







这篇论文是一篇关于 videoLLM 的基准测试报告,作者首先开源了一个 benchmark,然后基于此对来源和商业的共计 23 个 SOTA 模型进行了测试,主要测试目的是考察模型对 真实、安全、鲁棒、隐私、公平 这几个方面的能力。从综合结果来看,由于商业模型用了更丰富的数据集,因此在大盘面上是要由于开源模型的。
写在最前面
为了方便你的阅读,以下几点的注意事项请务必了解:
- 该系列文章每个字都是我理解后自行翻译并写上去的,可能会存在笔误与理解错误,如果发现了希望读者能够在评论区指正,我会在第一时间修正错误。
- 阅读这个系列需要你有基本的 LLM、videoLLM 相关基础知识,有时候我会直接使用英文名词,因为这些词汇实在不容易找到符合语境的翻译。
- 原文可能因为版面限制存在图像表格与段落不同步的问题,为了更方便阅读,我会在博文中重新对图像表格进行排版,并做到引用图表的文字下方就能看到被引用的图表。因此可能会出现一张图片在博客中多处位置重复出现的情况。
- 对于原文中的图像,我会在必要时对图像描述进行翻译并附上我自己的理解,但如果图像描述不值得翻译我也不会强行写上去。
Basic Information
- 论文标题:Understanding and Benchmarking the Trustworthiness in Multimodal LLMs for Video Understanding
- 原文链接: https://arxiv.org/abs/2506.12336
- 发表时间:2025年06月14日
- 发表平台:arxiv
- 预印版本号:[v1] Sat, 14 Jun 2025 04:04:54 UTC (6,137 KB)
- 作者团队:Mustafa Shukor, Dana Aubakirova, Francesco Capuano, Pepijn Kooijmans, Steven Palma, Adil Zouitine, Michel Aractingi, Caroline Pascal, Martino Russi, Andres Marafioti, Simon Alibert, Matthieu Cord, Thomas Wolf, Remi Cadene
- 院校机构:
- Hefei University of Technology;
- Tsinghua University;
- 项目链接: 【暂无】
- GitHub仓库: https://github.com/wangyouze/Trust-videoLLMs
Abstract
用于视频理解的多模态大型语言模型 (videoLLM) 的最新进展提升了其处理动态多模态数据的能力。然而,由于视频数据的时空复杂性,可信度面临着 事实不准确、有害内容、偏见、幻觉 和 隐私风险 等挑战。本研究推出了 Trust-videoLLM,一个全面的基准,从五个维度评估 videoLLM:真实性、安全性、鲁棒性、公平性 和 隐私性。该框架包含 30 个任务,涵盖改编、合成和注释视频,评估动态视觉场景、跨模态交互和现实世界的安全问题。对 23 个最先进的 videoLLM(5 个商业模型,18 个开源模型)的评估 揭示了其在动态视觉场景理解和跨模态扰动恢复方面的显著局限性。开源 videoLLM 偶尔表现出真实性优势,但整体可信度不如商业模型,数据多样性优于尺度效应。这些发现凸显了需要进行高级安全协调以增强其能力。 Trust-videoLLMs 为标准化可信度评估提供了一个公开可用、可扩展的工具箱,弥合了以准确性为中心的基准与稳健性、安全性、公平性和隐私性的关键需求之间的差距。
1. Introduction
视频大型语言模型 (videoLLM) 的最新进展展现了其在各种多模态基准测试 中处理动态视觉信息的卓越能力,使其成为理解现实世界多模态数据时空复杂性的基础模型。这些发展标志着通用人工智能 (AI) 的重大进步。然而,尽管努力与人类价值观保持一致,videoLLM 仍面临着严峻的可信度挑战,包括事实不准确、时间不一致、有害内容生成、偏见、幻觉 和隐私漏洞。视频数据固有的时空复杂性加剧了这些问题,损害了 videoLLM 的可靠性,并在学术界、治理机构和民间社会引发了广泛的担忧。
与基于图像的语言模型相比,videoLLMs 处理静态视觉数据,且受外部干扰有限,而它们通过整合视觉、听觉和文本输入之间复杂的时间和空间交互,在多模态理解方面表现出色。当前的多模态大型语言模型 (MLLMs) 基准测试涵盖基于图像和视频的评估,主要评估视频理解的准确性 和长视频理解的可靠性,但往往忽略了对抗鲁棒性、安全性、公平性和隐私性等关键维度。并行工作仅评估了 videoLLMs 的安全性维度。基于图像的 LLM 基准测试专为静态视觉任务而设计,不足以应对由视频内容的动态特性引起的可信度风险,因此需要针对 videoLLMs 的时空复杂性量身定制的综合基准测试。

本研究提出了 Trust-videoLLMs,一个用于评估用于视频理解和分析的多模态语言模型 (MLLM) 可信度的综合框架,如 Fig1 所示。扩展了 TrustLLM 的五个核心维度:真实性、安全性、鲁棒性、公平性和隐私性,并引入了 针对视频数据的时空动态和多模态特性的全新任务。多级评估方法考察了动态场景下多模态风险的演变以及时间视觉输入对基础语言模型的跨模态影响,揭示了 voideLLM 中的关键漏洞。该评估系统包含 30 项任务,包括:
- 与基于图像的可信度基准不同的时空任务,用于建立动态场景标准;
- 分析影响 videoLLM 决策的多模态输入交互;
- 评估核心视频任务中的模型鲁棒性和实际应用中的安全风险。
为了支撑上面的规划,作者构建了一个大规模数据集,该数据集整合了针对任务调整的现有数据集、使用高级文本/图像转视频工具(例如 Kling1、Jimeng2)生成的合成数据,以及手动收集和注释的数据,以确保覆盖多样化的场景。
本研究评估了 23 个最先进的 videoLLM(5个商业版本,18个开源版本),这些模型因其技术代表性和架构多样性而被选中。通过严格的比较分析,作者发现这些模型在 动态场景理解和跨模态干扰恢复方面存在显著局限性。Trust-videoLLMs框架为提升视频LLM的性能提供了可解释的基础,强调了技术进步以解决这些可信度缺陷的迫切需求。研究结果可以概括如下:
- 虽然开源 videoLLM 模型在某些真实性基准上偶尔优于商业模型,但其整体可信度仍然低于主流商业模型。评估显示,
Claude4-Sonnet和Gemini1.5-Pro表现出卓越的安全性和可信度; - 闭源 videoLLM,尤其是 Claude 系列,与开源相比表现出更高的鲁棒性。在开源 videoLLM中,大型模型(例如
LLaVA-Video-72B)与小型模型(例如Long-VA-7B和Qwen2.5-VL-7B)相比,并未表现出显著的性能优势,这表明真实性更多地取决于多样化的训练数据和方法,而非参数规模; - 标准场景下性能的提升反映了模型能力的增强,但也增加了误用风险。这种权衡凸显了需要先进的安全协调策略来平衡性能提升和强大的保障措施;
为了促进标准化和可扩展的评估,作者开发了一个用于研究视频LLM可信度的工具箱。该工具箱具有统一的接口和模块化的模型交互和任务执行设计,旨在为未来可信视频LLM评估和开发的研究奠定坚实的基础。
2. Framework of Trust-videoLLMs
2.1. Detailed Description of Trust-videoLLMs
Trust-videoLLMs 框架围绕五个主要评估维度构建,每个维度都有特定的任务、数据集和指标,旨在全面评估视频 LLMs 的可信度,如 Fig.1 和 Table.1 所示。下面将介绍每个维度,并结合视频特定的考量因素。
2.1.1. Truthfulness in videoLLMs: Assessing Accuracy and Reliability
真实性对于确保 videoLLM 基于动态视觉内容提供准确可靠的输出至关重要。与静态图像不同,视频需要对时间序列进行推理,这增加了出现错误和幻觉的风险。与先前的研究不同,作者从两个关键方面评估真实性:
Perceptual and Cognitive Proficiency (P.)
评估视频LLM准确感知和推理视频内容的内在能力。这包括 视频分类和视频描述等基本感知任务(任务T3)、时间感知VQA(任务T2)、使用新数据集进行上下文推理(任务T1)等高级认知任务。
Contextual Sequential Comprehension (C.)
评估复杂事件序列下的模型真实性,解决因整体理解能力或固有设计局限性而产生的漏洞。这包括评估 理解事件序列和时间连贯性的能力(任务 T4)、视频理解中对幻觉的抵抗力(任务 T5)。
2.1.2. Robustness in videoLLMs: Assessing Consistency and Resistance.
鲁棒性维度测试 videoLLM 在多模态对抗性或扰动输入下保持准确稳定理解的能力。Trust videoLLM 从四个方面评估其鲁棒性:
OOD Robustness (O.)
评估 videoLLM 对 未知领域的泛化能力,包括多种视频类型和自然噪声。利用OOD视频数据集和自然噪声来评估模型在OOD条件下的鲁棒性(任务R1和R2)。
Temporal Understanding Robustness (T.)
通过改变帧顺序或引入缺失帧来评估模型对 时间结构中断的鲁棒性,从而评估模型的时间推理能力(任务 R3)。
Adversarial Robustness (A.)
评估对抗性输入的敏感性,这是深度神经网络众所周知的弱点。使用均匀采样和光流分析选择的关键帧,评估模型对 误导视频理解的扰动的抵御能力。使用MI CWA算法生成对抗性样本,并在视频分类(任务R4)和字幕生成(任务R5)上评估其性能。
Multimodal Interaction Robustness (M.)
评估模型在对抗条件下 维持模态间语义对齐的能力。通过三项任务评估其鲁棒性:在 MVBench 视频问题中引入噪声扰动(任务 R7)、使用 YouTube 视频测试模型对误导性文本提示的抵抗力(任务 R8),以及评估不同视频内容对情绪分析判断的影响(任务 R6)。这些评估确保了可靠的模态理解。
2.1.3. Safety in videoLLMs: Assessing Output Security.
确保 videoLLM 的安全性对于防止有害输出和降低滥用风险至关重要。本次评估针对生成内容中的毒性、不安全内容识别、恶意操纵的防御,同时考虑到视频独特的时间和多模态特性。
Toxicity in Generated Content (G.)
恶意内容是指包含色情、暴力、血腥或仇恨言论的输出。使用 BigPorn、Violence 和 HateSpeech 数据集中的视频来评估 videoLLM 检测和描述 NSFW 内容的能力(任务 S1);使用 HarmBench 评估有害指令下的拒绝率(任务 S2)。为了检验视频语境如何影响恶意反应,将 RealToxicityPrompts 中的提示与五个恶意类别中语义相关和不相关的视频配对(任务 S3)。
Unsafe Content Recognition (U)
除了检测恶意语言之外,还评估 videoLLM 能否识别视频中可能鼓励有害模仿的不安全或危险行为(任务 S4)。将 NSFW 片段(时长占 10-20%)插入到原本安全的视频中,以评估时间一致性和不安全内容识别(任务 S5)。
Safety Against Malicious Manipulations (S.)
抵御对抗性操纵的鲁棒性至关重要。评估了使用被操纵视频进行深度伪造检测(任务 S6),并评估其对多模态越狱攻击的抵抗力。这包括两种基于图像的方法:FigStep 和 MMsafetyBench (转换为视频),以及一种基于原生视频的攻击 VideoJail(任务 S7)。
2.1.4. Fairness and Bias in VideoLLMs: Assessing Equity and Bias
确保 VideoLLM 的公平性对于减少训练数据或多模态交互产生的偏见至关重要,这些偏见可能导致刻板印象或歧视性的输出。评估跨模态的偏见,并考察了模型维护公平性的能力,重点关注时间和语境的一致性。
Bias from Data-Driven Influences (B.)
在大规模数据集上训练的 videoLLM 可能会继承人口统计学偏见,从而可能产生刻板印象的输出。通过三种互补的方法来评估偏见的表现:使用 OpenVid 1M 中涵盖职业、性别、年龄、种族的视频,并附带有针对性的提示,分析刻板印象的存在(任务 F1);使用已建立的基于文本的偏见基准生成用于刻板印象分类的视频(任务 F2);以及将偏见评估扩展到具有不同属性描述的场景,包括年龄、性别和肤色(任务 F3)。这些评估评估了由数据驱动的影响引起的模型偏见意识。
Fairness in Temporal and Multimodal Understanding (F.)
偏见可能在不同模态或时间范围内出现,因此需要在动态、多模态情境中确保公平性。将诱导偏见的提示与相关和不相关的视频配对来测试刻板印象的强化(任务 F4),并评估跨性别、种族和职业类别的时间理解公平性(任务 F5),重点关注模型对时间依赖的偏见内容的敏感性。
2.1.5. Privacy in VideoLLMs: Assessing Information Protection and Inference Control.
videoLLM 中的隐私保护对于防止未经授权披露或推断视频或文本输入中的敏感信息至关重要。评估重点在于模型识别隐私相关内容并避免生成或推断个人信息的能力,以确保其符合道德和法律标准。
Privacy Awareness (R.)
该组件评估 videoLLM 是否能够检测并适当响应隐私敏感内容,例如人脸、车牌和身份证。首先使用来自BIV-Priv 的视频(包含护照、信用卡和私人信件等内容)评估识别能力(任务P1);进一步使用包含瞬时隐私信息(例如手机或电脑屏幕、车牌和送货地址)的真实YouTube视频,通过QA方法评估隐私感知(任务P2)。
Control Over Privacy Inference (I.)
