







这篇论文是2025年发表在arxiv上的一篇VLA领域论文,这篇论文整体读下来其实不难,主要的创新点在于他将触觉表示成3D形式与RGBD相机得到的点云一起给PointNet++计算3D特征,用DP生成动作,之前有些方法是将触觉特征单独处理,然后在合适的位置编码进去,或者在动作序列中保留几个位置用来表示触觉的力度。
写在最前面
为了方便你的阅读,以下几点的注意事项请务必了解:
- 该系列文章每个字都是我理解后自行翻译并写上去的,可能会存在笔误与理解错误,如果发现了希望读者能够在评论区指正,我会在第一时间修正错误。
- 阅读这个系列需要你有基本的 VLN, LLM, VLM 相关基础知识,有时候我会直接使用英文名词,因为这些词汇实在不容易找到符合语境的翻译。
- 原文可能因为版面限制存在图像表格与段落不同步的问题,为了更方便阅读,我会在博文中重新对图像表格进行排版,并做到引用图表的文字下方就能看到被引用的图表。因此可能会出现一张图片在博客中多处位置重复出现的情况。
- 对于原文中的图像,我会在必要时对图像描述进行翻译并附上我自己的理解,但如果图像描述不值得翻译我也不会强行写上去。
Basic Information
- 论文标题:3D-ViTac: Learning Fine-Grained Manipulation with Visuo-Tactile Sensing
- 原文链接: https://arxiv.org/abs/2410.24091
- 发表时间:2023年04月23日
- 发表平台:arxiv
- 预印版本号:[v1] Sun, 23 Apr 2023 19:10:53 UTC (4,495 KB)
- 作者团队:Tony Z. Zhao, Vikash Kumar, Sergey Levine, Chelsea Finn
- 院校机构:
- Columbia University;
- University of Illinois Urbana-Champaign;
- University of Washington;
- 项目链接: https://binghao-huang.github.io/3D-ViTac/
- GitHub仓库: 【暂无】
Abstract
触觉和视觉感知对于人类与环境进行细粒度交互都至关重要。为机器人开发类似的多模态感知能力可以显著增强和扩展它们的操作技能。本文介绍了 3D-ViTac 一种专为灵巧双手操作而设计的多模态感知和学习系统。系统采用配备密集传感单元的触觉传感器,每个传感单元的面积为 3 平方毫米。这些传感器成本低且灵活,可以详细而广泛地覆盖物理接触,有效地补充视觉信息。为了整合触觉和视觉数据,将它们融合到一个统一的 3D 表示空间中以保留它们的 3D 结构和空间关系。然后,可以将多模态表示与扩散策略相结合以进行模仿学习。通过具体的硬件实验,证明即使是低成本的机器人也可以执行精确的操作,并且性能显著优于仅使用视觉的策略,尤其是在与易碎物品进行安全交互以及执行涉及手部操作的长距离任务时。
