合图理解

















 2003
2003











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