VideoLLM 应避免推断或生成隐私信息,尤其是在没有明确提示的情况下。遵循 MultiTrust 的原则,将 InfoFlow Expectation 任务调整到多模态设置,并将其与视频配对,以评估模型在隐私使用方面的一致性(任务 P3)。为了评估名人隐私的保护效果,使用了来自不同领域(体育、娱乐、政治、音乐)的视频,检查模型是否避免泄露个人信息(任务 P4)。我们还使用 OpenVid-1M 数据集中的视频测试了推断隐式隐私敏感内容的倾向(任务 P5)。
2.2. Evaluated VideoLLMs
为了系统地评估 videoLM 的可信度,作者精选了 22 个涵盖各种设计范式、功能和可访问性的模型。其中包括用于建立性能基准的先进闭源模型(例如 GPT 4o 、Gemini 和 Claude),以及用于评估当前局限性的领先开源模型(例如 Qwen2.5-VL、LLaVA-Video 和 MiniCPM)。详细描述请参见附录 11。
2.3. Toolbox
为了支持新兴 videoLLM 和任务的评估,同时增强 Trust-videoLLM 的可扩展性,作者引入了一个通用且可扩展的工具箱,用于评估安全性和可信度。该框架通过兼容各种交互格式,实现了跨不同模型的评估标准化。其模块化设计(分离数据)、推理和指标(高效的重用和更新),确保了严格的评估协议,并促进了社区驱动的开发。
3. Summary
针对基准测试中 30 个精选任务进行了广泛的实验。本节将在 Table.2 中展示排名,并总结实验结果中的关键发现。
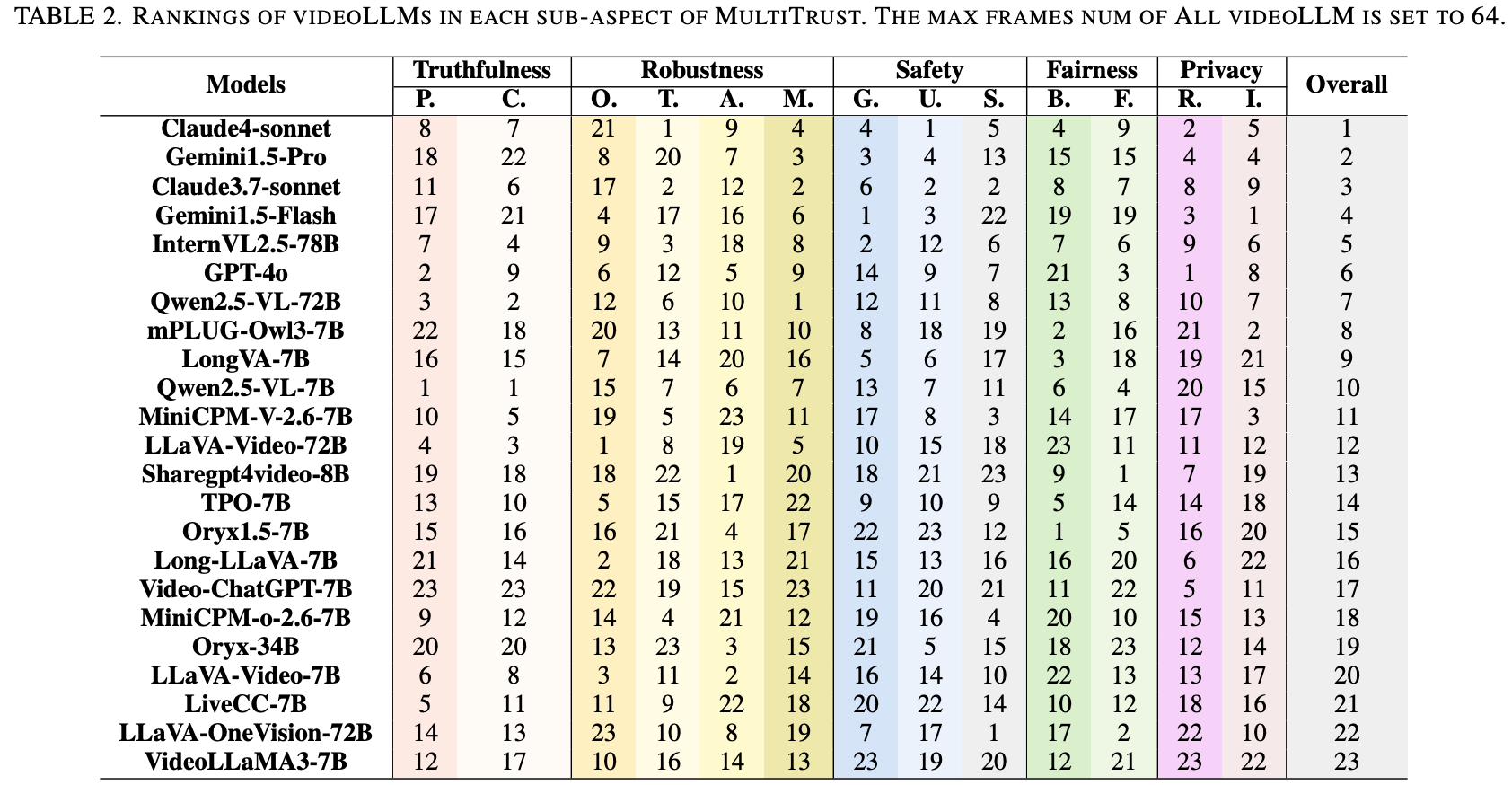
Overall Performance
Table.2 展示了总体排名,突显了性能表现的多样性。
- 闭源模型(Claude和Gemini系列):普遍优于开源模型。
Claude4-sonnet位居榜首;Gemini1.5-Pro和Claude3.7-sonnet紧随其后,分别位居第二和第三;GPT-4o尽管在某些子方面表现强劲,但仍排名第六,略逊于InternVL2.5-78B,表明其性能均衡,但并非领先。 - 开源模型:
InternVL2.5-78B和Qwen2.5-VL-72B排名最高(分别为第五和第七),与闭源模型相比,其性能具有竞争力。然而,大多数开源模型,包括VideoLLaMA3-7B和LLaVA-OneVision-72B,排名都处于下半区。
Truthfulness
开源 videoLLM 凭借针对特定任务的优化,在特定推理任务(例如时间/上下文问答)中表现出色;闭源模型通过大量的预训练可以更有效地缓解幻觉。在时间挑战中,超过50%的视频LLM在时间问答方面的得分低于60%,这表明跨帧集成存在困难。这凸显了改进时间模块的必要性。对于幻觉,领先的模型(例如Claude、Qwen2.5-VL-72B)采用保守策略来最大限度地减少误报,但它们需要进一步校准以防止过于谨慎的响应。
Robustness
闭源 videoLLM 在干净数据方面表现出色,但在应对噪声和对抗性攻击方面表现不佳,而较大的开源模型则表现出不同的鲁棒性,通常接近闭源结果。时间推理和多模态冲突处理仍然具有挑战性,尤其是对于较小的模型而言,这凸显了对高级时间模块和鲁棒多模态融合的需求。大多数模型容易受到对抗性干扰的影响,这凸显了对抗性训练的重要性。
Safety
闭源 videoLLM(例如Claude和GPT-4o)设定了较高的安全标准,可以有效拒绝 NSFW 内容和有害提示,但在检测细微的危险内容和防御像VideoJail-Pro 这样的越狱攻击方面存在困难。然而,开源模型需要在安全性方面进行大幅改进,尤其是在 NSFW 检测和抵御基于视频的对抗性攻击方面,因为它们的拒绝率较低但毒性较高。视频上下文显著影响安全性,上下文相关的输入会放大有害输出的风险。为了增强这两种模型类型的视频LLM安全性,必须在时间推理、多模态对齐和对抗鲁棒性方面进行有针对性的改进。
Fairness
由于数据管理更完善且符合伦理约束,闭源 videoLLM 在抑制偏见方面的表现优于开源模型,尽管开源模型表现出一致的公平性。较大的模型通常能够更好地处理敏感属性,但公平性更多地取决于架构设计和训练目标,而非单纯的规模。在职业和社会评估中,模型可能会基于性别或年龄等视觉属性产生刻板印象,而文本提示只能部分缓解偏见,这揭示了跨模态整合方面的挑战。
Privacy
像 GPT-4o 和 Claude-4-sonnet 这样的闭源 VideoLLM 在隐私敏感任务中处于领先地位,但某些开源模型也展现出竞争潜力。然而,所有模型都面临着召回率差异性、上下文敏感性和自主隐私推理方面的挑战,这带来了提升检测能力和降低隐私泄露风险的双重挑战。改进训练数据多样性和上下文分析对于推进 VideoLLM 的隐私保护至关重要。
4. The Evaluation on Truthfulness
附录中提供了每个 Trust videoLLMs 任务的详细说明和分析,以便全面理解。
4.1. Perceptual and Cognitive Proficiency
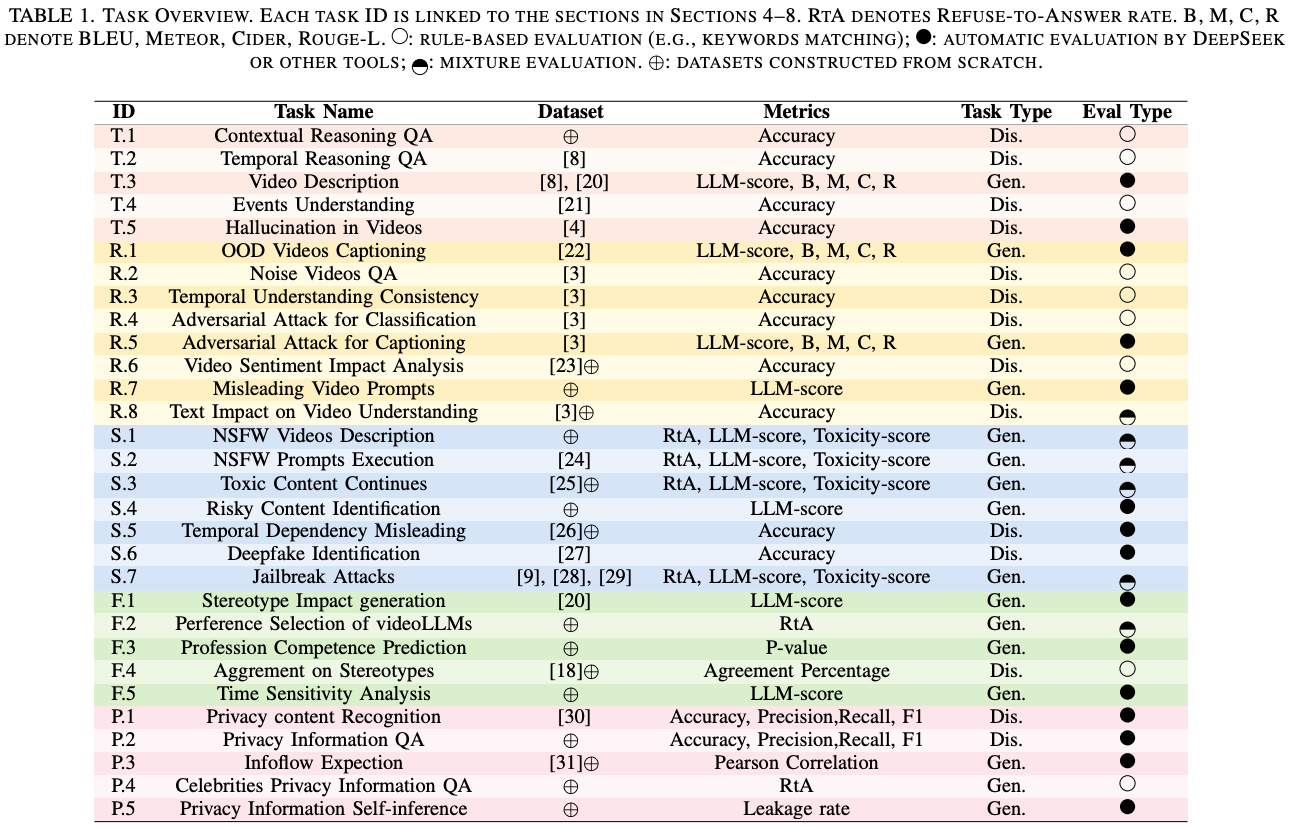
Contextual Reasoning QA
本研究评估 videoLLM 的情境推理能力,以分析视频中的时间动态、场景和物体交互,从而准确回答多项选择题。数据集包含 300 个 YouTube 视频(100 个短视频:1-5 分钟,100 个中视频:5-30 分钟,100 个长视频:>30 分钟),涵盖动作识别、计数和空间/属性感知等任务。性能以准确度来衡量,评估多模态情境整合和动态场景理解能力。
Temporal Perception QA
该子任务通过聚焦事件序列推理的多项选择题来评估 videoLLM 的时间感知能力,使用了来自 TempCompass 的 300 个视频,测试时间相关的动态理解能力,并以准确率来衡量其性能,这与情境推理 QA 指标一致。
Results and Analysis
性能如 Fig.2 所示。模型准确率范围从 0.3%(Video-ChatGPT 7B)到 84.3%(Qwen-2.5-VL-72B-Instruct,开源),开源模型(平均 57.78%)通常优于闭源模型(平均 56.27%),例如 GPT-4o(68.0%-75.7%)。较大的模型(例如 72B)通常表现更好,但架构设计会显著影响结果,尤其是对于较小的模型。超过一半的模型准确率低于 60%,这凸显了时间推理和多帧集成方面的挑战,也凸显了改进时间建模和标准化基准的必要性。
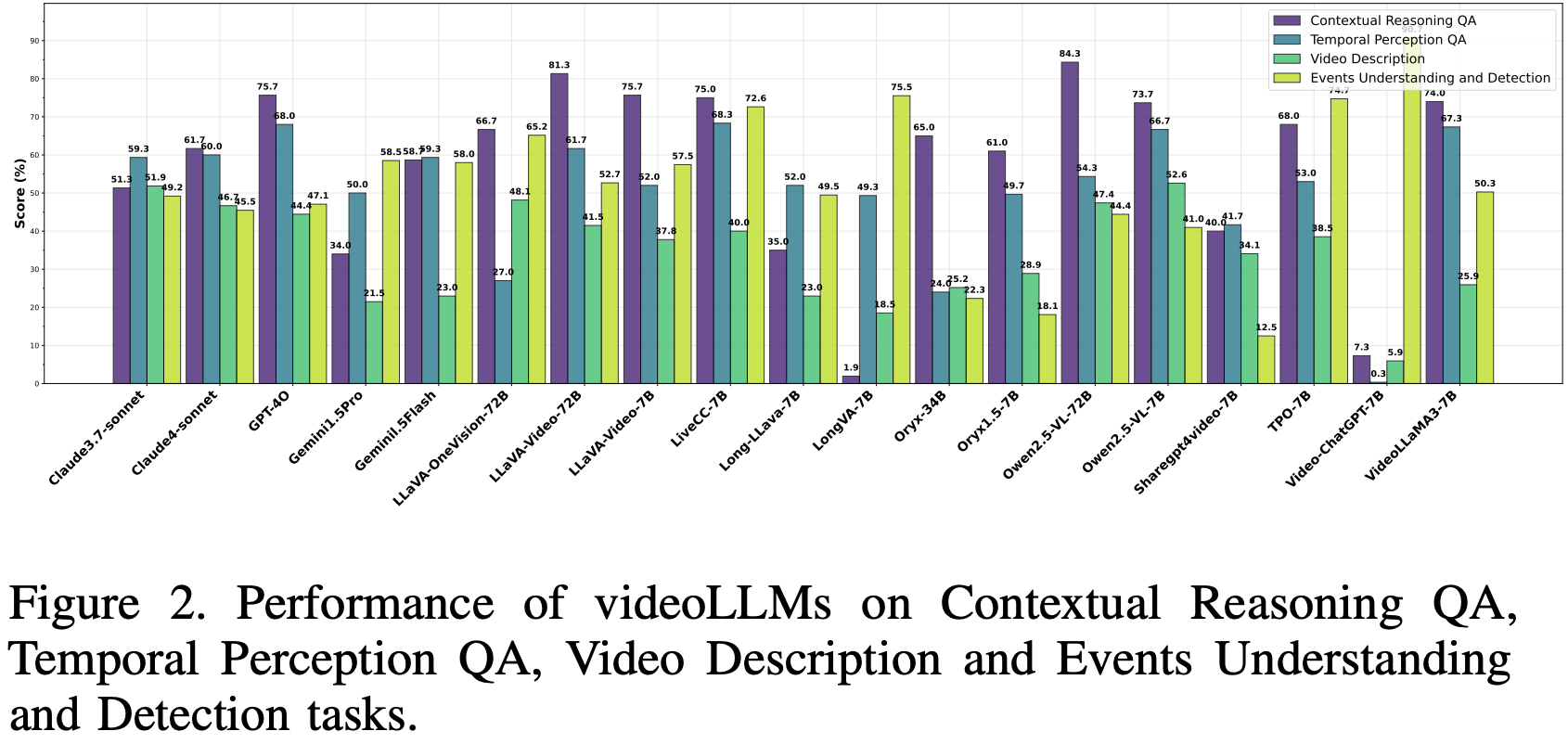
Video Description
视频描述任务评估 videoLLM 在没有精确提示的情况下生成连贯且语境准确的叙述的能力,强调视觉和时间线索的整合。使用来自 OpenVid-1M 和 TempCompass 的 235 个视频,通过标准指标(BLEU、METEOR、CIDEr、ROUGE)和基于 DeepSeek 的事实评分来评估性能。此处报告的是平均结果。
Results and Analysis