- project page:https://binghao-huang.github.io/3D-ViTac
1. Introduction
人类在日常操作中高度依赖视觉和触觉。想象一下抓取鸡蛋或葡萄:首先通过视觉定位物体,然后从与物体的触觉交互中提取更多信息,以确定施加的适当力度;用勺子吃饭时,眼睛会估算勺子的整体位置和几何信息,而触觉则会在与食物交互的过程中提供详细的接触信息。视觉和触觉相辅相成,增强了人与环境的交互,并显著提高了我们的灵活性和鲁棒性,尤其是在涉及大遮挡和手部操作的任务中。
然而,为机器人构建这样一个多模态平台带来了两大挑战:
- 触觉硬件和系统:由于对最小范围和视角要求,许多现有的光学触觉传感器对于细粒度操作或需要柔顺交互的任务来说要么过于笨重要么过于僵硬。许多商用触觉传感器由于定制制造和电子元件而价格昂贵,而一些低成本触觉传感器通常过于稀疏,无法传达有效信息;
- 触觉和视觉模态的不同性质:触觉信号通常是局部的和物理的,而视觉数据更全局和语义化。这种差异对模型有效处理和解释数据提出了重大挑战。成功融合这些不同的模态需要精心设计触觉传感器和学习算法。
为了应对这些挑战,作者提出了 3D-ViTac 一种用于接触丰富的操作任务的新型多模态传感和学习系统:
- 对于触觉传感硬件系统,没有使用现有的光学触觉传感器,而是提出了一种替代的密集、灵活的触觉传感器阵列,该阵列覆盖了机器人末端执行器的更大区域。触觉传感器受
STAG手套的启发,具有成本效益、灵活性,并能够在操作过程中产生稳定的连续信号。如Fig.1所示,传感器阵列在每个软手指上的分辨率为 KaTeX parse error: Undefined control sequence: \tiems at position 3: 16\̲t̲i̲e̲m̲s̲16,双手触觉传感系统中总共有 1024 个触觉传感单元。这种密集、连续的触觉传感器阵列提供有效的反馈,包括接触的存在、施加的法向力的大小以及局部接触模式; - 在算法方面,鉴于多模态感官信息,不再像以往那样分别将视觉和触觉数据输入策略,而是提出了一种统一的 3D 视觉-触觉表征,将这两种模态融合在一起实现模仿学习。该表征将 3D 视觉点和 3D 触觉点(利用机器人运动学计算)集成到一个统一的 3D 空间中,明确地解释了视觉和触觉之间的 3D 结构和空间关系。这种方法通过扩散策略实现了有效的模仿学习,使系统能够对细微的力变化做出反应,并克服严重的视觉遮挡。
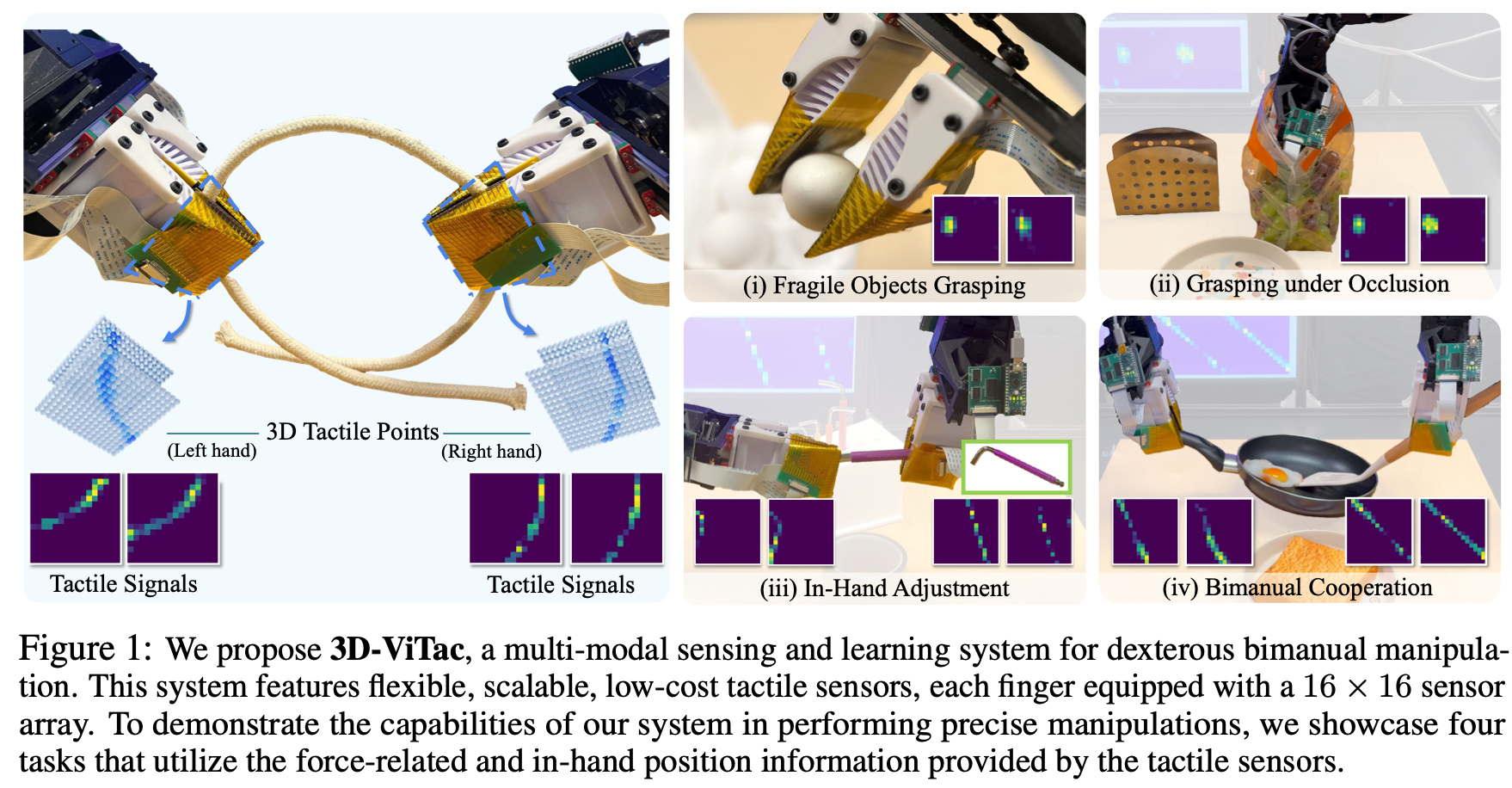
对四项具有挑战性的现实任务(例如,操作鸡蛋和水果等易碎物体,以及手持操作工具和器具,如Fig.1 所示)进行了全面评估。结果表明,作者提出的 3D 视觉触觉表征通过提供更详细的接触状态和局部几何或位置信息,显著提升了接触密集型操作的性能。作者观察到,在视觉遮挡严重的情况下,触觉信息尤为重要;还对感知特性进行了详细的消融研究,比较了不同触觉分辨率下的性能,并展示了持续触觉读取的重要性。此外,在数据收集过程中加入触觉反馈,使操作员能够收集更高质量的数据,从而使最终策略更加稳健。
