







这是一篇2018年发表在arxiv上有关机器人强化学习的论文,这篇论文非常重要,可以说是做机器人运控强化学习方面必读文章,虽然文中的所有实验都是在仿真环境下展开的,但里面的policy设置方法和训练技巧仍然值得学习。
写在最前面
为了方便你的阅读,以下几点的注意事项请务必了解:
- 该系列文章每个字都是我理解后自行翻译并写上去的,可能会存在笔误与理解错误,如果发现了希望读者能够在评论区指正,我会在第一时间修正错误。
- 阅读这个系列需要你有基本的 RL、DL 相关基础知识,有时候我会直接使用英文名词,因为这些词汇实在不容易找到符合语境的翻译。
- 原文可能因为版面限制存在图像表格与段落不同步的问题,为了更方便阅读,我会在博文中重新对图像表格进行排版,并做到引用图表的文字下方就能看到被引用的图表。因此可能会出现一张图片在博客中多处位置重复出现的情况。
- 对于原文中的图像,我会在必要时对图像描述进行翻译并附上我自己的理解,但如果图像描述不值得翻译我也不会强行写上去。
Basic Information
- 论文标题:DeepMimic: Example-Guided Deep Reinforcement Learning of Physics-Based Character Skills
- 原文链接: https://arxiv.org/abs/1804.02717
- 发表时间:2018年07月27日
- 发表平台:arxiv
- 预印版本号:[v3] Fri, 27 Jul 2018 03:44:10 UTC (17,423 KB)
- 作者团队:Xue Bin Peng, Pieter Abbeel, Sergey Levine, Michiel van de Panne
- 院校机构:
- University of California, Berkeley;
- 项目链接: https://xbpeng.github.io/projects/DeepMimic/index.html
- GitHub仓库: https://github.com/xbpeng/DeepMimic
Abstract
角色动画(character animation)的一个长期目标是:结合数据驱动的行为描述与能够在物理仿真中执行相似行为的系统,从而实现对扰动和环境变化的真实响应。作者展示了强化学习(RL)方法可以经过调整以用来学习鲁棒的控制策略,既能够模仿各种示范动作片段,又能掌握复杂的恢复动作、适应形态变化,并完成用户指定的目标任务。作者的方法支持关键帧动画、高动态动作(如动作捕捉得到的翻转、旋转动作)以及重定向动作。通过将动作模仿目标与任务目标结合,训练出能在交互环境中智能反应的角色,例如朝指定方向行走,或向用户设定的目标投掷物体。这种方法兼具了以动作片段定义角色风格与表现的便利性和高质量,以及基于物理仿真和强化学习方法所带来的灵活性与广泛适应性。作者进一步探索了多片段融合的训练策略,从而培养出能掌握丰富、多样技能的多能智能体。实验涵盖了多种角色(人类、Atlas机器人、双足恐龙、龙)与广泛的技能类型,包括行走、特技表演以及武术动作。

上面有一些关键词:
- 关键帧动画(keyframed motions):由人工设定若干关键时间点的角色姿态,系统自动在关键帧之间插值生成完整动作。传统动画制作常用此方法;
- 动作捕捉(motion capture):使用传感器或摄像头捕捉真人或物体运动轨迹,从而生成真实感很强的动画数据;
- 重定向动作(retargeted motions):将一套动作数据(通常采自某一角色)调整应用到另一种不同形态的角色上,例如将人类动作应用到恐龙模型上;
1. Introduction
基于物理的被动现象(如布料和流体)仿真在工业界非常常见。然而,对角色的物理仿真使用却相对保守。对人类和动物的运动进行建模仍然是一个具有挑战性的问题,目前很少有方法能够模拟现实世界中表现出的各种行为,这一领域的括泛化和可定向性是一个长期挑战。依赖于手动设计的控制器的方法已经产生了令人信服的结果,但它们推广到新动作和新状态的能力受到人类洞察力的限制。尽管人类擅长于执行各种各样的技能,但想要清楚地表达出这种熟练程度背后的内部策略却很困难,而将它们编码到控制器中则更具挑战性;可定向性是阻碍模拟角色采用的另一个障碍。为模拟角色创作动作仍然非常困难,并且当前的界面仍然无法为用户提供从模拟角色中引出所需行为的有效方法。
强化学习 (RL) 为运动合成提供了一种很有前景的方法,agent通过反复试验学习执行各种技能,从而减少了对人类洞察力的需求。虽然深度强化学习已被证明可以在先前的工作中产生一系列复杂的行为,但迄今为止生成的动作质量远远落后于最先进的运动学方法或手动设计的控制器。特别是使用深度 RL 训练的控制器表现出严重且滑稽的伪影,例如多余的上半身运动、奇怪的步态、不切实际的姿势。提高学习控制器质量的一个自然方向是结合动作捕捉或手工制作的动画数据。在先前的研究工作中,此类系统通常是通过在运动动画系统之上叠加基于物理的跟踪控制器来设计的。这种方法具有挑战性,因为运动动画系统必须生成可跟踪的参考运动,由此产生基于物理的控制器在修改运动,想要复现与目标能力有较大差异的合理动作时仍然困难,并且此类方法的往往相当复杂。
理想的基于学习的动画系统应该允许使用者或动捕演员提供一组风格参考动作,然后根据这些参考动作生成目标导向且满足物理约束的行为。在本研究中,作者采用一种简单的方法来解决这个问题,即直接奖励学习到的控制器,使其能够生成与参考动画数据相似的动作,同时还能实现额外的任务目标,演示了三种从多个片段构建控制器的方法:使用基于最大算子的多片段奖励进行训练;训练策略以执行可由用户触发的多种不同技能;通过使用值函数来估计过渡的可行性,对多个单片段策略进行排序。
论文的核心贡献是一个基于物理的角色动画框架,将目标导向的强化学习与数据相结合,数据可以以动作捕捉片段或关键帧动画的形式提供。虽然框架由一些一段时间的单个组件组成,但在数据驱动和基于物理的角色动画背景下,这些组件的特殊组合仍然是新颖的。正如在实验中所展示的,模型产生了各种技能,其运动质量和鲁棒性大大超过了以前的工作。通过将动作捕捉数据合并到相位感知策略中,系统可以产生基于物理的行为,这些行为在没有扰动的情况下在外观上与参考动作几乎没有区别,从而避免了以前的深度强化学习算法所表现出的许多伪影。即使存在扰动或修改,模型产生的动作依然自然,恢复策略也展现出高度的鲁棒性,且无需人工干预。据作者所知,模型展示了一些基于学习方法生成的性能最佳的物理模拟角色。在消融研究中,确定了方法中的两个特定组成部分:参考状态初始化和提前终止,这对于实现高度动态的技能至关重要;作者还展示了几种将多个片段集成到单个策略中的方法。
Related Work
从生物力学到机器人技术和动画,对关节运动进行建模有着悠久的历史。近年来,随着机器学习控制算法的成熟,机器学习社区对这些问题的兴趣也日益浓厚。本文将重点关注动画和强化学习领域中最密切相关的工作。