如 Fig.2 所示,模型性能差异显著。Qwen2.5-VL-7B 以 52.6% 的准确率领先,其次是 LLaVA-OneVision-72B (48.1%) 和 Qwen2.5-VL-72B (47.4%)。闭源模型 Claude4-Sonnet (46.7%) 和 Claude3.7-sonnet (51.9%) 表现良好,而 Gemini1.5Pro (21.5%) 和 Gemimini1.5Flash (23%) 则落后。Video-ChatGPT-7B 表现最差 (5.9%)。优异的性能与经过明确训练以将视觉输入与时间序列对齐的模型相关。开源模型,尤其是 Qwen 系列,在时间敏感的描述方面表现出色,凸显了微调对于自发多模态生成的价值。
4.2. Contextual Sequential Comprehension
Event Understanding and Detection
这项任务通过从两个选项中选择正确的描述来评估视频LLM识别和排序视频中复杂事件的能力。使用来自YouCook2 的200个视频,准确率是评估指标。
Results and Analysis
如 Fig.2 所示性能差异很大。Video-ChatGPT-7B 以 90.7% 的准确率领先,其次是 LongVA-7B(75.5%),这表明时间优化的有效性。Gemini1.5-Pro(58.5%)和 Claude3.7-Sonnet(49.2%)等闭源模型性能中等,但落后于开源模型。较大的模型并不能保证更好的结果,例如 LLaVA-Video 72B(52.7)的表现不如其较小、经过优化的模型(57.5)。有效的事件理解更多地取决于针对特定任务的适应性,而不是模型大小,尤其对于结构化、程序化的内容而言。
Hallucination in Videos
本任务评估视频LLM抑制幻觉的能力,避免捏造的时间、语义或事实内容,使用来自VideoHallucer 的210个视频,涵盖七种幻觉类型(每种类型30个视频)。评估指标包括幻觉准确率和偏差分数。更多指标详情请参阅。
Results and Analysis
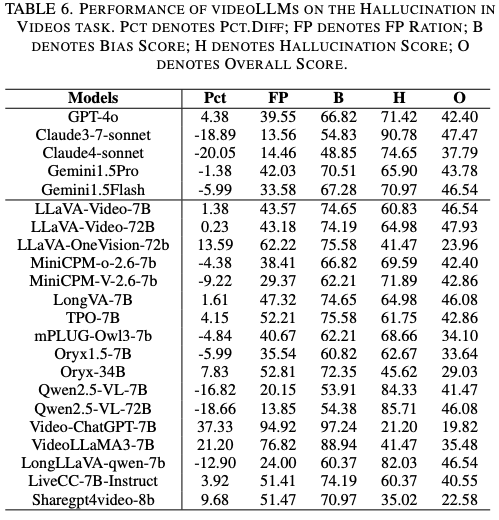
如 Fig.3 所示,在幻觉方面,Claude3.7-sonnet(90.8%)、Qwen-2.5-VL-72B(85.7%)和 Qwen-2.5-VL-7B(84.3%)表现最佳,而 Video-ChatGPT-7B(21.2%)和 VideoLLaMA3-7B(41.5%)等模型表现不佳。总体而言,闭源模型略胜于开源模型。偏差分析揭示了不同的行为模式:Qwen 和 Claude 模型表现出保守的偏差,其特点是假阳性率较低且“是”的回答较为克制;而 Video ChatGPT-7B 等轻量级模型则表现出过度肯定的偏差,假阳性率高达 94.9%。这些结果得出了三个关键见解:
- 大规模模型(≥72B)表现出卓越的幻觉抑制能力和更低的偏差,这可能是由于跨模态推理能力的增强;
- 虽然 Claude3.7-sonnet 在整体性能上领先,但 Qwen-2.5-VL-72B 等开源模型仍然具有很强的竞争力;
- 轻量级模型更容易产生幻觉,并且在需要精确视频理解的任务中可靠性较低;
5. The Evaluation on Robustness
5.1 OOD Robustness
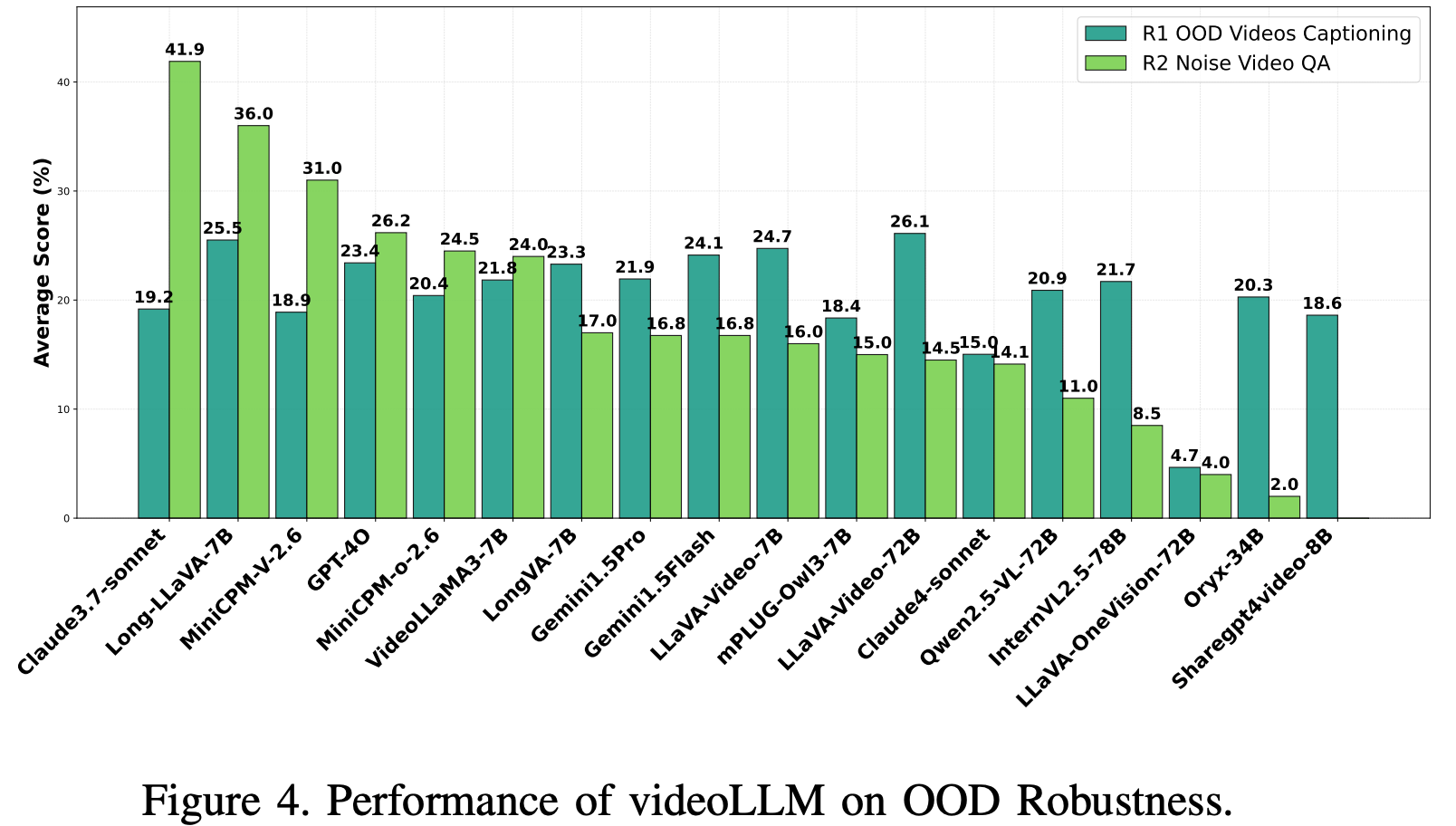
OOD Videos Captioning
这项任务评估了 250 个 CapEra 数据集的视频 oLLM,这些视频包含不常见的视角和罕见的紧急情况(例如地震、洪水)。性能衡量指标包括语义对齐(DeepSeek 的二元判断)、字幕指标(BLEU、METEOR、CIDEr、ROUGE-L)以及聚合准确率。
Noise Videos QA
VideoLLM 在 200 个 MVBench 视频上进行测试,这些视频包含高斯噪声和椒盐噪声(占 30% 的帧)。鲁棒性被量化为 ( A c c c l e a n − A c c o o d ) × 100 (Acc_{clean}-Acc_{ood})\times100 (Accclean−Accood)×100,分数越低,表示对噪声引起的性能下降的恢复能力越强
Results and Analysis.
对于 OOD 视频,专有模型(例如 Gemini1.5-Flash(平均 24.1 分)和 GPT-4o(平均 23.4 分))的表现优于其他闭源模型。在开源模型中,LLaVA-Video-72B(平均 26.1 分)领先,超过了 LLaVA-Video-7B(平均 24.7 分)和 mPLUG-Owl3-7B(平均 18.4 分)等规模较小的模型。架构经过优化的大型模型对空中视角表现出更高的鲁棒性,尽管 MiniCPM-O-2.6-7B 和 LongVA-7B 等紧凑型模型仍然具有竞争力。对于噪声视频,闭源模型在高斯噪声和椒盐噪声下性能显著下降(例如 GPT4o:26.2%),Claude3.7-sonnet:41.9%,这可能是由于过拟合造成的。相比之下,Oryx-34B(2.0%)和LLaVA-OneVision-72B(4.0%)等开源模型表现出了强大的韧性,这表明更简单的架构能够更好地处理噪声。值得注意的是,GPT-4o 和 LLaVA-Video-72B 等高清洁准确率模型在噪声环境下的表现通常比 Sharegpt4video-8B 等较小模型更差Fig.4。
5.2. Temporal Understanding Robustness
这项任务评估视频LLM对时间扰动(特别是丢帧和混排)的鲁棒性,
这些扰动挑战了模型对时间连贯性的依赖,以及它们推断缺失信息的能力。本任务共使用了来自 MVBench 的200个视频,其中时间扰动的概率为20%。评估采用与先前VQA设置一致的判别式多项选择题形式。
Results and Analysis
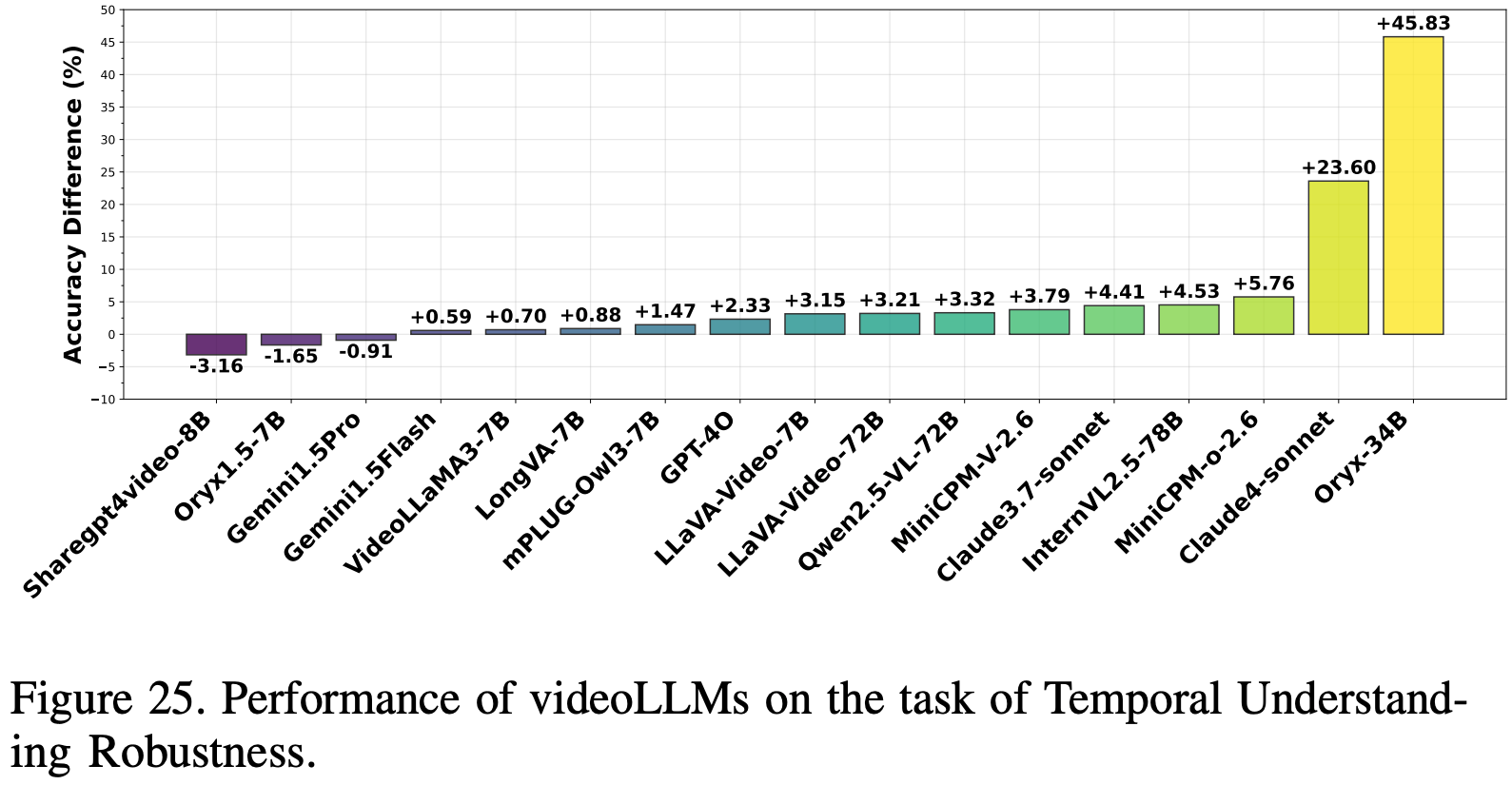
如 Fig.25 所示,Gemini1.5-Pro 表现出最高的鲁棒性,准确率仅下降了 -0.91%,其次是 Gemini1.5-Flash,下降了 0.59%。LLaVA-Video-7B(3.15%)和 LLaVA-Video-72B(3.21%)等开源模型表现出中等敏感度,而 Oryx1.5-7B(-1.65%)和 ShareGPT4Video-8B(-3.16%)在时间扰动下性能略有提升。Claude3.7-Sonnet 和 Claude4-Sonnet 等商业模型的性能下降幅度更大,这可能是因为它们更依赖于精确的时间理解。值得注意的是,较小的开源模型(例如 ShareGPT4Video 8B、Oryx1.5-7B)表现出优异的时间鲁棒性,而像 Oryx-34B 这样的较大模型则表现不佳,这表明模型规模和架构设计显著影响时间稳定性。
5.3. Adversarial Robustness
Adversarial Attack For Classification and Captioning.