2. Related Work
Bimanual Manipulation
双臂机器人装置为广泛的应用提供了丰富的机会。传统双臂操作方法基于经典的模型控制视角,利用已知的环境动力学。然而,这些方法依赖于真实的环境模型,而这些模型不仅构建耗时,而且通常需要全状态估计,尤其对于具有复杂物理特性的物体而言通常难以实现,例如可变形物体。近年来,机器人领域的许多研究人员越来越多地将研究重点转向基于learning的方法,例如强化学习和模仿学习。然而,大多数双手操作方法仍然主要依赖于视觉输入,由于人机本体之间的感知差距,限制了机器人达到人类水平的灵活性和灵巧性。为了克服这些限制,近期的研究采用了来自光学触觉传感器的 RGB 图像。然而,这些传感器中摄像头的探测范围有限,机器人手指通常非常笨重且过于僵硬,限制了它们在更复杂的灵巧任务中的有效性。相比之下,本研究中引入的触觉传感器基于压阻材料,可以实现更大规模、更柔顺的柔性纤细手指覆盖。
Visuo-Tactile Manipulation
触觉信息在生物学中起着至关重要的作用,而视觉和触觉的整合是人类与环境成功互动的基础。视觉提供了广阔的环境视角,但往往缺乏详细的接触信息,并且容易受到视觉遮挡的影响,而触觉感知可以有效地弥补这一缺陷,整合视觉和触觉信息对于机器人操作也至关重要。Lin 等人提出了一种视觉-触觉策略,利用双手系统中的人类演示,然而他们的触觉传感器分辨率低,而且缺乏对视觉和触觉之间空间关系的明确描述;Yuan 等人提出了机器人联觉,将视觉和触觉数据作为策略网络的单一输入,然而仅考虑低分辨率二进制触觉信号,而这在视觉-触觉感知能力方面受到限制。相比之下,作者的方法采用了密集的连续触觉感知系统,能够提供关于接触区域的全面信息,通过将两种模态整合到统一的三维表征空间中,对场景结构进行了清晰的描述,从而实现了更高效的策略学习过程。
3. Visuo-Tactile Manipulation System
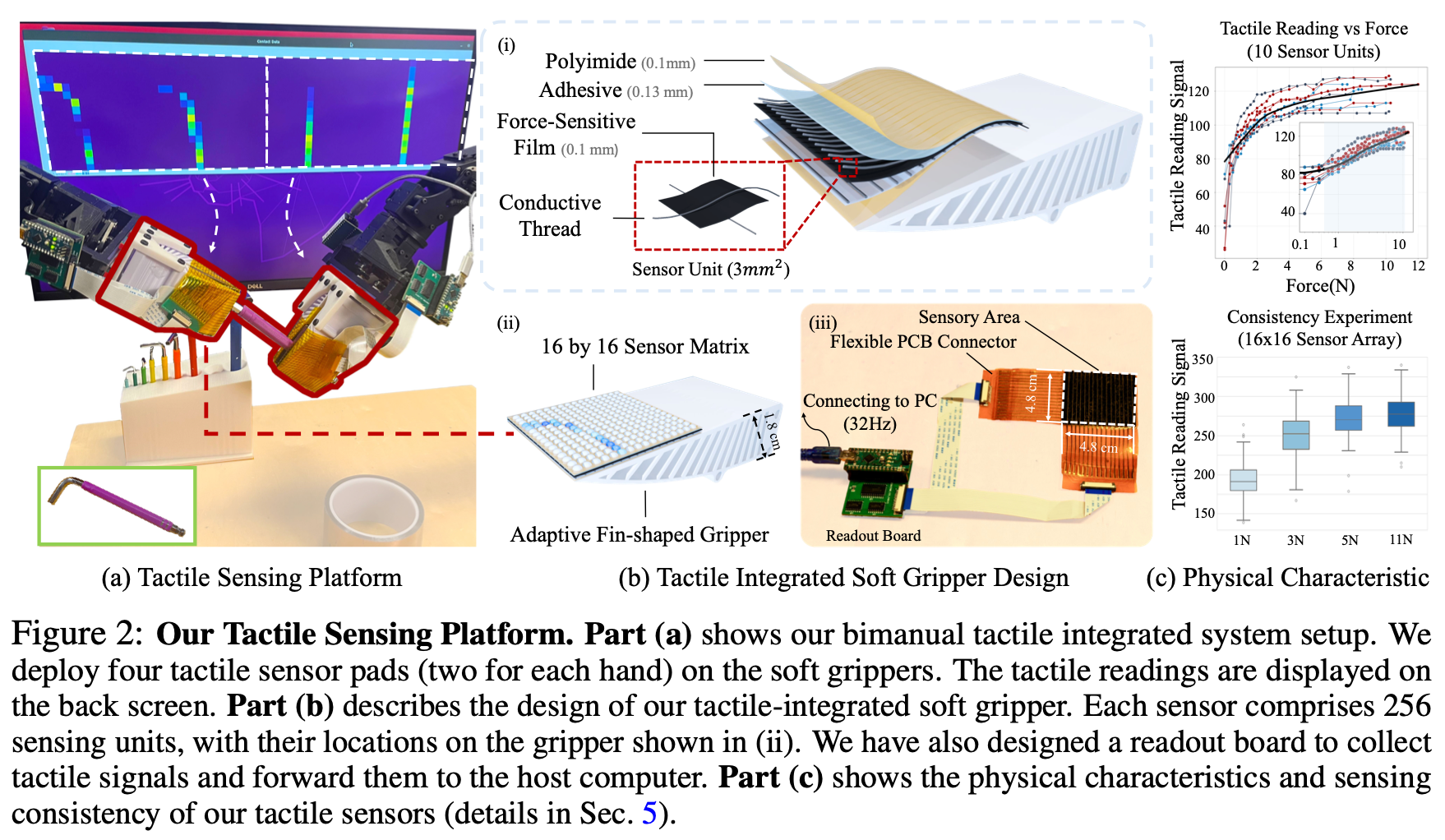
3.1 Sensor and Gripper Design
Flexible Tactile Sensors
传感器垫由电阻式传感矩阵组成,可将机械压力转换为电信号。这些触觉传感器垫的总厚度小于 1 毫米,可轻松集成到各种机器人操纵器上,包括机器人手臂的表面。在本文中,将触觉传感器安装在一个柔软且适应性强的鳍状夹持器上,如Fig.2 (b) 所示。这些柔性传感器垫可随柔软夹持器弯曲,并持续提供有效的信号传输,使该系统适用于各种机器人应用。
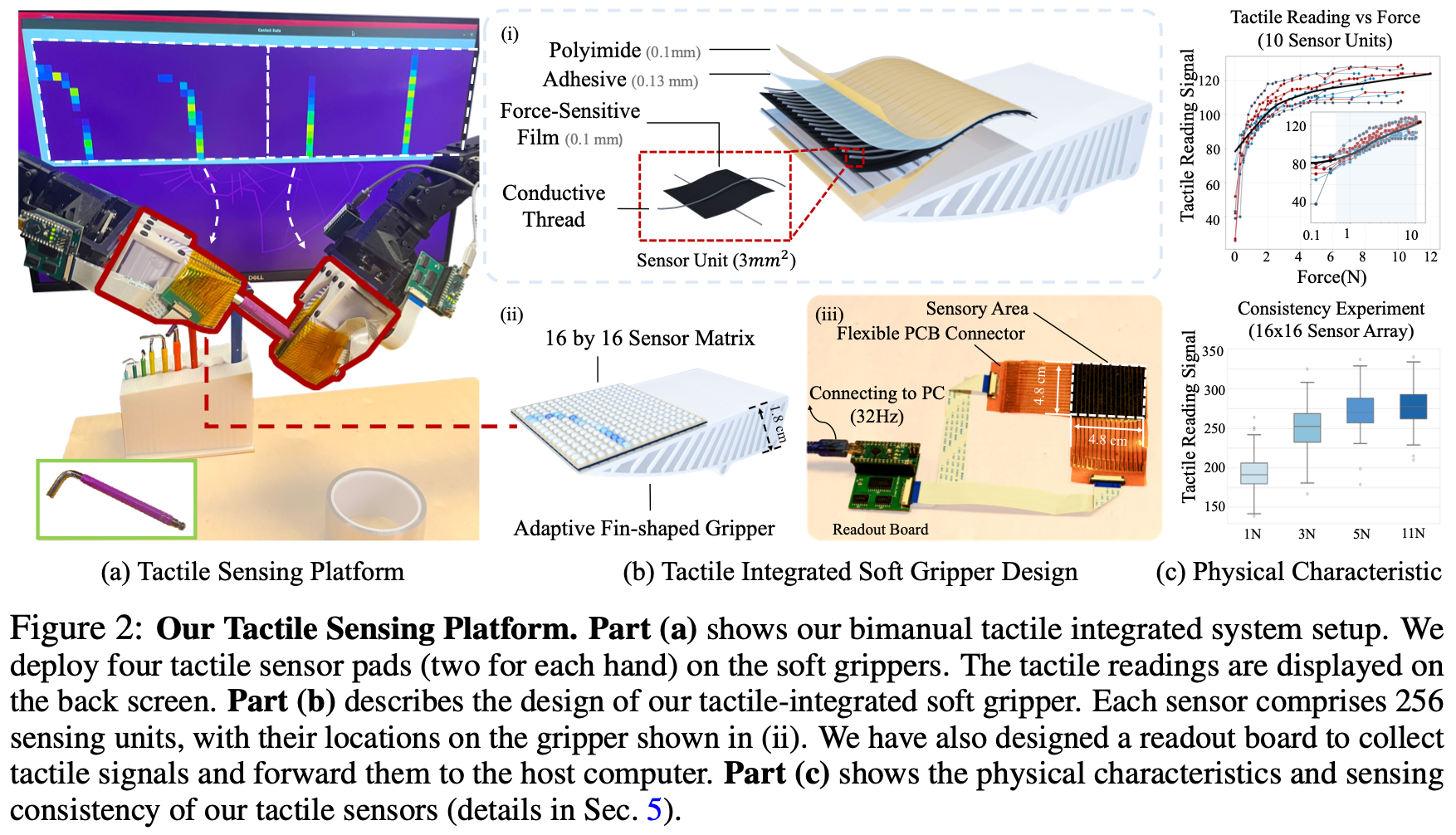
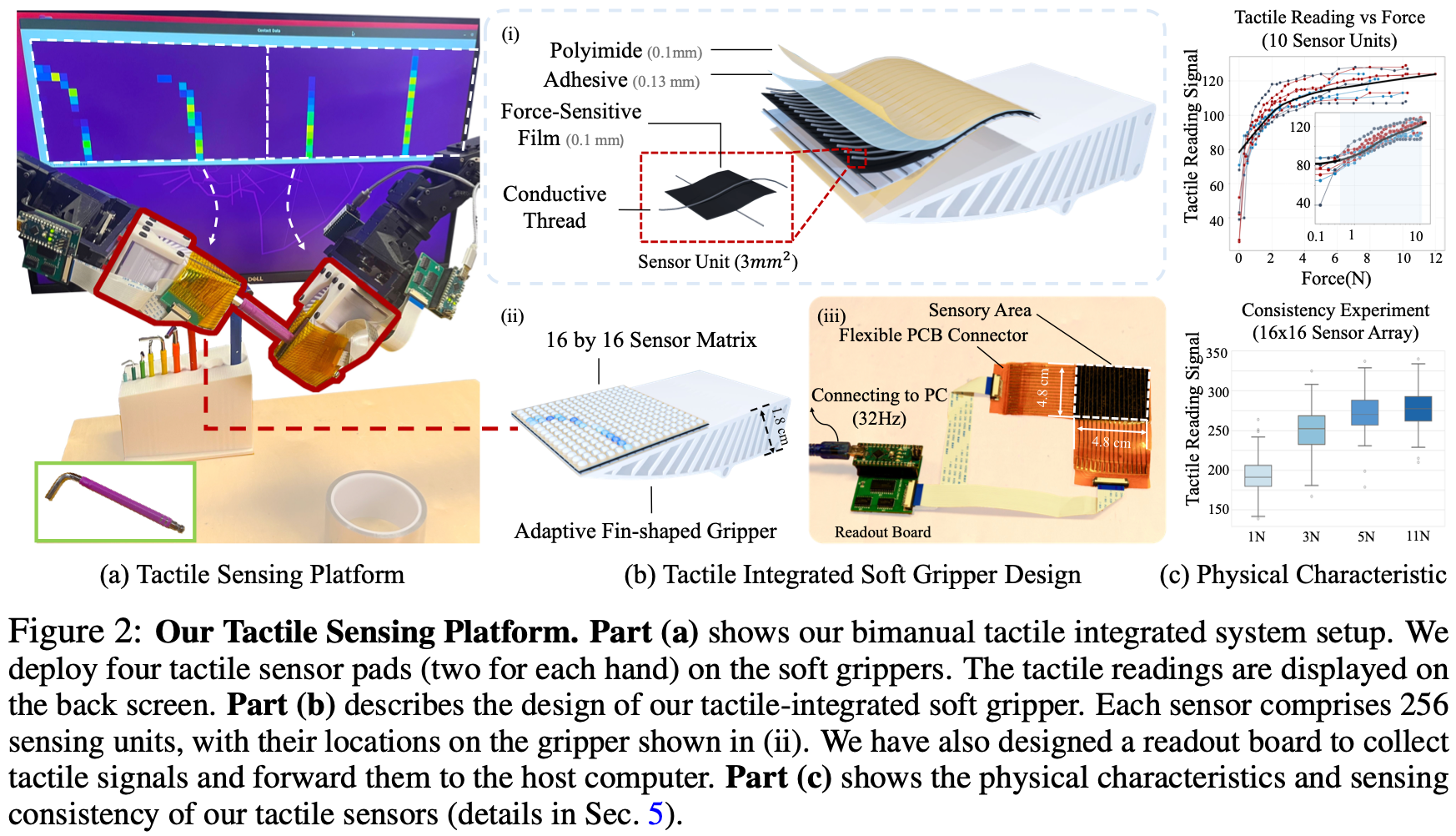
如Fig.2 (b)所示,机械手的每个手指都配备了一个传感器垫,其中包含 256 个传感单元(