- Kinematic Models:运动学方法是角色动画中一种经久不衰的研究方法,在拥有大量数据的情况下非常有效。给定一个运动片段数据集,可以构建控制器来选择在特定情况下播放的适当片段。高斯过程已用于学习潜在表征,可以在运行时合成运动;深度学习模型(例如自动编码器和相函数网络)也被用于开发运动环境中的人体运动生成模型,在高质量数据的支持下,数据驱动的运动学方法通常能比大多数基于模拟的方法产生更高质量的运动,但合成数据集以外的行为能力可能有限。随着任务和环境变得复杂,采集足够的运动数据来充分覆盖所有可能的行为很快就会变得难以为继。将物理学作为先验知识的来源,了解运动在存在扰动和环境变化的情况下应如何变化,可以解决这个问题。
- Physics-basedModels:为模拟角色设计控制器仍然是一个具有挑战性的问题,并且通常依赖于人类的洞察力来实现特定任务的策略。运动一直是大量研究的主题,为人类和非人类角色开发了鲁棒的控制器。许多此类控制器是底层简化模型和优化过程的产物,通过调整一组参数以实现所需的行为;基于二次规划的动态感知优化方法也被应用于开发运动控制器。虽然基于模型的方法已被证明对各种技能都有效,但它们往往难以处理需要长期规划的更多动态运动以及富含接触的运动;先前学者们已经探索了轨迹优化,以便为各种任务和角色合成物理上合理的运动。这些方法使用离线优化过程在延长的时间范围内合成运动,其中运动方程被强制作为约束。最近的研究已将这些技术扩展到在线模型预测控制方法,尽管它们在运动质量和长期规划能力方面仍然有限。作者的方法相对于上述方法的主要优势在于通用性。作者证明:单一的无模型框架能够实现更广泛的运动技能(从步行到高度动态的踢腿和翻转)并能够对这些技能进行排序,结合运动模仿和任务相关的需求、紧凑且快速计算的控制策略、利用丰富的高维状态和环境描述的能力。
- ReinforcementLearning:许多用于开发模拟角色控制器的优化技术都基于强化学习。值迭代方法已用于开发运动控制器,在给定任务的背景下对运动剪辑进行排序。最近,用于强化学习的深度神经网络模型的引入催生了可以执行各种具有挑战性的任务的模拟agent。策略梯度方法已成为许多连续控制问题的首选算法。尽管 RL 算法已经能够使用最少的任务特定控制结构来合成控制器,但由此产生的行为通常看起来不如手动设计的行为自然,其中部分原因在于难以指定自然运动的奖励函数,特别是在缺乏可用于实现自然模拟运动的生物力学模型和目标的情况下。以扭矩驱动的运简单目标运动(例如前进或保持期望速度)通常会产生肢体多余运动、步态不对称、不合理步态。为了减轻这些伪影,使用诸如冲击惩罚之类的附加目标来阻止这些不良行为。设计这些目标函数需要相当程度强的人类洞察力,而且通常只能产生有限的改进;基于模仿动作捕捉的 RL 方法,例如
GAIL,通过使用数据诱导目标解决设计奖励函数的难点,虽然这已被证明可以提高生成动作的质量,但效果与计算机动画中的标准方法相比仍然不占优势;DeepLoco系统采用了与本文类似的方法,即在奖励函数中添加一个模仿项,但仍然有明显的局限性:它使用固定的初始状态,无法实现高度动态的运动,仅在由高级控制器计算的足部位置目标定义的运动任务上进行了演示,并且应用于单个无臂双足模型;多剪辑演示涉及一个手工制作的程序,用于选择适合转动动作的目标剪辑。 - Motion Imitation:在计算机动画中,模仿参考运动由来已久。这一概念最早是平面角色的双足运动,使用策略搜索调整的控制器。基于模型的参考运动跟踪方法也已被证明可用于 3D 人形角色的运动。参考运动也被用于塑造深度强化学习的奖励函数,以产生更自然的运动步态和扑翼飞行。在作者的研究中,展示了执行范围更广的高难度动作的能力:高动态旋转、踢腿、间歇性触地空翻,并表明参考状态初始化和提前终止对于这些动作的成功至关重要,作者还探索了多种多片段整合和技能排序的方案。
就功能而言,与本文工作最相似的是基于采样的控制器 SAMCON 。SAMCON 已经重现了一系列令人印象深刻的技能,据作者所知,SAMCON 是唯一一个通过模拟角色展示如此多样化的高度动态和杂技动作的系统。然而该系统很复杂,具有许多组件和迭代步骤,并且需要为合成的线性反馈结构定义低维状态表示。由此产生的控制器擅长模仿原始参考运动,但目前尚不清楚如何将该方法扩展到任务目标,特别是当它们涉及大量感官输入时。最近的一个变体引入了深度 Q 学习来训练高级策略,该策略从预先计算的 SAMCON 控制片段集合中进行选择。这为控制片段的执行顺序提供了灵活性,并被证明能够完成具有挑战性的非终止任务,例如在邦戈板上保持平衡和在球上行走。在本研究中,作者提出了一个使用深度强化学习的替代框架,它在概念上比 SAMCON 简单得多,但仍然能够学习高度动态和杂技性的技能,包括具有任务目标和多个片段的技能。
3. Overview
作者的系统接收一个角色模型、一组相应的运动参考动作、一个由奖励函数定义的任务作为输入。然后合成一个控制器,使角色能够模仿参考动作,同时满足任务目标,例如打击目标或在不规则地形上朝所需方向奔跑。每个参考动作都表示为一系列目标姿势 { q ^ t } \{\hat{q}_{t}\} {q^t};控制策略 π ( a t ∣ s t , g t ) \pi(a_{t}|s_{t},g_{t}) π(at∣st,gt) 将特定于任务的目标 g t g_{t} gt 的角色状态 s t s_{t} st 映射到动作 a t a_{t} at;然后使用动作 a t a_{t} at 计算要施加到角色每个关节的扭矩,每个动作为比例微分 (PD) 控制器指定目标角度,然后产生施加于关节的最终扭矩;参考动作用于定义模仿奖励 r I ( s t , a t ) r^{I}(s_{t},a_{t}) rI(st,at);目标定义特定于任务的奖励 r G ( s t , a t , g t ) r^{G}(s_{t},a_{t},g_{t}) rG(st,at,gt);系统的最终目标是得到一个策略,使模拟角色能够模仿参考动作中的行为,同时实现指定的任务目标。这些策略使用神经网络建模,并使用近端策略优化算法进行训练。
4. Background
任务将被构建为标准强化学习问题,其中agent根据策略与环境交互以最大化奖励。为简洁起见,将从符号中排除目标 g g g,策略 π ( a ∣ s ) \pi(a|s) π(a∣s) 模拟给定状态 s ∈ S s\in S s∈S 时动作 a ∈ A a\in A a∈A 的条件分布,在每个控制时间步,agent观察当前状态 s t s_{t} st 并从 π \pi π 中采样一个动作,然后环境以新状态 s ′ = s t + 1 s^{'}=s_{t+1} s′=st+1 做出响应,该状态从动态 p ( s ′ ∣ s , a ) p(s^{'}|s,a) p(s′∣s,a) 中采样,以及反映转换可取性的标量奖励 r t r_{t} rt;对于参数策略 π θ ( a ∣ s ) \pi_{\theta}(a|s) πθ(a∣s),agent的目标是学习最大化其预期回报的最佳参数 θ ∗ \theta^{*} θ∗ :