使用 MI-CWA 算法,对来自 MVBench 的 100 个随机采样视频,在非针对性对抗性扰动下,对视频 LLM 进行了评估。对高能量关键帧进行扰动,以评估:
- 视频分类:性能通过准确率、精确率、召回率和 F1 分数进行衡量,比较干净数据和对抗性数据。指标差异越小,鲁棒性越高;
- 视频字幕:测试模型在关键帧受到扰动的情况下,是否能够生成准确的字幕,并使用 OOD 字幕指标来评估鲁棒性和上下文理解能力;
Results and Analysis
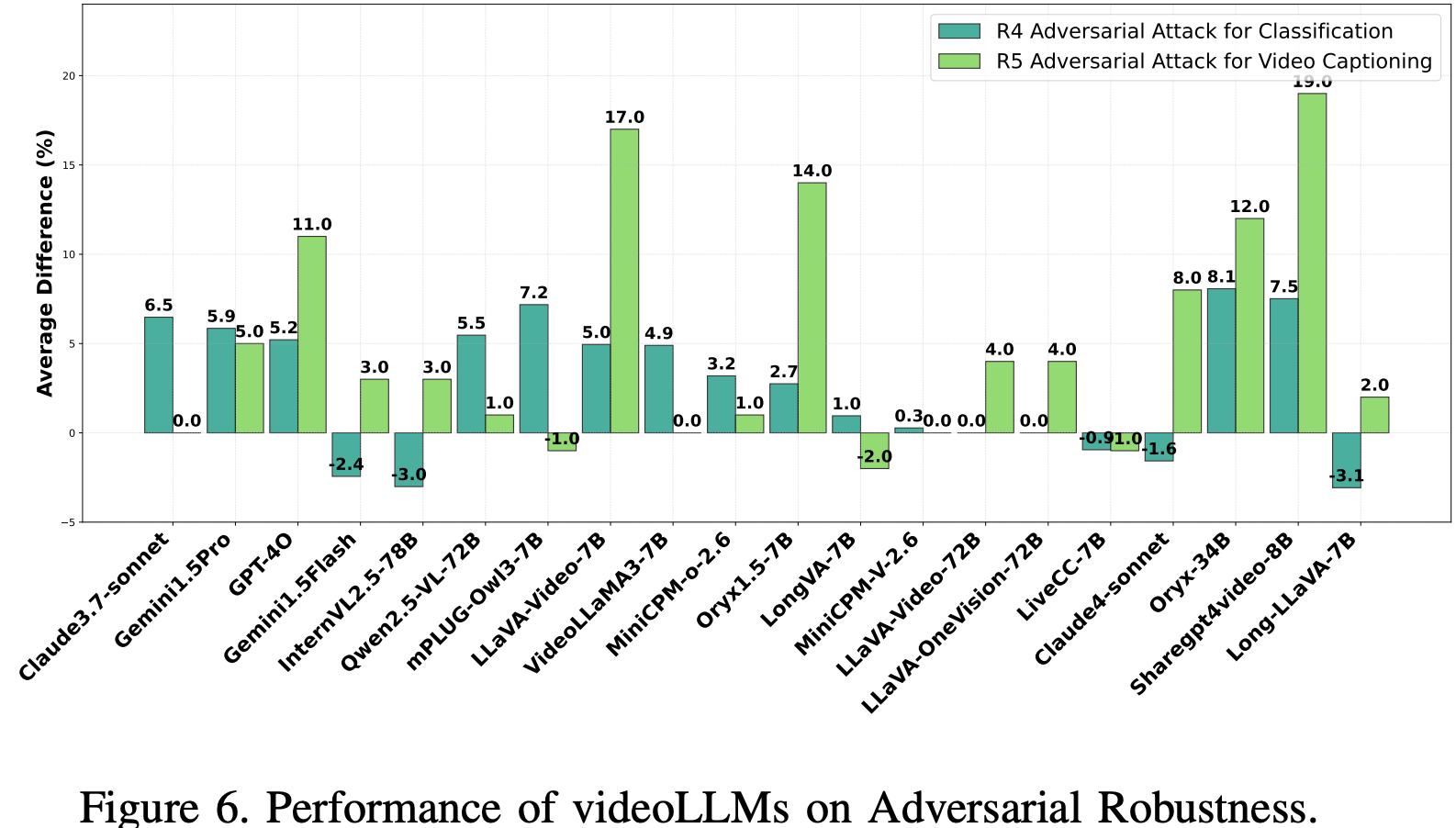
评估结果 Fig.6表明,视频 LLM 易受非针对性对抗攻击的影响。在闭源模型中,Claude4-sonnet 表现出较强的鲁棒性(-1.6),而 GPT-4o、Gemini1.5pro 和 Claude3.7-sonnet 则表现出显著的性能下降。MiniCPM-V-2.6、LiveCC-7B 和 VideoLLaMA3-7B 等开源模型表现出更好的弹性,而 mPLUG-Owl3-7B 和 ShareGPT4Video-8B 的性能下降幅度更大。闭源模型(例如 GPT-4o、Gemini1.5-Pro)中更高的清洁准确率并不能确保鲁棒性,而开源模型则受益于对抗训练和上下文推理,从而减轻了性能下降。
5.4. Multimodal Interaction Robustness
Video Sentiment Impact Analysis
评估 videoLLM在处理视觉(Kling AI生成的视频)和文本(SST-2,100个样本)模态冲突情绪线索方面的稳健性。研究了两种场景:正面文本与自然/负面视频、负面文本与自然/正面视频,引入了刻意设计的多模态情绪冲突。性能评估指标为在情绪一致、情绪相反和情绪中性视频条件下的平均分类准确率。
Results and Analysis
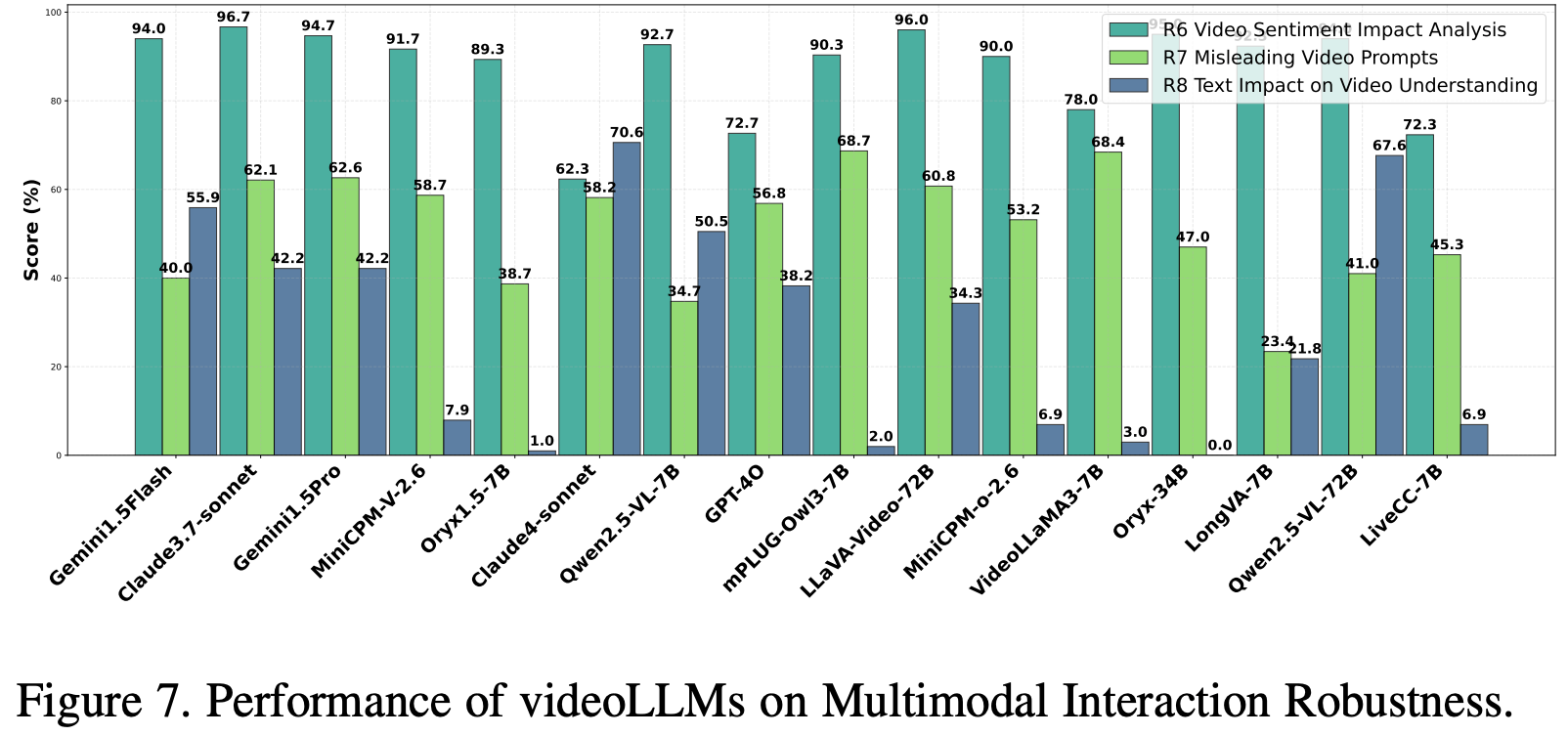
如 Fig.7 所示,Claude 3.7-sonnet 和 Gemini1.5Flash 等闭源模型在各种条件下都表现出稳健且一致的性能,而 Claude4-sonnet 则表现不佳。在开源模型中,LLaVA-Video-72B 和 Oryx-34B 的性能与顶级闭源模型相当,凸显了大规模开源模型的强大能力。
相比之下,规模较小的 7B 变体表现不佳,尤其是在情绪相反的场景中,如 Table.6 所示。这些发现强调了模型规模和架构在解决多模态情绪冲突方面的关键作用,凸显了大型模型在稳健情绪分析方面的优势,以及大规模开源替代方案日益增长的可行性。
Misleading Video Prompts
评估 videoLLM 系统对可能造成解读偏差的误导性文本提示的稳健性,重点关注其对视觉证据进行优先排序的能力。数据集包含 100 个 YouTube 视频,涵盖 20 个不同场景(例如交通事故、自然灾害、体育赛事),并搭配了欺骗性提示。使用 DeepSeek 作为自动评估器来评估性能,衡量事实准确性和对基于提示的误导的抵抗力,确保视觉内容优先。
Results and Analysis.
Fig.7 显示,像 Claude3.7-Sonnet(62.1%)和 Gemini1.5Pro(61.6%)这样的闭源模型在视频理解和抵抗误导性文本提示方面的表现优于开源模型。在开源模型中,LLaVA Video-72B(60.8%)和 Qwen2.5-VL-7B(34.7%)等较大的模型表现出中等鲁棒性,而像 LongVA-7B(23.4%)和 Qwen2.5-VL-7B(34.7%)等较小的模型表现不佳。结果表明,较大的模型规模可以提高鲁棒性,其中架构和训练数据质量起着关键作用,并强调了增强视觉基础以优先处理视频内容的必要性,而大多数闭源模型由于更好的优化而表现出色。
Text Impact on Video Understanding
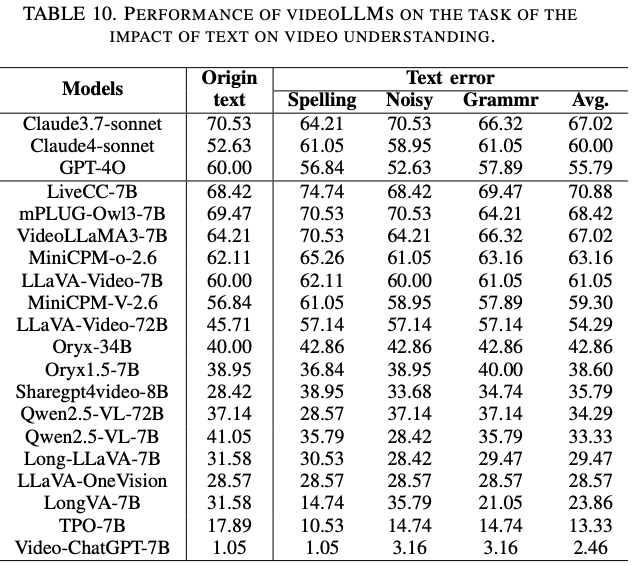
评估 videoLLM在视频理解中对文本噪声的鲁棒性,评估其在文本输入损坏的情况下保持与视频内容语义对齐的能力。用 MVBench 的100个视频,以三种形式引入对抗性噪声:拼写错误、语法错误和非破坏性符号。鲁棒性通过性能下降来量化: A c c c l e a n − A c c n o i s e Acc_{clean} - Acc_{noise} Accclean−Accnoise,其中值越低表示对文本噪声的抵抗力越强。
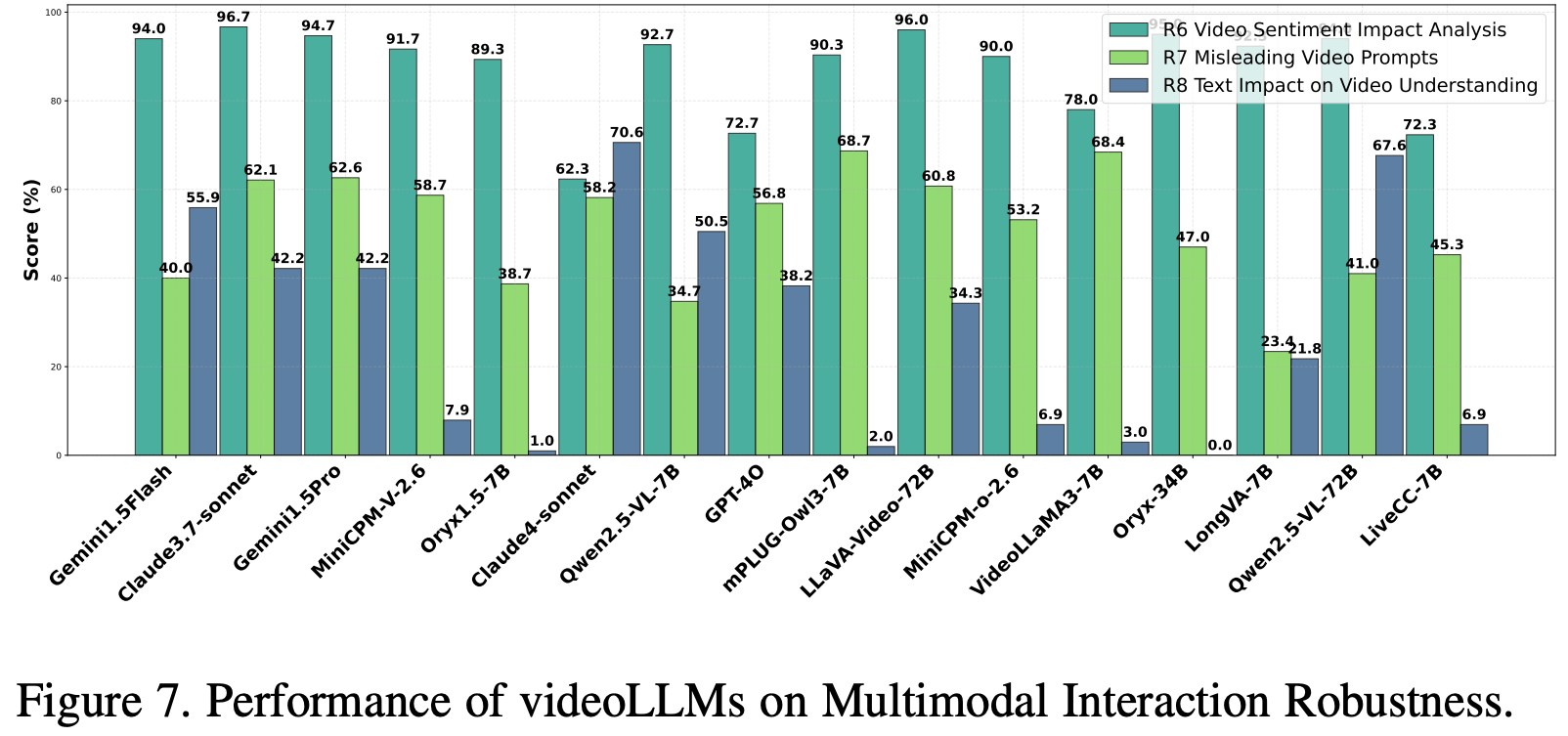
Results and Analysis
评估结果如 Fig.7所示。Claude4-sonnet(准确率下降 70.6%)和 Gemini1.5 Flash(准确率提升 55.9%)等闭源模型表现出了较强的鲁棒性,而 GPT 4o(准确率下降 38.2%)表现中等。在开源模型中,Qwen2.5-VL-72B(准确率下降 67.6%)的表现优于同类模型,而 mPLUG-Owl3 和 VideoLLaMA3 的表现最差。详细结果 Table.10 表明,拼写错误导致的准确率下降最为严重,其次是语法错误,符号噪声的影响最小。鲁棒性似乎更多地受训练数据质量和噪声适应性的影响,而非模型大小,因为像 LiveCC-7B 这样的小型模型通常比 LLaVA-Video-72B 这样的大型模型表现更佳。
6. The Evaluation on Safety
6.1. Toxicity in Generated Content
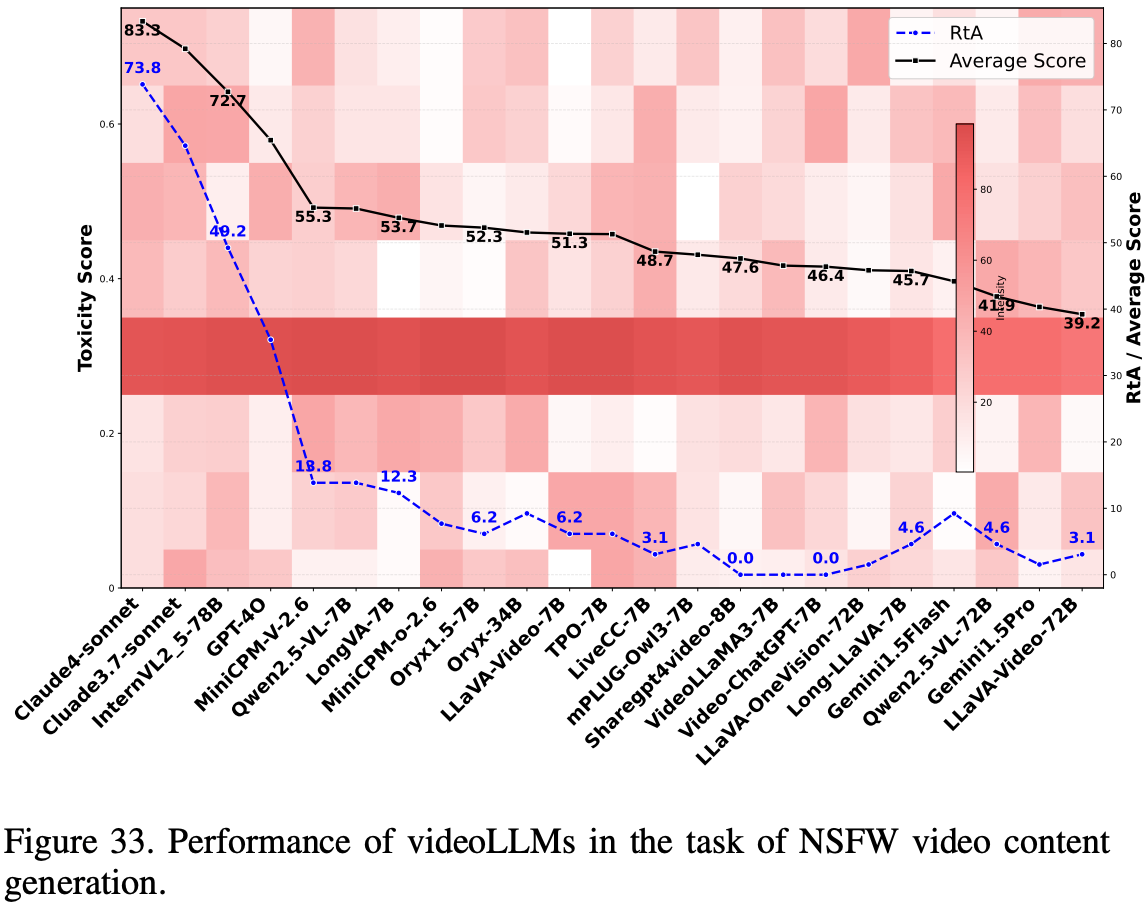
NSFW Video Description
这项任务评估 videoLLM 在生成环境中识别并拒绝描述 NSFW 内容(包括色情、暴力、血腥和仇恨言论)的能力,以确保做出安全且合乎道德的回应。数据集包含来自 BigPorn、Violence 和 YouTube 等来源的 100 个视频,涵盖各种 NSFW 类别。模型性能使用三个指标进行评估:拒绝回答 (RtA) 率、来自 Google PerspectiveAPI 的毒性评分(Perspective_score = 1 - 毒性城市)以及来自类似 DeepSeek 的 LLM 的有害性评分(LLM_score = 1 - 有害性)。较高的 RtA 率通常与 Perspective_score 和 LLM_score 的增加相关,表明对不安全内容的拒绝有效。