16
×
16
16\times16
16×16传感器阵列)。传感器垫的尺寸、密度和空间传感分辨率可以定制;在当前的配置中,分辨率设置为每个传感器点 3 平方毫米。触觉传感垫采用三层设计,其中压阻层 (Velostat) 夹在两组正交排列的导电纱线之间用作电极;使用高强度粘合剂 (3M 468MP) 将这些层封装在两层成型的聚酰亚胺薄膜之间,确保电极和压阻薄膜之间牢固的电接触,这对于可靠的信号采集至关重要。传感器特性在多个设备之间可重复,并且在多个循环中可靠。有关触觉传感器制造的更多详细信息参阅 Appendix。
压阻层的电阻会随着施加的压力而变化,从而使每个传感器点能够将机械压力转换为电信号。这些模拟信号由 Arduino Nano 捕获,并通过串行通信传输到计算机。使用定制的电读出电路以高达约 32.2 FPS 的帧速率采集数据。一个传感器垫和读取板(不含 Arduino)的总成本约为 20 美元。
Integration of Flexible Tactile Sensor and Soft Gripper
将触觉传感器安装在由TPU材料制成的全3D打印软夹持器的表面上Fig.2 (b)。触觉传感器垫与柔性软夹持器完美结合。新的夹持器设计具有诸多优势:
- 夹持器的柔软特性显著增加了传感器与目标物体之间的接触面积。这不仅有助于稳定操作过程,还能确保物体接触模式和几何形状的一致性;
- 虽然视觉-触觉策略提供了一定程度的动作柔顺性,但夹持器的柔软性增加了机械柔顺性,能够更有效地处理易碎物体;
3.2 Multi-Modal Sensing and Teleoperation Setup
采用双手遥操作系统,使用两个主机器人控制两个跟随机器人在数据采集过程中以 10 Hz 的恒定频率从各种传感器(包括触觉传感器、多视角 RGBD 摄像头 (Realsense) 以及机器人目标动作和当前关节状态的数据)收集同步多模态信息。传感信息之间的同步对于保持多模态数据集的时间一致性至关重要,从而实现触觉反馈和视觉数据之间的精确对齐。通过在屏幕上可视化来实现实时触觉信息反馈,如Fig.2 (a)所示。这使人类操作员能够评估接触是否足以实现安全抓握,从而提高所采集数据的质量。
4. Learning Visuo-Tactile Dexterity
4.1 Problem Formulation
通过模仿学习解决了学习富含接触的机器人技能轨迹的挑战。Fig.3 概述了视觉-触觉数据的集成及其后续动作生成过程。具体来说,引入了一个视觉-触觉策略,表示为
π
:
O
→
A
\pi:O\to A
π:O→A。该策略将视觉和触觉观测
o
∈
O
o\in O
o∈O 映射到动作
a
∈
A
a\in A
a∈A。方法包含两个关键部分:
- Dense Visuo-Tactile Representation:密集的视觉-触觉表征,