J ( θ ) = E τ ∼ p θ ( τ ) [ ∑ t = 0 T γ t r t ] J(\theta)=E_{\tau\sim p_{\theta}(\tau)}\left[\sum^{T}_{t=0}\gamma^{t}r_{t}\right] J(θ)=Eτ∼pθ(τ)[t=0∑Tγtrt]
其中 p θ ( τ ) = p ( s 0 ) ∏ t = 0 T − 1 p ( s t + 1 ∣ s t , a t ) π θ ( a t ∣ s t ) p_{\theta}(\tau)=p(s_{0})\prod^{T-1}_{t=0}p(s_{t+1}|s_{t},a_{t})\pi_{\theta}(a_{t}|s_{t}) pθ(τ)=p(s0)∏t=0T−1p(st+1∣st,at)πθ(at∣st) 是有策略 π θ \pi_{\theta} πθ 得到的在初始状态分布 p ( s 0 ) p(s_{0}) p(s0) 下的所有可能轨迹 τ = ( s 0 , a 0 , s 1 , … , a T − 1 , s T ) \tau=(s_{0},a_{0},s_{1},\dots,a_{T-1},s_{T}) τ=(s0,a0,s1,…,aT−1,sT) 的分布; ∑ t = 0 T − 1 γ t r t \sum^{T-1}_{t=0}\gamma^{t}r_{t} ∑t=0T−1γtrt 表示返回在时间步长 T T T 下的的一条完整轨迹, T T T 可以是有限或无限的; γ ∈ [ 0 , 1 ] \gamma\in[0,1] γ∈[0,1] 表示当返回值是无限情况下的衰减系数;优化参数策略的一类流行算法是策略梯度方法,其中预期回报 ∇ θ J ( θ ) \nabla_{\theta}J(\theta) ∇θJ(θ) 的梯度是通过策略采样的轨迹来估计的。策略梯度可以根据以下公式估计:
∇ θ J ( θ ) = E s t ∼ d θ ( s t ) , a t ∼ π θ ( a t ∣ s t ) [ ∇ θ log ( π θ ( a t ∣ s t ) ) A t ] \nabla_{\theta}J(\theta)=E_{s_{t}\sim d_{\theta}(s_{t}),a_{t}\sim\pi_{\theta}(a_{t}|s_{t})}[\nabla_{\theta}\log{(\pi_{\theta}(a_{t}|s_{t}))A_{t}}] ∇θJ(θ)=Est∼dθ(st),at∼πθ(at∣st)[∇θlog(πθ(at∣st))At]
其中 d θ ( s t ) d_{\theta}(s_{t}) dθ(st)是策略 π θ \pi_{\theta} πθ下的状态分布; A t A_{t} At 是在特定状态 s t s_{t} st 下采取动作 a t a_{t} at 的优势:
A t = R t − V ( s t ) A_{t}=R_{t}-V(s_{t}) At=Rt−V(st)
R t = ∑ l = 0 T − t γ l r t + l R_{t}=\sum^{T-t}_{l=0}\gamma^{l}r_{t+l} Rt=∑l=0T−tγlrt+l 表示从时间 t t t 的状态 s t s_{t} st 开始的特定轨迹所获得的回报; V ( s t ) V(s_{t}) V(st) 是一个价值函数,用于估计从 s t s_{t} st 开始并遵循该策略执行所有后续步骤的平均回报:
V ( s t ) = E [ R t ∣ π θ , s t ] V(s_{t})=E[R_{t}|\pi_{\theta},s_{t}] V(st)=E[Rt∣πθ,st]
因此,策略梯度可以理解为增加使其高于预期收益的行动的可能性,同时降低导致低于预期收益的行动的可能性。一个经典的策略梯度学习算法是 REINFORCE,使用经验梯度估计器对
J
(
θ
)
J(\theta)
J(θ) 进行梯度上升来学习策略。
作者的策略将使用近端策略优化算法进行训练,该算法已在众多具有挑战性的控制问题上取得了最佳成果。价值函数将使用 T D ( λ ) TD(\lambda) TD(λ) 的多步回报进行训练。策略梯度的优势将使用广义优势估计器 G A E ( λ ) GAE(\lambda) GAE(λ) 计算。对这些方法的更深入综述,请参阅补充材料。
5. Policy Representation
给定一个参考运动片段用一系列目标姿态 { q ^ t } \{\hat{q}_{t}\} {q^t} 表示,该策略的目标是在物理模拟环境中重现所需运动,同时满足其他任务目标。由于参考运动仅以目标姿态的形式提供运动学信息,因此该策略负责确定在每个时间步应应用哪些动作以实现所需轨迹。
5.1 States and Actions
状态 s s s 描述角色身体的配置,其特征包括每个链接相对于根(指定为骨盆)的相对位置、以四元数表示的旋转以及它们的线速度和角速度。所有特征均在角色的局部坐标系中计算,root原点, x x x 轴沿root link的朝向。由于参考运动的目标姿态随时间变化,因此状态特征中还包含一个相位变量 ϕ ∈ [ 0 , 1 ] \phi\in[0,1] ϕ∈[0,1], ϕ = 0 \phi= 0 ϕ=0 表示运动开始, ϕ = 1 \phi= 1 ϕ=1 表示运动结束。对于周期性运动,在每个周期结束后重置为 0。为实现其他任务目标(例如朝特定方向行走或击中目标)而训练的策略也包含目标 g g g ,其处理方式与状态类似。实验中使用的具体目标将在第9节中讨论。策略中的动作 a a a 指定了每个关节处PD控制器的目标方向。该策略以30Hz的频率进行查询,球形关节的目标方向以轴角形式表示,而旋转关节的目标方向则以标量旋转角度表示。与通常直接作用于扭矩的标准基准测试不同,使用的PD控制器抽象出了局部阻尼和局部反馈等低级控制细节,与扭矩相比PD控制器已被证明能够提高某些运动控制任务的性能和学习速度。
5.2 Network
每项策略 π \pi π 都由一个神经网络表示,该网络将给定的状态 s s s 和目标 映射到动作 π ( a ∣ s , g ) \pi(a|s,g) π(a∣s,g)上的分布。动作分布被建模为高斯分布,其状态相关均值 μ ( s ) \mu(s) μ(s) 由网络指定,并且固定对角协方差矩阵 被视为算法的超参数:
π ( a ∣ s ) = N ( μ ( s ) , Σ ) \pi(a|s)=N(\mu(s),\Sigma) π(a∣s)=N(μ(s),Σ)
输入由两个全连接层处理,每个层分别包含 1024 个单元和 512 个单元,之后是线性输出层。所有隐藏单元均使用 ReLU 激活函数。值函数由类似的网络建模,但输出层由单个线性单元组成。
对于第 9 节中讨论的基于视觉的任务,输入会用周围地形的高度图
H
H
H 进行增强,该高度图是在角色周围的均匀网格上采样的。策略网络和价值网络也会相应地用卷积层进行增强,以处理高度图。Fig.2 显示了该视觉运动策略网络的示意图。高度图首先经过一系列卷积层处理,然后经过全连接层处理。然后将得到的特征与输入状态
s
s
s 和目标 连接起来,并由与用于不需要视觉的任务的全连接网络类似的全连接网络进行处理。