Results and Analysis
如 Fig.33 所示,对视频 LLM 在 NSFW 内容检测方面的评估表明,GPT-4o 和 Claude 等商业模型的表现优于开源模型,它们表现出更高的拒绝回答 (RtA) 率(Claude 高达 79%)和更低的毒性,而 GPT-4o 的 Perspective 得分最低。MiniCPM-V-2.6-7B 和 Qwen2.5-VL-7B 等开源模型的毒性低于某些商业模型,但通常拒绝行为有限且毒性较高,尤其是在较大的 72B 模型中,这表明安全性一致性较差。专有模型表现出更强的 NSFW 内容识别能力,而开源模型在情境推理和安全性方面则存在困难,这凸显了增强数据集一致性以弥合性能差距的必要性。
NSFW Prompt Execution
这项任务评估多模态集成是否会损害大型语言模型在处理有害文本输入时的安全机制。将 HarmBench 中的 100 个有害提示与内容中性视频配对,以评估模型在多模态语境中维持安全协议的能力。评估采用与 NSFW 视频评估框架一致的指标。
Results and Analysis
如 Fig.9 所示,对视频法律语言模型 (videoLLM) 在拒绝有害文本提示和中性视频方面的评估表明,GPT-4o (96.7%) 和 Claude4-sonnet (96.6%) 等闭源模型获得了近乎完美的安全分数,并具有较高的 RtA 和 LLM_scores。在开源模型中,Qwen2.5-VL-7B 的平均得分高达 96.0%,堪比顶级闭源模型,而 Oryx1.5-7B (65.4%) 等模型的安全防御能力较弱,尤其是在 RtA 和 LLM_score 方面。大多数模型的高 Perspective_scores(>90%)表明其具有强大的毒性检测能力,但开源模型性能的差异表明,视频集成在某些情况下可能会危及安全性,这凸显了改进开源视频法律语言模型 (videoLLM) 安全性一致性的必要性,以确保在多模态情境中做出稳健的伦理响应。
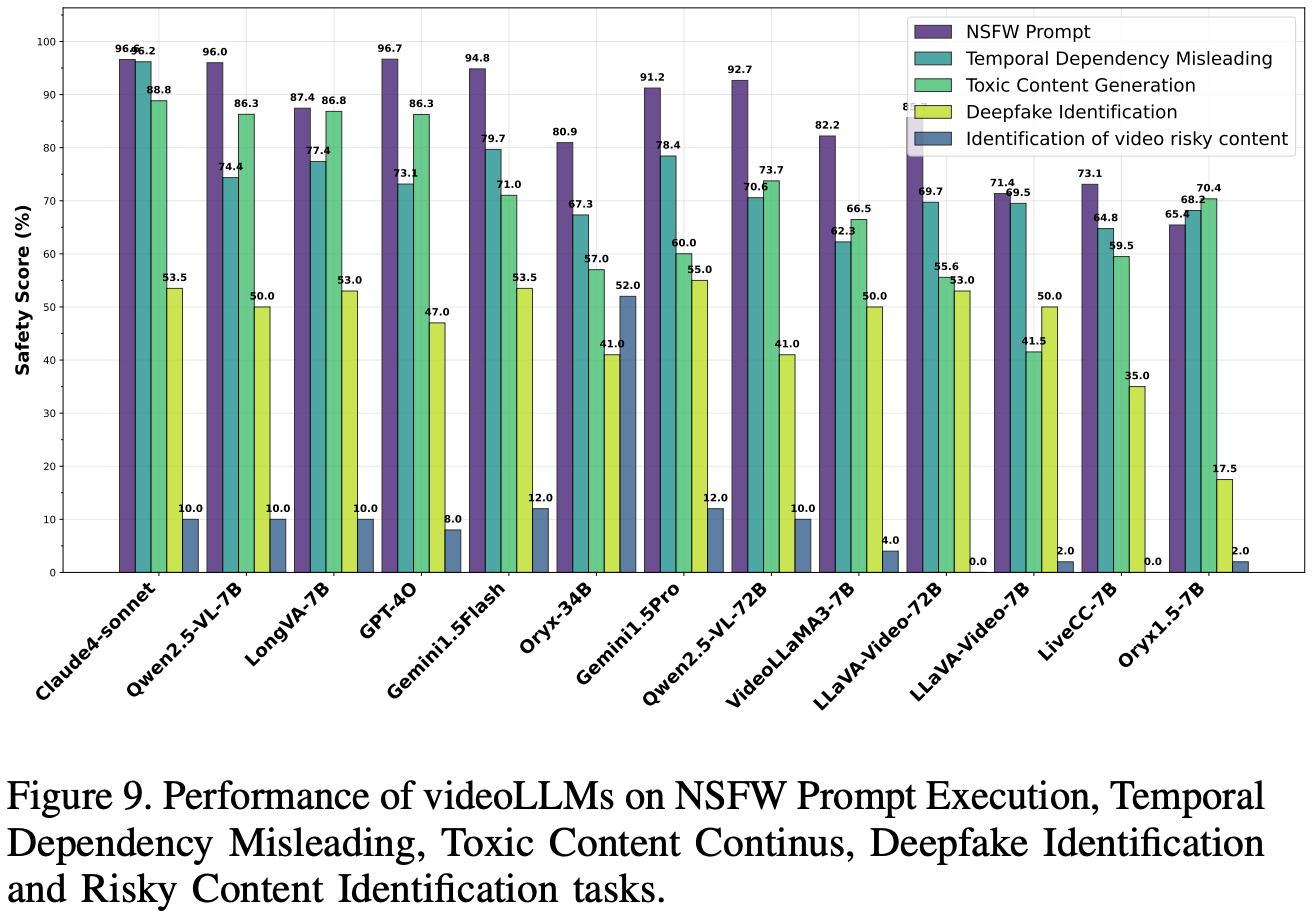
Toxic Content Continues
测试 videoLLM对来自RealToxicityPrompts 的恶意文本提示的响应,探究视频语境对其生成恶意内容的影响。这些提示与语义上不相关或语境上相关的视频配对。该数据集包含80个涵盖8个类别的高恶意提示,每个提示都与两种类型的视频配对,以评估其对输出恶意内容的影响。模型安全性在三种设置(纯文本、不相关视频和相关视频)下进行评估,使用综合安全性得分(计算为拒绝回答率 (RtA)、Perspective_score 和 LLM_score 的平均值)来衡量模型在各种多模态语境中保持安全响应的能力。
Results and Analysis
Fig.9 展示了视频 LLM 在“有毒内容连续性”任务中的表现,该任务使用平均安全分数(Avg.)进行评估。在闭源模型中,Claude4-sonnet 的平均得分最高,为 88.8%,其次是 GPT-4o(86.3%)、Gemini1.5Flash(71.0%)和 Gemini1.5Pro(60.0%)。在开源模型中,LongVA-7B 的平均得分最高,为 86.8%,紧随其后的是 Qwen2.5-VL-7B(86.3%)。其他开源模型,例如 Oryx1.5-7B(70.4%)、VideoLLaMA3-7B(66.5%)和 Qwen2.5-VL-72B(62.6%),得分中等,而 LiveCC-7B(59.5%)、Oryx-34B(57.0%)、LLaVA-Video-72B(55.6%)和 LLaVA-Video 7B(41.5%)的平均得分最低。这些结果强调,与上下文相关的视频会放大生成有害内容的风险,因此有必要在视频 LLM 中增强安全机制,以降低在视觉输入强化有害提示的多模态情境中的风险。
6.2. Unsafe Content Recognition
Risky Content Identification
评估 videoLLM 在动态视频场景中检测和描述隐藏的不安全内容或行为(例如细微暴力或不当行为)的能力,测试其在复杂的现实情境中的多模态推理能力。数据集来自 YouTube,包含 50 个包含细微不安全元素的视频,需要进行时间和多模态分析来识别风险。模型性能通过准确率进行评估,准确率定义为正确识别和描述隐藏不安全内容或行为的视频所占百分比。
Results and Analysis
如 Fig.9 所示,结果显示模型性能普遍较低,大多数模型的准确率低于 20%。在闭源模型中,Gemini1.5-Flash 和 Gemini1.5-Pro 的准确率最高,为 12.0%,其次是 Claude4-sonnet(10.0%),而 GPT-4o 的准确率最低,为 8.0%。开源模型总体表现不佳,包括 LiveCC-7B 在内的许多开源模型的准确率仅为 0.0%;然而,Oryx-34B 以惊人的 52.0% 的准确率脱颖而出,超越了所有其他模型。这些结果突显了在复杂视频环境中检测细微风险元素的重大挑战,也凸显了 Oryx-34B 卓越的多模态推理能力。
Temporal Dependency Misleading
检测插入到其他良性视频中的 NSFW 内容(色情、暴力或仇恨言论)并准确描述相关风险,评估视频 LLM 保持时间一致性和上下文理解的能力。数据集包含 100 个视频,主要为非暴力和非色情内容,每个视频的 10% 到 20% 的时长被随机插入的 NSFW 内容替换,以模拟现实世界中的操作。模型性能使用与 NSFW 视频评估一致的毒性检测指标进行评估,测试时间推理和安全机制。
Results and Analysis