Fig.3 (b)展示了视觉和触觉数据在统一坐标系中的集成,其中包括:(i) 3D 视觉点云,由摄像头捕获格式为 P t v i s u a l ∈ R N v i s × 4 P^{visual}_{t}\in R^{N_{vis}\times4} Ptvisual∈RNvis×4,包含一个额外的空通道以匹配触觉数据。 (ii) 3D 触觉点云,该触觉点云包含触觉感知单元的所有点,并使用感知值作为特征通道,格式为 P t t a c t i l e ∈ R N t a c × 4 P^{tactile}_{t}\in R^{N_{tac}\times4} Pttactile∈RNtac×4; - 策略学习:
Fig.3 (c)表示了模仿学习过程,基于构建的 3D 稠密视觉触觉表征,利用扩散策略将动作生成为机器人关节状态序列。
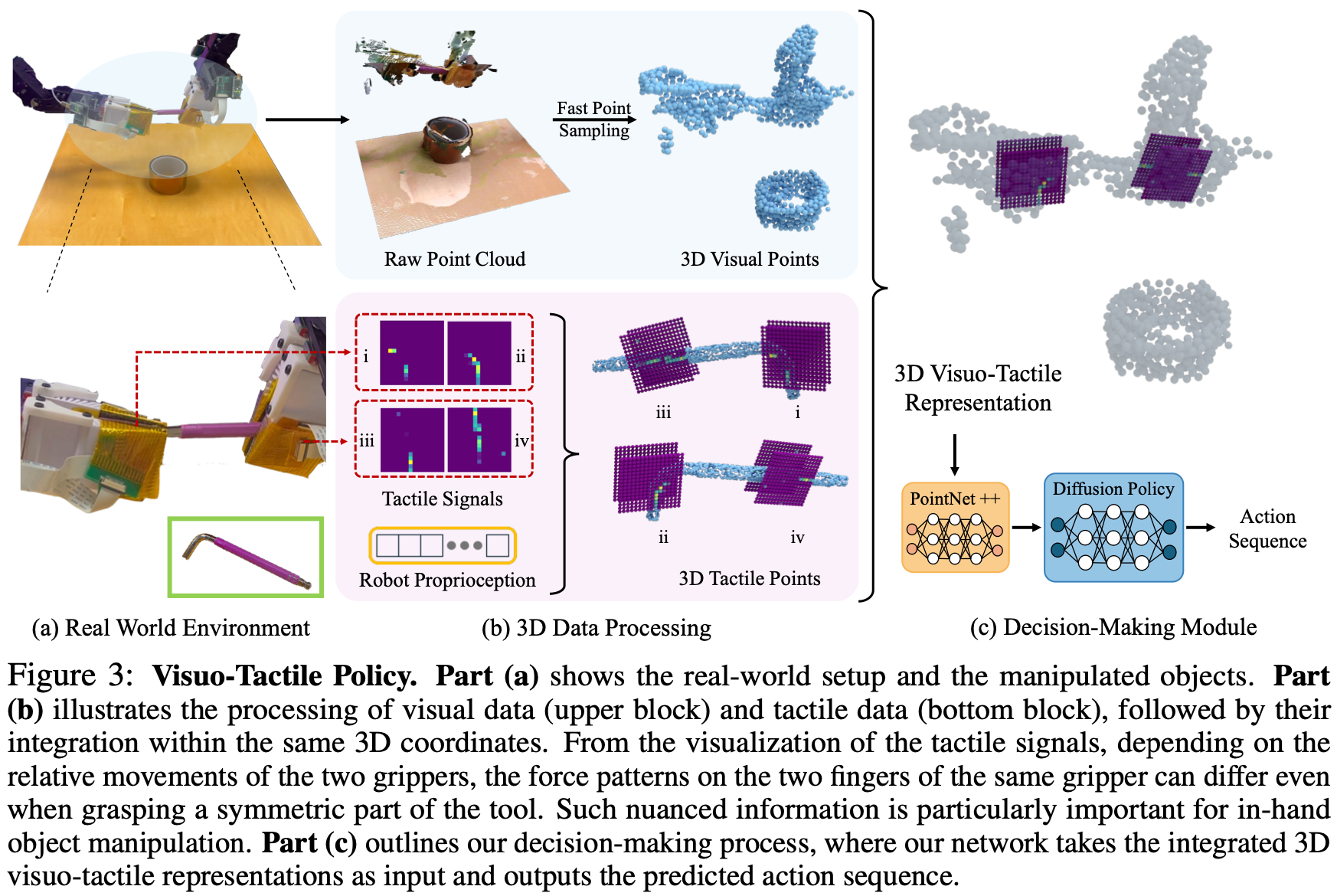
4.2 Dense Visuo-Tactile Representation
在作者的方法中,模型不分开处理触觉和视觉模态来提取特征,而是通过将触觉和视觉数据投影到同一个三维空间来整合它们。如Fig.3 (b)所示,上行演示了视觉观察的处理过程,下面描述了利用触觉信号和机器人本体感觉处理密集的三维触觉点的过程。
3D Visual Point Cloud
对摄像机捕获的点云实施了一系列数据预处理程序,表示为 P t v i s u a l ∈ R N v i s × 4 P^{visual}_{t}\in R^{N_{vis}\times4} Ptvisual∈RNvis×4 。该过程包括四个步骤:
- Merge:合并来自多视角深度观测的点云,以确保全面覆盖观测环境;
- Crop:使用手动定义的bounding box将点云裁剪到指定的工作区域;
- Down-Sample:为了提高视觉数据处理的效率,使用最远点采样(FPS)对点云进行下采样,以确保更均匀地覆盖 3D 空间。设置 N v i s = 512 N_{vis} = 512 Nvis=512 以在几何细节和计算效率之间保持平衡;
- Transform:将点云变换到机器人的基准坐标系中;
3D Tactile Point Cloud
基于触觉的点云 P t t a c t i l e ∈ R N t a c × 4 P^{tactile}_{t}\in R^{N_{tac}\times4} Pttactile∈RNtac×4 表示三维空间中触觉单元的位置 t t t 和连续触觉读数。为了确定每个传感器的位置,作者基于机器人的关节状态,使用正向运动学计算实时夹持器的位置。将触觉点云设置为 N t a c = 256 × N f i n g e r N_{tac} = 256\times N_{finger} Ntac=256×Nfinger,其中 N f i n g e r N_{finger} Nfinger 表示配备触觉传感器垫的机器人手指数量。每个传感器垫由 256 个触觉点组成。对于单臂任务, N + f i n g e r = 2 N+{finger} = 2 N+finger=2,对于双手任务 N f i n g e r = 4 N_{finger} = 4 Nfinger=4。