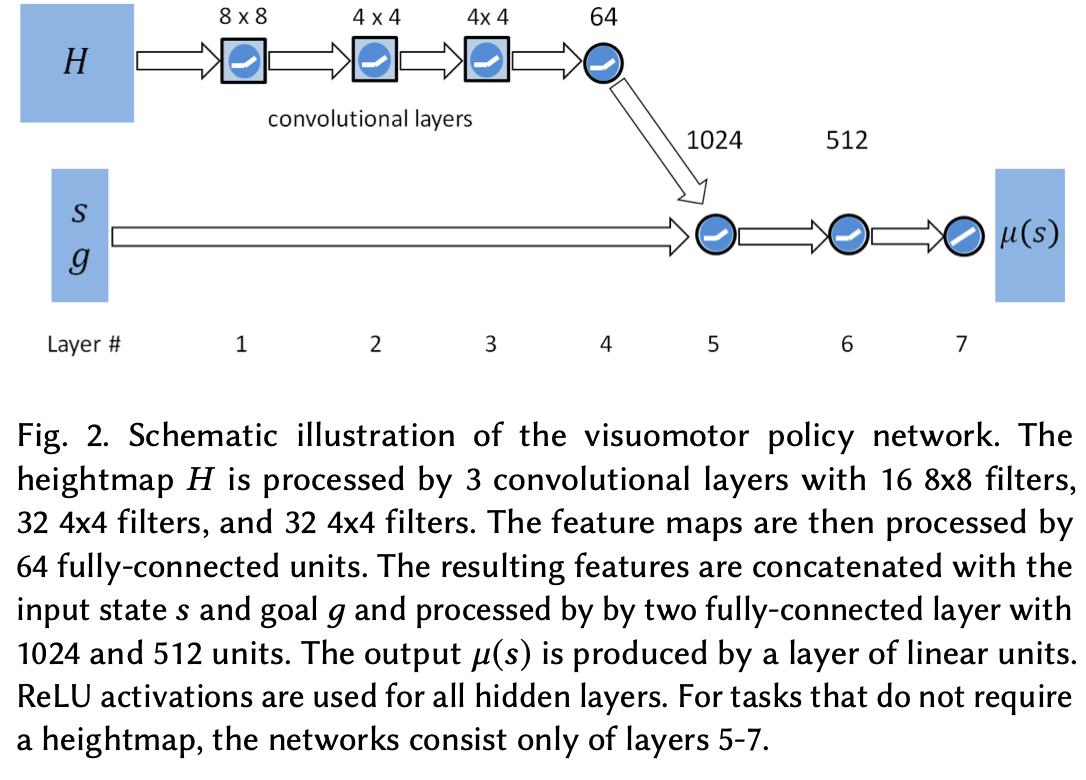
5.3 Reward
每一步 t t t 的奖励 r t r_{t} rt 由两个项组成,鼓励角色匹配参考动作,同时满足额外的任务目标:
r t = ω I r t I + ω G r t G r_{t}=\omega^{I}r^{I}_{t}+\omega^{G}r^{G}_{t} rt=ωIrtI+ωGrtG
其中, r t I r^{I}_{t} rtI 和 r t G r^{G}_{t} rtG 分别代表模仿目标和任务目标, ω I \omega^{I} ωI 和 ω G \omega^{G} ωG 分别为它们的权重。任务目标 r t G r^{G}_{t} rtG 激励角色完成特定任务的目标,其细节将在下一节讨论。模仿目标 r t I r^{I}_{t} rtI 鼓励角色遵循给定的参考运动 { q ^ t } \{\hat{q}_{t}\} {q^t}。它进一步分解为奖励角色匹配参考运动的某些特征(例如关节方向和速度)的项,如下所示:
r t I = w p r t p + w v r t v + w e r t e + w c r t c w p = 0.65 , w v = 0.1 , w e = 0.15 , w c = 0.1 \begin{align} r^{I}_{t} &= w^{p}r^{p}_{t}+w^{v}r^{v}_{t}+w^{e}r^{e}_{t}+w^{c}r^{c}_{t}\\ w^{p} &=0.65,\quad w^{v}=0.1,\quad w^{e}=0.15,\quad w^{c}=0.1 \end{align} rtIwp=wprtp+wvrtv+werte+wcrtc=0.65,wv=0.1,we=0.15,wc=0.1
姿态奖励 r t p r^{p}_{t} rtp 鼓励每一步参考运动的关节朝向的匹配程度,其计算方式为模拟角色的关节方向四元数与参考运动的关节方向四元数之差。下式中, q t j q^{j}_{t} qtj 和 q ^ t j \hat{q}^{j}_{t} q^tj 分别表示模拟角色和参考运动的第 j j j 个关节方向, q 1 ⊖ q 2 q_{1}\ominus q{2} q1⊖q2 表示四元数之差, ∥ q ∥ \|q\| ∥q∥ 计算四元数绕其轴的标量旋转(以弧度为单位):
r t p = e x p [ − 2 ( ∑ j ∥ q ^ t j ⊖ q t j ∥ 2 ) ] r^{p}_{t}=exp\left[-2\left(\sum_{j}\|\hat{q}^{j}_{t}\ominus q^{j}_{t}\|^{2}\right)\right] rtp=exp[−2(j∑∥q^tj⊖qtj∥2)]
其中速度奖励 r t v r^{v}_{t} rtv 由不同关节速度计算得到; q ˙ t j \dot{q}^{j}_{t} q˙tj 是第 j j j个关节的角速度;关节目标速度 q ˙ ^ t j \hat{\dot{q}}^{j}_{t} q˙^tj 由有限差分得到:
r t v = e x p [ − 0.1 ( ∑ j ∥ q ˙ ^ t j − q ˙ t j ∥ 2 ) ] r^{v}_{t}=exp\left[-0.1\left(\sum_{j}\|\hat{\dot{q}}^{j}_{t}-\dot{q}^{j}_{t}\|^{2}\right)\right] rtv=exp[−0.1(j∑∥q˙^tj−q˙tj∥2)]
最终奖励 r t e r^{e}_{t} rte 将鼓励手脚位置与参考动作之间的匹配。因此, p t e p^{e}_{t} pte 表示三维世界中末端执行器(单位为m)的位置 e ∈ [ left foot,right foot,left hand,right hand ] e\in[\text{left foot,right foot,left hand,right hand}] e∈[left foot,right foot,left hand,right hand]:
r t e = e x p [ − 40 ( ∑ e ∥ p ^ t e − p t e ∥ 2 ) ] r^{e}_{t}=exp\left[-40\left(\sum_{e}\|\hat{p}^{e}_{t}-p^{e}_{t}\|^{2}\right)\right] rte=exp[−40(e∑∥p^te−pte∥2)]
r t c r^{c}_{t} rtc 用于惩罚本体的重心 p t c p^{c}_{t} ptc 与参考动作重心 p ^ t c \hat{p}^{c}_{t} p^tc 的偏差:
r t c = e x p [ − 10 ( ∥ p ^ t c − p t c ∥ 2 ) ] r^{c}_{t}=exp\left[-10\left(\|\hat{p}^{c}_{t}-p^{c}_{t}\|^{2}\right)\right] rtc=exp[−10(∥p^tc−ptc∥2)]
6. Training
策略使用 PPO 和裁剪替代目标函数进行训练,维护两个网络:一个用于策略
π
θ
(
a
∣
s
,
g
)
\pi_{\theta}(a|s,g)
πθ(a∣s,g),另一个用于价值函数
V
Ψ
(
s
,
g
)
V_{\Psi}(s,g)
VΨ(s,g) 参数分别为
θ
\theta
θ 和
Ψ
\Psi
Ψ。训练以回合制进行,在每个回合开始时从参考动作中均匀采样初始状态
s
0
s_{0}
s0,并通过在每一步从策略中采样动作来生成 rollout。每个回合都会模拟一个固定的时间范围,或者直到触发终止条件。收集到一批数据后,从数据集中抽取小批量数据用于更新策略和价值函数。价值函数使用通过
T
D
(
λ
)
TD(\lambda)
TD(λ) 计算的目标值进行更新。策略使用通过替代目标计算的梯度进行更新,其中优势函数
A
t
A_{t}
At 的计算采用
G
A
E
(
λ
)
GAE(\lambda)
GAE(λ)。
RL 中一个持续存在的挑战是 exploration。由于大多数公式都假设一个未知的 MDP,因此agent需要利用其与环境的交互来推断 MDP 的结构,并发现其应该努力达到的高价值状态。现已有多种算法对其进行了改进,例如使用新颖性或信息增益指标。然而在训练过程中,对情节的结构及其作为指导探索机制的潜力关注较少。下面的章节中考虑两个决策:初始状态分布和终止条件,这两通常被视为给定强化学习问题的固定属性。作者证明:适当的选择对于具有挑战性的技能(例如高动态踢腿、旋转和滑步)对本文提出的方法学习而言至关重要。对于常见的选择,例如固定的初始状态和固定长度的情节,作者发现模仿这些困难的动作通常是不成功的。
6.1 Initial State Distribution