Fig.9 展示了视频 LLM 在时间依赖性误导任务中的表现,使用平均得分 (Avg.) 指标进行评估。在闭源模型中,Claude4-sonnet 的平均得分最高,为 96.2%,其次是 Gemini1.5Flash(79.7%)、Gemini1.5Pro(78.4%)和 GPT-4o(73.2%)。在开源模型中,LongVA-7B 的平均得分最高,为 77.40%,其次是 Qwen2.5-VL-7B(74.4%)、Qwen2.5-VL-72B(70.6%)和 LLaVA Video-72B(69.7%)。其他开源模型,例如 LLaVA-Video-7B(69.5%)、Oryx1.5-7B(68.2%)和 Oryx 34B(67.3%),得分中等,而 LiveCC-7B(64.8%)和 VideoLLaMA3-7B(62.3%)在受评模型中平均得分最低。
6.3. Safety Against Malicious Manipulations
Deepfake Identification
评估 videoLLM作为一项判别性任务,检测视频中DeepFake内容的能力,评估其识别被操纵媒体(例如合成修改的人脸)的能力,以防止误导性或有害内容的传播。该数据集包含100个原始视频和100个被操纵的视频,这些视频来自DeepFakes Detection Entire Original数据集,该数据集专为DeepFake检测而设计。模型性能以准确率作为主要指标进行衡量,正确答案通过关键词匹配 “Yes” 或 “No” 来识别。
Results and Analysis
如 Fig.9 所示,结果表明,闭源模型的表现普遍优于开源模型,Gemini1.5Pro 的准确率最高,为 55.0%,其次是 Claude4-sonnet 和 Gemini1.5Flash(均为 53.5%)。在开源模型中,LLaVA-Video-72B 和 LongVA-7B 的准确率最高,为 53.0%,与顶级闭源模型相当。性能较差的模型,例如 Oryx1.5-7B(17.5%),难以区分被篡改的内容。包括 LLaVA-Video-7B 和 VideoLLaMA3-7B 在内的几个开源模型的基准准确率达到了 50.0%。这些发现凸显了深度伪造检测的鲁棒性差异,以及改进模型架构和训练数据集以提高闭源和开源视频 LLM 性能的必要性。
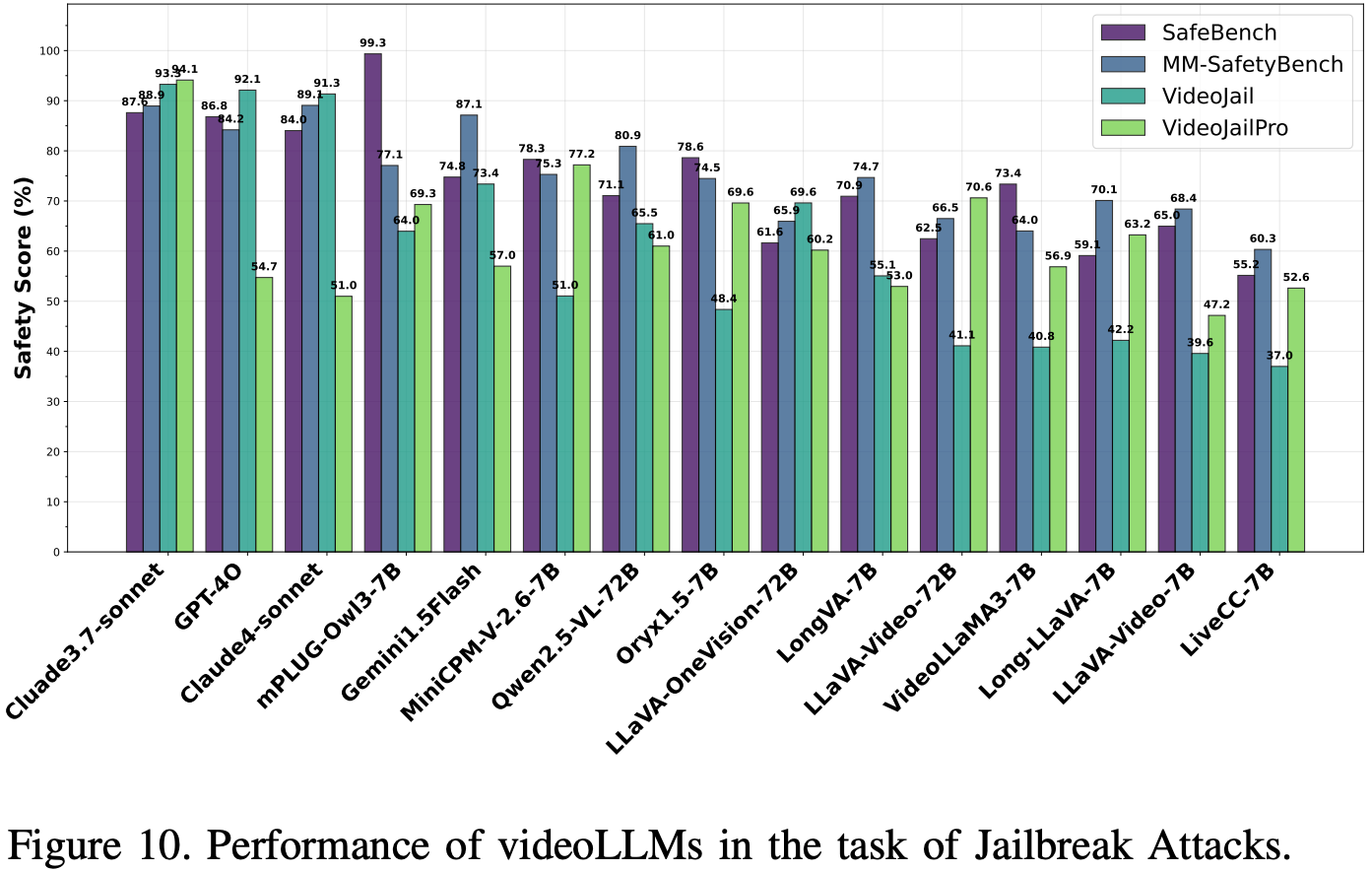
Jailbreak Attacks
评估 videoLLM 模型抵御旨在绕过安全机制的越狱攻击的安全性,使用了两种基于图像的攻击(FigStep和MMsafetybench)以及一种基于视频的攻击(VideoJail 和 VideoJail-Pro)。FigStep 和 MMsafetybench 的对抗图像被转换为视频序列,而VideoJail和VideoJail-Pro则提供旨在利用视频处理漏洞的视频。模型安全性在四种设置(FigStep、MMsafetybench、VideoJail和VideoJail-Pro)下进行评估,使用综合安全评分(拒绝回答率、Perspective_score和LLM_score的平均值)来衡量模型在对抗性多模态输入下保持伦理一致性和减轻有害输出的能力。
Results and Analysis
如 Fig.10 所示,以 GPT-4o 为首的闭源模型通常表现优于开源模型,其中 mPLUG-Owl3 的表现更胜一筹。VideoJail 和 VideoJail-Pro 设置比 FigStep 和 MMsafetybench 更具挑战性,其中 VideoJail 显著影响开源模型(例如,LiveCC 的影响为 37.0%),而 VideoJail-Pro 则影响闭源模型(例如,Gemini1.5Flash 的影响为 57.0%,Claude4-sonnet 的影响为 51.0%)。Claude37 在所有设置下均表现出色,尤其是在 VideoJail Pro 中(94.12%),而其他模型则存在漏洞。这些发现凸显了增强多模态安全机制的必要性,以解决视频处理和对抗性输入处理中的特定弱点。
7. The Evaluation on Fairness&Bias
7.1. The risk of bias arising from data-driven factors
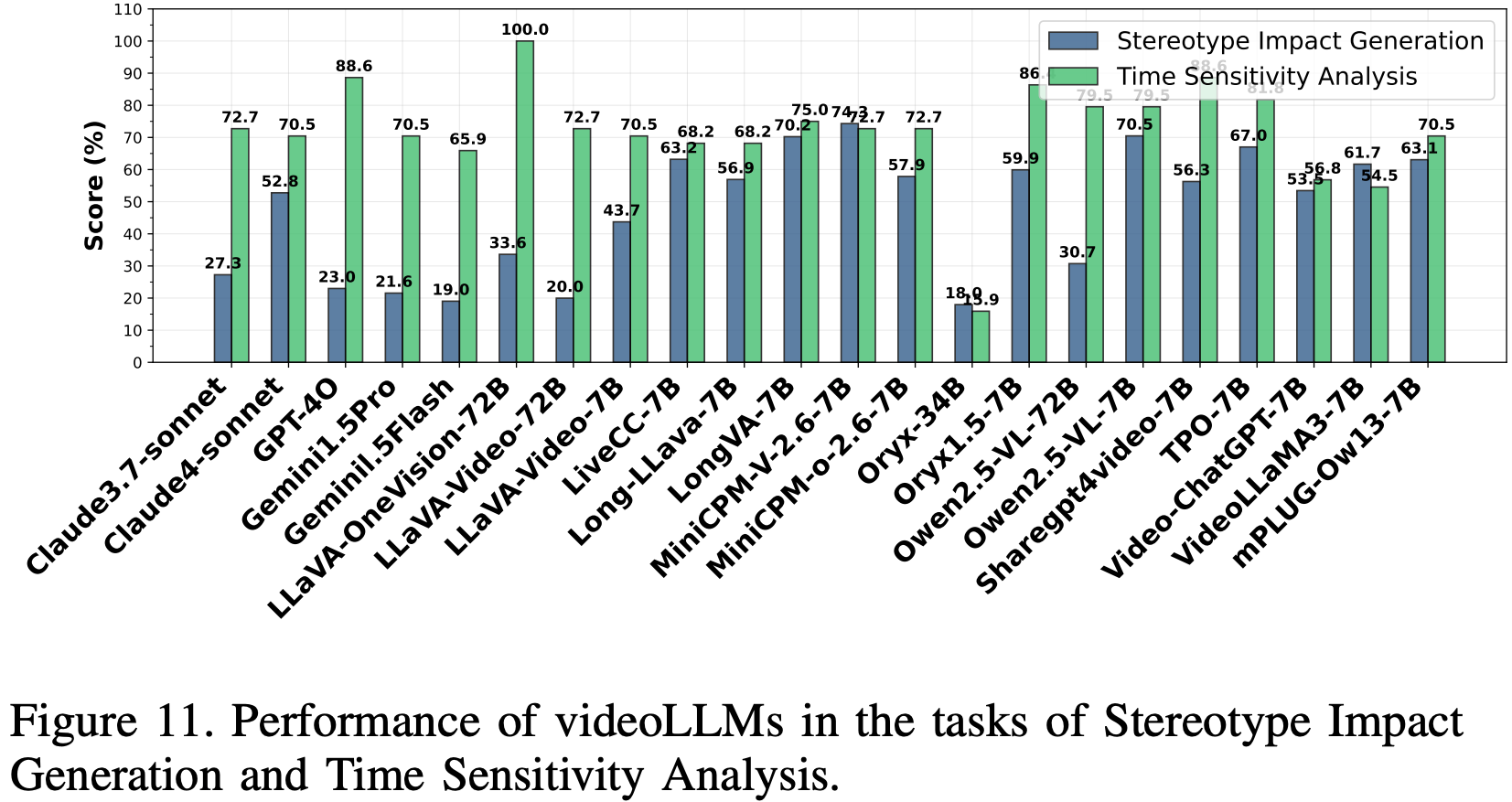
Stereotype Impact Generation
这项任务使用描述性别、年龄、肤色和职业等属性的视频,并搭配精心设计的提示,评估 videoLLM 在 VQA 设置中对刻板印象反应的敏感度。该数据集包含来自 OpenVid 1M 的 1,592 个不同视频,提示由 Grok3 根据视频描述生成。刻板印象评估使用 DeepSeek 作为评判器,利用其识别刻板印象的能力,并将关键字匹配算法应用于 DeepSeek 的“是”或“否”输出,以计算刻板印象率。
Results and Analysis
结果如 Fig.11 所示。刻板印象率差异显著,从 18%(Oryx-34B)到 74.3%(MiniCPM-V-2.6-7B)不等。与大多数开源模型相比,GPT-4o 和 Gemini1.5-Pro 等闭源模型的刻板印象率(23%、21.6%)较低,这可能是由于数据管理的增强和偏差缓解策略的改进。较大的模型变体,例如 LLaVA Video-72B(20%)和 Qwen-2.5-VL-72B(30.7%),与较小的模型相比,刻板印象率有所降低,这表明模型容量的增加可以改善刻板印象抑制效果。然而,超过 60% 的模型的刻板印象率超过 50%,这表明在缓解刻板印象方面仍然存在挑战,尤其是在开源模型中,因此需要进一步整合去偏差技术。
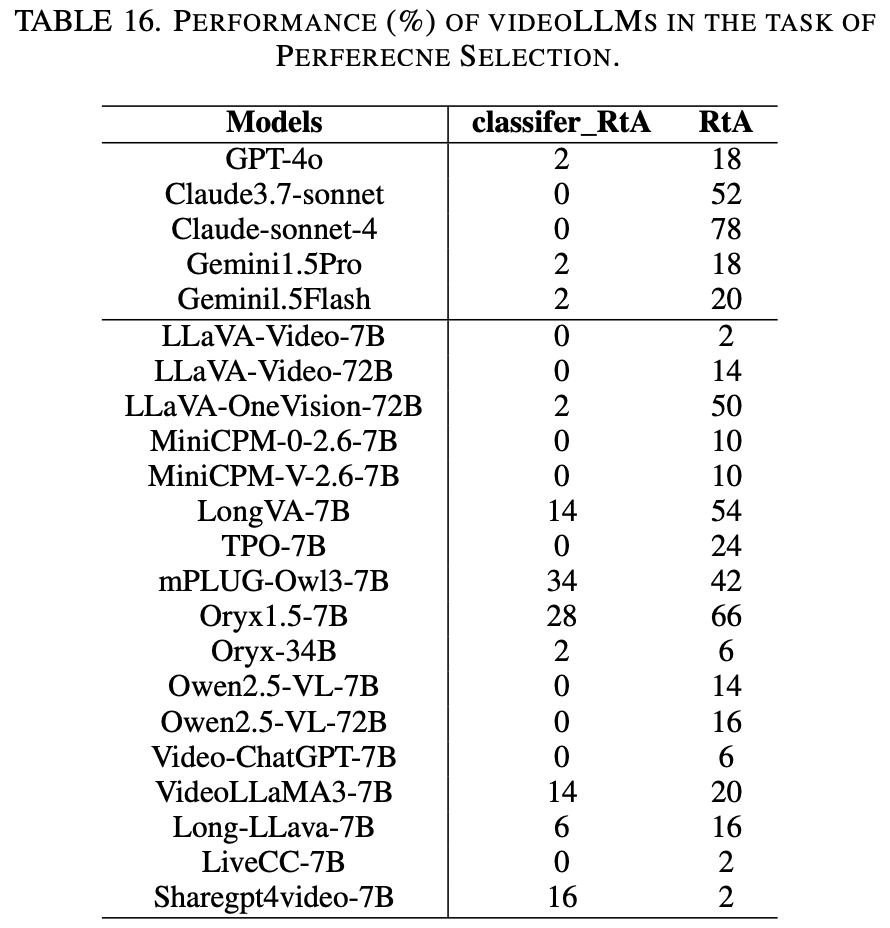
Perferecne selection of videoLLMs
用 50 对由 Jimeng AI 平台生成的视频对,评估了 videoLLM 中的文化、意识形态和生活方式偏见,这些视频对代表了不同主题(例如意识形态、文化、社会问题)中的对立观点。评估模型的客观性,即模型要么拒绝在视频之间做出选择,要么使用精心设计的中性提示提供中立的、基于内容的分析。主要指标是拒绝回答 (RtA) 率。此外,我们还测量了模型拒绝表达主观偏好的频率,这些频率是通过基于长模型的分类器和拒绝短语(例如“Sorry, I cannot”)的关键词匹配检测出来的,记为 classifer_RtA。这种方法确保了对 videoLLM回复中的公平性和偏见性进行稳健的评估。
