







这篇博客瞄准的是 pytorch 官方教程中 Image and Video 章节的 TorchVision Object Detection Finetuning Tutorial 部分。
完整网盘链接: https://pan.baidu.com/s/1L9PVZ-KRDGVER-AJnXOvlQ?pwd=aa2m 提取码: aa2m
【注意】:
- 这个示例中需要用到一些
torchvision的新API,如果你和官网是同步的2.6.0版本则可以直接使用,否则无法保证能够运行; - 尽管里面提到了下载一些脚本,但并没有用到,不用担心内容太多;
TorchVision Object Detection Finetuning Tutorial
该教程将在 Penn-Fudan 数据集上微调预训练的 Mask R-CNN 模型用于行人检测和分割。它包含 170 张图像,其中有 345 个行人实例,以此来演示如何使用 torchvision 在自定义数据集上训练对象检测和实例分割模型。
安装下本次教程中所需的依赖
pip install pycocotools
Defining the Dataset
训练对象检测、实例分割、人物关键点检测可以轻松添加新自定义数据集。数据集应继承自标准 torch.utils.data.Dataset 类,并实现 __len__ 和 __getitem__后者应该返回一个元组,这个教程中提供的python代码其实可以用来训练任何数据集,只要你的数据集满足以下条件即可
- image:
torchvision.tv_tensors.Image需要一个shape=[3, H, W]的纯 Tensor 或者一个size=(H, W)的PIL 对象; - target 是一个包含以下信息的
dict对象:boxes:shape=[N, 4]的torchvision.tv_tensors.BoundingBoxes,值为[x0, y0, x1, y1]格式的N个边界框的坐标,值域为[0, W], [0, H];labels:shape=[N]的int类型torch.Tensor,为每个boxes的标签,0代表背景,如果你的数据集中没有背景标签,就不要使用0,直接从1开始;image_id:int类型的图像对象标识符,对于数据集中的所有图像而言都是是唯一的;area:shape=[N]的float类型torch.Tensor,boxes的面积,在使用 COCO 度量进行评估时使用此值,将度量分数分为小框、中框和大框;iscrowd:shape=[N]的uint8类型torch.Tensor,iscrowd=True的样本将在评估期间被忽略;masks:shape=[N, H, W]的torchvision.tv_tensors.Mask类型,每个对象的分割掩码;
Writing a custom dataset for PennFudan
首先从这个 链接 中下载并解压到 data 文件夹中,或者使用下面的命令:
$ wget https://www.cis.upenn.edu/~jshi/ped_html/PennFudanPed.zip -P data
$ cd data && unzip PennFudanPed.zip
抽查一对数据
import matplotlib.pyplot as plt
from torchvision.io import read_image
image = read_image("data/PennFudanPed/PNGImages/FudanPed00046.png")
mask = read_image("data/PennFudanPed/PedMasks/FudanPed00046_mask.png")
plt.figure(figsize=(16, 8))
plt.subplot(121)
plt.title("Image")
plt.imshow(image.permute(1, 2, 0))
plt.subplot(122)
plt.title("Mask")
plt.imshow(mask.permute(1, 2, 0))
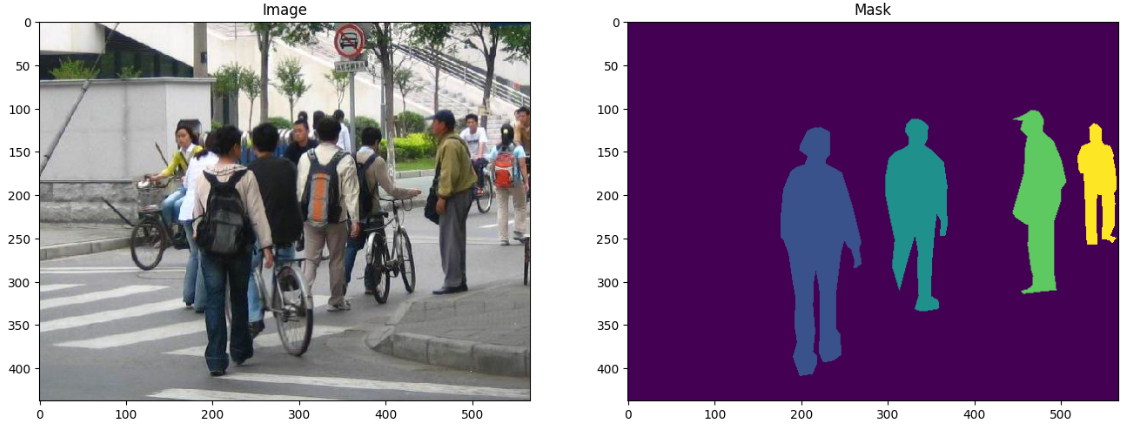
针对这个数据集编写一个 torch.utils.data.Dataset 类,将image、bounding boxes、mask包装到 torchvision.tv_tensors.TVTensor 类中,其中image Tensor由 torchvision.tv_tensors.Image 包装;bounding boxes 由 torchvision.tv_tensors.BoundingBoxes 包装;mask 由 torchvision.tv_tensors.Mask 包装。由于 torchvision.tv_tensors.TVTensor 是 torch.Tensor 子类,因此包装的对象也是 Tensor 并继承了的 torch.Tensor API。