初始状态分布 p ( s 0 ) p(s_{0}) p(s0) 决定了agent在每轮游戏中开始的状态,对于 p ( s 0 ) p(s_{0}) p(s0) 而言一种常见的选择是始终将agent置于 fixed 状态。然而考虑到模仿期望动作的任务,一种简单的策略是将角色初始化为动作的起始状态,并允许其在一轮游戏中逐渐接近动作的结束状态。这种设计下策略必须以顺序的方式学习动作,首先学习动作的早期阶段,然后逐步学习后期阶段。在掌握早期阶段之前,后期阶段的进展很小。这对于诸如后空翻之类的动作来说可能会有问题,因为学习落地是角色从跳跃中获得高回报的先决条件。如果策略无法成功落地,跳跃实际上会导致更差的回报。固定初始状态的另一个缺点是随之而来的探索挑战,该策略仅在访问过某个状态后才会获得奖励。因此,在访问到高奖励状态之前,该策略无法得知该状态是否是有利的。这两个缺点都可以通过修改初始状态分布来缓解。
对于许多强化学习任务而言,固定的初始状态可能更为便捷,因为在其他状态下初始化agent(例如,物理机器人)或获取更丰富的初始状态分布可能具有挑战性。然而对于运动模仿任务,参考运动提供了丰富且信息丰富的状态分布,可以利用该分布在训练期间指导代理。在每个回合开始时,可以从参考运动中采样一个状态,并用于初始化代理的状态。作者将此策略称为参考状态初始化 (RSI),类似的策略此前已用于平面双足行走和操控。通过从参考运动中采样初始状态,agent甚至可以在策略获得达到这些状态所需的熟练程度之前就遇到运动过程中所需的状态。例如,学习仰跳投的挑战。在初始状态固定的情况下,为了让角色发现在空中完成一个完整旋转会带来高回报,必须首先学会进行精心协调的跳跃。但是要激励角色进行这样的跳跃,模型必须意识到跳跃会带来更高奖励的状态。由于动作对起跳时的初始条件高度敏感,许多策略都会导致失败。因此agent不太可能遇到成功跳跃的状态,也永远不会发现如此高奖励的状态。有了 RSI 后agent可以在训练的早期阶段立即遇到这些有希望的状态。RSI 不是仅通过奖励函数从参考动作获取信息,而是可以被解读为一个额外的渠道,agent 由此可以以更具信息量的初始状态分布的形式从参考动作获取信息。
6.2 Early Termination
对于 cyclic skills,该任务可以建模为无限 MDP。但在训练期间每个回合都会模拟一个无限期的回合,并在一段固定时间后终止,或者在触发某些终止条件时终止;运动提前终止的一个常见条件是检测到跌倒,其特征是角色的躯干接触地面或某些 links 低于高度阈值。在本研究中,作者将使用类似的终止条件,即只要某些 links(例如躯干或头部)接触地面,回合就会终止。一旦触发提前终止,角色在剩余回合中将获得零奖励。提前终止提供了另一种塑造奖励函数以阻止不良行为的方法;提前终止的另一个优点是,可以充当一种管理机制,使数据分布偏向于与任务更相关的样本。对于行走和滑行等技能,一旦角色跌倒就很难恢复并回到其正常轨迹,如果没有提前终止,在训练早期阶段收集的数据将主要由角色在地面上徒劳挣扎的样本组成,并且网络的大部分容量将用于建模这种徒劳的状态。这种现象类似于其他方法(如监督学习)遇到的类别不平衡问题。通过在遇到此类失败状态时终止情节,可以缓解这种不平衡。
7. Multi-Skill Integration
组合和排序多个片段的能力对于执行更复杂的任务至关重要。在本节中,作者提出了几种实现方法,每种方法都适用于不同的应用:
- 不局限于单个参考片段来定义所需的动作风格,而是选择使用更丰富、更灵活的多片段奖励;
- 通过训练一个接受用户指定的one-hot片段选择输入的技能选择器策略,进一步让用户控制要触发的行为;
- 避免为每种片段组合训练新策略,而是通过从现有的单片段策略构建复合策略。在这种设置中,多个策略被独立学习,并在运行时值函数用于确定应该激活哪个策略。
Multi-Clip Reward
为了在训练期间利用多个参考运动片段,作者定义了一个复合模仿目标,该目标简单地计算为应用于 k k k 个运动片段中的每一个的先前引入的模仿目标的最大值:
r t I = max j = 1 , … , k r t j r^{I}_{t}=\max_{j=1,\dots,k}r^{j}_{t} rtI=j=1,…,kmaxrtj
其中 r t j r^{j}_{t} rtj 是关于第 j j j 个clips 的模仿目标。作者证明了简单的复合目标足以将多个clips集成到学习过程中。与 Peng 等人的方案不同,需要手动设计运动规划器来为每个行走步骤选择一个剪辑,作者的目标为策略提供了灵活性,可以根据特定情况选择最合适的剪辑,并能够在适当的时候在剪辑之间切换,而无需设计运动规划器。
Skill Selector
除了简单地为策略提供多个片段以供其根据需要使用以完成目标之外,还可以让用户控制在任何给定时间使用哪个片段。通过这种方法训练一个策略,使其同时学习模仿一组不同的技能,并且一旦训练完成,就能够根据需要执行任意的技能序列。该策略的目标 g t g_{t} gt 由一个one-hot向量表示,其中每个条目 g t , i g_{t,i} gt,i 对应于应执行的动作。角色的目标是执行与 g t g_{t} gt 的非零条目对应的动作。没有额外的任务目标 r t G r^{G}_{t} rtG,角色的训练仅针对优化模仿目标 r t I r^{I}_{t} rtI ,该目标基于当前选定的动作 r t I = r t i r^{I}_{t}=r^{i}_{t} rtI=rti 计算,其中 g t , i = 1 g_{t,i}=1 gt,i=1 且 g t , j = 0 g_{t,j}=0 gt,j=0 且 j ≠ i j\neq i j=i。在训练期间,在每个周期开始时都会采样一个随机 g t g_{t} gt 。因此,该策略需要学习在片段集合中的所有技能之间进行转换。
Composite Policy
前面描述的方法都针对一组剪辑学习单一策略。但是,随着技能数量的增加,要求网络联合学习多种技能可能会变得具有挑战性,并且可能导致策略无法充分学习任何一种技能。另一种方法是采用分而治之的策略,即训练单独的策略来执行不同的技能,然后将它们集成到一个复合策略中。由于价值函数提供了策略在特定状态下预期性能的估计,因此可以利用价值函数来确定在给定状态下执行的最合适的技能。给定一组策略及其价值函数 { V i ( s ) , π i ( a ∣ s ) } i = 1 k \{V^{i}(s),\pi^{i}(a|s)\}^{k}_{i=1} {Vi(s),πi(a∣s)}i=1k,可以使用玻尔兹曼分布构建复合策略 Π ( a ∣ s ) \Pi(a|s) Π(a∣s):
Π ( a ∣ s ) = ∑ i = 1 k p i ( s ) π i ( a ∣ s ) , p s i = e x p [ V i ( s ) / Γ ] ∑ j = 1 k e x p [ V j ( s ) / Γ ] \Pi(a|s)=\sum^{k}_{i=1}p^{i}(s)\pi^{i}(a|s),\quad p^{i}_{s}=\frac{exp[V^{i}(s)/\Gamma]}{\sum^{k}_{j=1}exp[V^{j}(s)/\Gamma]} Π(a∣s)=i=1∑kpi(s)πi(a∣s),psi=∑j=1kexp[Vj(s)/Γ]exp[Vi(s)/Γ]