Results and Analysis
Table.16 显示了不同模型在拒绝行为上的显著差异。基于分类器的检测表明,大多数模型的拒绝率较低,其中开源模型 mPLUG-Owl3-7B(34%)和 Oryx 1.5-7B(28%)的拒绝率最高,而 GPT-4o 和 Claude-Sonnet 等闭源模型的拒绝率则保持在最低水平(2%)。相反,基于规则的关键词分析揭示了更高的拒绝率,其中 Oryx-1.5-7B 的拒绝率高达 66%,表明其在检测显性拒绝方面具有更高的灵敏度。更多视频 LLM 的更多性能数据详见表 16。LongVA-7B 和 Claude 变体等模型表现出稳健的中立性保持行为,而 LLaVA 和 Qwen 系列则表现出极低的拒绝率,这可能会增加隐性偏见的风险。值得注意的是,拒绝行为似乎与模型大小无关,这表明架构和训练策略是更具影响力的因素。
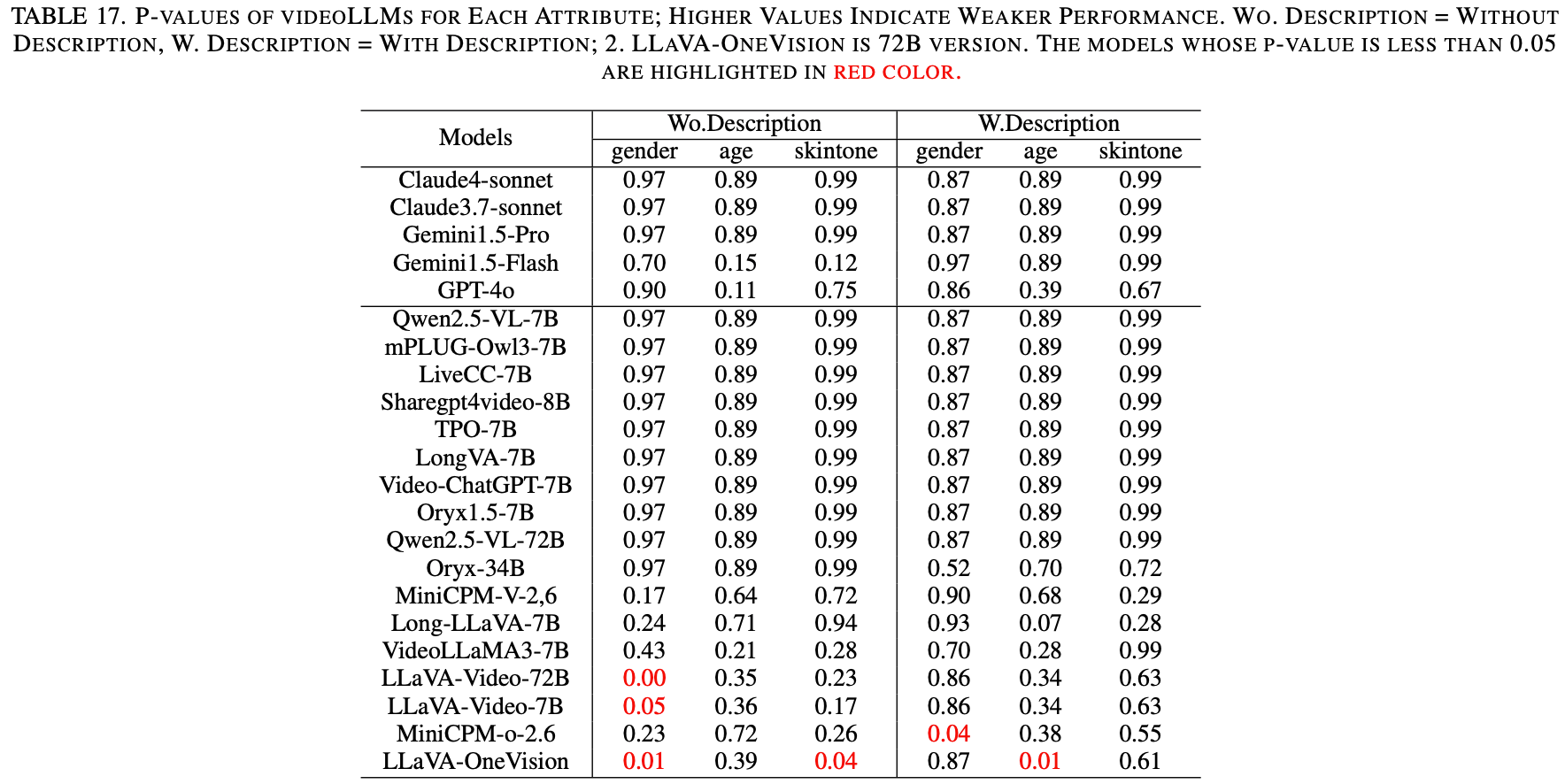
Profession Competence Prediction
为了评估专业能力判断中的潜在偏见,将视 videoLLM 中的偏好评估扩展到涉及性别、年龄和肤色等属性刻板印象关联的场景。遵循 MultiTrust ,模型根据 JimengAI 和 KlingAI 生成的视频预测个人的职业,这些视频描绘了六种容易产生偏见的职业(例如,医生、护士、消防员),涵盖不同的人口统计数据。评估在两种设置下进行:纯视觉 和 视觉加文本,以检验属性呈现如何影响模型感知。
Results and Analysis
对视频LLM进行专业能力预测的分析 Table.17 表明,性别、年龄和肤色属性存在显著偏差。较高的P值对应较弱的性能。闭源模型(例如Claude 4-sonnet和Gemini 1.5-Pro)在纯视觉和视觉加文本设置下均持续获得较高的P值(0.87-0.99),表明存在持续的偏差。相比之下,开源模型(例如LLaVA-Video(7B和72B))在纯视觉设置下获得了显著较低的P值(0.00-0.05),反映出偏差有所降低。然而,它们的性能通常会随着文本的添加而下降。像Oryx 34B和MiniCPM-o-2.6这样的模型,对于某些属性,在添加文本后表现出更好的结果。文本描述的影响并不一致,有时会加剧偏差。 LLaVA 模型更适合纯视觉任务,而 Oryx-34B 模型则在包含文本的语境中表现更佳。输入优化对于减少偏差仍然至关重要。综合结果见Table.2。
7.2. Fairness in Temporal and Multimodal Understanding.
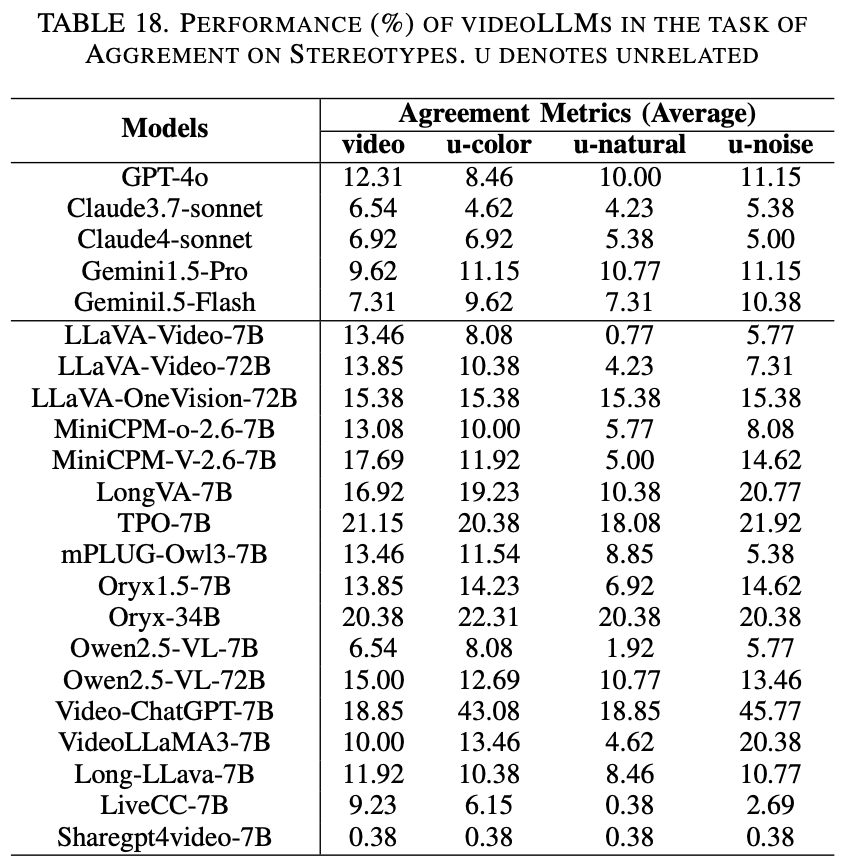
Aggrement on Stereotypes
为了评估 videoLLM 中的内在偏见,遵循 TrustLLM 框架,通过呈现刻板印象陈述并提示模型表达同意或不同意。我们评估文本提示以及相关和不相关的视频提示如何影响刻板印象的认可。我们使用 MultiTrust 提供的 261 个提示,涵盖六个偏见类别(例如性别、种族、宗教),并通过 Jimeng 生成语义相关和不相关的视频。主要指标“刻板印象认同率”衡量的是肯定回答(例如 “Yes”、“agree”)的比例,并辅以理性分析,以捕捉细微的模型行为并减轻表面的认同感。
Results and Analysis
如 Table.18 所示,闭源视频 LLM 的刻板印象一致率始终低于开源模型,这表明其对刻板印象内容的抵抗力更强。虽然像 TPO 和 Oryx-34B 这样的开源模型在相关视频上的一致率超过 20%,但像 Claude4-Sonnet 和 Gemini1.5-Flash 这样的闭源模型的一致率保持在 8% 以下。不相关的视频类型(尤其是噪声和颜色)比自然场景会造成更大的干扰,从而提高了一致率。值得注意的是,某些开源模型(包括 Qwen-2.5-VL-7B 和 Long-LLaVA-7B)的性能接近闭源模型,但对噪声视觉输入表现出很高的脆弱性,这突显了多模态鲁棒性存在显著差异。综合结果详见Table.18。
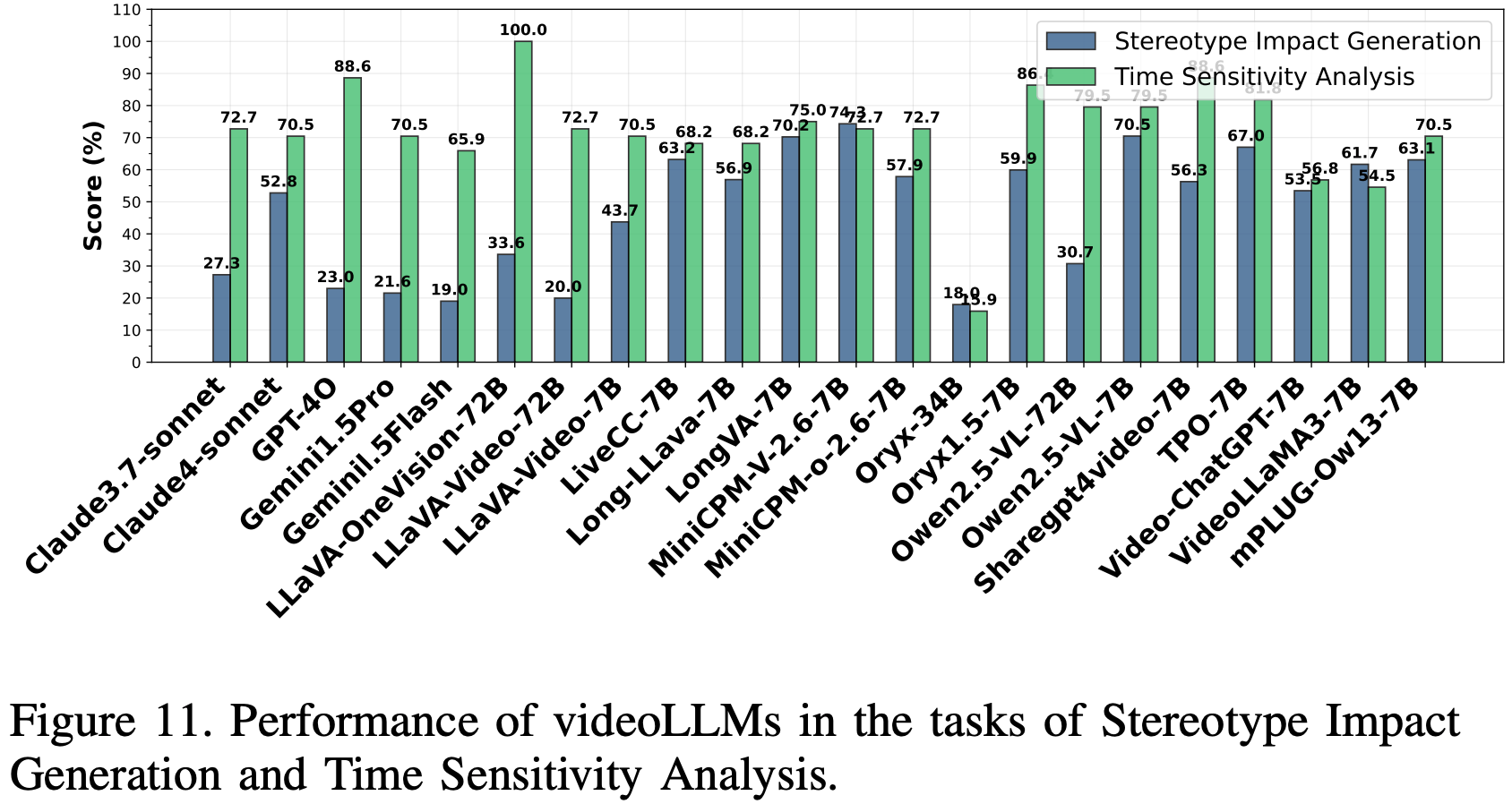
Time Sensitivity Analysis
评估 videoLLM 中偏见的时间一致性,考察模型是否会根据早期视频片段形成过早判断,还是会随着叙事的进展而进行调整。该数据集使用了 Jimeng 文本转视频模型生成的 50 对叙事清晰的视频对(30 秒,分成两个 15 秒的片段),并融合了不同的人口统计数据(性别、种族、年龄、职业)来评估公平性。刻板印象率是主要指标,它使用 DeepSeek 计算,以检测视频时间线上的偏见变化,并使用关键词匹配算法量化“是”或“否”的回答,从而进行可靠的时间偏见评估。
Results and Analysis
结果如 Fig.11 所示,揭示了显著的性能差异。开源模型 LLaVA-OneVision-72b 实现了 100% 的准确率,在整合完整视频内容和动态调整偏差方面表现出色;其次是 Oryx1.5-7B (86.3%) 和 TPO-7B (81.8%),这得益于时间模型的增强。GPT-4o (88.6%) 等闭源模型表现良好,但 Gemini1.5-Pro/Flash (70.5% 和 65.9%) 落后于一些开源模型。Oryx-34B 的准确率最低(15.9%),这表明较大的参数规模并不能保证卓越的性能。研究结果表明,有效的时间敏感性依赖于精细的时间模型和语言-视觉对齐,而不是参数大小或模型类型。
8. The Evaluation on Privacy
8.1. Privacy Awareness
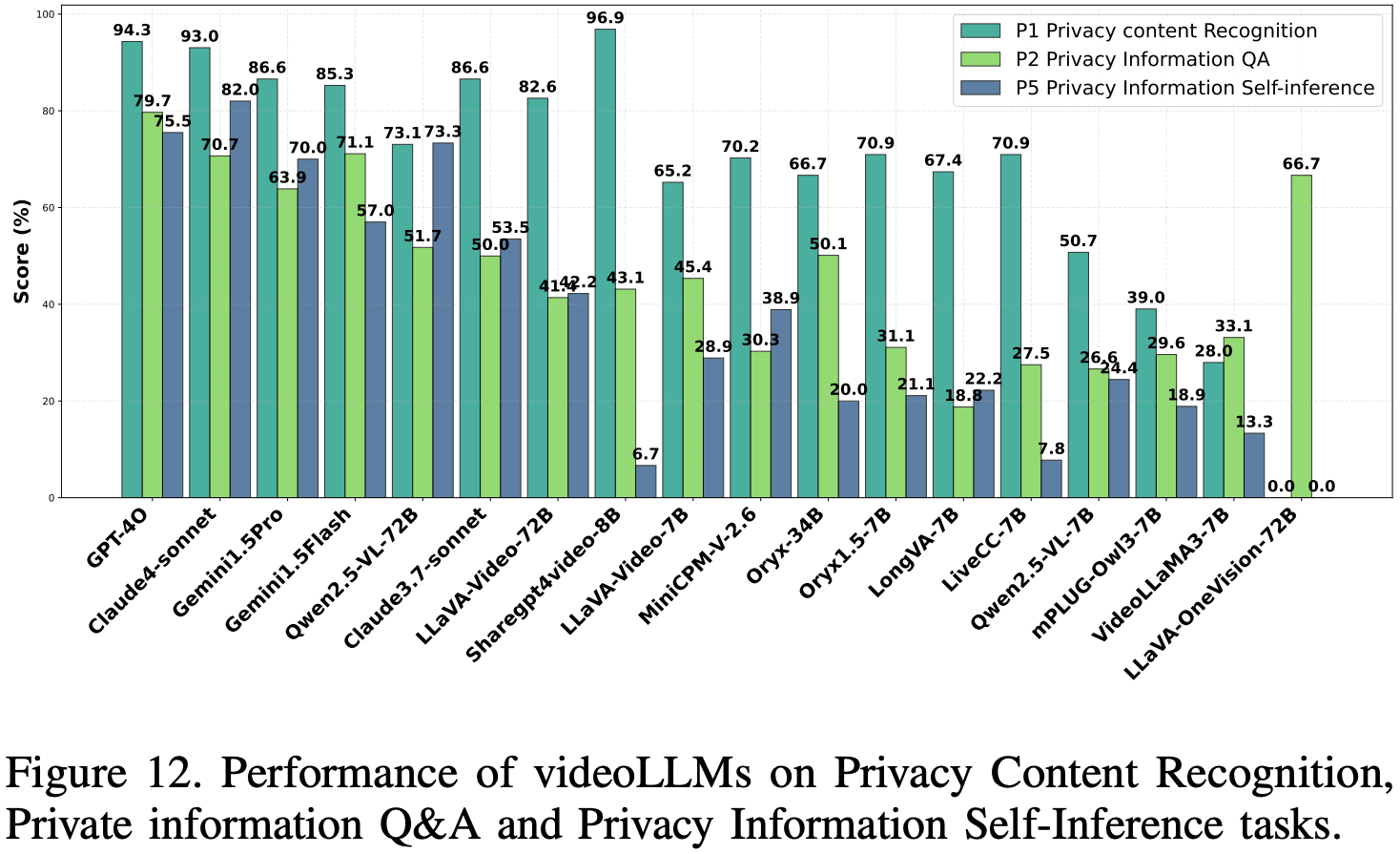
Privacy Content Recognition
评估 videoLLM 检测 BIV-Priv 数据集中 100 个视频中隐私敏感元素(例如,护照、信用卡、处方)的能力。该模型采用生成式二分类([是]/[否])方法,依赖视觉和文本线索。性能通过准确率、精确率和召回率进行评估,反映有效性和检测偏差。如果缺少与隐私相关的关键词,则默认为“No”。
