







CUDA简介
另一篇介绍windows 下程序
编程入门博客
深入浅出谈CUDA
CUDA(Compute Unified Device Architecture),是显卡厂商NVIDIA推出的运算平台。是一种通用并行计算架构,该架构使GPU能够解决复杂的计算问题。说白了就是我们可以使用GPU来并行完成像神经网络、图像处理算法这些在CPU上跑起来比较吃力的程序。通过GPU和高并行,我们可以大大提高这些算法的运行速度。
安装链接:CUDA—toolkit
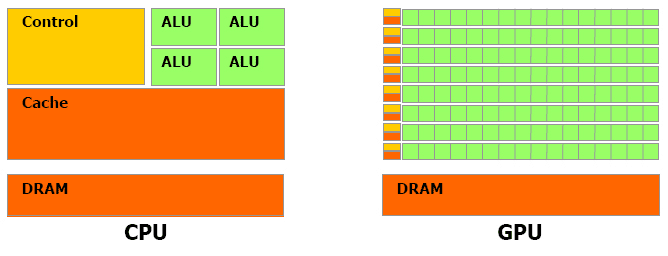
对于浮点数操作能力,CPU与GPU的能力相差在GPU更适用于计算强度高,多并行的计算中。因此,GPU拥有更多晶体管,而不是像CPU一样的数据Cache和流程控制器。这样的设计是因为多并行计算的时候每个数据单元执行相同程序,不需要那么繁琐的流程控制,而更需要高计算能力,这也不需要大cache。但也因此,每个GPU的计算单元的结构是十分简单的,因此对程序的可并行性的要求也是十分苛刻的。
GPU计算的优缺点(摘自《深入浅出谈CUDA》,所以举的例子稍微老了一点,但不影响意思哈):
使用显示芯片来进行运算工作,和使用 CPU 相比,主要有几个好处:
显示芯片通常具有更大的内存带宽。例如,NVIDIA 的 GeForce 8800GTX 具有超过50GB/s 的内存带宽,而目前高阶 CPU 的内存带宽则在 10GB/s 左右。
显示芯片具有更大量的执行单元。例如 GeForce 8800GTX 具有 128 个 “stream processors”,频率为 1.35GHz。CPU 频率通常较高,但是执行单元的数目则要少得多。
和高阶 CPU 相比,显卡的价格较为低廉。例如一张 GeForce 8800GT 包括512MB 内存的价格,和一颗 2.4GHz 四核心 CPU 的价格相若。
当然,使用显示芯片也有它的一些缺点:
显示芯片的运算单元数量很多,因此对于不能高度并行化的工作,所能带来的帮助就不大。
显示芯片目前通常只支持 32 bits 浮点数,且多半不能完全支持 IEEE 754 规格, 有些运算的精确度可能较低。目前许多显示芯片并没有分开的整数运算单元,因此整数运算的效率较差。
显示芯片通常不具有分支预测等复杂的流程控制单元,因此对于具有高度分支的程序,效率会比较差。
由于显示芯片大量并行计算的特性,它处理一些问题的方式,和一般 CPU 是不同的。主要的特点包括:
内存存取 latency 的问题:CPU 通常使用 cache 来减少存取主内存的次数,以避免内存 latency 影响到执行效率。显示芯片则多半没有 cache(或很小),而利用并行化执行的方式来隐藏内存的 latency(即,当第一个 thread 需要等待内存读取结果时,则开始执行第二个 thread,依此类推)。
分支指令的问题:CPU 通常利用分支预测等方式来减少分支指令造成的 pipeline bubble。显示芯片则多半使用类似处理内存 latency 的方式。不过,通常显示芯片处理分支的效率会比较差。
因此,最适合利用 CUDA 处理的问题,是可以大量并行化的问题,才能有效隐藏内存的latency,并有效利用显示芯片上的大量执行单元。使用 CUDA 时,同时有上千个 thread 在执行是很正常的。因此,如果不能大量并行化的问题,使用 CUDA 就没办法达到最好的效率了。
第一个CUDA程序
在 CUDA 的架构下,一个程序分为两个部份:host 端和 device 端。Host 端是指在 CPU 上执行的部份,而 device 端则是在显示芯片上执行的部份。Device 端的程序又称为 “kernel”。通常 host 端程序会将数据准备好后,复制到显卡的内存中,再由显示芯片执行 device 端程序,完成后再由 host 端程序将结果从显卡的内存中取回。
NVCC编译器
任何一种程序设计语言都需要相应的编译器将其编译为二进制代码,进而在目标机器上得到执行。对于异构计算而言,这一过程与传统程序设计语言是有一些区别的。为什么?因为CUDA它本质上不是一种语言,而是一种异构计算的编程模型,使用CUDA C写出的代码需要在两种体系结构完全不同的设备上执行:1、CPU;2、GPU。因此,CUDA C的编译器所做的工作就有点略多了。一方面,它需要将源代码中运行在GPU端的代码编译得到能在CUDA设备上运行的二进制程序。另一方面,它也需要将源代码中运行在CPU端的程序编译得到能在主机CPU上运行的二进制程序。最后,它需要把这两部分有机地结合起来,使得两部分代码能够协调运行。
CUDA C为我们提供了这样的编译器,它便是NVCC。严格意义上来讲,NVCC并不能称作编译器,NVIDIA称其为编译器驱动(Compiler Driver),本节我们暂且使用编译器来描述NVCC。使用nvcc命令行工具我们可以简化CUDA程序的编译过程,NVCC编译器的工作过程主要可以划分为两个阶段:离线编译(Offline Compilation)和即时编译(Just-in-Time Compilation)。
- 离线编译
离线编译(Offline Compilation): 在CUDA源代码中,既包含在GPU设备上执行的代码,也包括在主机CPU上执行的代码。因此,NVCC的第一步工作便是将二者分离开来,这一过程结束之后:
运行于设备端的代码将被NVCC工具编译为PTX代码(GPU的汇编代码)或者cubin对象(二进制GPU代码);
运行于主机端的代码将被NVCC工具改写,将其中的内核启动语法(如<<<…>>>)改写为一系列的CUDA Runtime函数,并利用外部编译工具(gcc for linux,或者vc compiler for windows)来编译这部分代码,以得到运行于CPU上的可执行程序。 完事之后,NVCC将自动把输出的两个二进制文件链接起来,得到异构程序的二进制代码。
2 . 即时编译
任何在运行时被CUDA程序加载的PTX代码都会被显卡的驱动程序进一步编译成设备相关的二进制可执行代码。这一过程被称作即时编译(just-in-time compilation)。即时编译增加了程序的装载时间,但是也使得编译好的程序可以从新的显卡驱动中获得性能提升。同时到目前为止,这一方法是保证编译好的程序在还未问世的GPU上运行的唯一解决方案。
在即时编译的过程中,显卡驱动将会自动缓存PTX代码的编译结果,以避免多次调用同一程序带来的重复编译开销。NVIDIA把这部分缓存称作计算缓存(compute cache),当显卡驱动升级时,这部分缓存将会自动清空,以使得程序能够自动获得新驱动为即时编译过程带来的性能提升。
>which nvcc //检测是否install nvcc如下代码为cuda-7.5/samples/0-samplePrintf中的例程,先实验一波。