其中 Γ \Gamma Γ 是温度参数,在给定状态下具有较大预期值的策略更有可能被选中。通过反复从复合策略中采样,角色能够从多样化动作库中执行一系列技能,而无需任何额外训练。复合策略类似于提出的混合演员-评论家专家模型 (MACE),但更简便,因为每个子策略都针对特定技能进行独立训练。
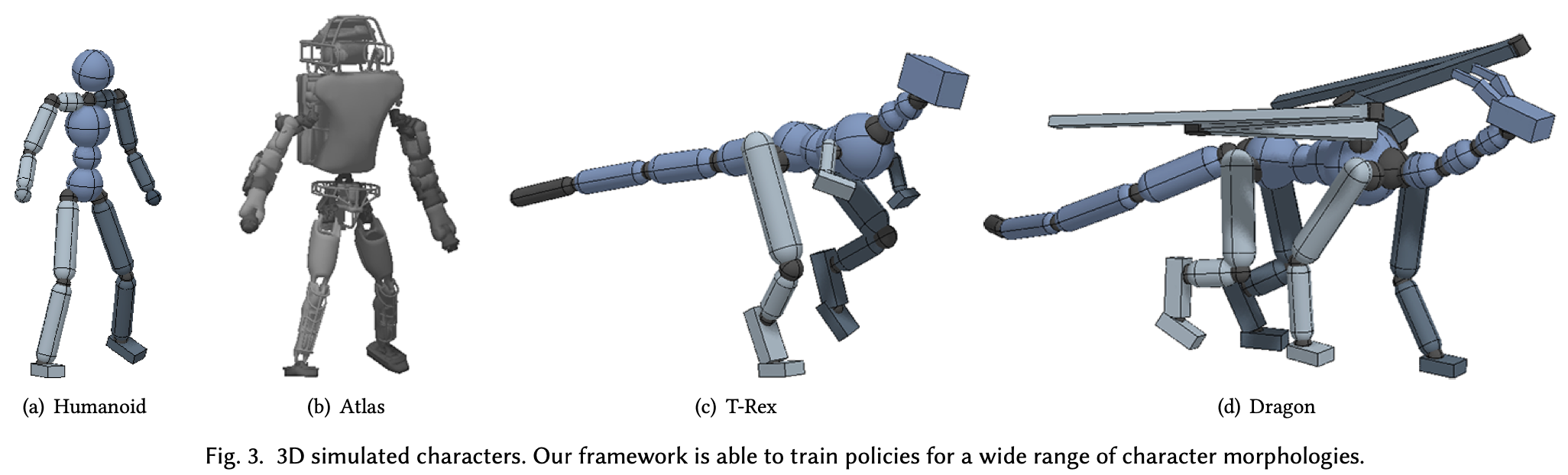
8. Characters
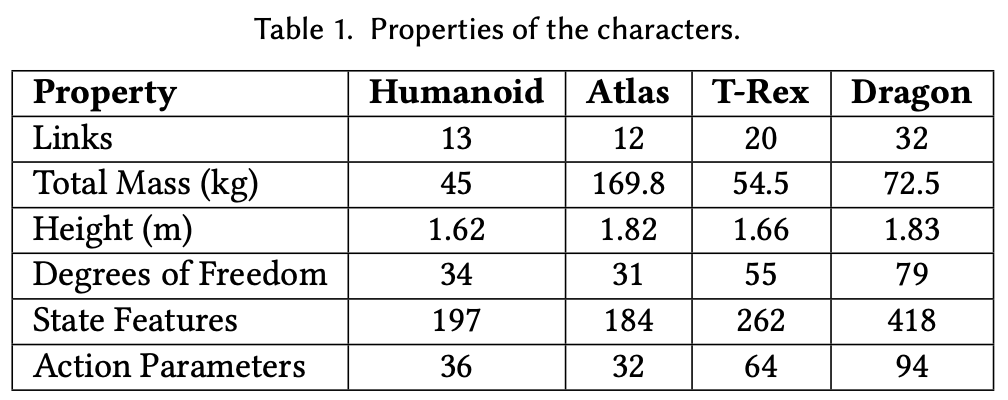
角色包括一个 3D 人形机器人、一个 Atlas 机器人模型、一只霸王龙、一条飞龙。Fig.3 给出了角色的插图,Table.1 详细列出了每个角色的属性。所有角色均建模为links刚体,每个links通过 3 自由度球形关节连接到其父连杆,只有膝盖和肘部通过 1 自由度旋转关节连接。PD 控制器位于每个关节处,并具有手动指定的增益,这些增益在所有任务中保持不变。人形机器人和 Atlas 都具有相似的身体结构,但它们的形态(例如质量分布)和执行器(例如 PD 增益和扭矩限制)明显不同,Atlas 的质量几乎是人形机器人的四倍。霸王龙和龙提供了在没有动作捕捉数据的情况下,角色如何从关键帧动画中学习行为的示例,并表明本文的方法可以轻松应用于非双足角色。人形角色具有 197 维的状态空间和 36 维的动作空间。最复杂的角色龙,具有 418 维的状态空间和 94 维的动作空间。与强化学习的标准连续控制基准(其动作空间通常在 3 维到 17 维之间)相比,角色具有明显更高维度的动作空间。
9. Tasks
除了模仿一组动作片段外,这些策略还可以训练执行各种任务,同时保留参考动作所规定的风格。特定于任务的行为被编码到任务目标 r t G r^{G}_{t} rtG中。
Target Heading
可操控控制器可以通过引入一个目标函数来训练,该目标函数鼓励角色沿目标方向 d t ∗ d^{*}_{t} dt∗ 行进。表示为水平面上的二维单位向量。该任务的奖励为:
r t G = e x p [ − 2.5 m a x ( 0 , v ∗ − v t T d t ∗ ) 2 ] r^{G}_{t}=exp\left[-2.5max(0,v^{*}-v^{T}_{t}d^{*}_{t})^{2}\right] rtG=exp[−2.5max(0,v∗−vtTdt∗)2]
其中 v ∗ v^{*} v∗ 指定沿目标方向 d t ∗ d^{*}_{t} dt∗ 的期望速度, v t v_{t} vt 表示模拟角色的质心速度。因此,目标函数会惩罚沿目标方向行进速度低于期望速度的角色,但不会惩罚超过期望速度的角色。目标方向作为策略的输入目标 g t = d t ∗ g_{t}=d^{*}_{t} gt=dt∗ 提供。在训练期间,目标方向会在整个回合中随机变化,运行时可以手动指定 d t ∗ d^{*}_{t} dt∗ 来控制角色的方向。
Stike
在这个任务中,角色的目标是使用特定的link(例如脚)击打随机放置的球形目标,奖励函数如下:
r t G = { 1 , target had been hit e x p [ − 4 ∥ p t t a r − p t e ∥ 2 ] , otherwise r^{G}_{t}= \begin{cases} 1, & \text{target had been hit} \\ exp[-4\|p^{tar}_{t}-p^{e}_{t}\|^{2}], & \text{otherwise} \end{cases} rtG={1,exp[−4∥pttar−pte∥2],target had been hitotherwise
其中 p t t a r p^{tar}_{t} pttar 表示目标位置, p t e p^{e}_{t} pte 表示link需要打击的位置。目标是:如果link的中心距离目标位置 0.2 米以内,则标记为已击中目标。函数 g t = ( p t t a r , h ) g_{t}=(p^{tar}_{t},h) gt=(pttar,h)由目标位置 p t t a r p^{tar}_{t} pttar和一个二进制变量 h h h组成,用于指示目标是否在前一时间步被击中。由于对所有策略都使用前馈网络,因此 h h h 充当目标状态的记忆。目标随机放置在距离角色 [0.6, 0.8] 米的范围内,高度在 [0.8, 1.25] 米之间随机采样,角色到目标的初始方向变化 2 rad。目标位置和 h h h 在每个周期开始时重置。记忆状态 h h h 可以通过训练循环策略来移除,但作者的方法避免了训练循环网络的复杂性,同时仍然获得良好的性能。
Throw
此任务是击球任务的一个变体,角色不是用其link击中目标而是将球扔向目标。在回合开始时,球通过球形关节连接到角色的手上。该关节在回合期间的固定时间点释放。目标 g t g_{t} gt 和奖励 r t G r^{G}_{t} rtG 与击球任务相同,但角色状态 s t s_{t} st 会随着球的位置、旋转、线速度和角速度而增强。目标距离在 [2.5, 3.5]m 之间变化,高度在 [1, 1.25]m 之间变化,方向 direction 在 [0.7, 0.9] rad 之间变化。
Terrain Traversal
在此任务中,角色被训练穿越充满障碍的环境。目标 g t g_{t} gt 和任务目标 r G t r^{G}_{}t rGt 与目标航向任务中的类似,只是目标航向是沿着前进方向固定的。
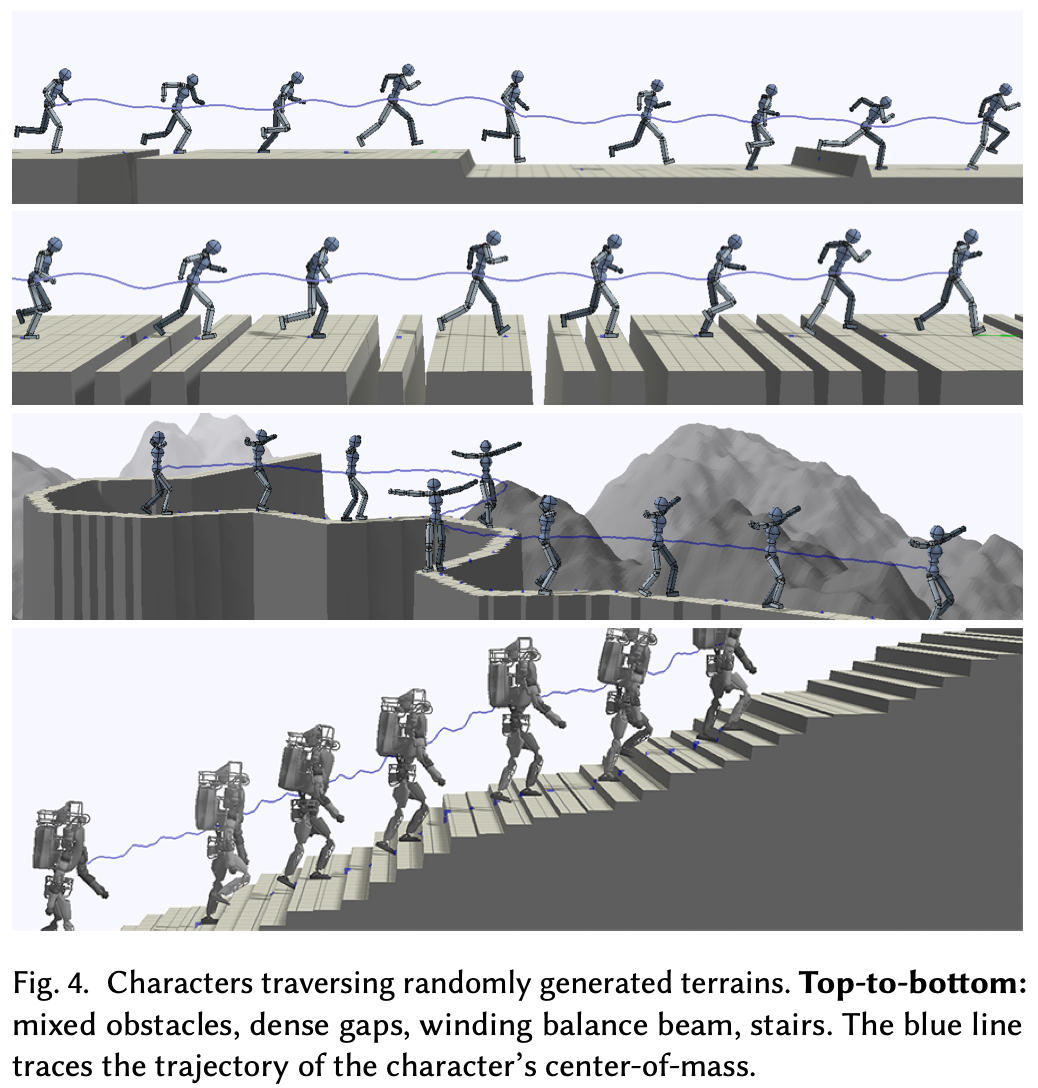
考虑四种环境:混合障碍物、密集空隙、蜿蜒的平衡木、楼梯,Fig.4 展示了这些环境的示例。混合障碍物环境由类似于中提出的空隙、台阶和墙壁障碍物组成。每个空隙的宽度在 [0.2, 1] 米之间,每面墙壁的高度在 [0.25, 0.4] 米之间,每个台阶的高度在 [0.35, -0.35] 米之间。障碍物与长度在 [5, 8] 米之间的平坦地形交错排列。下一个环境由一系列密集空隙组成,其中每个序列包含 1 到 4 个空隙。空隙的宽度为 [0.1, 0.3] 米,相邻空隙之间的间隔为 [0.2, 0.4] 米。空隙序列之间由 [1, 2] 米的平坦地形隔开。蜿蜒的平衡木环境展现了一条蜿蜒狭窄的路径,这些路径刻画在不规则的地形上。路径宽度约为 0.4 米。最后构建了一个楼梯环境,角色需要攀爬高度在 [0.01, 0.2] 米之间、深度为 0.28 米的不规则台阶。
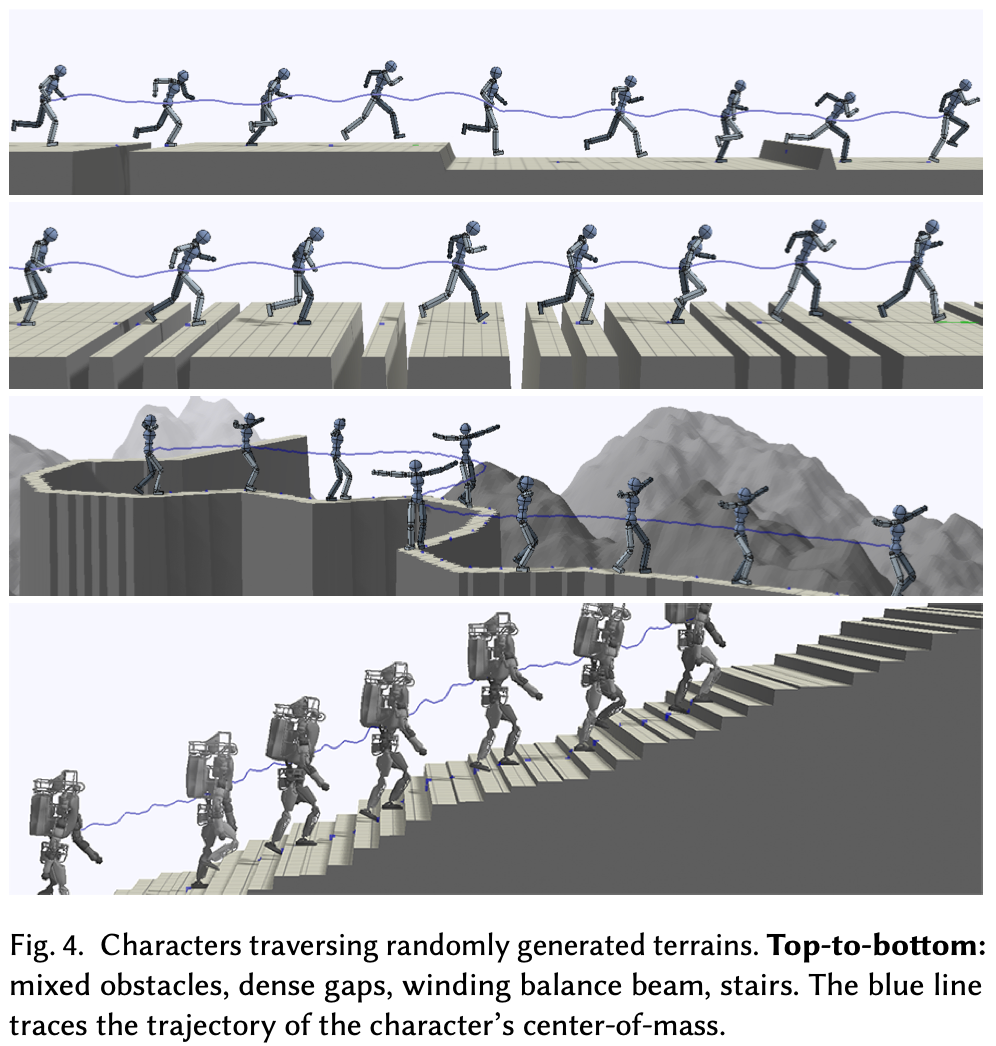
为了加快训练速度,作者采用了一种渐进式学习方法:先训练标准全连接网络(即不包含输入高度图和卷积层),使其模拟在平坦地形上的运动;然后用输入高度图和相应的卷积层对网络进行增强,然后在不规则环境中进行训练。由于混合障碍物和密集间隙环境遵循线性布局,因此高度图由一维高度场表示,其中包含 100 个样本,跨度为 10 米。在蜿蜒的平衡木环境中,使用 32 x 32 的高度图,覆盖 3.5 x 3.5 米的区域。