导入依赖库
import os
import torch
from torchvision.io import read_image
from torchvision.ops.boxes import masks_to_boxes
from torchvision import tv_tensors
from torchvision.transforms.v2 import functional as F
定义数据集的Dataset对象
class PennFudanDataset(torch.utils.data.Dataset):
def __init__(self, root, transforms):
self.root = root
self.transforms = transforms
self.imgs = list(sorted(os.listdir(os.path.join(root, "PNGImages"))))
self.masks = list(sorted(os.listdir(os.path.join(root, "PedMasks"))))
def __getitem__(self, idx):
img_path = os.path.join(self.root, "PNGImages", self.imgs[idx])
mask_path = os.path.join(self.root, "PedMasks", self.masks[idx])
img = read_image(img_path)
mask = read_image(mask_path)
obj_ids = torch.unique(mask)
obj_ids = obj_ids[1:]
num_objs = len(obj_ids)
masks = (mask == obj_ids[:, None, None]).to(dtype=torch.uint8)
boxes = masks_to_boxes(masks)
labels = torch.ones((num_objs,), dtype=torch.int64)
image_id = idx
area = (boxes[:, 3] - boxes[:, 1]) * (boxes[:, 2] - boxes[:, 0])
iscrowd = torch.zeros((num_objs,), dtype=torch.int64)
img = tv_tensors.Image(img)
target = {}
target["boxes"] = tv_tensors.BoundingBoxes(boxes, format="XYXY", canvas_size=F.get_size(img))
target["masks"] = tv_tensors.Mask(masks)
target["labels"] = labels
target["image_id"] = image_id
target["area"] = area
target["iscrowd"] = iscrowd
if self.transforms is not None:
img, target = self.transforms(img, target)
return img, target
def __len__(self):
return len(self.imgs)
Defining your model
模型部分使用基于 Faster R-CNN 的 Mask R-CNN。Faster R-CNN 是一种预测图像中潜在对象的边界框和类别分数的模型。
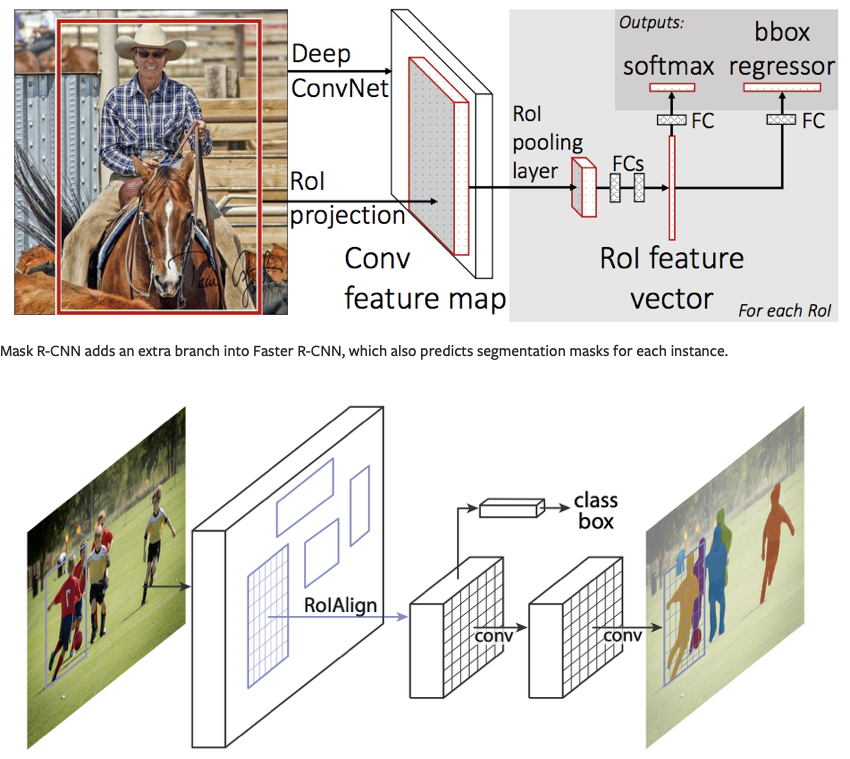
1 - Finetuning from a pretrained model
如果你想直接使用从 COCO 上预训练的模型,并希望针对特定类进行微调。
使用下面的代码
import torchvision
from torchvision.models.detection.faster_rcnn import FastRCNNPredictor
model = torchvision.models.detection.fasterrcnn_resnet50_fpn(weights="DEFAULT")
num_classes = 2
in_features = model.roi_heads.box_predictor.cls_score.in_features