/*
* Copyright 1993-2015 NVIDIA Corporation. All rights reserved.
// System includes
#include <stdio.h>
#include <assert.h>
// CUDA runtime
#include <cuda_runtime.h>
// helper functions and utilities to work with CUDA
#include <helper_functions.h>
#include <helper_cuda.h>
#ifndef MAX
#define MAX(a,b) (a > b ? a : b)
#endif
__global__ void testKernel(int val)
{
printf("[%d, %d]:\t\tValue is:%d\n",\
blockIdx.y*gridDim.x+blockIdx.x,\
threadIdx.z*blockDim.x*blockDim.y+threadIdx.y*blockDim.x+threadIdx.x,\
val);
}
int main(int argc, char **argv)
{
int devID;
cudaDeviceProp props;
// This will pick the best possible CUDA capable device
devID = findCudaDevice(argc, (const char **)argv);
//Get GPU information
checkCudaErrors(cudaGetDevice(&devID));
checkCudaErrors(cudaGetDeviceProperties(&props, devID));
printf("Device %d: \"%s\" with Compute %d.%d capability\n",
devID, props.name, props.major, props.minor);
printf("printf() is called. Output:\n\n");
//Kernel configuration, where a two-dimensional grid and
//three-dimensional blocks are configured.
dim3 dimGrid(2, 2);
dim3 dimBlock(2, 2, 2);
testKernel<<<dimGrid, dimBlock>>>(10);
cudaDeviceSynchronize();
// cudaDeviceReset causes the driver to clean up all state. While
// not mandatory in normal operation, it is good practice. It is also
// needed to ensure correct operation when the application is being
// profiled. Calling cudaDeviceReset causes all profile data to be
// flushed before the application exits
cudaDeviceReset();
return EXIT_SUCCESS;
}
运行结果如下(调用了sample/common/inc中的部分函数):
GPU Device 0: "GeForce GTX 960M" with compute capability 5.0
Device 0: "GeForce GTX 960M" with Compute 5.0 capability
printf() is called. Output:
[3, 0]: Value is:10
[3, 1]: Value is:10
[3, 2]: Value is:10
[3, 3]: Value is:10
[3, 4]: Value is:10
[3, 5]: Value is:10
[3, 6]: Value is:10
[3, 7]: Value is:10
[2, 0]: Value is:10
[2, 1]: Value is:10
[2, 2]: Value is:10
[2, 3]: Value is:10
[2, 4]: Value is:10
[2, 5]: Value is:10
[2, 6]: Value is:10
[2, 7]: Value is:10
[1, 0]: Value is:10
[1, 1]: Value is:10
[1, 2]: Value is:10
[1, 3]: Value is:10
[1, 4]: Value is:10
[1, 5]: Value is:10
[1, 6]: Value is:10
[1, 7]: Value is:10
[0, 0]: Value is:10
[0, 1]: Value is:10
[0, 2]: Value is:10
[0, 3]: Value is:10
[0, 4]: Value is:10
[0, 5]: Value is:10
[0, 6]: Value is:10
[0, 7]: Value is:10
Tips
在尝试运行helloworld.cu程序时,遇到/bin/..//include/host_config.h:82:2: error: #error – unsupported GNU version! gcc 4.9 and up are not supported!问题:
因为我的cuda版本为7.5,不支持我的gcc,运行如下指令更新gcc版本:
sudo apt-get install gcc-4.8 g++-4.8
sudo update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-4.8 50
sudo update-alternatives --install /usr/bin/g++ g++ /usr/bin/g++-4.8 50在运行时执行make命令,自己单独使用nvcc调用还有问题,估计时环境变量的问题,留待明天解决(solver:是因为引用了sample/common/inc中的部分.h文件)。















 1225
1225

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