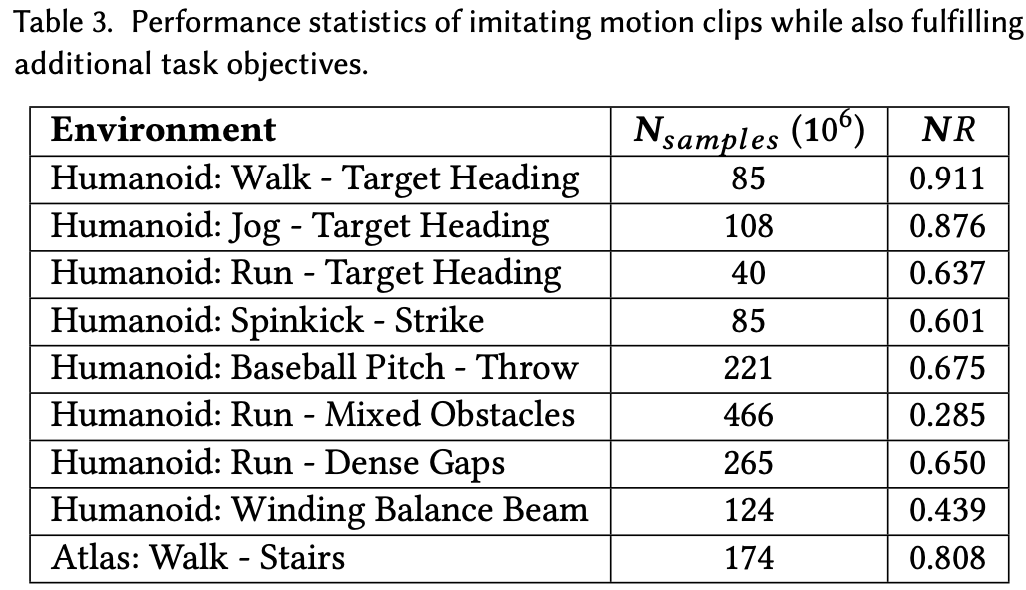
10. Results
训练策略产生的运动在补充视频中看得最清楚。Fig. 5,6,7 给出了模拟角色所执行技能的快照。策略以 30Hz 执行。使用 Bullet 物理引擎以 1.2kHz 执行物理模拟。所有神经网络均使用 TensorFlow 构建和训练。角色的运动由使用稳定 PD 控制器计算的扭矩驱动。类人机器人的结果展示了大量的运动、杂技和武术技能,而龙和霸王龙的结果则展示了运动。每项技能都是从从 http://mocap.cs.cmu.edu 和 http://mocap.cs.sfu.ca 收集的大约 0.5-5 秒的动作捕捉数据中学习而来的。对于霸王龙和龙等没有动作捕捉数据的角色,证明了作者的框架能够从关键帧中学习技能。在用于训练之前,这些剪辑需要手动处理并重新定位到各自的角色。Table.2 提供了已学技能和性能统计数据的完整列表。补充材料中提供了所有策略的学习曲线。每个环境都用“角色:技能 - 任务”表示。对于仅训练以模仿参考动作而没有其他任务目标的策略,任务未指定。性能通过平均回报来衡量,该平均回报由每集的最小和最大可能回报标准化。请注意,最大回报可能无法实现。例如,对于投掷任务,最大回报需要将球瞬间移动到目标。在评估策略的性能时,将应用提前终止,并通过 RSI 初始化每集开始时角色的状态。所有任务的模仿目标和任务目标的权重均设置为
ω
I
=
0.7
\omega^{I}=0.7
ωI=0.7 和
ω
G
=
0.3
\omega^{G}=0.3
ωG=0.3。


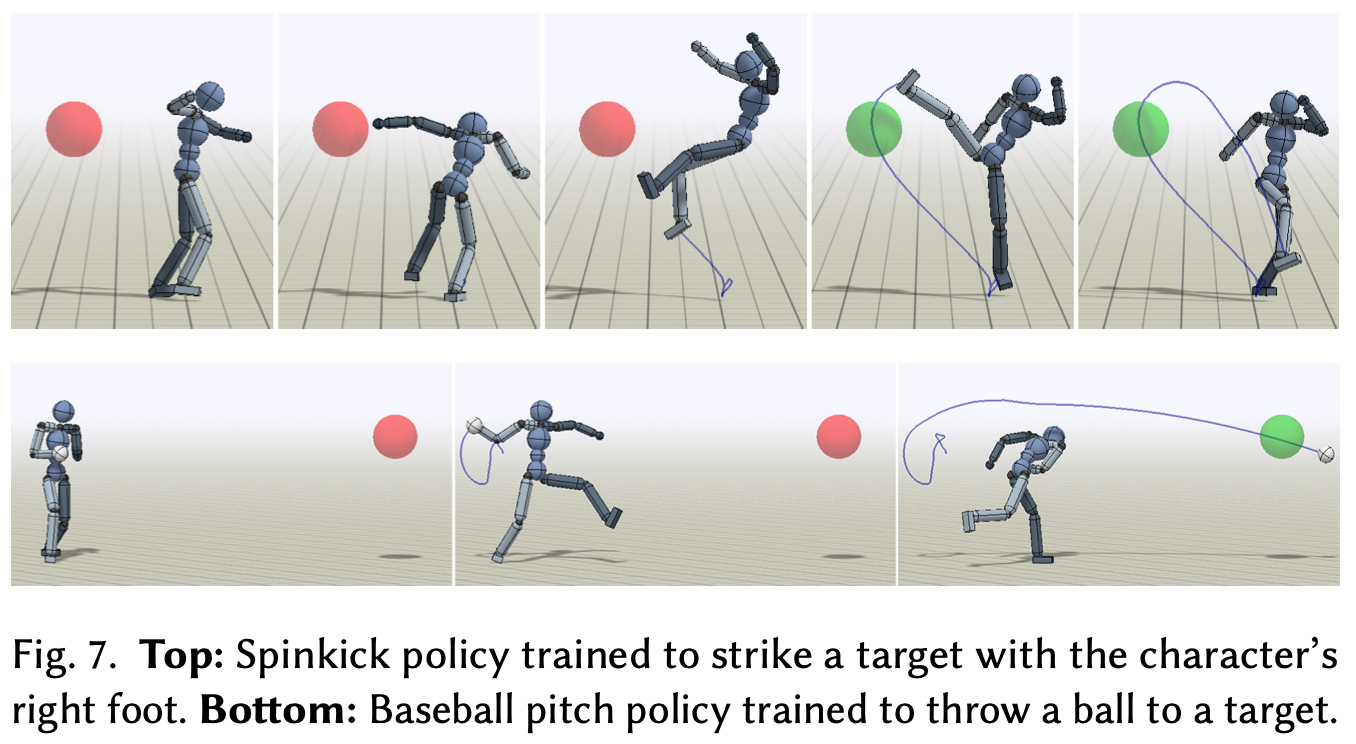
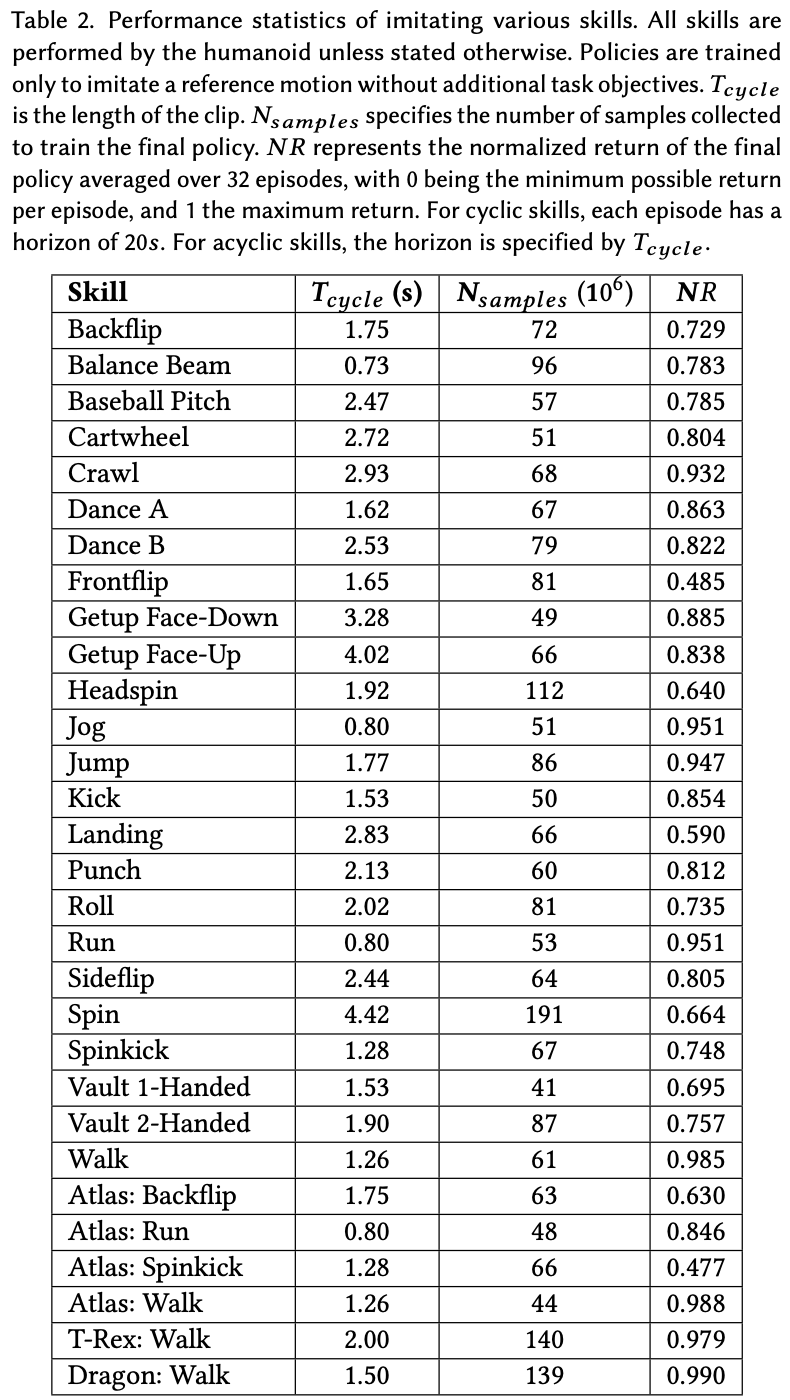
通过鼓励策略模仿人类受试者的动作捕捉数据,作者的系统能够学习丰富技能的策略。对于行走和跑步等运动技能,策略可以产生自然的步态,避免以前的深度强化学习方法中表现出的许多伪影。人形机器人能够学习各种具有长飞行阶段的杂技技能,例如后空翻和旋转踢,这些技能尤其具有挑战性,因为角色需要学习协调其在半空中的动作。该系统还能够重现接触丰富的动作,例如爬行和滚动,以及需要与环境协调交互的动作,例如Fig.6 所示的跳马技巧。学到的策略对重大外部扰动具有很强的鲁棒性,并能产生合理的恢复行为。针对霸王龙和龙所训练的策略表明,当无法使用动作捕捉时,该系统还可以从艺术家生成的关键帧中学习,并且可以扩展到比以前使用深度强化学习所展示的角色更复杂的角色。
10.1 Tasks
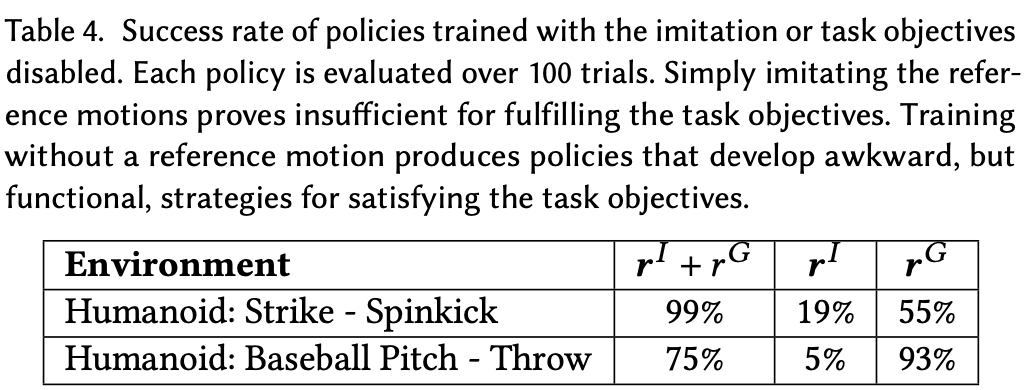
除了模仿参考动作之外,策略还可以根据需要调整动作以满足其他任务目标,例如跟随目标航向和将球投向随机放置的目标。Table.3 提供了每个任务的性能统计数据。为了研究动作对特定任务的适应程度,比较了同时优化模仿目标
r
I
r^{I}
rI 和任务目标
r
G
r^{G}
rG 的训练策略与仅使用模仿目标训练的策略的性能。Table.4 总结了不同策略的成功率。对于投掷任务,使用两个目标训练的策略能够以 75% 的成功率击中目标,而仅模仿棒球投球动作训练的策略仅在 5% 的试验中成功。同样,对于击球任务,使用两个目标训练的策略成功击中了 99% 的目标,而仅模仿参考动作训练的策略的成功率为 19%。这些结果表明,仅仅模仿参考动作不足以成功完成任务。使用任务目标训练的策略能够偏离原始参考动作,并制定额外的策略来满足各自的目标。我们进一步训练策略,使其仅优化任务目标,而不模仿参考动作。最终的策略能够实现任务目标,但由于缺乏参考动作,这些策略会发展出不自然的行为,类似于先前深度强化学习方法产生的行为。对于投掷任务,策略不是投掷球,而是采取一种笨拙但实用的策略,即带球跑向目标。Fig.8 展示了这种行为。

10.2 Multi-Skill Integration
作者的方法可以构建策略来重现各种单个动作片段。然而,许多更复杂的技能需要从一系列潜在行为中进行选择。本节将讨论几种方法,通过这些方法可以将策略扩展为将多个动作片段组合成一个复合技能。
Multi-Clip Reward
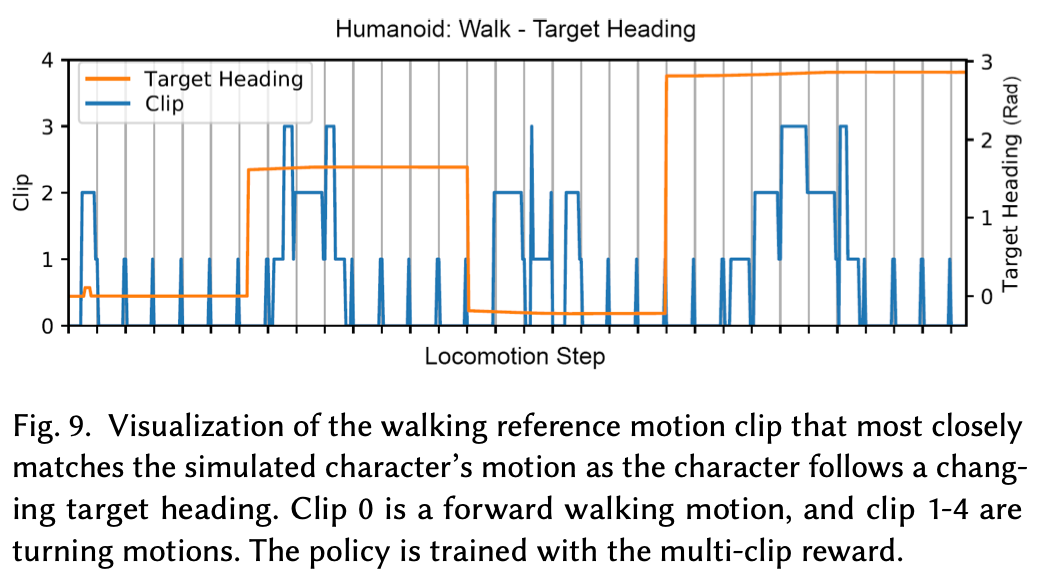
为了评估多片段奖励,作者从 5 个不同的行走和转弯片段中构建了一个模仿目标。使用此奖励训练一个类人策略,使其在遵循期望航向的同时行走。最终的策略学习利用各种灵活的步态行为来遵循目标航向。为了确定该策略是否确实学会了模仿多个片段,作者记录了在每个时间步长中与模拟角色跟随不断变化的目标航向时的运动最匹配的片段的 ID。最佳匹配片段被指定为在当前时间步长产生最大奖励的片段。Fig.9 记录了 20 秒情节中最佳匹配的片段和目标航向。片段 0 对应于向前行走运动,片段 1-4 对应于不同的转弯运动。当目标航向恒定时,角色的运动主要与向前行走匹配。当目标航向发生变化时,角色的运动与转弯运动更加匹配。当角色重新调整至目标航向后,向前行走的片段再次成为最佳匹配。这表明多片段奖励函数确实能够让角色从多个不同行走动作的片段中学习。使用多片段奖励时,我们发现这些片段通常应该来自相似的运动类型(例如不同类型的行走和转弯)。混合使用非常不同的动作(例如侧滑和前滑),可能会导致策略仅模仿片段的子集。对于更加多样化的片段,我们发现复合策略是一种更有效的集成方法。
Skill Selector
使用one-hot vector训练了一个策略来执行各种跳跃动作,并训练了另一个策略来执行不同方向的跳跃动作。flip policy 经过训练,可以执行向前、向后、左侧和右侧的跳跃动作;jump policy 经过训练,可以执行向前、向后、左侧和右侧的跳跃动作。每个片段的第一帧和最后一帧都会被复制,以确保每组片段的循环周期相同。训练完成后,这些策略能够执行各自技能库中的任意技能序列。one-hot vector还为用户提供了一个便捷的界面,方便用户实时操控角色。补充视频中提供了类人机器人执行用户指定技能序列的片段。
Composite Policy
虽然多片段目标可以有效地整合属于同一类别(例如行走)的多个片段,但作者发现它在整合更多样技能的片段时效率较低。为了整合更多样化的技能语料库,构建了一个包含后挥杆、前挥杆、侧挥杆、侧手翻、旋转踢、翻滚、面朝下起身和面朝上起身策略的复合策略。值函数的输出被规范化为 [-1, 1] 之间的值,并将温度设置为 Γ = 0.3 \Gamma=0.3 Γ=0.3。在每个循环开始时,都会从复合策略中采样一个新技能,并在选择新技能之前,先执行所选技能一个完整的循环。为了防止角色重复执行同一项技能,该策略被限制为在连续的循环中不采样同一项技能。与技能选择器策略不同,复合策略中的各个策略从未被明确训练以在不同技能之间转换。通过使用价值函数来指导技能选择,角色能够成功地在各种技能之间转换。当角色跌倒时,复合策略会激活相应的起身策略,无需任何手动脚本,如补充视频所示。
10.3 Retargeting