model.roi_heads.box_predictor = FastRCNNPredictor(in_features, num_classes)
2 - Modifying the model to add a different backbone
如果你想要修改模型以使用不同的 backbone,使用下面的代码。这里使用的是MobileNetV2的特征层及其以上部分作为backbone,然后用AnchorGenerator对计算得到的特征层进行锚点的生成,相当于将 FasterRCNN 中的部分功能层进行替换,但总体框架仍然使用的 FasterRCNN 的结构。
导入依赖库
import torchvision
from torchvision.models.detection import FasterRCNN
from torchvision.models.detection.rpn import AnchorGenerator
MobileNetV2 特征层骨架
backbone = torchvision.models.mobilenet_v2(weights="DEFAULT").features
backbone.out_channels = 1280
anchor生成器和ROI池化作为模型的功能层
anchor_generator = AnchorGenerator(
sizes=((32, 64, 128, 256, 512),),
aspect_ratios=((0.5, 1.0, 2.0),)
)
roi_pooler = torchvision.ops.MultiScaleRoIAlign(
featmap_names=['0'],
output_size=7,
sampling_ratio=2
)
完整模型:
model = FasterRCNN(
backbone,
num_classes=2,
rpn_anchor_generator=anchor_generator,
box_roi_pool=roi_pooler
)
这里可以自己写一个函数用来将模型结构写入到tensorboard中方便查看。
【注意】:该函数不是一个通用函数,如果想要在其他地方使用需要修改一些地方。
def log_model_to_tensorboard(model, log_dir="log"):
from torch.utils.tensorboard import SummaryWriter
model.eval()
writer = SummaryWriter(log_dir=log_dir)
dummy_input = torch.randn(3, 224, 224)
class WrapperModel(torch.nn.Module):
def __init__(self, model):
super().__init__()
self.model = model
def forward(self, x):
detections = self.model(x)
return [detections[0]["boxes"]] # 主要是修改这个位置
wrapped_model = WrapperModel(model)
writer.add_graph(wrapped_model, dummy_input.unsqueeze(0))
writer.close()
log_model_to_tensorboard(model)
允信并在终端输入以下命令:
$ tensorboard --logdir=log
在 Chrome 浏览器中打开http://localhost:6006/ 地址即可查看模型结构:
Object detection and instance segmentation model for PennFudan Dataset
这里使用上面方案中的第一个,对模型进行微调,并使用 Mask R-CNN 来计算实例分割掩码。
import torchvision
from torchvision.models.detection.faster_rcnn import FastRCNNPredictor
from torchvision.models.detection.mask_rcnn import MaskRCNNPredictor
def get_model_instance_segmentation(num_classes):
model = torchvision.models.detection.maskrcnn_resnet50_fpn(weights="DEFAULT")
in_features = model.roi_heads.box_predictor.cls_score.in_features
model.roi_heads.box_predictor = FastRCNNPredictor(in_features, num_classes)