3D Visuo-Tactile Points
将两种类型的点云
o
=
P
t
t
a
c
t
i
l
e
∪
P
t
v
i
s
u
a
l
o=P^{tactile}_{t} \cup P^{visual}_{t}
o=Pttactile∪Ptvisual 整合到相同的空间坐标中,如Fig.3 (c)所示。每个点还被分配一个one-hot编码,以指示它是视觉点还是触觉点。这种统一的 3D 视觉-触觉表征为策略网络提供了触觉和视觉数据之间空间关系的详细而明确的描述。这种整合引入了一种归纳偏差,可以增强在接触密集型任务中的操作有效性,尤其是在那些需要全面考虑两种模态的任务中。
4.3 Training Procedure
如Fig.3 (c) 所示,决策模块被表述为一个条件去噪扩散模型。它以 PointNet++ 架构为backbone,以 3D 视觉触觉表征
o
o
o 为条件,将随机高斯噪声去噪为动作
a
a
a。
5. Experiments
5.1 Tactile Sensor Hardware Characterization
作者评估了触觉传感器的物理特性,以更好地了解其性能和信号范围。如Fig.2 (c)所示,触觉传感器的读数信号如何随施加的力而变化。从一个传感器垫中选择了 10 个传感器单元,并使用每个传感器单元的数据来拟合单独的曲线。Fig.2 (c)中的下图显示了触觉传感器垫在不同负载下的性能一致性。将传感器分成
8
×
8
8\times8
8×8 网格,并对每个单元的读数求和。使用箱线图显示
8
×
8
8\times8
8×8 网格在不同负载下的一致性。为了展示密集、连续的触觉传感器的能力,对比使用仅 3D 触觉信息和被操作物体的模型进行了 6 DoF 姿态估计的额外实验。更多详细信息可在附录中找到。
5.2 Experiment Setup for Imitation Learing
利用四项具有挑战性的现实世界机器人任务来评估我们的多模态感知和学习系统,每个任务分为四个步骤,以便更细致地评估其性能Fig.4。任务根据其如何从触觉信号的整合中获益进行分类。以下是所有任务的基本描述和评估指标:
1. Tasks Requiring Fine-Grained Force Information:
- Egg Steaming:首先用右手打开蛋托,然后抓取鸡蛋并将其放入煮蛋器中;用左手将煮蛋器的盖子重新盖好并固定到鸡蛋上。评估指标:如果鸡蛋放置无损,且煮蛋器盖子正确盖在鸡蛋上,则任务成功。如果鸡蛋因抓取力不足而掉落,或因用力过大而破裂,则视为操作失败;
- Fruit Preparation:左手抓住盘子并将其放置在桌子上,两个机械臂协作打开塑料袋,然后右臂抓住一颗或多颗葡萄并将其放置在盘子上。评估指标:如果葡萄被放置在盘子上且没有受到任何损坏,则任务成功;