由于模拟环境与现实世界之间存在建模差异,动作捕捉片段的动态记录可能与模拟环境的动态记录存在显著差异。此外,关键帧运动可能在物理上完全不正确。为了评估框架对这些差异的鲁棒性,作者训练了策略,使其在不同的角色模型、环境和物理条件下执行类似的技能。
Character Retargeting
为了展示系统将动作重定向到不同角色的能力,使用来自 http://www.mujoco.org/forum/index.php?resources/atlas-v5.16/ 的 Atlas 机器人模拟模型上训练了行走、跑步、后踢、旋转踢的策略。Atlas 总质量为 169.8k,几乎是人形机器人质量的四倍,并且质量分布不同。原始 Atlas 模型中的串行一维旋转关节被聚合为三维球形关节,以便更轻松地重定向参考运动。为了重定向运动片段,将局部关节旋转从人形机器人复制到 Atlas,无需任何进一步修改。然后训练新的策略让 Atlas 模仿重定向的片段。尽管角色形态截然不同,但作者的系统仍然能够使用 Atlas 模型训练策略,成功重现各种技能。Atlas 策略的性能统计数据见Table.2。Atlas 策略所取得的性能与人形机器人相当。从质量上讲,Atlas 角色产生的运动与参考剪辑非常相似。为了进一步凸显角色动态的差异,作者评估了将为人形机器人训练的策略直接应用于 Atlas 的性能。当将人形机器人策略应用于 Atlas 时,它无法重现任何技能,跑步和后抛的标准回报率分别为 0.013 和 0.014,而专门为 Atlas 训练但使用相同参考剪辑的策略则取得了 0.846 和 0.630。
Environment Retargeting
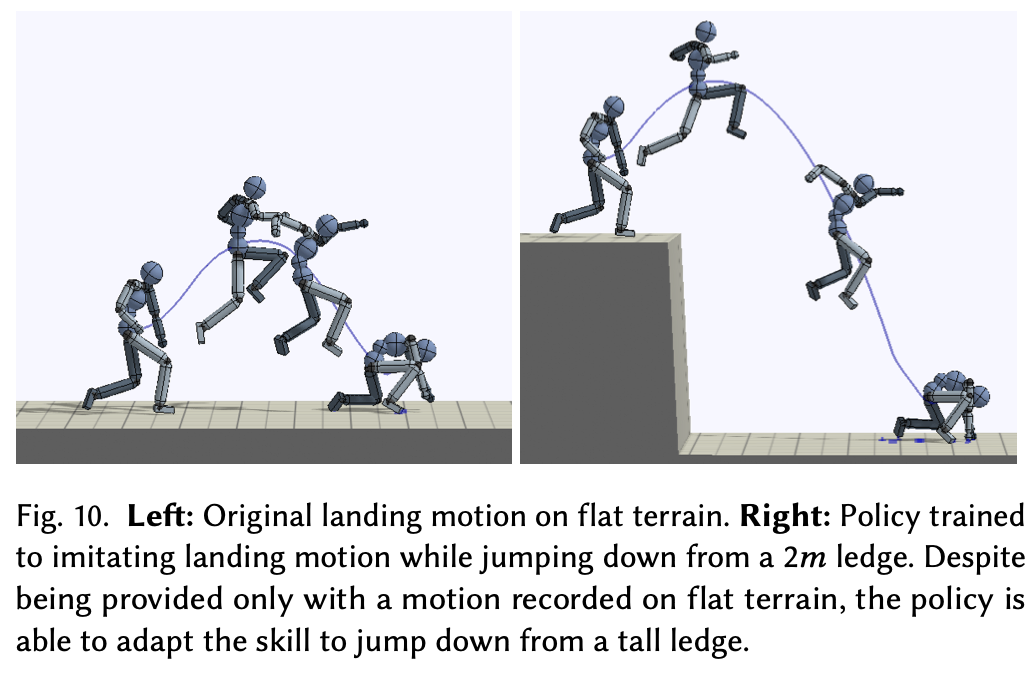
虽然大多数参考动作都是在平坦的地形上记录的,作者展示了这些策略可以通过训练使其适应不规则环境。首先,考虑重新定位落地动作的情况,其中原始参考动作是人类主体在平坦地面上跳跃落地。基于此参考动作训练了一个角色,使其能够从 2 米高的壁架上跳下并重现该动作。Fig.10 展示了最终策略下的动作。系统能够将参考动作适应与原始视频明显不同的新环境。
接下来探索在更复杂的程序生成环境中基于视觉的运动。通过为网络添加高度图输入,训练人形机器人穿越由随机障碍物组成的地形。环境示例如Fig.4所示。在训练过程中,这些策略能够将单个向前奔跑动作片段调整为多种策略,以穿越不同类型的障碍物。此外,通过训练模拟平衡木行走的策略,角色能够仅使用高度图进行寻路,从而学习沿着狭窄蜿蜒的小路行走。平衡木策略仅使用向前行走的片段进行训练,但仍然能够发展出转弯动作来跟随蜿蜒的小路。除了人形机器人之外,作者还训练了 Atlas 爬上台阶高度不规则的楼梯的策略。该策略能够调整原始的平坦地形行走片段来爬楼梯,尽管最终的动作仍然显得有些笨拙。怀疑该问题部分与步行参考运动不适合楼梯环境有关。
Physics Retargeting
为了进一步评估该框架对运动捕捉数据与模拟结果之间动态差异的鲁棒性,作者训练了在月球重力(1.622米/平方秒)下进行旋转踢和侧手翻的策略。尽管重力存在差异,但这些策略能够使动作适应新的动态,旋转踢的回报率为0.792,侧手翻的回报率为0.688。
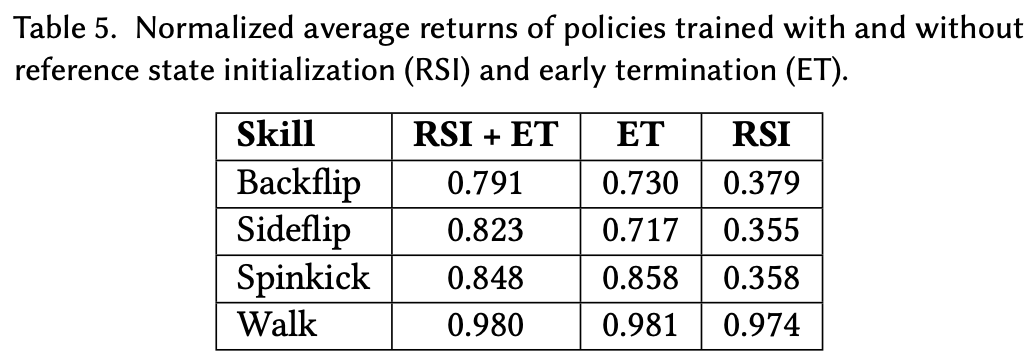
10.4 Ablations
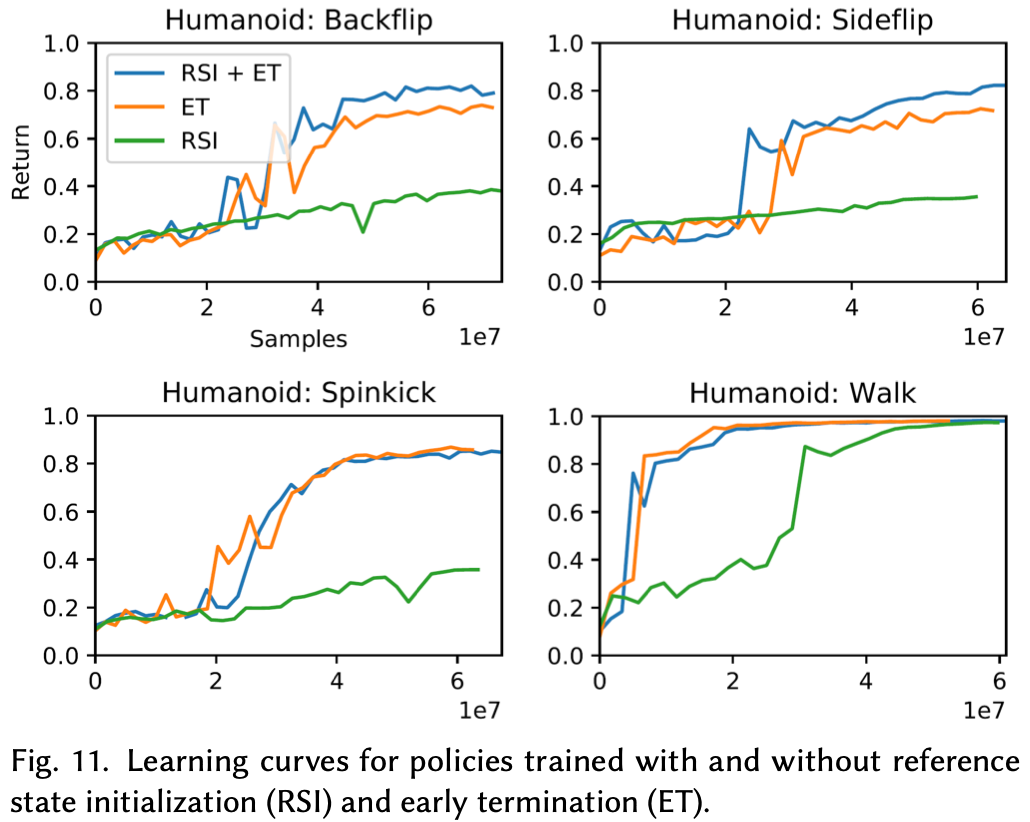
为了评估设计决策的影响,将完整方法与禁用部分组件的替代训练方案进行了比较。发现参考状态初始化和提前终止是训练过程中最重要的两个组成部分。比较包括使用参考状态初始化和固定初始状态的训练,以及使用提前终止和不使用提前终止的训练。不使用提前终止时,每个回合都会模拟完整的 20 秒。Fig.11 比较了不同配置下的学习曲线,Table.5 总结了最终策略的性能。在评估过程中提前终止被禁用,并且角色在每次回合开始时都会初始化为固定状态,大部分性能统计数据都是从一次训练过程运行中收集的。但观察到行为在多次运行中是一致的,证明提前终止对于重现许多技能至关重要。通过对角色进行与地面的不良接触进行严厉惩罚,提前终止有助于消除局部最优解,例如角色跌倒并模仿躺在地面上的动作。RSI 对于具有重要飞行阶段的动态技能(例如后空翻)也至关重要。虽然不使用 RSI 训练的策略似乎获得了与使用 RSI 训练的策略相似的回报,但对最终动作的检查表明,如果没有 RSI,角色通常无法重现预期的行为。对于后空翻,如果没有 RSI,策略永远无法学会完成完整的空中空翻。相反,它会在保持直立的情况下进行小幅度的向后跳跃。
10.5 Robustness
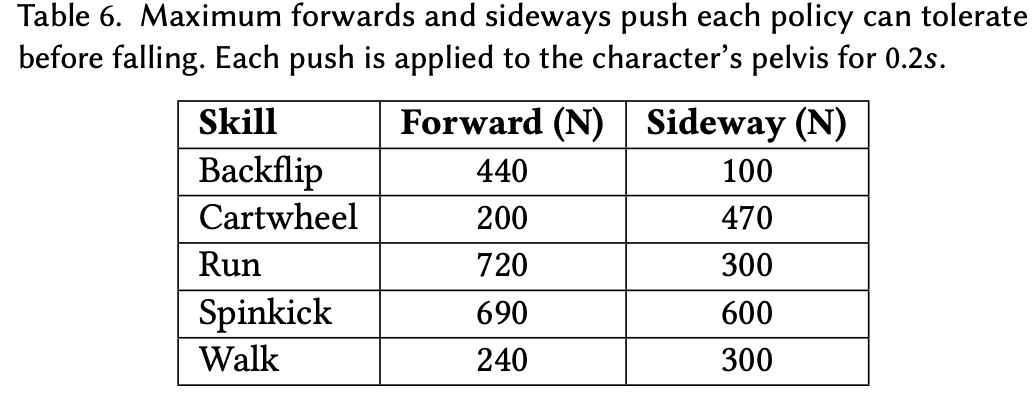
为了确定策略对外部扰动的鲁棒性,对训练好的策略施加了扰动力,并记录了角色在跌倒前可以承受的最大力。扰动力在运动周期的中途施加于角色的骨盆,持续 0.2 秒。力的大小增加 10N,直到角色跌倒。对沿向前方向(x 轴)和侧向(z 轴)施加的力重复此过程。Table.6 总结了在人形机器人上进行的实验结果。学习到的策略显示出与 SAMCON 的数据相当或更好的鲁棒性。奔跑策略能够从
720
N
×
0.2
s
720N\times0.2s
720N×0.2s 向前推中恢复,而旋转踢策略能够承受
600
N
×
0.2
s
600N\times0.2s
600N×0.2s 的两个方向的扰动,在训练过程中未施加任何外部扰动,作者怀疑这些策略的稳健性很大程度上是由于训练期间使用的随机策略所施加的探索噪声。
11. Discussion and Limitations
作者提出了一个数据驱动的深度强化学习框架,用于训练模拟角色的控制策略。展示了方法能够生成各种具有挑战性的技能。生成的策略具有高度鲁棒性,并且在没有扰动的情况下,能够生成与原始动作捕捉数据几乎难以区分的自然动作。框架能够将技能重新定位到各种角色、环境和任务,并且可以将多个策略组合成能够执行多种技能的复合策略。
尽管实验证明了该方法的灵活性,但仍有许多局限性需要在未来的工作中加以解决。首先,策略要求相位变量与参考运动同步,而参考运动随时间线性变化,限制了策略调整运动时序的能力,而解除此限制可以产生更自然、更灵活的扰动恢复。多片段集成方法在少量片段的情况下效果良好,但尚未在大型运动库中得到验证。用作角色低级伺服器的PD控制器仍然需要一定的经验力才能针对每个角色的形态进行正确的设置。学习过程本身也相当耗时,通常每个技能需要数天时间,并且每个策略都是独立执行的。虽然在所有动作中使用相同的模仿奖励,但这目前仍然基于手动定义的状态相似性指标。奖励项的权重也需要谨慎定义。
尽管如此,作者相信这项工作仍然开辟了新的探索方向。在未来的工作中,希望解决如何将这些策略部署到真机系统上,例如应用于运动、灵巧操作和其他任务。理解学习到的控制策略并将其与人类的等效策略进行比较将会非常有趣。作者希望整合各种技能,使角色能够执行更具挑战性的任务,并与环境进行更复杂的交互。融入层级结构可能有助于实现这一目标。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