in_features_mask = model.roi_heads.mask_predictor.conv5_mask.in_channels
hidden_layer = 256
model.roi_heads.mask_predictor = MaskRCNNPredictor(
in_features_mask,
hidden_layer,
num_classes
)
return model
Putting everything together
在 references/detection/ 中有许多辅助函数来简化训练和评估检测模型。这里使用 references/detection/engine.py 和 references/detection/utils.py,使用以下命令下载:
你也可以手动打开里面的链接,将其下载到当前目录下
os.system("wget https://raw.githubusercontent.com/pytorch/vision/main/references/detection/engine.py")
os.system("wget https://raw.githubusercontent.com/pytorch/vision/main/references/detection/utils.py")
os.system("wget https://raw.githubusercontent.com/pytorch/vision/main/references/detection/coco_utils.py")
os.system("wget https://raw.githubusercontent.com/pytorch/vision/main/references/detection/coco_eval.py")
os.system("wget https://raw.githubusercontent.com/pytorch/vision/main/references/detection/transforms.py")
定义数据增强函数
from torchvision.transforms import v2 as T
def get_transform(train):
transforms = []
if train:
transforms.append(T.RandomHorizontalFlip(0.5))
transforms.append(T.ToDtype(torch.float, scale=True))
transforms.append(T.ToPureTensor())
return T.Compose(transforms)
Testing forward() method
在训练之前测试一下模型的输出,可以大概了解预训练模型在这个任务下是个什么性能。
训练前的试验
加载预训练模型
import utils
model = torchvision.models.detection.fasterrcnn_resnet50_fpn(weights="DEFAULT")
dataset = PennFudanDataset("data/PennFudanPed", get_transform(train=True))
data_loader = torch.utils.data.DataLoader(
dataset,
batch_size=2,
shuffle=True,
collate_fn=utils.collate_fn
)
用数据集中的第一对来跑一下训练
images, targets = next(iter(data_loader))
images = list(image for image in images)
targets = [{k: v for k,v in t.items()} for t in targets]
output = model(images, targets)
print(output)
用一个随机数来进行一次推理
model.eval()
x = [torch.rand(3, 300, 400), torch.randn(3, 500, 400)]
predictions = model(x)
print(predictions[0])
正式训练
准备数据集与加载器
from engine import train_one_epoch, evaluate
device = torch.accelerator.current_accelerator().type if torch.accelerator.is_available() else "cpu"
print(device)