2. Tasks Requiring In-Hand State Information:

- Hex Key Collection:左右手各自握住一个六角扳手,用左手调整六角扳手的位置,将内六角扳手准确地插入盒子上的孔中。评估指标:成功将内六角扳手插入孔中即为操作成功。此外,如果未能正确调整六角扳手的位置,则可能导致无法将其插入孔中;
- Sandwich Serving:右手握住公勺,左手握住锅柄倾斜锅,右手从锅中取出煎蛋,并将其放在面包上。评估指标:机器人必须成功从锅中取出煎蛋并将其放在面包上;
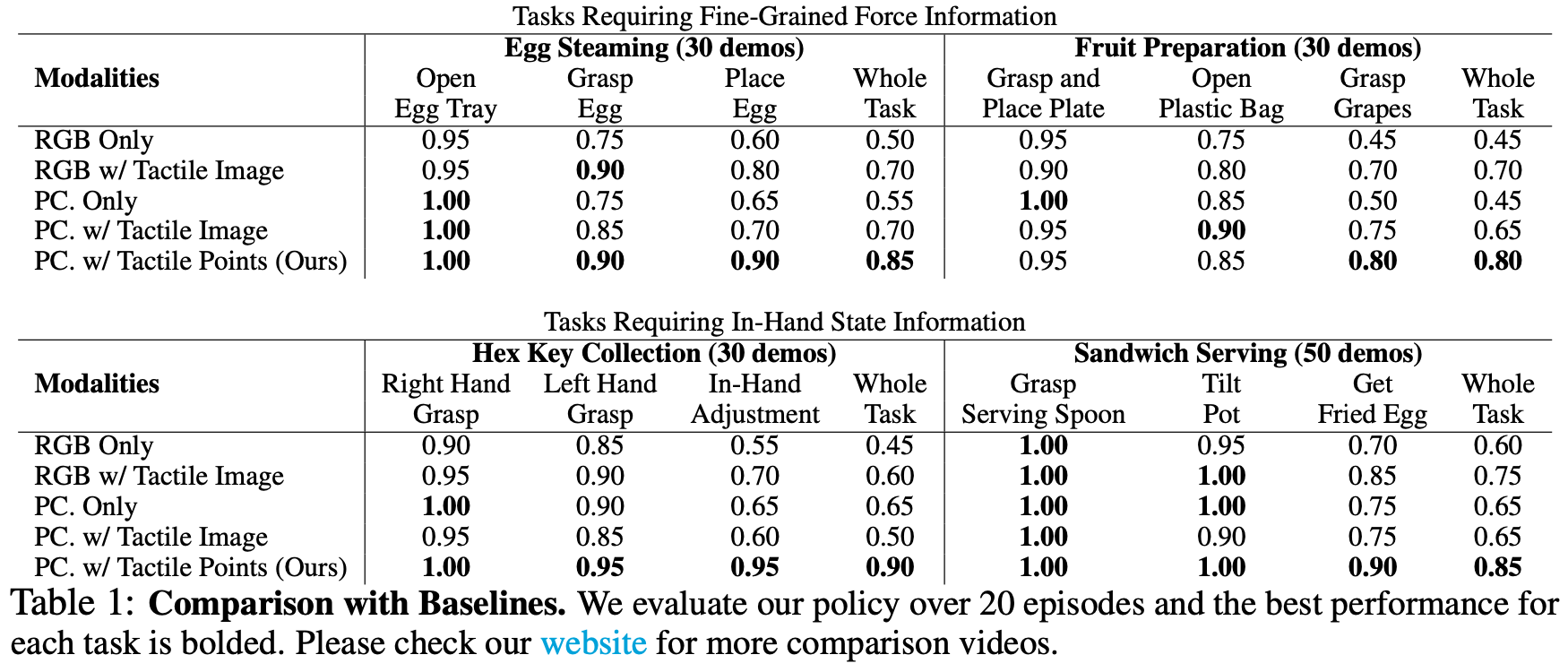
实验中主要将模型与以下baseline方法进行比较。所有策略都训练了 2,000 个 epoch。所有方法(包括基线方法)都使用三个摄像机视图:
- RGB Only:使用来自摄像机的多视角RGB图像作为基于图像的扩散策略的输入;
- RGB w/ Tactile Image:通过不同的分支处理多视角RGB图像和触觉图像,以实现扩散策略。使用CNN作为触觉图像的特征提取器;
- PC. Only:仅使用多视角视觉点云作为扩散策略的感知模态,
PointNet++作为特征提取器; - PC. w/ Tactile Image:通过不同的分支融合多视角视觉点云和触觉图像,以实现扩散策略,使用 CNN 作为触觉图像的特征提取器,并使用
PointNet++作为点云的特征提取器;
5.3 Qualitative Analysis
策略整合了三种模式:视觉、触觉、机器人本体感受,并已通过四项具有挑战性的长视域任务证明其有效性。观察到整合触觉的三个主要优势:
【Note】:这部分建议去他们项目网站看看视频可以更直观感受baseline失败的现象 https://binghao-huang.github.io/3D-ViTac/
- 触觉传感器能够提供关于接触存在和适当施力程度的关键反馈:在蒸鸡蛋任务中,baseline的一个常见问题是施力不足,这通常会导致鸡蛋掉落或无法从托盘中成功抓取;在葡萄处理任务中,当抓取器尝试一次抓取多颗葡萄时,通常会施加过大的力从而损坏葡萄;
- 策略利用触觉提供的详细接触模式来有效解决视觉遮挡问题:在六角扳手收集任务中,baseline的一个常见失败是无法调整手中六角扳手的位置,从而导致后续插入尝试失败;在三明治夹取任务中,触觉反馈对于理解握持状态以及接触区域与所有工具之间的空间关系至关重要,尤其是在勺子与锅具交互时,这在baseline中工具可能会被动旋转是导致失败的主要原因;
- 触觉反馈提供了在不同任务阶段之间转换所需的能力:这在视觉信息嘈杂或严重遮挡的场景中尤为重要。在袋子抓取葡萄的实验中,纯视觉策略经常失败,经常卡在袋子里而无法进入下一阶段。更多详细信息和失败案例视频;
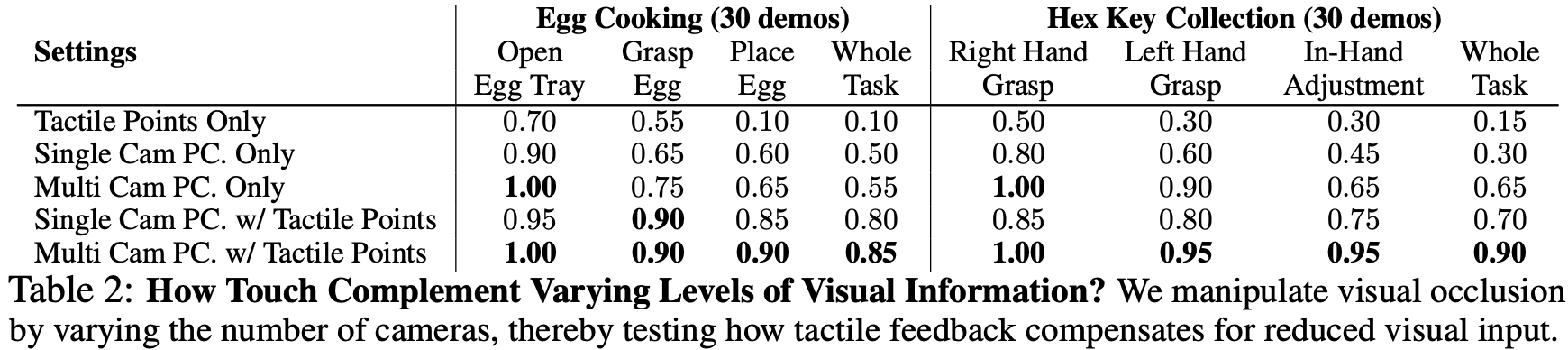
Ablation Study on Varying Levels of Visual Information
