







我们或多或少都有遇到过选择困难的情况。比如,今天晚上去哪吃?吃什么?怎么吃?(等等,为什么都是吃…)面对选择困难的时候如何做出选择是一个让很多人头疼和纠结的事情。
如果我们对我们吃完之后对哪个比较满意提前就知道的话我们当然就不会有如此的纠结。所谓的纠结其实就是因为情报不完全而难以做出判断。如果把这个问题说得更宽泛一点,它就是一个决策的问题。在不完全情报下做出最优的策略?
事实上有一样东西做起决策来比你还纠结,它就是计算机。如果不给定一个确定的计算方法,它可是做不出决策出来。这在计算机人工智能领域有一个非常常用的方法来帮助计算机来做出这样的决策,它就是“贝叶斯决策”。利用该方法来决定每天吃什么,即可以消除自己的纠结,也可以避免使用随机方法(比如抛硬币)这样比较愚蠢的方法。
贝叶斯决策是基于18世纪著名的英国数学家提出的贝叶斯公式来的。但是我并不是一个喜欢说公式这样生涩难懂的东西的人,所以我们可以先聊聊别的。
- 我们来假设一种情况,我们来估计我明天有没有事要不要出门,为了简化模型,我们认为只有明天有事的情况下出门。于是我去看了一眼天气预报,明天的降水概率是30%,然后再去想了一下,其实上个月 30 天里,有 10 天下了雨,这 10 天里有 1 天有事,而剩下 20 天里有 5 天有事。
画一个 10×10 的正方形,横轴 3:7 分开,分别代表明天的下雨还是不下雨。
然后分开来看,左边下雨的部分,分成 10 分,取 1 分,因为下雨天有事的概率只有 1/10,右边分成 4 分取 1 分因为不下雨有事的概率是 1/4。于是下图中红色面积和黄色面积加起来就是明天会出门的概率啦。

显然地红色加黄色的面积(出门)比蓝色加绿色的面积(不出门)要大啊!如果精确算一下的话,整个正方形的面积是10×10的话,红色加黄色的面积是 1×3+2.5×7=20.5,大约只有1/5的概率会出门。哈!果然死宅是不用出门的呢!(这么自暴自弃可好?)
这是简单的贝叶斯公式的应用,但是实际情况比这个复杂得多,因为并不是什么情况都能在做一件事之前就清楚地知道每个部分的概率的。于是便有了贝叶斯决策的核心内容,也就是 先进行主观的概率估计(这个概率估计被称为先验概率),然后通过一些数据对这个估计进行修正(修正后的概率称之为后验概率),通过后验概率的大小来进行决策。
所以我们回到一上来考虑的问题,今天晚上吃什么。
为了简化模型,我们发现面前来到的地方只有“肯打鸡”和“铜钱豹”两家店在营业。一个想知道哪家更好吃的办法就是看看别人的意见,于是打开了大众点评
发现肯打鸡的评分是 4/5,铜钱豹的评分是 3.5/5。于是我们就不妨假设先验概率为 8:7。
然后我发现,过去我在大众点评吃过的所有4星的餐厅里,大概有 70% 是满意的。而所有 3.5 星餐厅中,大概有 50% 是满意的。于是变成了下图。
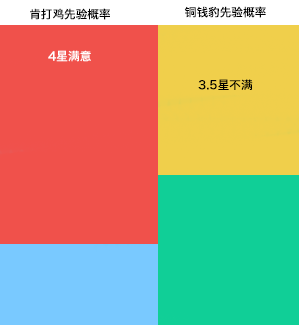
红色+黄色的面积成为了我选择肯打鸡的概率 60.67%,蓝色+绿色面积是我选择铜钱豹的概率,39.33%。
然后更神奇的一幕出现,贝叶斯算法对于条件还可以嵌套使用。也就是说用更多条件来约束,从而求得更精确的后验概率。比如肯打鸡的人均消费是 50 元,而铜钱豹的人均消费是 200。我过去吃人均消费 50 左右的次数是吃 200 左右的 3 倍,然后再代入,再求出相应的当前我选择肯打鸡的概率和选择铜钱豹的概率。当你认为把各个条件都考虑差不多了,最终的后验概率也就出现了,哪个概率高,就去吃哪个咯~
之所以贝叶斯决策能很好地终结选择困难是因为你终于将困扰你的所有因素的写了下来,并用数学的方法确定了他们对你决策的影响。每次考虑的时候都是两两考虑,尽可能地避免了其它因素的干扰。而且,根据现有经验的增长,可以对公式进行不断的修正,随着对这个公式的使用次数越来越多,得出结果的准确性也会越来越高。从而能得到一个基于现有经验的客观合理的选择,并且给了自己一个信服的理由,而不是抛硬币的一个草率的结果。
对于贝叶斯公式的应用当然远不止如此,尤其是它是机器学习的重要手段。比如2002年时,Paul Graham 提出的垃圾邮件过滤器(这是我们现在垃圾邮件过滤的主要方法之一),就是通过贝叶斯公式,学习一定样本量的垃圾邮件,然后判断下一封邮件是不是垃圾邮件,并且判断完垃圾邮件之后还可以通过这封新的垃圾邮件继续学习。该过滤器在当时可以过滤超过 99% 的垃圾邮件(当然魔高一尺道高一丈,现在垃圾邮件也通过干扰字符等手段不但破解这个系统,也促使了过滤器的进一步发展)。
后记:其实很少说有关算法或者数学方面的内容,因为公式之类的东西实在是生涩难懂让人厌烦。所以我尽量在描述的时候用通俗的方法来描述概念,而不是列一个公式出来。虽便于理解,但有时也颇有不够严谨之处。不知道这样的文章大家是否可以看懂,是否觉得有意思,以及有哪些可以改进的地方。偶尔做一些这样的尝试,如有不妥之处也请各位指出,谢谢。
转自 http://blog.heckpsi.com/2015/01/19/application-of-bayes-theorem/















 3767
3767

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