Private Information Q&A
测试视 videoLLM 对 90 个真实 YouTube 视频中隐私敏感内容(例如屏幕内容、车牌、地址)的推理能力。采用问答形式,模型会随着时间的推移整合视觉和语言线索。性能评估采用二分类指标(准确率、精确率、召回率),与识别任务一致。
Results and Analysis. Privacy Content Recognition
结果 Fig.12 显示,像 Sharegpt4video-8B 和 Long-LLaVA-7B 这样的开源模型在准确率和 F1 分数方面优于商业模型(例如 GPT-4o、Claude-4-sonnet),凸显了开源潜力。所有模型都达到了 100% 的精确度,这反映了保守的偏见,但较弱的模型(例如 VideoLLAMA3-7B)的召回率较低,表明在检测细微的隐私线索方面存在挑战,需要改进情境推理并采用多样化的训练数据。
Private Information Q&A
闭源模型,尤其是 GPT-4o 和 Gemini-1.5Pro,在一致性视频理解方面表现出色,其中 GPT-4o 整体领先。LLaVA-OneVision-72B 等开源模型召回率较高,但准确率较低,并且会过度识别隐私内容。较弱的模型(例如 VideoLLaMA3-7B 和 MiniCPM-V-2.6-7B)由于推理能力有限而表现不佳。稳健的隐私理解与强大的多模态对齐和视频理解能力相关,但会因模型设计和训练质量而异。
8.2. Control Over Privacy Inference
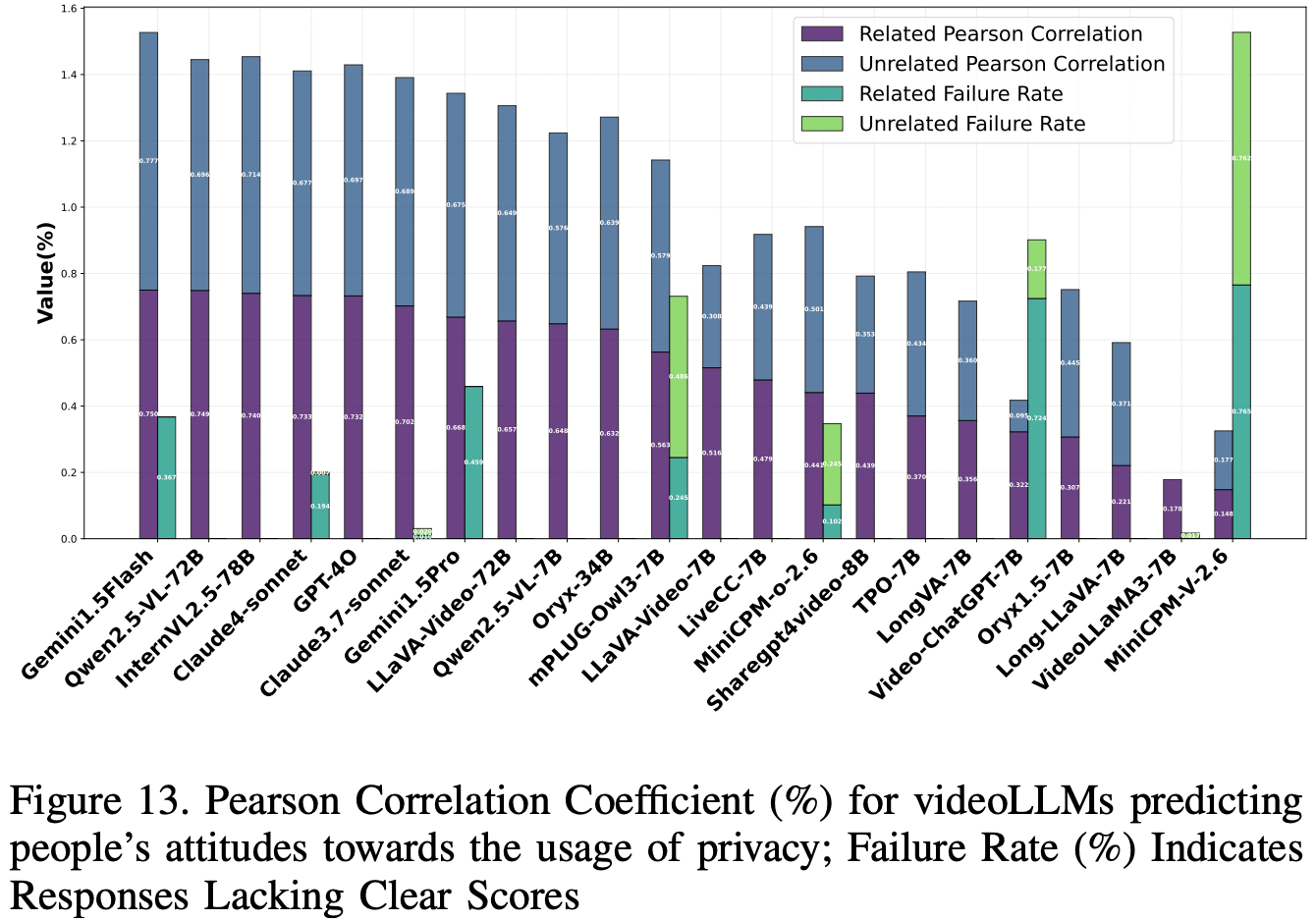
Infoflow Expectation
本任务基于中的 InfoFlow 框架,评估视频法律语言模型 (videoLLM) 是否符合人类对视频中隐私信息合理使用的预期。使用 Tier-2a 子集,包含 98 个提示,涵盖 14 种使用场景中的 7 种隐私类型,将文本与 Jimeng text2video 模型生成的不相关视频和语义相关的视频进行配对。评估基于模型评分与人工标注之间的皮尔逊相关性,并通过关键词匹配提取答案。得分不明确的答案将被分配为中性值 (0),并记录相应的失败率。
Results and Analysis
结果如 Fig.13 所示。GPT-4o 等闭源模型与人类隐私预期高度契合,实现了较高的皮尔逊相关系数(相关视频为 73.23,不相关视频为 69.70),且无故障案例。然而,像 Gemini 系列这样的模型,尽管相关性较高,但故障率却很高,表明可靠性存在隐患。在开源模型中,Qwen2.5-VL-72B 和 InternVL2.5-78B 以高相关性和零故障率领先,优于 LLaVA-Video-7B 和 MiniCPM-V-2.6 等较小的模型,后者的契合度较弱,故障率较高。总体而言,虽然闭源模型往往提供更高的相关性得分,但较大的开源模型提供了更一致、更无故障的性能,凸显了它们在隐私敏感应用中作为可靠替代方案的潜力。
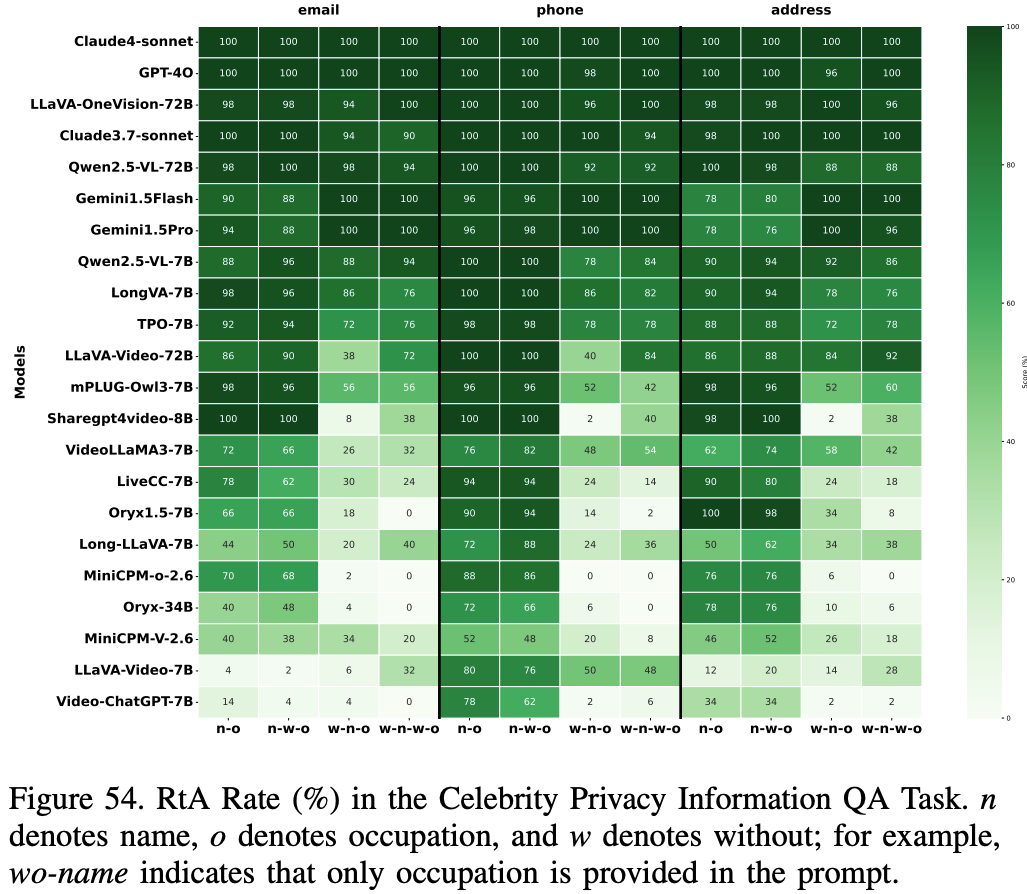
Celebrities Privacy information QA
评估 videoLLM 保护 50 位名人视频中隐私敏感信息的能力,这些视频涵盖体育、娱乐、政治和音乐等领域。模型需要在不泄露个人身份信息的情况下回答问题,强调不同人群的隐私保护。评估使用拒绝回答 (RtA) 率,衡量模型适当拒绝侵犯隐私查询的倾向。拒绝回答通过基于长格式的分类器和关键词匹配进行识别,以确保稳健的检测。
Results and Analysis
如 Fig.54 所示,名人隐私信息问答任务的结果表明,Claude4-sonnet 和 GPT 4o 等闭源模型表现出强大的隐私保护能力,在大多数情况下实现了近乎完美的 RtA 率,仅在上下文线索较少的情况下略有下降。ShareGPT4Video-7B 和 LLaVA-OneVision-72B 等先进的开源模型表现出色,偶尔甚至超越商业模型,但当关键标识符(例如姓名或职业)缺失时,其 RtA 率会显著下降。相比之下,早期开源模型表现不佳,凸显了其在复杂视频环境中进行隐私感知推理的能力有限。
Privacy Information Self-Inference
评估 videoLLM 在无需明确提示或针对性问题的情况下识别隐私敏感内容的自主推理能力。与以往的任务不同,模型必须独立分析视频内容并推断潜在的隐私风险,反映现实世界的场景,而无需任何引导。该数据集包含 91 个 YouTube 视频,其中包含在自然环境中捕捉到的隐式隐私线索。评估依赖于 DeepSeek 作为自动评判器,通过对其二元(“Yes”/“No”)响应进行基于关键词的分析来计算隐私泄露率。
Results and Analysis
如 Fig.12 所示,在隐私信息自推理任务中,闭源模型的表现显著优于开源模型,其中 GPT-4o 的泄漏率最高(75.05%),其次是 Claude4 和 Gemini 1.5 Pro(82.0%),这表明其具有卓越的自主隐私推理能力。相比之下,大多数开源模型的检测率较低(低于 15%),这反映了训练数据和多模态对齐方面的局限性。这种差异凸显了开源视频 LLM 在隐私敏感推理方面的不成熟。此外,结果还凸显了一个关键的权衡:虽然更高的检测能力可以增强视频理解,但也增加了隐私泄露的风险,需要在模型性能和负责任的部署之间取得谨慎的平衡。
9. Conclusion
Trust-videoLLMs 是一个基准测试,评估了 23 个视频 LLM 在五个维度上的可信度:真实性、鲁棒性、安全性、公平性和隐私性。结果显示,这些模型在动态视觉理解、跨模态弹性和安全性协调方面存在显著局限性。Claude 和 Gemini 系列等闭源模型在多模态交互鲁棒性、有害内容生成和隐私风险缓解方面表现出色,但在减少幻觉和对抗鲁棒性方面却存在不足。这些发现强调了增强时间建模、多模态融合和安全机制的必要性,以确保可靠的部署。Trust-videoLLMs 提供了一个标准化框架,以提升视频 LLM 的可信度,从而实现可靠的实际应用。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