视觉遮挡在操作任务中,尤其是在双手操作任务中,为了确定触觉感知能否弥补视觉遮挡,通过改变训练集和策略部署过程中使用的摄像头数量来改变遮挡程度。如Table.2 所示,“Cam”指的是使用视觉点云,而“Tactile Point”指的是使用与摄像头坐标对齐的 3D 空间中的触觉点云。结果表明,即使摄像头数量减少导致视觉遮挡加剧,该策略在触觉信息的帮助下仍然表现良好。
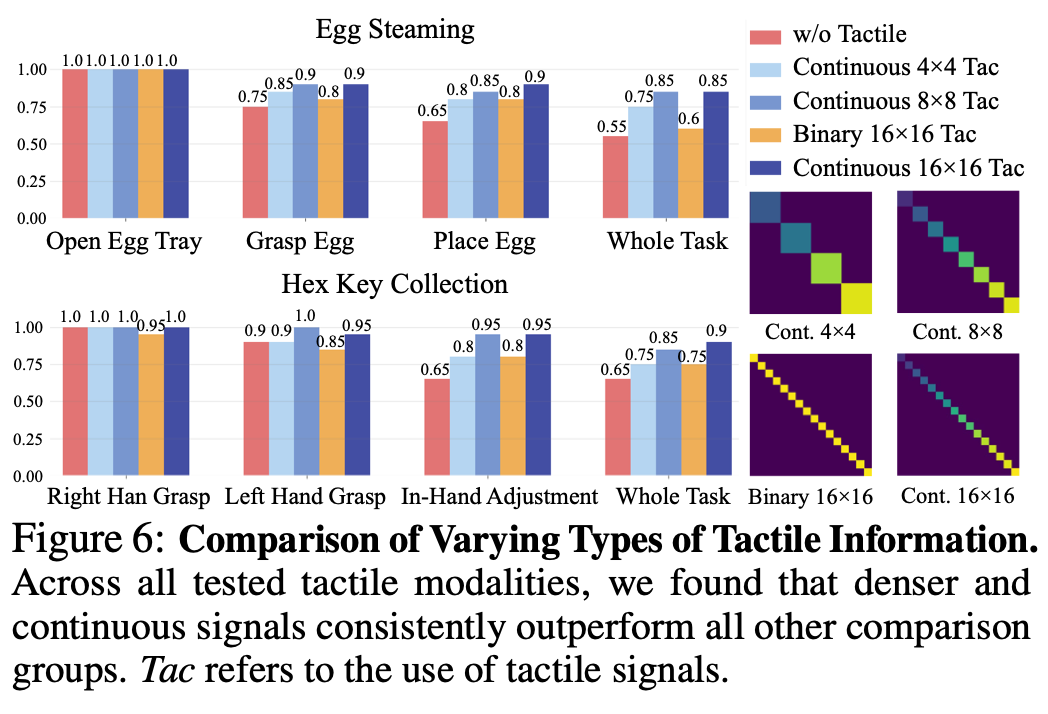
Ablation Study on Varying Levels of Tactile Information
接触数据的形式和分辨率各不相同,密集和连续的触觉数据不仅能指示触碰,还能测量力的大小和局部接触模式,这些是稀疏二进制触觉信号所缺乏的能力。为了验证这一点,作者将触觉分辨率从
16
×
16
16\times16
16×16 变为
8
×
8
8\times8
8×8 和
4
×
4
4\times4
4×4,并添加了一条仅考虑二进制信号的额外基线。Fig.6 中的所有baseline都包含多视角点云,作者发现连续信号显著提高了性能,尤其是在需要精确掌握所抓物体在手中方向的操作中。分辨率为
16
×
16\times
16× 的密集触觉模式略胜于
8
×
8\times
8× 分辨率,并明显超过
4
×
4
4\times4
4×4 和二进制比较组。
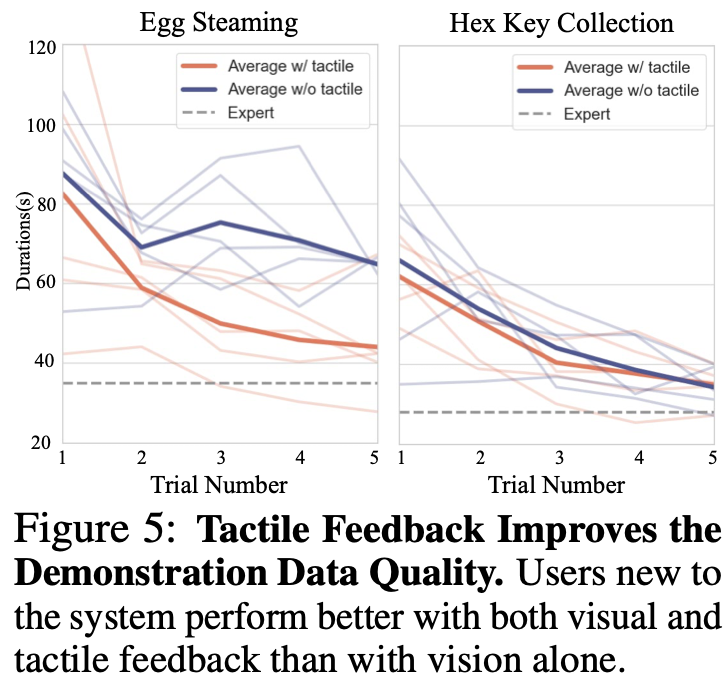
Demonstration Data Quality with Tactile Feedback
如Fig.2 (a)所示,在数据采集过程中,实时触觉信号以可视化的方式显示在操作员的屏幕上。此功能不仅提高了数据采集的效率,还提高了数据质量。为了验证触觉反馈的有效性,招募了 10 位新用户完成两项任务。其中 5 位用户使用触觉反馈操作远程操作系统,而另外 5 位用户则不使用。完成任务所需的时间如Fig.5 所示。
6 Conclusion and Limitation
Conclusion
本文开发了一个用于多接触机器人操作的多模态感知和学习系统。引入了一个密集灵活的触觉传感器阵列,该阵列可覆盖更大面积的薄型柔性机器人夹持器;还提出了一个统一的三维视觉-触觉表征,该表征明确地解释了视觉和触觉之间的三维结构和空间关系。在一系列具有挑战性的操作任务中展示了这些创新的有效性。我们承诺将发布代码和硬件配置。
Limitations
由于数据收集本身以及触觉感知模态的增加,使用多模态感知系统收集真实数据的成本很高。研究中缺少触觉传感器的模拟,这限制了引入随机化或扩展数据的能力。在未来的工作中,目标是增强系统能力,更好地利用物理模拟方面的进展,进一步提升策略的通用性和鲁棒性。

















 707
707

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