num_classes = 2
dataset = PennFudanDataset('data/PennFudanPed', get_transform(train=True))
dataset_test = PennFudanDataset('data/PennFudanPed', get_transform(train=False))
indices = torch.randperm(len(dataset)).tolist()
dataset = torch.utils.data.Subset(dataset, indices[:-50])
dataset_test = torch.utils.data.Subset(dataset_test, indices[-50:])
data_loader = torch.utils.data.DataLoader(
dataset,
batch_size=2,
shuffle=True,
collate_fn=utils.collate_fn
)
data_loader_test = torch.utils.data.DataLoader(
dataset_test,
batch_size=1,
shuffle=False,
collate_fn=utils.collate_fn
)
创建模型
model = get_model_instance_segmentation(num_classes)
model.to(device)
params = [p for p in model.parameters() if p.requires_grad]
optimizer = torch.optim.SGD(params, lr=0.005, momentum=0.9, weight_decay=0.0005)
lr_scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=3, gamma=0.1)
定义训练过程
num_epochs = 2
for epoch in range(num_epochs):
train_one_epoch(model, optimizer, data_loader, device, epoch, print_freq=10)
lr_scheduler.step()
evaluate(model, data_loader_test, device=device)
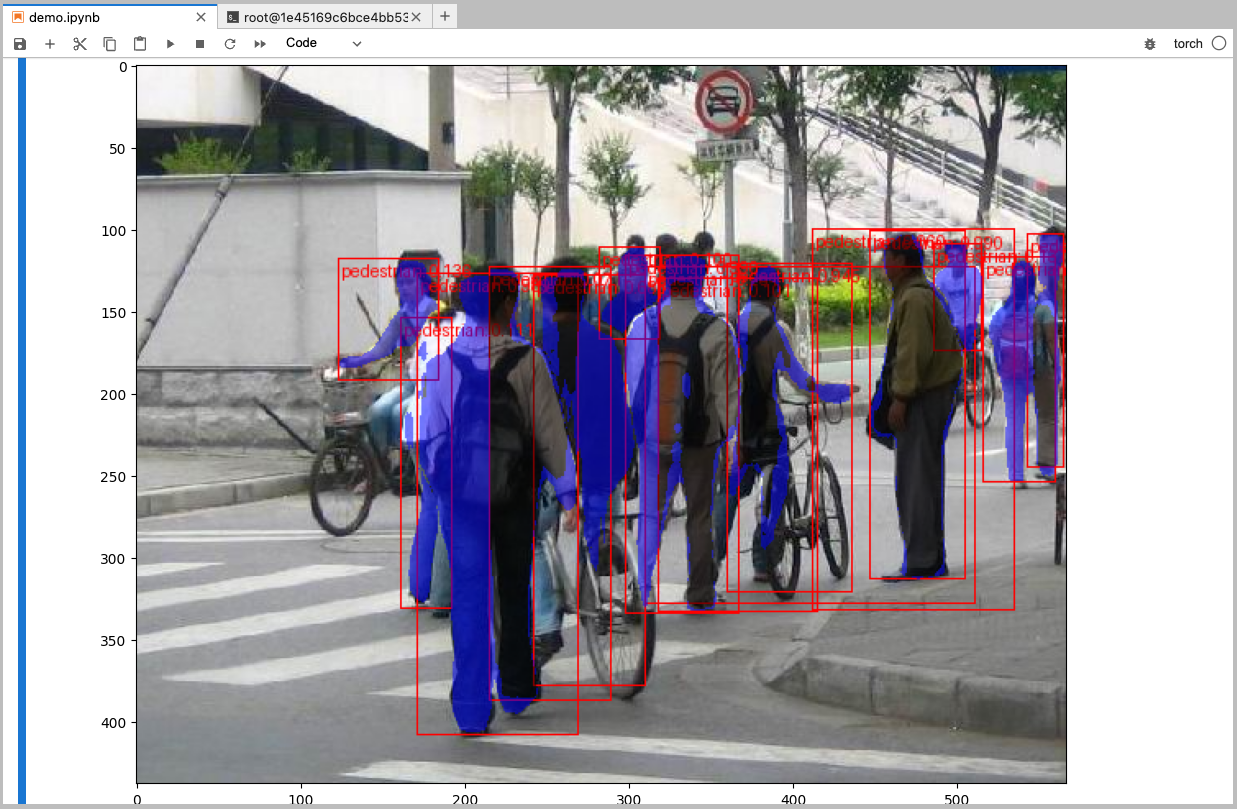
抽查一下训练结果
import matplotlib.pyplot as plt
from torchvision.utils import draw_bounding_boxes, draw_segmentation_masks
拉取一个图像
image = read_image("data/PennFudanPed/PNGImages/FudanPed00046.png")
eval_transform = get_transform(train=False)
模型执行推理
model.eval()
with torch.no_grad():
x = eval_transform(image)
x = x[:3, ...].to(device)
predictions = model([x,])
pred = predictions[0]
结果显示
image = (255.0 * (image - image.min()) / (image.max() - image.min())).to(torch.uint8)
image = image[:3, ...]
pred_labels = [f"pedestrian: {score:.3f}" for label, score in zip(pred["labels"], pred["scores"])]
pred_boxes = pred["boxes"].long()
output_image = draw_bounding_boxes(image, pred_boxes, pred_labels, colors="red")
masks = (pred["masks"] > 0.7).squeeze(1)
output_image = draw_segmentation_masks(output_image, masks, alpha=0.5, colors="blue")
plt.figure(figsize=(12, 12))
plt.imshow(output_image.permute(1, 2, 0))


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









